引言
我上一篇文章详细讲述了如何将 RAGFlow 部署到本地,有兴趣的铁子也可以去看一下:RAGFlow Windows环境下本地部署全攻略,但部署到本地之后又产生了一个问题,如何将本地模型配置到 RAGFlow,虽然没官方文档也有介绍,但是基本上是一笔带过,不是很详细,我也根据网上的方法做了一些尝试,但都没有达到想要的效果,于是就有了这篇文章,想详细记录一下部署过程,避免大家走弯路。
一、主流本地模型部署方案
要配置本地模型,肯定先要下载模型到本地,下面我们利用现在网络上流行的两种主流方法进行本地模型的部署,如果已经部署过本地模型的可以跳过安装,直接进入配置即可。
方案一:Ollama轻量级集成
1. 安装Ollama
进入 Ollama 下载官网:https://ollama.com/download,选择对应版本下载即可,这里我电脑是 Windows 所以点击 Windows 图标直接下载即可:
下载完成之后,双击安装包一步步进行安装即可,这里没有特别需要注意的所以不过多赘述。
2. 启动本地模型(以 DeepSeek-R1-8B 为例)
安装完 ollama 之后,进入 ollama 官网页面:https://ollama.com/library/deepseek-r1,选择你想要下载的模型,这里我选择的是 deepseek-r1:8b,选择好之后后面会出现安装指令(ollama run deepseek-r1:8b)
打开终端输入下面命令,等待安装完成即可:
bash
ollama run deepseek-r1:8b3. 配置RAGFlow连接
安装完成之后打开 RAGFlow 以如下步骤进入模型提供商界面:
- 进入RAGFlow管理界面 → 模型提供商 → 添加模型
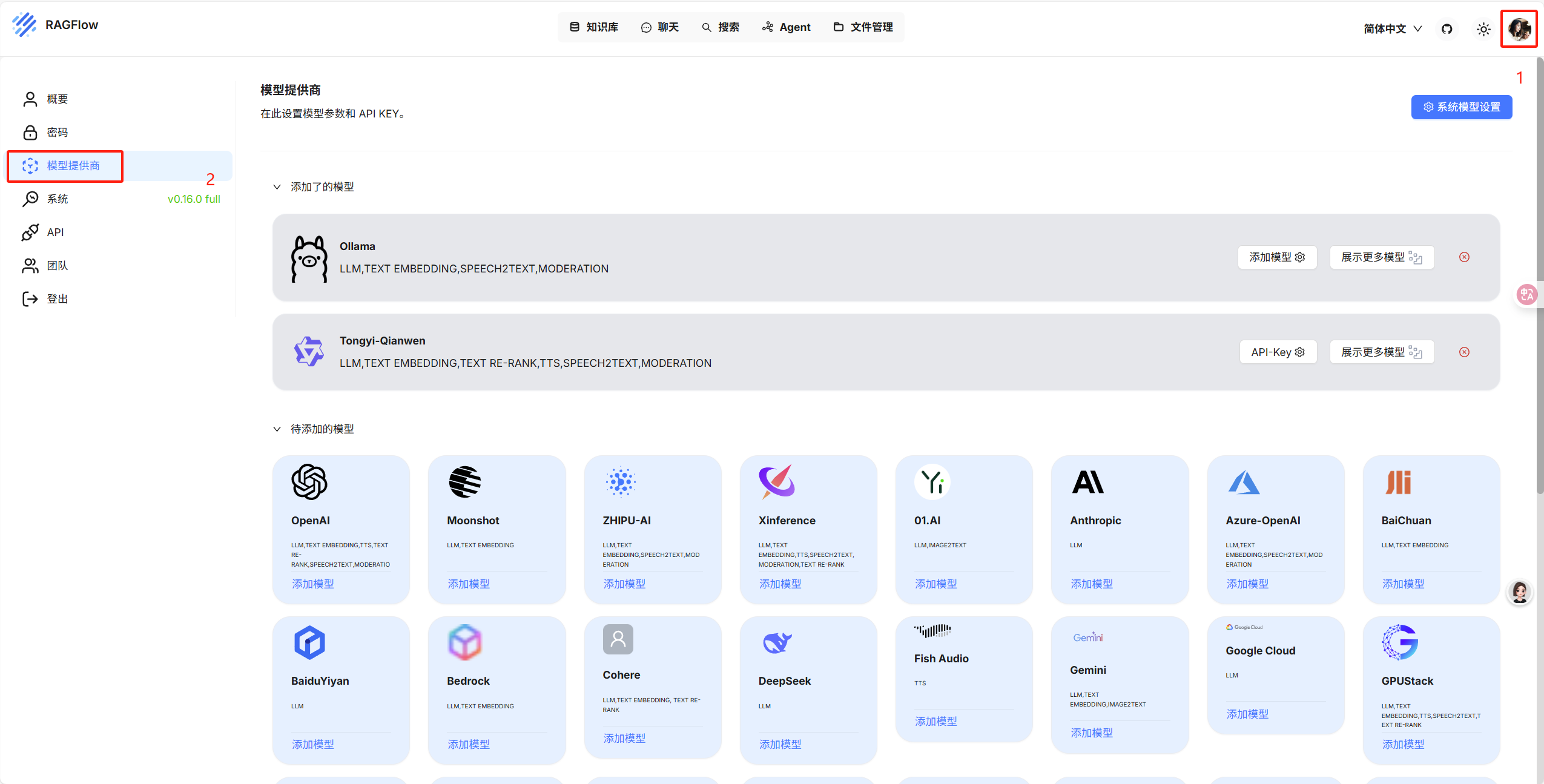
然后选择 Ollama,这里因为我已经添加过了,所以 Ollama 在添加了的模型分组里面,如果你没添加过 Ollama 就应该在待添加的模型里面,点击添加模型,进入模型配置里面:
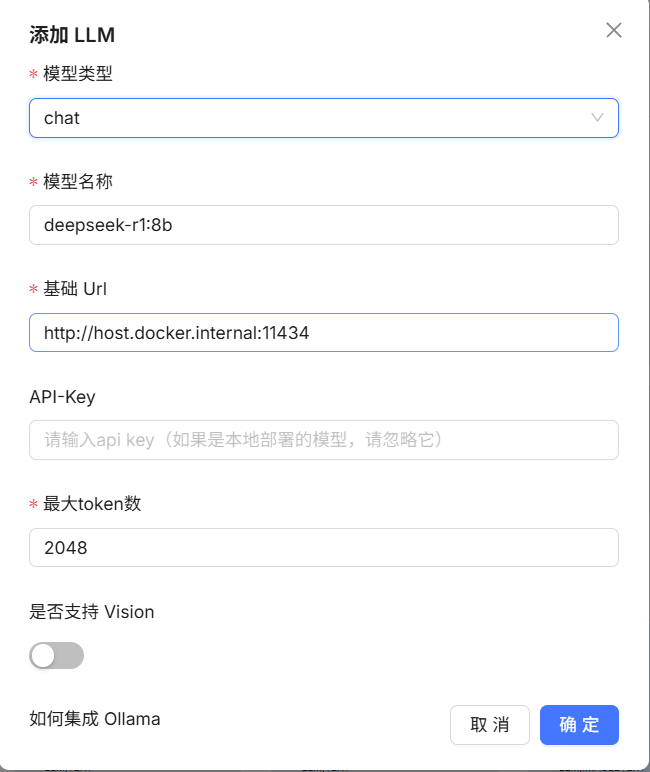
解释: 模型类型里面总共有四类分别为:
chat(对话):专注于对话场景,使模型具备自然语言理解与生成能力,能理解对话上下文并生成连贯、自然的回复,适用于智能客服、虚拟助手等需要交互问答的场景,让用户获得类人化的对话体验。
embedding(嵌入):将文本、图像等数据转换为固定长度的向量表示,保留数据语义信息,便于后续进行相似度计算、文本检索、聚类分析等任务。在RAGFlow中,常用于将文档内容转为向量,以便快速检索匹配相关信息。
rerank(重新排序):对初步检索结果进行优化排序,结合上下文信息和用户意图,提升检索结果的相关性与精度。例如在复杂问答中,对多个检索到的文档片段进行重排序,优先呈现最符合需求的内容。
image2text(图像转文本):将图像内容转化为文本形式,提取图像中的信息(如物体、场景、文字等),以便进一步分析、检索或生成回答,拓展了对非文本数据的处理能力。
这些模型类型在 RAGFlow 中协同工作,可实现更智能的知识检索与内容生成,满足多样化的应用需求,如智能客服、知识问答、内容创作等,这里我们一般只需要添加 chat 和 embedding 即可。
第二个模型名称进来和下载时的名称一样,也就是:deepseek-r1:8b
第三个 url 这里是我配置了好久也没配置成功的地方,所以这块是重点,在我配置时一直提示下面这个错误:

后面找了很多方法都显示只需要配置为 http://ollama:11434 但是一直报这个错误后面才发现是 Docker 容器默认是网络隔离的,RAGFlow 容器中的 localhost 指向自身,而非宿主主机,在 RAGFlow 中填写http://ollama:11434,会尝试连接 RAGFlow 容器内的 11434 端口,所以才会一直报这个错误,只需要将地址改为 http://host.docker.internal:11434 就可以,这里我也列出了三种方法,你们可以逐一尝试:
- 方法一:
http://<宿主机IP>:11434 - 方法二:
http://ollama:11434 - 方法三:
http://host.docker.internal:11434
至于 API-key 因为是本地连接,所以不需要管,到这里只需要按你的需求配置 token 数(一般为1024或者2048等)然后点击确定即可。
4. 验证配置
刷新一下点击展示更多模型如果显示了你刚添加的模型就代表配置成功了
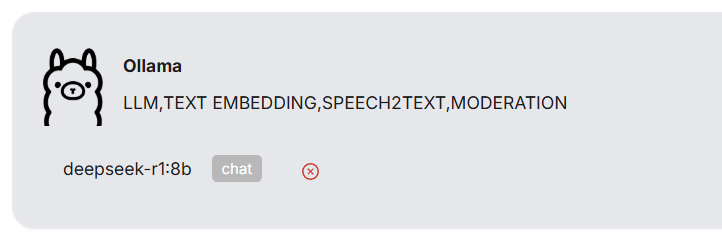
方案二:Xinference高性能部署
这里知识模型拉取方式不同,其他的相差不多,所以这里我简略叙述一下。
1. 拉取Xinference镜像
bash
docker pull ghcr.io/xinyagroup/xinference:latest2. 启动服务
bash
docker run -d -p 8997:8997 ghcr.io/xinyagroup/xinference:latest3. 部署模型(以LLaMA-2为例)
- 访问
http://localhost:8997→ 模型市场 → 选择llama-2-7b-chat - 点击部署 → 等待模型加载完成
4. 配置RAGFlow
- 在RAGFlow中添加模型提供商:
- 名称:LLaMA-2-7B
- API地址:
http://localhost:8997/v1 - 模型名称:
llama-2-7b-chat
二、常见问题与解决方案
1. 连接超时
可能原因:
- 本地模型未启动或端口错误
- Docker容器防火墙限制
解决步骤:
bash
# 检查Ollama状态
ollama status
# 测试端口连通性
telnet localhost 114342. 模型不兼容
症状 :返回unsupported model
解决方案:
- 确保模型支持OpenAI API规范
- 使用Xinference等兼容层转换接口
3. 上下文长度不足
优化方法:
bash
# 在Ollama中指定上下文长度
ollama run mistral:7b --ctx-size 4096总结
通过本文的详细指南,希望您可以掌握在RAGFlow中集成Ollama、Xinference等本地部署的核心技巧,如果您有什么疑问也欢迎您在评论区留言一起讨论。在实际应用中,建议根据场景选择方案:
- 轻量级场景:Ollama + Mistral,适合快速验证
- 高性能需求:Xinference + LLaMA-2,支持复杂推理
- 隐私敏感场景:结合HTTPS和访问控制,确保数据安全
未来可进一步探索模型量化、多模态融合等高级特性,充分释放本地大模型的潜力。