AI Repos
OpenHands(前身为OpenDevin)是一个由AI驱动的软件开发代理平台,它能够像人类开发者一样修改代码、运行命令、浏览网页、调用API,甚至从StackOverflow复制代码片段。用户可以通过OpenHands Cloud轻松上手,新用户可获得50美元免费积分,也可选择通过Docker在本地系统运行。OpenHands旨在为单个用户在本地工作站上提供支持,不适用于多租户部署,并鼓励开发者社区贡献力量,共同推动项目发展。

2、fastmcp
FastMCP是一个TypeScript框架,专为构建MCP(Model Context Protocol)服务器而设计,能有效管理客户端会话。该框架具备简易的工具、资源、提示定义、认证、会话管理、图像与音频内容处理、日志记录及错误处理等功能。它支持HTTP Streaming和SSE兼容,并提供CLI工具用于测试与调试。FastMCP旨在简化MCP服务器的开发流程,支持多种传输选项和灵活的工具定义方式,包括参数校验、多种内容返回类型以及可配置的Ping行为和根目录管理,为开发者提供强大且便捷的解决方案。
Claude Code Interface是一款为VS Code设计的轻量级扩展,它在VS Code中提供了一个聊天式界面,让用户能直接与Claude Code进行交互。该扩展支持文件上下文选择,帮助Claude更好地理解代码库,并通过专用终端展示Claude的响应。用户只需安装并认证Claude Code CLI,即可在VS Code中便捷地发送消息、提问,并查看Claude的实时回复,从而提升编程效率。
该GitHub仓库提供了基于MCP Streamable HTTP Spec的Python和TypeScript实现的MCP(Model Context Protocol)Streamable HTTP客户端和服务器示例。它展示了如何使用单一语言(Python或TypeScript)构建完整的客户端-服务器堆栈,同时也强调了跨语言兼容性,允许Python客户端与TypeScript服务器通信,反之亦然。通过这些示例,开发者可以了解如何配置API密钥、启动服务器和客户端,并进行交互式聊天,实现基于Claude语言模型的天气查询等功能,所有通信均通过Streamable HTTP协议进行。
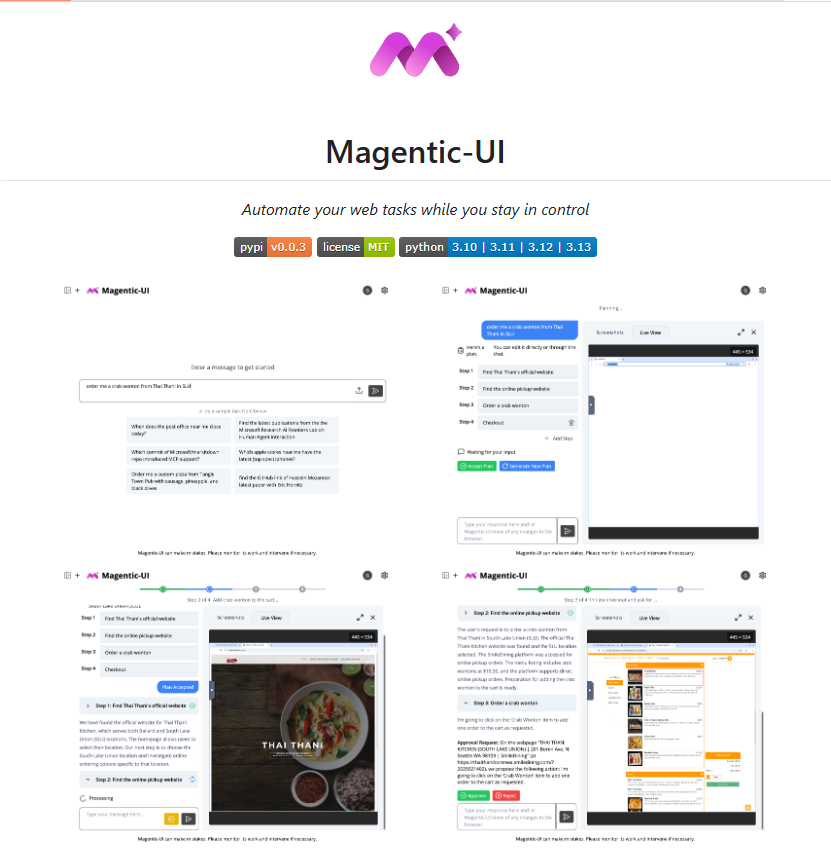
Magentic-UI是基于AutoGen的多智能体系统原型,旨在提供以人为中心的Web操作界面。它能实现浏览网页、执行代码、生成和分析文件等功能,尤其擅长处理需要深度导航或代码执行的Web任务。Magentic-UI的特色在于其透明且可控的界面,支持人机协同规划与执行、敏感操作审批、计划学习与检索以及并行任务执行。安装简便,仅需Docker环境,用户可通过Python包管理器快速部署,并灵活配置不同LLM模型。
AI News
1、谷歌推出 MedGemma:医疗AI影像与文本分析新突破
谷歌在2025年I/O开发者大会上宣布开源MedGemma,这是一款基于Gemma3架构的医疗AI模型,旨在革新医疗诊断与治疗。MedGemma提供4B和27B两种参数配置:4B模型擅长医疗图像分类与解读,能生成详细诊断报告;27B模型则专注于深度理解临床文本,支持患者分诊和决策辅助。开发者可在本地或通过谷歌云Vertex AI平台部署使用,并利用谷歌提供的丰富资源进行模型微调。MedGemma的发布预示着医疗AI领域的重大进展,为未来的医疗实践带来了无限可能。
2、英伟达推出 Cosmos-Reason1:赋能AI物理常识与具身推理
英伟达近日发布Cosmos-Reason1系列模型,旨在解决现有AI模型在理解物理世界方面的不足。该模型采用物理AI监督微调和强化学习两大训练阶段,并引入双本体系统,将物理常识分为空间、时间和基础物理,同时映射具身代理的推理能力。Cosmos-Reason1结合视觉编码器处理视频数据,实现文本与视觉数据的同步推理。在多项物理常识和具身推理基准测试中,模型表现出色,特别是在强化学习后,对下一步行动预测、任务完成验证和物理可行性评估方面取得显著进展,为机器人和自动驾驶等领域提供了新方案。
3、腾讯混元大模型战略升级:Turbo S与T1模型全面迭代
2025年5月21日,腾讯宣布其混元大模型矩阵全面升级,涵盖旗舰快思考模型混元TurboS、深度思考模型混元T1,以及视觉深度推理模型T1-Vision和端到端语音通话模型混元Voice等。混元TurboS在全球大语言模型评测中位列前八,并通过技术优化显著提升理科推理、代码能力和竞赛数学成绩。多模态生成模型如混元图像2.0和混元3D v2.5也实现突破,并在游戏领域推出混元游戏视觉生成模型。腾讯表示将继续开源,推动AI普惠和产业升级。
4、字节跳动开源多模态模型BAGEL:图文生成与编辑新突破
字节跳动近日开源了多模态基础模型BAGEL,拥有70亿活跃参数,整体达140亿参数。该模型在多模态理解基准测试中超越Qwen2.5-VL和InternVL-2.5,并在文本到图像生成质量上媲美SD3,在图像编辑方面表现更优。BAGEL采用混合变换器专家(MoT)架构,利用双编码器捕捉图像特征,通过"下一个标记组预测"范式训练。经海量多模态数据预训练和微调,BAGEL展现了先进的上下文多模态能力,包括自由形式图像编辑、未来帧预测及三维操作,持续提升在理解、生成和编辑任务中的表现。
5、谷歌发布Gemma3n:手机上的多模态AI新纪元
谷歌在2025年I/O大会上推出Gemma3n,一款专为低资源设备设计的多模态AI模型。该模型仅需2GB RAM,即可在手机、平板和笔记本电脑上流畅运行,支持文本、图像、视频和音频的实时处理,且无需云端连接。Gemma3n新增音频理解和签语理解功能,响应时间低至50毫秒,并支持高效微调。它基于Gemini Nano架构,通过逐层嵌入和量化感知训练优化内存占用。Gemma3n的发布标志着移动端AI的重大突破,尤其在无障碍技术、移动创作和物联网领域潜力巨大。
6、谷歌I/O大会发布AI全家桶:搜索与多媒体创作全面升级
谷歌在近期I/O大会上推出系列AI新功能,旨在革新搜索与创作体验。其中,AI Mode作为全新AI搜索体验,支持多模态输入与上下文推理,能快速生成引用报告并实现摄像头实时提问。模型方面,Gemini2.5Pro和Flash版本升级,提升推理能力和效率,特别是Deep Think功能强化了复杂问题解决。此外,谷歌还发布多款创作工具,包括音频视频生成模型Veo3、图像生成工具Imagen4,以及支持实时音乐生成的Lyria RealTime。这些创新展示了谷歌在AI领域的强大实力,推动数字内容创作进入新时代。