前言
为了方便大家学习,我整理了PyTorch全套学习资料,包含配套教程讲义和源码
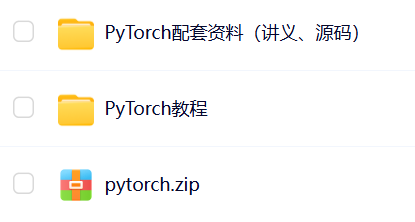
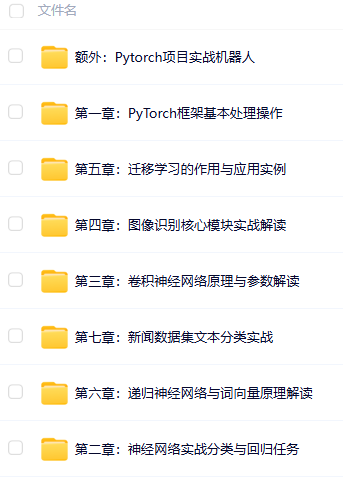
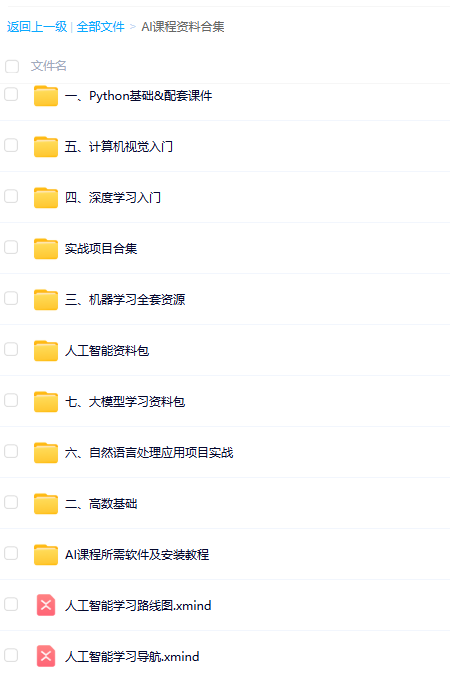
除此之外还有100G人工智能学习资料
包含数学与Python编程基础、深度学习+机器学习入门到实战,计算机视觉+自然语言处理+大模型资料合集,不仅有配套教程讲义还有对应源码数据集。更有零基础入门学习路线,不论你处于什么阶段,这份资料都能帮助你更好地入门到进阶。
需要的兄弟可以按照这个图的方式免费获取
一、张量操作
1、创建张量
import torch
# 从列表创建
x = torch.tensor([1, 2, 3])
# 全零/全一张量
zeros_tensor = torch.zeros(2, 3) # 全零矩阵
ones_tensor = torch.ones(2, 3) # 全一矩阵
# 随机张量(标准正态分布)
rand_tensor = torch.randn(2, 3) :ml-citation{ref="4,6" data="citationList"}2、数学运算
支持逐元素运算与广播机制:
a = torch.tensor([1, 2, 3])
b = torch.tensor([4, 5, 6])
c = a + b # 逐元素相加 → tensor([5,7,9])
d = a * 2 # 标量乘法 → tensor([2,4,6])
e = torch.mm(a.unsqueeze(0), b.unsqueeze(1)) # 矩阵相乘 → tensor(32) :ml-citation{ref="4,7" data="citationList"}3、形状操作
x = torch.rand(2, 3, 4)
y = x.view(2, 12) # 改变形状(需元素总数一致)
z = x.permute(2, 0, 1) # 维度置换(原形状2x3x4 → 4x2x3) :ml-citation{ref="3,7" data="citationList"}二、自动求导(Autograd)
1、梯度追踪
通过设置 requires_grad=True 跟踪计算图:
x = torch.tensor(3.0, requires_grad=True)
y = x**2 + 2*x
y.backward() # 反向传播计算梯度
print(x.grad) # 输出导数 dy/dx → 8.0 :ml-citation{ref="5,8" data="citationList"}2、梯度清零
每次反向传播前需手动清零,避免梯度累积:
optimizer.zero_grad() # 优化器清零梯度 :ml-citation{ref="3,5" data="citationList"}三、神经网络模块(nn.Module)
1、自定义网络
class NeuralNet(torch.nn.Module):
def __init__(self):
super().__init__()
self.layer1 = nn.Linear(10, 5) # 输入10维,输出5维
self.activation = nn.ReLU()
def forward(self, x):
x = self.layer1(x)
return self.activation(x) :ml-citation{ref="3,5" data="citationList"}2、参数管理
通过 parameters() 获取所有可训练参数:
model = NeuralNet()
for param in model.parameters():
print(param.shape) # 打印各层权重维度 :ml-citation{ref="3,5" data="citationList"}四、优化器与训练流程
1、优化算法选择
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # 使用Adam优化器 :ml-citation{ref="3,5" data="citationList"}2、训练循环示例
for epoch in range(100):
outputs = model(inputs) # 前向传播
loss = criterion(outputs, labels)
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播
optimizer.step() # 参数更新 :ml-citation{ref="3,5" data="citationList"}五、数据加载与GPU加速
1、数据集加载
使用 Dataset 和 DataLoader 实现批量加载:
from torch.utils.data import DataLoader, TensorDataset
dataset = TensorDataset(features, labels)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True) :ml-citation{ref="3,4" data="citationList"}2、 GPU迁移
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model.to(device) # 模型移至GPU
inputs = inputs.to(device) # 数据移至GPU :ml-citation{ref="2,5" data="citationList"}