论文地址:BLIP
代码地址:BLIP
Abstract
视觉-语言预训练(VLP)已经提升了许多视觉-语言任务的性能。然而,大多数现有的预训练模型只在理解类任务或生成类任务中表现出色。此外,性能提升主要通过扩大从网络收集的噪声图像-文本对数据集来实现,这是一个次优的监督来源。在本文中,我们提出了BLIP,一个新的VLP框架,可以灵活地迁移到视觉-语言理解和生成任务。BLIP通过自举标题的方式有效利用噪声网络数据,其中标题生成器生成合成标题,过滤器移除噪声标题。 我们在广泛的视觉-语言任务上取得了最先进的结果,如图像-文本检索(平均recall@1提升2.7%)、图像标题生成(CIDEr提升2.8%)和视觉问答(VQA得分提升1.6%)。BLIP还展现了强大的泛化能力,可以零样本直接迁移到视频-语言任务。
!tip
这个摘要其实体现了很多当时研究的问题所在,尤其是在阅读了CLIP与VILT论文之后,存在的问题很明显:
专业化困境: 现有模型要么擅长理解(如检索),要么擅长生成(如描述),缺乏统一性
数据质量瓶颈: 依赖网络爬取的噪声数据,存在大量不准确的图像-文本配对
扩展性限制: 简单的数据量扩展并不能解决根本的数据质量问题
BLIP模型在此基础上提出了他们的解决方案:
- 统一架构: 设计了能同时处理理解和生成任务的模型架构
- 数据自举: 用模型自身来清洗和改善训练数据质量
- 双模块协作: Captioner负责生成,Filter负责筛选,形成闭环优化
Introduction
视觉-语言预训练最近在各种多模态下游任务上取得了巨大成功。然而,现有方法存在两个主要局限性:
(1) 模型视角: 大多数方法要么采用基于编码器的模型,要么采用编码器-解码器模型。然而,基于编码器的模型不太容易直接迁移到文本生成任务(如图像描述生成),而编码器-解码器模型尚未成功应用于图像-文本检索任务。
(2) 数据视角: 大多数最先进的方法在从网络收集的图像-文本对上进行预训练。尽管通过扩大数据集规模获得了性能提升,但我们的论文表明噪声网络文本对于视觉-语言学习是次优的。
为此,我们提出了BLIP:用于统一视觉-语言理解和生成的自举语言-图像预训练。 BLIP是一个新的VLP框架,能够支持比现有方法更广泛的下游任务。它分别从模型和数据角度引入了两个贡献:
(a) 多模态编码器-解码器混合架构(MED): 一种用于有效多任务预训练和灵活迁移学习的新模型架构。MED可以作为单模态编码器、图像引导的文本编码器或图像引导的文本解码器运行。该模型通过三个视觉-语言目标进行联合预训练:图像-文本对比学习、图像-文本匹配和图像条件语言建模。
(b) 标题生成与过滤(CapFilt): 一种从噪声图像-文本对中学习的新数据集自举方法。我们将预训练的MED微调为两个模块:一个标题生成器用于为网络图像生成合成标题,一个过滤器用于从原始网络文本和合成文本中移除噪声标题。
此处Claude4给出一个分析很好,也在下面补充:
!info
编码器模型的局限性:
典型代表: CLIP、ALBEF等
擅长任务: 图像-文本检索、分类等理解任务
局限性: 无法直接生成连贯的文本序列,因为缺乏自回归生成能力
具体问题: 当需要生成图像描述时,编码器只能产生固定长度的表示,无法逐词生成文本
下面是BLIP的模型架构MED,如下:
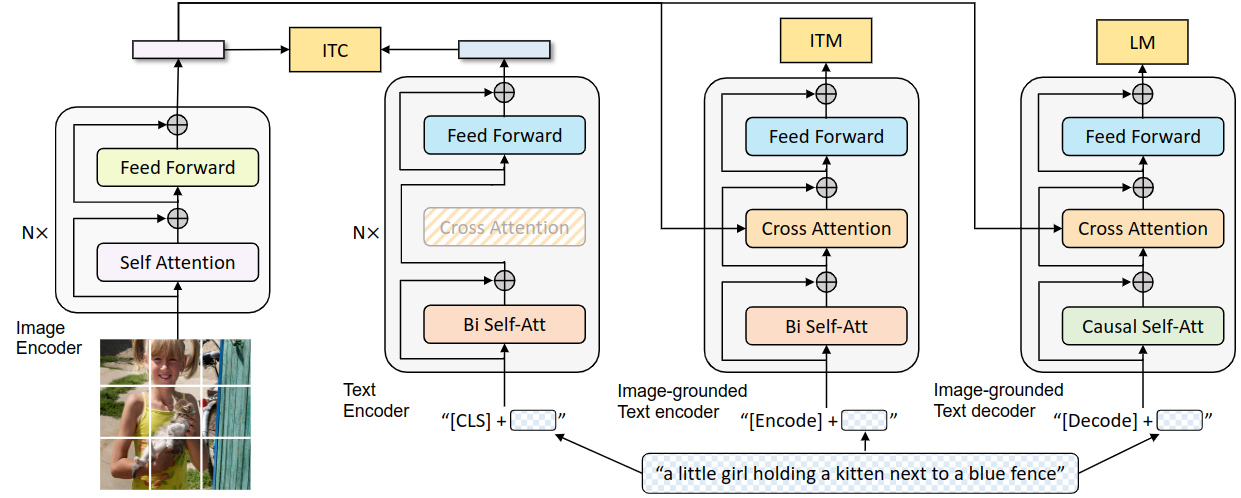
整体可以分为四个主要部分,从左到右分别为:
- 图像编码器
- 文本编码器
- 视觉文本编码器
- 视觉文本解码器
图像编码器
将文本分割为多个Patch,然后输入编码器得到image embedding,此处仍然采取的是ViT架构(遵循VILT的设计),完全不使用卷积神经网络,而是用Transformer架构进行替代。
!\[Drawing 2025-05-21 19.57.03.excalidraw\|1000]
文本编码器
图片上看的不是很真切,但是查了别的博客,这里直接使用的BERT的架构,BERT本身就是Transformer的编码器部分。大致结构如下图所示:
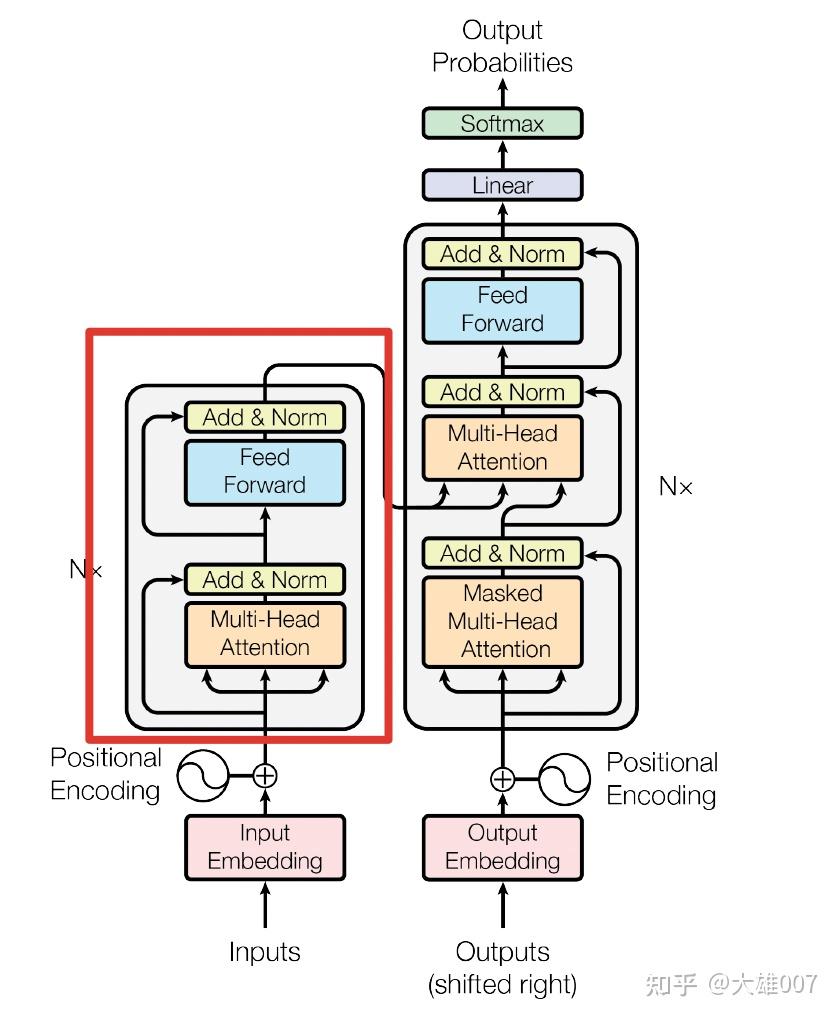
第二部分的Bi self-attention再级联前向传播的结构与论文《Attention is all you need》中的网络结构类似:
ITC损失
此处的 ITC 全称是 Image-Text Contrastive Loss(图像-文本对比损失),这是BLIP模型中三个预训练目标之一。
1. 特征提取
- 图像通过视觉编码器(Vision Transformer)得到图像特征 f v f_v fv
- 文本通过文本编码器得到文本特征 f t f_t ft
2. 相似度计算
计算图像特征和文本特征之间的余弦相似度:
s ( v , t ) = f v ⋅ f t ∣ ∣ f v ∣ ∣ ⋅ ∣ ∣ f t ∣ ∣ s(v,t) = \frac{f_v \cdot f_t}{||f_v|| \cdot ||f_t||} s(v,t)=∣∣fv∣∣⋅∣∣ft∣∣fv⋅ft
3. 对比损失公式
ITC损失包含两个方向:
图像到文本方向:
L i 2 t = − 1 N ∑ i = 1 N log exp ( s ( v i , t i ) / τ ) ∑ j = 1 N exp ( s ( v i , t j ) / τ ) L_{i2t} = -\frac{1}{N}\sum_{i=1}^{N} \log \frac{\exp(s(v_i, t_i)/\tau)}{\sum_{j=1}^{N} \exp(s(v_i, t_j)/\tau)} Li2t=−N1i=1∑Nlog∑j=1Nexp(s(vi,tj)/τ)exp(s(vi,ti)/τ)
文本到图像方向
L t 2 i = − 1 N ∑ i = 1 N log exp ( s ( v i , t i ) / τ ) ∑ j = 1 N exp ( s ( v j , t i ) / τ ) L_{t2i} = -\frac{1}{N}\sum_{i=1}^{N} \log \frac{\exp(s(v_i, t_i)/\tau)}{\sum_{j=1}^{N} \exp(s(v_j, t_i)/\tau)} Lt2i=−N1i=1∑Nlog∑j=1Nexp(s(vj,ti)/τ)exp(s(vi,ti)/τ)
总的ITC损失:
L I T C = 1 2 ( L i 2 t + L t 2 i ) L_{ITC} = \frac{1}{2}(L_{i2t} + L_{t2i}) LITC=21(Li2t+Lt2i)
其中:
- N N N是批次大小
- τ \tau τ是温度参数
- ( v i , t i ) (v_i, t_i) (vi,ti)是匹配的图像-文本对
在BLIP中,视觉文本编码器和视觉文本解码器是模型的核心组件,我来详细解释它们的实现原理和设计思路:
视觉文本编码器(Multimodal Encoder)
实现方式
输入:图像特征 + 文本特征
架构:基于BERT的Transformer编码器
关键组件:Cross Attention + Self Attention具体结构
-
输入处理:
-
图像特征:
C L S \] i m g , p a t c h 1 , p a t c h 2 , . . . , p a t c h N \] \[CLS\]_{img}, patch_1, patch_2, ..., patch_N\] \[CLS\]img,patch1,patch2,...,patchN
-
文本特征:
C L S \] t x t , t o k e n 1 , t o k e n 2 , . . . , t o k e n M \] \[CLS\]_{txt}, token_1, token_2, ..., token_M\] \[CLS\]txt,token1,token2,...,tokenM
-
拼接成:
C L S \] i m g , p a t c h e s , \[ C L S \] t x t , t o k e n s \] \[CLS\]_{img}, patches, \[CLS\]_{txt}, tokens\] \[CLS\]img,patches,\[CLS\]txt,tokens
-
-
Transformer层:
- Self Attention:处理图像和文本的联合表示
- Cross Attention:显式建模图像-文本交互
- 前馈网络:特征变换
作用
- 学习图像和文本的深层交互
- 为ITM(Image-Text Matching)任务提供融合特征
- 输出用于判断图像-文本对是否匹配
视觉文本解码器(Multimodal Decoder)
实现方式
输入:图像特征 + 部分文本序列
架构:基于GPT的Transformer解码器
关键组件:Causal Self Attention + Cross Attention具体结构
1. Causal Self Attention
- 对文本序列进行因果自注意力
- 确保生成时只能看到前面的token
- 掩码矩阵防止信息泄露
2. Cross Attention机制
python
# 伪代码示例
class CrossAttention:
def forward(self, text_hidden, image_features):
# Query来自文本特征
Q = self.query_proj(text_hidden)
# Key和Value来自图像特征
K = self.key_proj(image_features)
V = self.value_proj(image_features)
# 计算注意力
attention_weights = softmax(Q @ K.T / sqrt(d_k))
output = attention_weights @ V
return output3. 为什么需要Cross Attention
信息流向:
- Query(Q):来自当前生成的文本特征
- Key(K)和Value(V) :来自图像编码器的输出
作用机制:
- 视觉引导:文本生成过程中动态关注图像的不同区域
- 内容对齐:确保生成的文本与图像内容一致
- 细节捕获:根据生成进度关注图像的相关细节
一个需要注意的点是:相同颜色的部分是参数共享的,即视觉文本编码器和视觉文本解码器共享除 Self-Attention 层之外的所有参数。每个 image-text 在输入时,image 部分只需要过一个 ViT 模型,text 部分需要过3次文本模型。
接入前面图像编码器输出的原因
1. 分层特征利用
图像编码器输出 → 提供视觉特征基础
文本编码器输出 → 提供语言特征基础
多模态编码器 → 融合交互特征
多模态解码器 → 生成任务特征2. 信息传递路径
- 直接连接:保留原始单模态信息
- 交叉连接:建立跨模态关联
- 层次融合:从浅层到深层逐步融合
3. 任务特化设计
python
# 不同任务使用不同组件
if task == "Image-Text Retrieval":
use_unimodal_encoders() # ITC损失
elif task == "Image-Text Matching":
use_multimodal_encoder() # ITM损失
elif task == "Image Captioning":
use_multimodal_decoder() # LM损失CapFilt模块
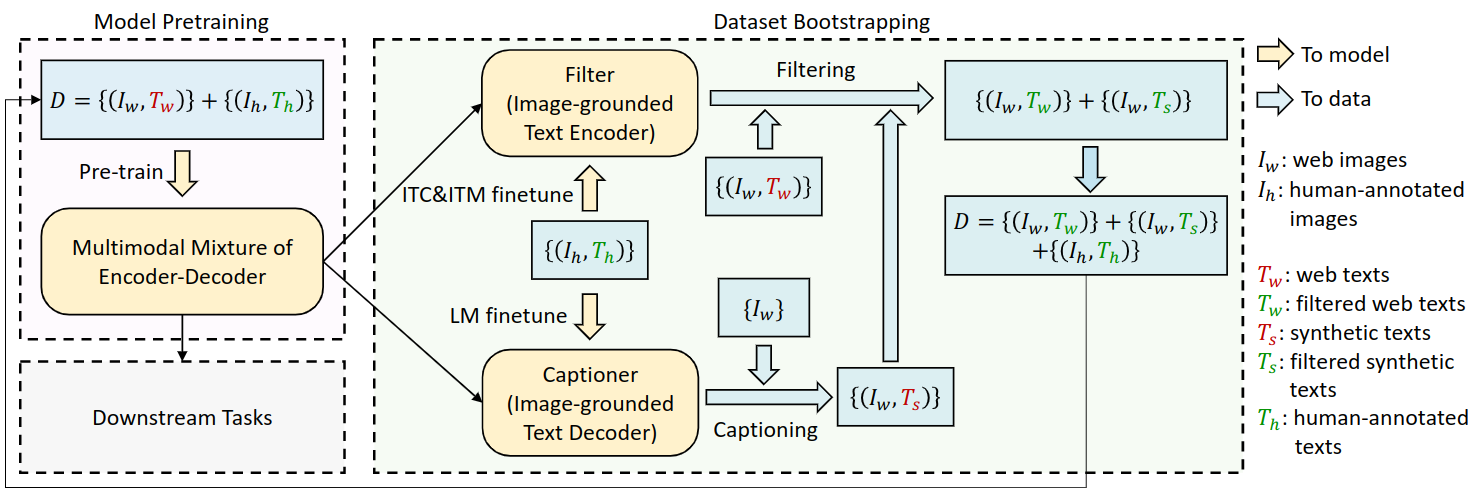
模块主要解决数据质量困境:
- 高质量人工标注数据:数量有限,如COCO数据集,标注成本极高
- 网络爬取数据:规模庞大但质量参差不齐,alt-text往往不能准确描述图像内容,存在大量噪声
核心思想
通过自举学习(Bootstrapping 的方式,利用少量高质量数据训练模型,再用训练好的模型来改善大规模网络数据的质量。
数据符号说明 - I h , T h I_h, T_h Ih,Th:人工标注的图像-文本对(高质量,小规模)
- I w , T w I_w, T_w Iw,Tw:网络爬取的图像-文本对(低质量,大规模)
- T s T_s Ts:模型生成的合成文本
- T ~ w , T ~ s T̃_w, T̃_s T~w,T~s:经过过滤的高质量文本
具体工作流程:
第一阶段:模型初始化
使用人工标注数据 I h , T h {I_h, T_h} Ih,Th → 预训练基础MED模型
第二阶段:专门化微调
从同一个预训练模型分别微调出两个专门化模块:
- Captioner(描述生成器)
本质: 图像引导的文本解码器(Image-grounded Text Decoder)
微调目标: 语言建模(LM)目标
功能: 为网络图像 I w I_w Iw生成高质量的合成描述 T s T_s Ts
训练数据: COCO等人工标注数据集 - Filter(质量过滤器)
本质: 图像引导的文本编码器(Image-grounded Text Encoder)
微调目标: ITC(图像-文本对比)+ ITM(图像-文本匹配)目标
功能: 判断图像-文本对是否匹配,过滤噪声数据
过滤标准: ITM头预测为"不匹配"的文本被视为噪声
第三阶段:数据增强与过滤
伪代码流程
python
for web_image in web_images:
# 1. 生成合成描述
synthetic_caption = captioner.generate(web_image)
# 2. 过滤原始网络文本
if filter.is_matched(web_image, original_web_text):
keep_original_text()
# 3. 过滤合成文本
if filter.is_matched(web_image, synthetic_caption):
keep_synthetic_text()第四阶段:数据集重构
最终数据集组成:
D = { I h , T h } + { I w , T ~ w } + { I w , T ~ s } D = \{I_h, T_h\} + \{I_w, T̃_w\} + \{I_w, T̃_s\} D={Ih,Th}+{Iw,T~w}+{Iw,T~s}
即:原始人工标注数据 + 过滤后的网络文本 + 过滤后的合成文本
第五阶段:模型重新预训练
使用增强后的高质量数据集D重新预训练新的BLIP模型