📖标题:Teach2Eval: An Indirect Evaluation Method for LLM by Judging How It Teaches
🌟摘要
🔸大型语言模型(LLM)的最新进展已经超过了有效评估方法的发展。传统的基准测试依赖于特定任务的指标和静态数据集,这些指标和数据集往往存在公平性问题、可扩展性有限和污染风险。
🔸本文介绍了Teach2Eval,这是一个受费曼技术启发的间接评估框架。我们的方法不是直接在预定义的任务上测试LLM,而是评估模型的多种能力,以教较弱的"学生"模型有效地执行任务。Teach2Eval通过教师生成的反馈将开放式任务转化为标准化的多项选择题(MCQ),实现了可扩展、自动化和多维的评估。我们的方法不仅避免了数据泄露和记忆,还捕捉到了与当前基准正交的广泛认知能力。
🔸26个领先LLM的实验结果表明,与现有的人类和基于模型的动态排名高度一致,同时为培训指导提供了额外的可解释性。
🛎️文章简介
🔸研究问题:当前大语言模型(LLM)评估方法存在局限性,特别是如何通过间接方式评估模型的多维能力?
🔸主要贡献:论文提出了一种新的间接评估框架Teach2Eval,通过测量教师模型指导弱学生模型的能力,来反映教师模型的综合能力。
📝重点思路
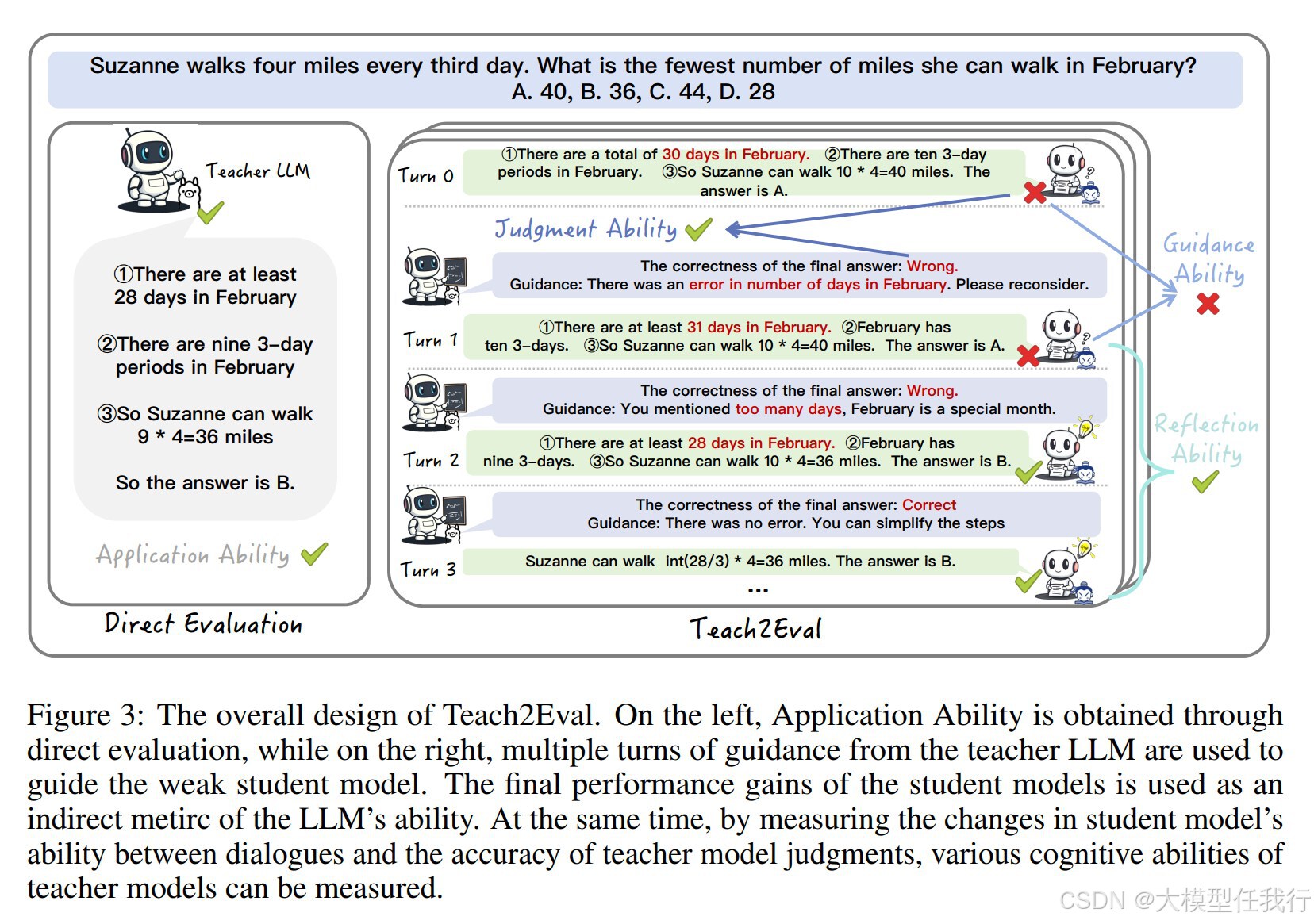
🔸设计了Teach2Eval评估框架,利用弱学生模型在教师模型指导下的表现提升作为评估标准。
🔸将开放式问题转换为多选题(MCQ)格式,以保证评估的标准化和可扩展性。
🔸构建了包含60个数据集的基准,涵盖知识、推理、理解和多语言等四个领域。
🔸通过动态指导过程,教师模型根据学生模型的历史交互提供反馈,而不接触答案选项,以确保评估的客观性。
🔸评估过程中考虑了模型的判断能力、指导能力和反思能力,形成多维度的能力分类。
🔎分析总结
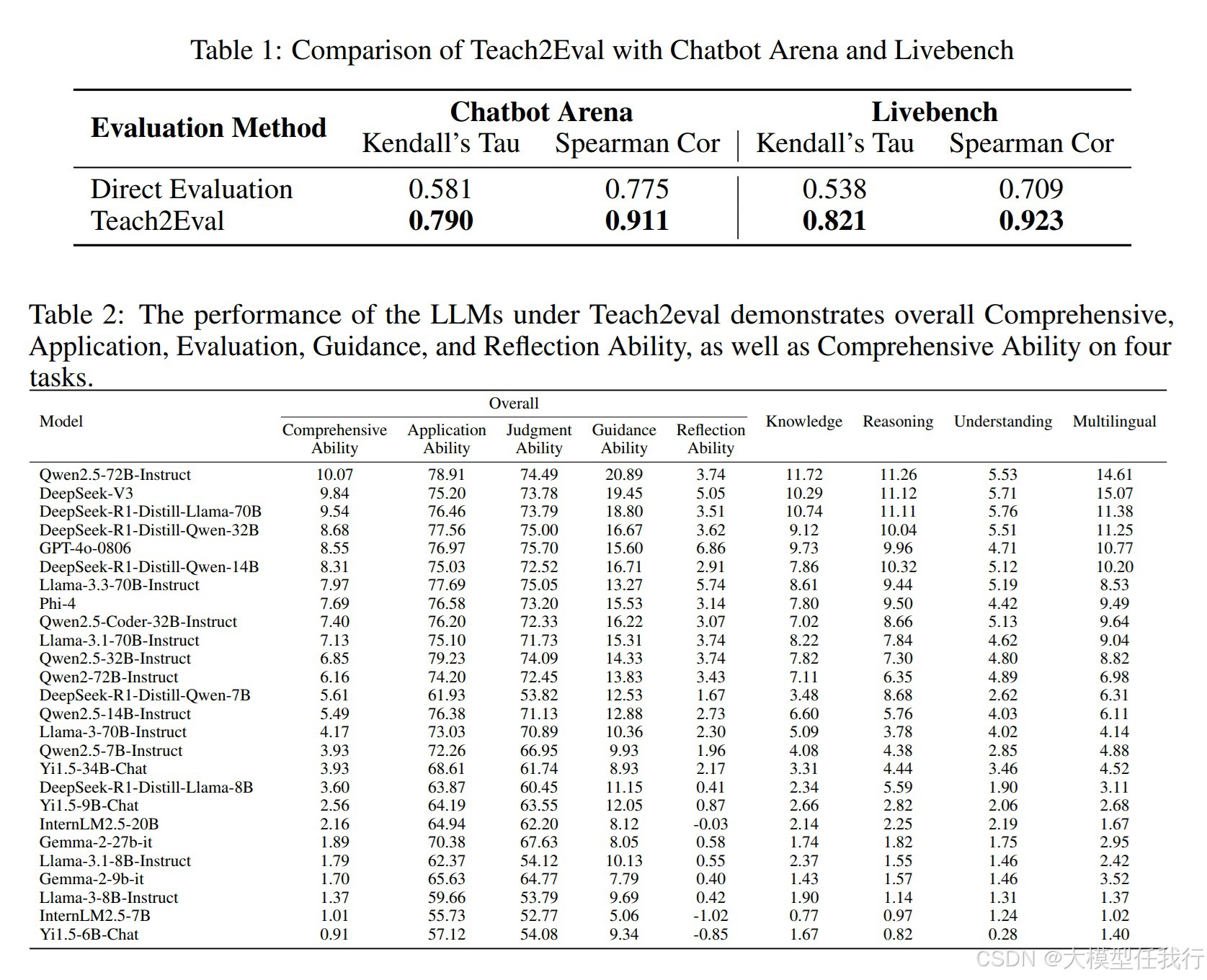
🔸实验结果显示,Teach2Eval方法与现有的评估平台(如Chatbot Arena和LiveBench)之间的结果高度一致,相关系数达到0.90以上。
🔸通过对26种最新LLM的评估,发现Teach2Eval能够有效识别并指导模型训练,提供防止过拟合的方向。
🔸模型在不同难度数据上的指导效果表现出中等难度问题更易于提升,说明教师模型的能力在不同情境下的适应性。
🔸结果表明,Teach2Eval有效缓解了数据污染问题,并能够揭示模型的真实能力,特别是在高阶能力方面。
💡个人观点
论文的创新点在于将评估视为教学过程,转化为测量教师模型指导弱学生模型的能力。
🧩附录