引言:当机器学习遇见自然语言
**自然语言处理(Natural Language Processing, NLP)**作为人工智能皇冠上的明珠,正在深刻改变人机交互的方式。从智能客服到机器翻译,从情感分析到文本生成,NLP技术的突破都建立在坚实的机器学习基础之上。本文将深入剖析机器学习核心算法,揭示这些"传统"方法在NLP领域的独特价值,为开发者构建完整的AI知识体系提供关键路径。
第一部分 机器学习基础与核心算法
1.1 机器学习方法论的三大支柱
机器学习算法可分为三大类:监督学习 通过标注数据建立输入输出映射(如分类/回归),无监督学习 发现数据内在结构(如聚类/降维),强化学习通过环境反馈优化决策策略。这三类方法构成了现代AI系统的基石。
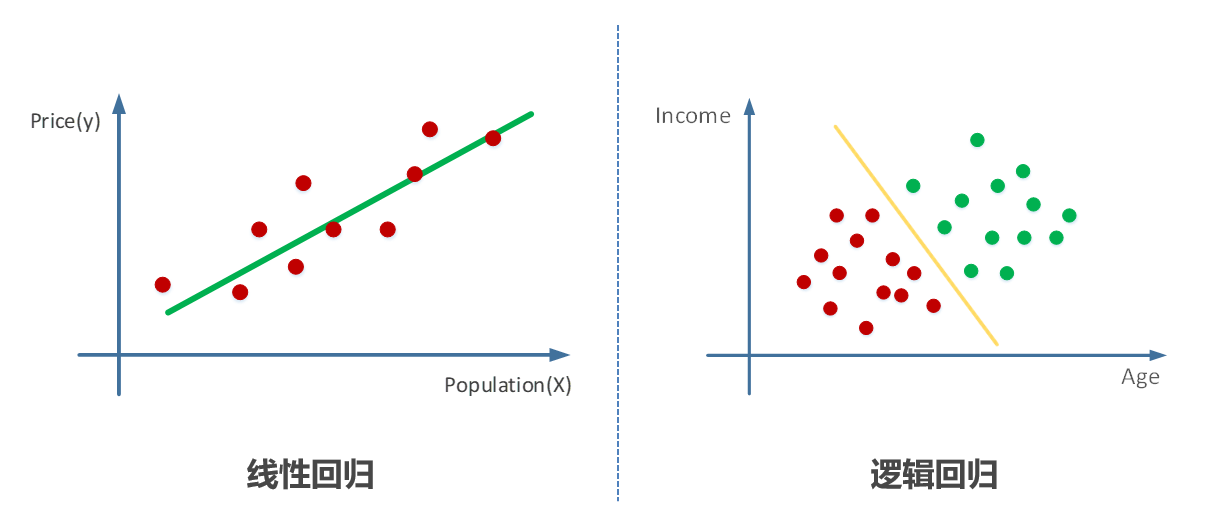
1.2 线性回归:从数学基础到特征工程

NLP应用示例:
from sklearn.linear_model import LinearRegression
from sklearn.feature_extraction.text import TfidfVectorizer
# 将文本转化为TF-IDF特征
vectorizer = TfidfVectorizer(max_features=1000)
X_train = vectorizer.fit_transform(text_data)
# 训练回归模型预测阅读难度分数
regressor = LinearRegression()
regressor.fit(X_train, readability_scores)1.3 逻辑回归:分类任务的瑞士军刀
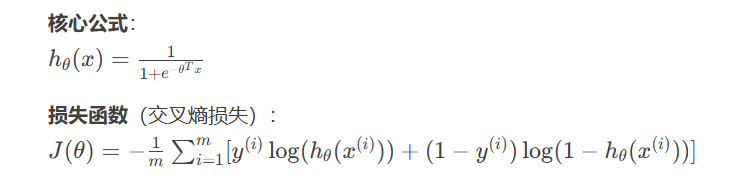
优化技巧:
-
L1/L2正则化防止过拟合
-
分类阈值调整优化召回率
文本分类实战:
from sklearn.linear_model import LogisticRegression
# 使用TF-IDF特征进行情感分类
tfidf = TfidfVectorizer(ngram_range=(1,2), max_features=5000)
X = tfidf.fit_transform(reviews)
model = LogisticRegression(class_weight='balanced')
model.fit(X_train, y_train)
# 获取特征重要性
feature_importance = pd.DataFrame({
'word': tfidf.get_feature_names_out(),
'coef': model.coef_[0]
})1.4 决策树:可解释性的典范
关键概念:
-
信息增益:IG(D_p) = I(D_p) - \\sum_{j=1}\^k \\frac{N_j}{N_p}I(D_j)
-
基尼不纯度:Gini = 1 - \\sum_{k=1}\^K p_k\^2
构建算法(ID3/C4.5/CART):
-
选择最佳分割特征
-
递归生成子节点
-
设置终止条件(最大深度、最小样本等)
NLP应用场景:
-
对话系统中的意图识别
-
结合TF-IDF特征的文本分类
-
特征选择(通过特征重要性排序)
第二部分 NLP学习的技术演进
2.1 传统NLP技术体系
典型pipeline:
原始文本 → 分词 → 去除停用词 → 词干提取 → 特征提取(TF-IDF) → 机器学习模型经典算法:
-
朴素贝叶斯:基于条件独立假设
-
支持向量机(SVM):寻找最大间隔超平面
-
隐马尔可夫模型(HMM):序列标注任务
2.2 深度学习的革命性突破
关键技术突破:
-
Word2Vec/GloVe词向量
-
LSTM/GRU时序建模
-
Transformer注意力机制
-
BERT等预训练模型
与传统方法对比:
| 维度 | 传统方法 | 深度学习方法 |
|---|---|---|
| 特征工程 | 需要人工设计 | 自动特征学习 |
| 数据需求 | 小样本有效 | 依赖大数据量 |
| 可解释性 | 高 | 较低 |
| 计算资源 | CPU即可运行 | 需要GPU加速 |
| 领域迁移能力 | 需重新设计特征 | 微调即可适应 |
第三部分 经典算法在NLP中的创新应用
3.1 集成方法的威力展现
Stacking模型示例:
from sklearn.ensemble import StackingClassifier
from sklearn.svm import SVC
# 第一层基学习器
base_models = [
('lr', LogisticRegression(C=0.1)),
('svm', SVC(kernel='linear', probability=True)),
('dt', DecisionTreeClassifier(max_depth=5))
]
# 元学习器使用逻辑回归
stack_model = StackingClassifier(
estimators=base_models,
final_estimator=LogisticRegression(),
stack_method='predict_proba'
)
# 处理文本特征
X = tfidf.transform(text_data)
stack_model.fit(X_train, y_train)3.2 特征工程的艺术
高级文本特征构建:
-
词汇多样性:\\frac{unique_words}{total_words}
-
情感词典匹配得分
-
句法复杂度(依存路径深度)
-
主题模型特征(LDA生成的分布)
混合特征实践:
import textstat
def extract_style_features(text):
return [
textstat.flesch_reading_ease(text),
textstat.dale_chall_readability_score(text),
len(text.split()),
text.count('!')
]
# 将风格特征与TF-IDF拼接
style_features = [extract_style_features(t) for t in texts]
X_combined = hstack([tfidf_features, style_features])第四部分 面向未来的思考
4.1 传统方法的现代价值
-
可解释性需求:金融、医疗等敏感领域仍需白盒模型
-
冷启动场景:新业务初期数据不足时的可靠选择
-
资源受限环境:嵌入式设备等低算力场景
4.2 融合创新的趋势
-
神经网络与传统模型的混合架构
-
预训练模型作为特征提取器
-
图神经网络与知识图谱的结合
结语:构建完整的NLP知识体系
尽管深度学习已成为NLP领域的主流方法,但经典机器学习算法仍具有不可替代的价值。理解线性回归的优化思想、逻辑回归的概率解释、决策树的特征选择机制,这些基础能力将帮助开发者在以下方面获得优势:
-
快速原型开发:在小数据场景快速验证想法
-
模型可解释性:满足监管合规要求
-
系统优化能力:定位模型瓶颈并提出改进方案
-
创新方案设计:将传统方法的优势与深度学习结合