Matlab实现LSTM-SVM时间序列预测,作者:机器学习之心
目录
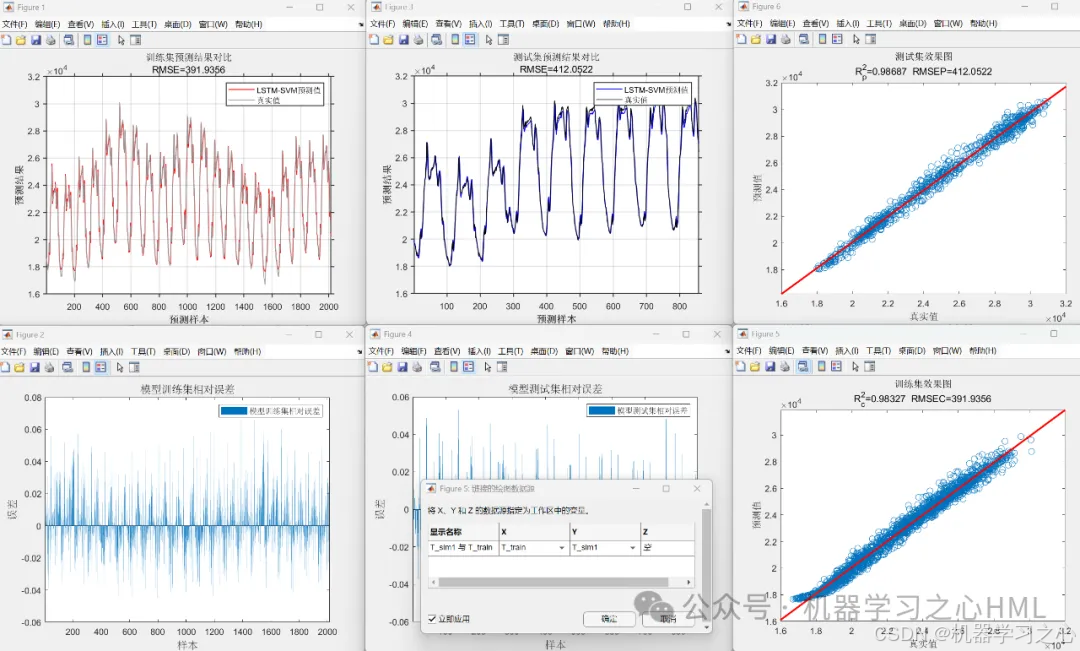
效果一览
基本介绍
该代码实现了一个结合LSTM和SVM的混合模型,用于时间序列数据的回归预测。具体功能包括:
数据预处理:划分时间窗口、归一化、划分训练集和测试集。
LSTM特征提取:构建LSTM网络提取时间序列的深层特征。
SVM回归预测:将LSTM提取的特征输入SVM模型进行训练和预测。
模型评估:计算RMSE、R²、MAE、MAPE、MBE、MSE等指标,并通过图表展示预测结果和误差分布。
算法步骤
初始化与数据导入:
清除环境变量,添加路径,导入单列时间序列数据(data.xlsx)。
数据窗口划分:
设定时间窗口参数(kim=7为历史步长,zim=1为预测步长),将数据重构为输入-输出对。
数据集划分与归一化:
按比例(num_size=0.7)划分训练集和测试集,使用mapminmax归一化数据。
LSTM模型构建与训练:
网络结构:输入层 → LSTM层(64单元) → ReLU层 → Dropout层(概率0.2) → 全连接层 → 回归层。
训练参数:Adam优化器,学习率0.001,最大迭代50次,批大小32,梯度阈值10。
LSTM特征提取:
从全连接层(fc)提取特征,作为SVM的输入。
SVM模型训练与预测:
使用libsvmtrain训练SVM(核函数为线性,参数-c 0.8 -g 100),对训练集和测试集进行预测。
反归一化与评估:
计算RMSE、R²、MAE、MAPE、MBE、MSE,绘制预测对比图、误差图及拟合效果图。
参数设定
时间序列参数:
kim=7:用7个历史时间点作为输入。
zim=1:预测下一个1个时间点的值。
数据集划分:
num_size=0.7:70%的数据作为训练集。
LSTM模型参数:
网络结构:64个LSTM单元,Dropout概率0.2。
训练选项:50个epoch,批大小32,学习率0.001,梯度阈值10。
SVM参数:
bestc=0.8(正则化参数),bestg=100(核函数参数)。
评估指标:
包含RMSE、R²、MAE、MAPE、MBE、MSE。
注意事项
版本依赖:需MATLAB 2023b及以上版本。
模型特点:LSTM用于捕获时序依赖,SVM用于增强回归性能,适合中长期时间序列预测任务。
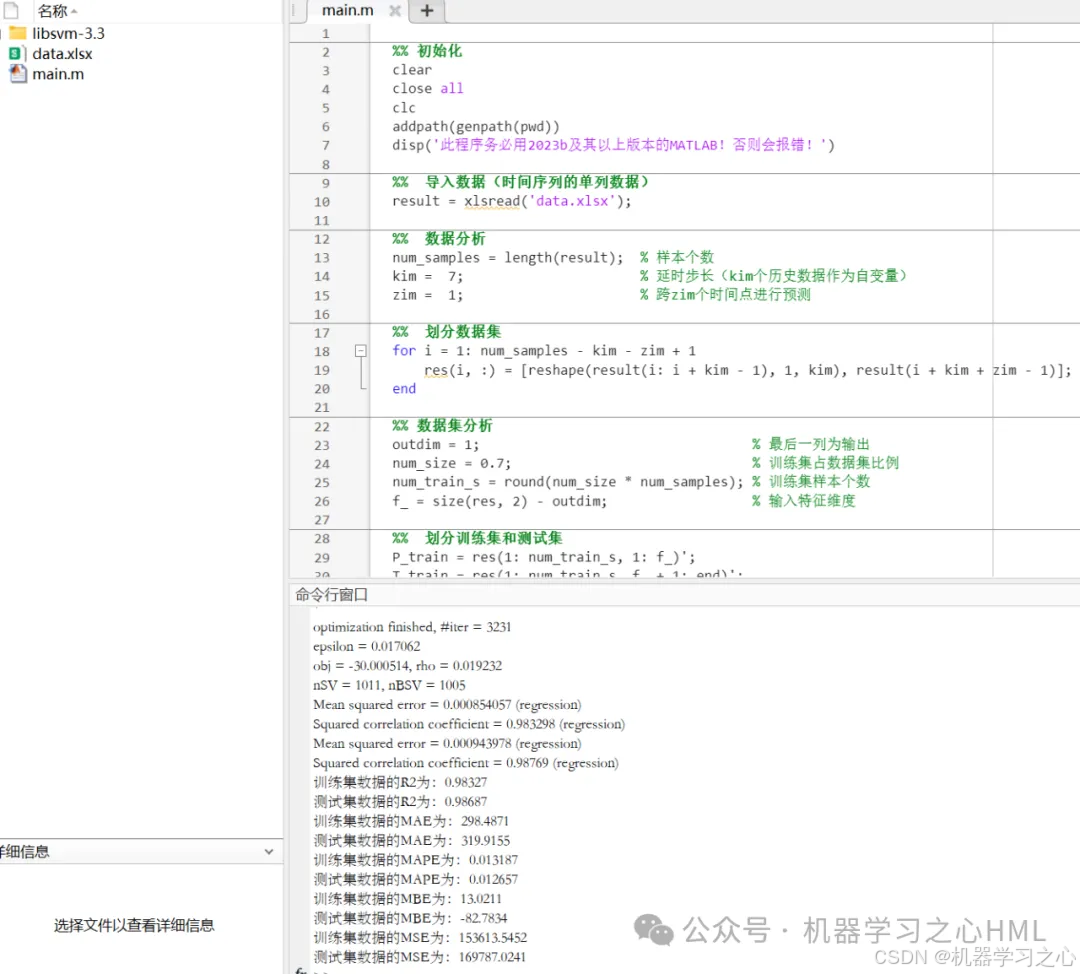
程序设计
完整源码私信回复Matlab实现LSTM-SVM时间序列预测,作者:机器学习之心
clike
.rtcContent { padding: 30px; } .lineNode {font-size: 10pt; font-family: Menlo, Monaco, Consolas, "Courier New", monospace; font-style: normal; font-weight: normal; }
%% 初始化
clear
close all
clc
addpath(genpath(pwd))
disp('此程序务必用2023b及其以上版本的MATLAB!否则会报错!')
%% 导入数据(时间序列的单列数据)
result = xlsread('data.xlsx');
%% 数据分析
num_samples = length(result); % 样本个数
kim = 7; % 延时步长(kim个历史数据作为自变量)
zim = 1; % 跨zim个时间点进行预测
%% 划分数据集
for i = 1: num_samples - kim - zim + 1
res(i, :) = [reshape(result(i: i + kim - 1), 1, kim), result(i + kim + zim - 1)];
end
%% 数据集分析
outdim = 1; % 最后一列为输出
num_size = 0.7; % 训练集占数据集比例
num_train_s = round(num_size * num_samples); % 训练集样本个数
f_ = size(res, 2) - outdim; % 输入特征维度
%% 划分训练集和测试集
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);
P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);
% 数据归一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test = mapminmax('apply', P_test, ps_input);
[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);
% 格式转换
for i = 1 : M
vp_train{i, 1} = p_train(:, i);
end
for i = 1 : N
vp_test{i, 1} = p_test(:, i);
end
%% 构建的LSTM模型
参考资料
1 https://blog.csdn.net/kjm13182345320/article/details/129215161
2 https://blog.csdn.net/kjm13182345320/article/details/128105718