简介
简介:这篇论文挑战了"GANs难以训练"的广泛观点,通过提出一个更稳定的损失函数和现代化的网络架构,构建了一个简洁而高效的GAN基线模型R3GAN。作者证明了通过合适的理论基础和架构设计,GANs可以稳定训练并达到优异性能。
论文题目:The GAN is dead; long live the GAN! A Modern Baseline GAN
会议:NeurIPS 2024
源码地址:https://www.github.com/brownvc/R3GAN
本文在调试代码的时候对代码做了一些修改,如果有遇到报错的问题可以直接复制我这篇博客修改后的代码:R3GAN利用配置好的Pytorch训练自己的数据集-CSDN博客这篇论文挑战了"GANs难以训练"的广泛观点,通过提出一个更稳定的损失函数和现代化的网络架构,构建了一个简洁而高效的GAN基线模型R3GAN。作者证明了通过合适的理论基础和架构设计,GANs可以稳定训练并达到优异性能。https://blog.csdn.net/LJ1147517021/article/details/148315781?fromshare=blogdetail&sharetype=blogdetail&sharerId=148315781&sharerefer=PC&sharesource=LJ1147517021&sharefrom=from_link
摘要:论文反驳了GANs难以训练的普遍观点,提出了一个理论有保障的现代GAN基线。首先,推导出一个良好行为的正则化相对论GAN损失函数,解决了模式丢弃和不收敛问题,并数学证明了其局部收敛性。其次,该损失函数允许丢弃所有经验性技巧,用现代架构替换常见GANs中的过时骨干网络。以StyleGAN2为例,展示了简化和现代化的路线图,产生了新的极简基线R3GAN。尽管简单,该方法在FFHQ、ImageNet、CIFAR和Stacked MNIST数据集上超越了StyleGAN2,与最先进的GANs和扩散模型相比表现优异。
模型结构
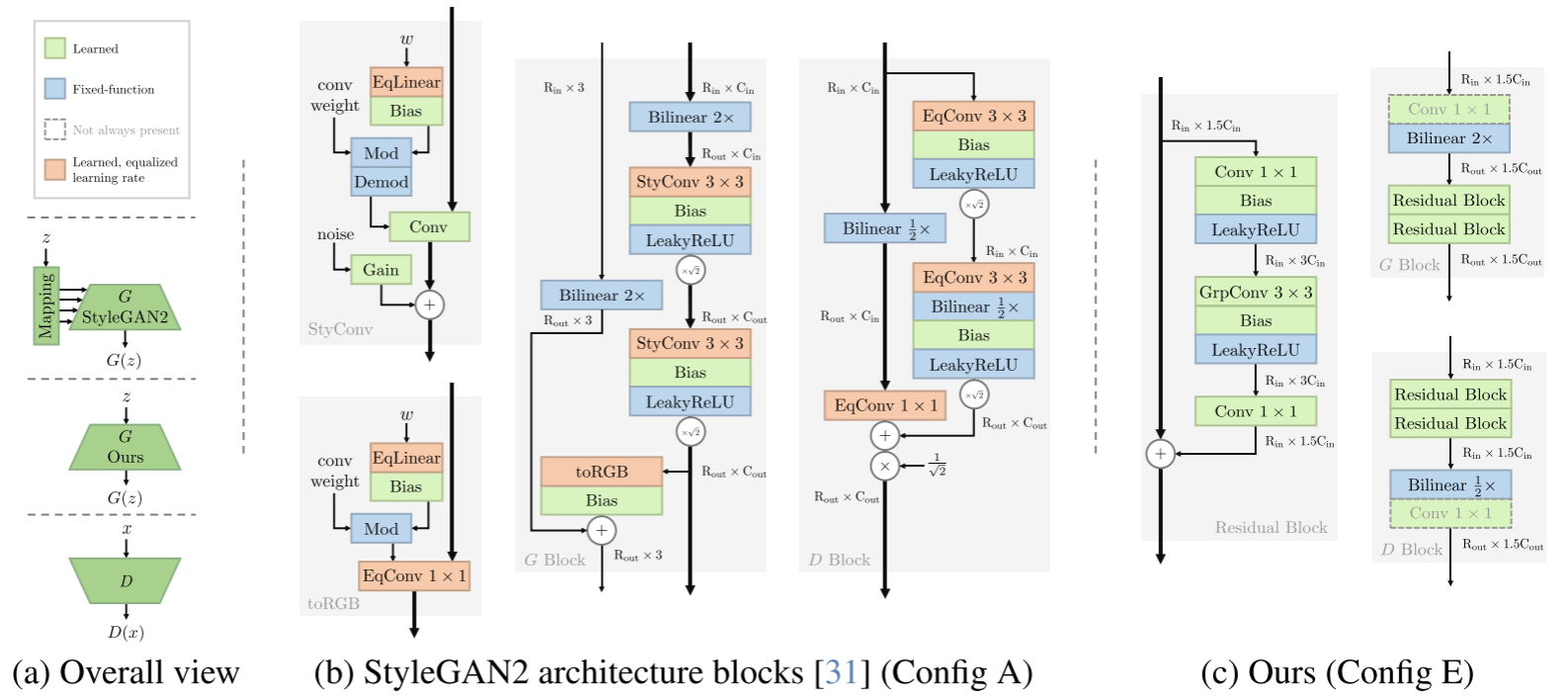
生成器架构
核心设计原则:
- 基于现代化ResNet架构,摒弃VGG-like设计
- 每个分辨率阶段包含一个过渡层和两个残差块
- 采用分组卷积和倒置瓶颈设计
关键特性:
- 无归一化层:避免批量归一化等数据相关的归一化
- Fix-up初始化:零初始化每个残差块的最后一层卷积
- 双线性插值:用于上采样,避免棋盘效应
鉴别器架构
设计特点:
- 与生成器完全对称的架构
- 相同的残差块结构和过渡层设计
- 分类器头:全局4×4深度卷积 + 线性层
损失函数
相对论配对GAN损失 (RpGAN):
L(θ,ψ) = Ef(D_ψ(G_θ(z)) - D_ψ(x))
R1正则化:
R1(ψ) = (γ/2) * E\|\|∇_x D_ψ(x)\|\|² (x~p_D)
R2正则化:
R2(θ,ψ) = (γ/2) * E\|\|∇_x D_ψ(x)\|\|² (x~p_θ)
训练自己的数据集
1. 准备数据集
首先使用 dataset_tool.py 将您的图像数据转换为适合训练的格式:
# 从文件夹创建数据集
python dataset_tool.py --source=path/to/your/images --dest=path/to/output.zip
# 如果需要调整分辨率和裁剪
python dataset_tool.py --source=path/to/your/images --dest=path/to/output.zip \
--resolution=256x256 --transform=center-crop数据集要求:
- 图像必须是正方形(如256x256, 512x512)
- 分辨率必须是2的幂次(64, 128, 256, 512, 1024等)
- 支持RGB或灰度图像
- 可以是文件夹或ZIP格式
2. 创建自定义训练配置
在 train.py 中添加您自己的预设配置。参考现有预设,在 main() 函数中添加:
if opts.preset == 'YOUR_DATASET':
# 网络架构参数
WidthPerStage = [768, 768, 768, 512, 256] # 每阶段宽度
BlocksPerStage = [2, 2, 2, 2, 2] # 每阶段块数
CardinalityPerStage = [96, 96, 96, 48, 24] # 每阶段基数
FP16Stages = [-1, -2, -3, -4] # FP16优化的阶段
NoiseDimension = 64 # 噪声维度
# 如果是条件生成(有类别标签)
if opts.cond:
c.G_kwargs.ConditionEmbeddingDimension = NoiseDimension
c.D_kwargs.ConditionEmbeddingDimension = WidthPerStage[0]
# 训练调度参数
ema_nimg = 500 * 1000 # EMA开始的图像数
decay_nimg = 2e7 # 总衰减图像数
# 各种调度器
c.ema_scheduler = { 'base_value': 0, 'final_value': ema_nimg, 'total_nimg': decay_nimg }
c.aug_scheduler = { 'base_value': 0, 'final_value': 0.3, 'total_nimg': decay_nimg }
c.lr_scheduler = { 'base_value': 2e-4, 'final_value': 5e-5, 'total_nimg': decay_nimg }
c.gamma_scheduler = { 'base_value': 2, 'final_value': 0.2, 'total_nimg': decay_nimg }
c.beta2_scheduler = { 'base_value': 0.9, 'final_value': 0.99, 'total_nimg': decay_nimg }3. 开始训练
# 无条件生成(如人脸、风景等)
python train.py \
--outdir=./training-runs \
--data=./datasets/your_dataset.zip \
--gpus=4 \
--batch=256 \
--mirror=1 \
--aug=1 \
--preset=YOUR_DATASET \
--tick=1 \
--snap=200
# 条件生成(有类别标签)
python train.py \
--outdir=./training-runs \
--data=./datasets/your_dataset.zip \
--gpus=4 \
--batch=256 \
--mirror=1 \
--aug=1 \
--cond=1 \
--preset=YOUR_DATASET \
--tick=1 \
--snap=2004. 参数说明
--gpus: GPU数量--batch: 总批次大小--mirror: 是否启用水平翻转增强--aug: 是否启用数据增强--cond: 是否训练条件模型(需要标签)--tick: 多少kimg输出一次进度--snap: 多少tick保存一次模型
5. 生成图像
训练完成后,使用保存的模型生成图像:
# 生成8张图像
python gen_images.py \
--seeds=0-7 \
--outdir=generated_images \
--network=training-runs/xxxxx-your_dataset/network-snapshot-xxxxx.pkl
# 条件生成(指定类别)
python gen_images.py \
--seeds=0-7 \
--outdir=generated_images \
--class=5 \
--network=training-runs/xxxxx-your_dataset/network-snapshot-xxxxx.pkl6. 评估指标
python calc_metrics.py \
--metrics=fid50k_full,kid50k_full \
--data=./datasets/your_dataset.zip \
--network=training-runs/xxxxx-your_dataset/network-snapshot-xxxxx.pkl7.报错指南
1.UnboundLocalError: local variable 'NoiseDimension' referenced before assignment
解决办法:在 train.py 中,NoiseDimension 只在特定的预设配置块中定义(如 CIFAR10、FFHQ-64 等)。如果您使用的 --preset 参数不匹配任何现有预设,这个变量就不会被定义,导致使用时出错。可以使用作者定义好的预先设置。
--preset=CIFAR10
--preset=FFHQ-64
--preset=FFHQ-256
--preset=ImageNet-32
--preset=ImageNet-642.RuntimeError: Could not find MSVC/GCC/CLANG installation on this computer. Check _find_compiler_bindir() in "R3GAN\torch_utils\custom_ops.py".
解决办法:这个错误是因为R3GAN使用了自定义的CUDA操作符,需要C++编译器来编译。在Windows系统上缺少MSVC/GCC/CLANG编译器。
修改 torch_utils/custom_ops.py :找到 get_plugin 函数(大约第84行),在函数开头添加:
def get_plugin(module_name, sources, headers=None, source_dir=None, **build_kwargs):
# 禁用所有自定义插件
return None
def bias_act(x, b=None, dim=1, act='linear', alpha=None, gain=None, clamp=None, impl='ref'):
# 强制使用 'ref' 实现
impl = 'ref'