文章目录
- 一、摘要
- 二、挑战
- 三、Method
-
- [3.1 前置知识](#3.1 前置知识)
-
- [3.1.1 预训练SD ×4 Upscaler](#3.1.1 预训练SD ×4 Upscaler)
- [3.1.2 Inflated 2D Convolution 扩展2D卷积](#3.1.2 Inflated 2D Convolution 扩展2D卷积)
- [3.2 Local Consistency within Video Segments 视频片段中的一致性](#3.2 Local Consistency within Video Segments 视频片段中的一致性)
-
- [3.2.1 微调时序U-Net](#3.2.1 微调时序U-Net)
- [3.2.2 微调时序VAE-Decoder](#3.2.2 微调时序VAE-Decoder)
- [3.3 跨片段的全局一致性 Global Consistency cross Video Segments](#3.3 跨片段的全局一致性 Global Consistency cross Video Segments)
-
- [3.3.1 无训练的递归隐码传播 Training-Free Recurrent Latent Propagation](#3.3.1 无训练的递归隐码传播 Training-Free Recurrent Latent Propagation)
- [3.4 Inference with Additional Conditions](#3.4 Inference with Additional Conditions)
- 四、实验设置
-
- [4.1 数据集](#4.1 数据集)
- 贡献总结
论文全称: Upscale-A-Video: Temporal-Consistent Diffusion Model for Real-World Video Super-Resolution
代码路径: https://github.com/sczhou/Upscale-A-Video
更多RealWolrd VSR整理在 https://github.com/qianx77/Video_Super_Resolution_Ref
一、摘要
基于文本的扩散模型在生成和编辑方面表现出了显著的成功,显示出利用其生成先验增强视觉内容的巨大潜力。然而,由于对输出逼真度和时间一致性的高要求,将这些模型应用于视频超分辨率仍然具有挑战性,而这一点又因扩散模型固有的随机性而变得更加复杂。我们的研究引入了Upscale-A-Video,一种用于视频上采样的文本引导的潜在扩散方法。该框架通过两个关键机制确保时间一致性:局部上,它将时间层集成到U-Net和VAE-解码器中,保持短序列内的一致性;全局上,在不进行训练的情况下,引入了一个流引导的递归潜在传播模块,通过在整个序列中传播和融合潜在信息来增强整体视频的稳定性。得益于扩散范式,我们的模型还提供了更大的灵活性,允许文本提示引导纹理生成,并通过可调节的噪声水平平衡修复与生成,从而实现逼真度与生成质量之间的权衡。大量实验表明,Upscale-A-Video在合成和现实世界基准测试中,以及在人工智能生成的视频中,都超过了现有的方法,展现出令人印象深刻的视觉真实感和一致性。
二、挑战
扩散去噪过程由于其固有的随机特性,在应用于视频任务时面临重大挑战。这些挑战包括时间不稳定性和闪烁伪影的出现,这在涉及较长视频序列的VSR任务中尤为明显。这些任务的复杂性不仅在于实现局部片段内的一致性,还在于在整个视频中保持连贯性。
三、Method
3.1 前置知识
3.1.1 预训练SD ×4 Upscaler
使用预训练SD ×4 Upscaler,扩散的优化目标,UNet预测噪声
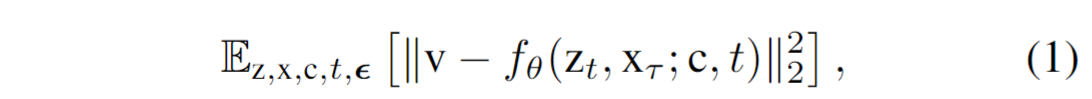
3.1.2 Inflated 2D Convolution 扩展2D卷积
要将2D扩散模型用在视频任务上,需要将2D卷积扩展到3D卷积,增加额外的时间层(temporal layers),目标是继承单帧图像生成能力,增加时序连续性。
3.2 Local Consistency within Video Segments 视频片段中的一致性
其他方法:3D convolutions、temporal attention、cross-frame attention保证时序一致性
3.2.1 微调时序U-Net
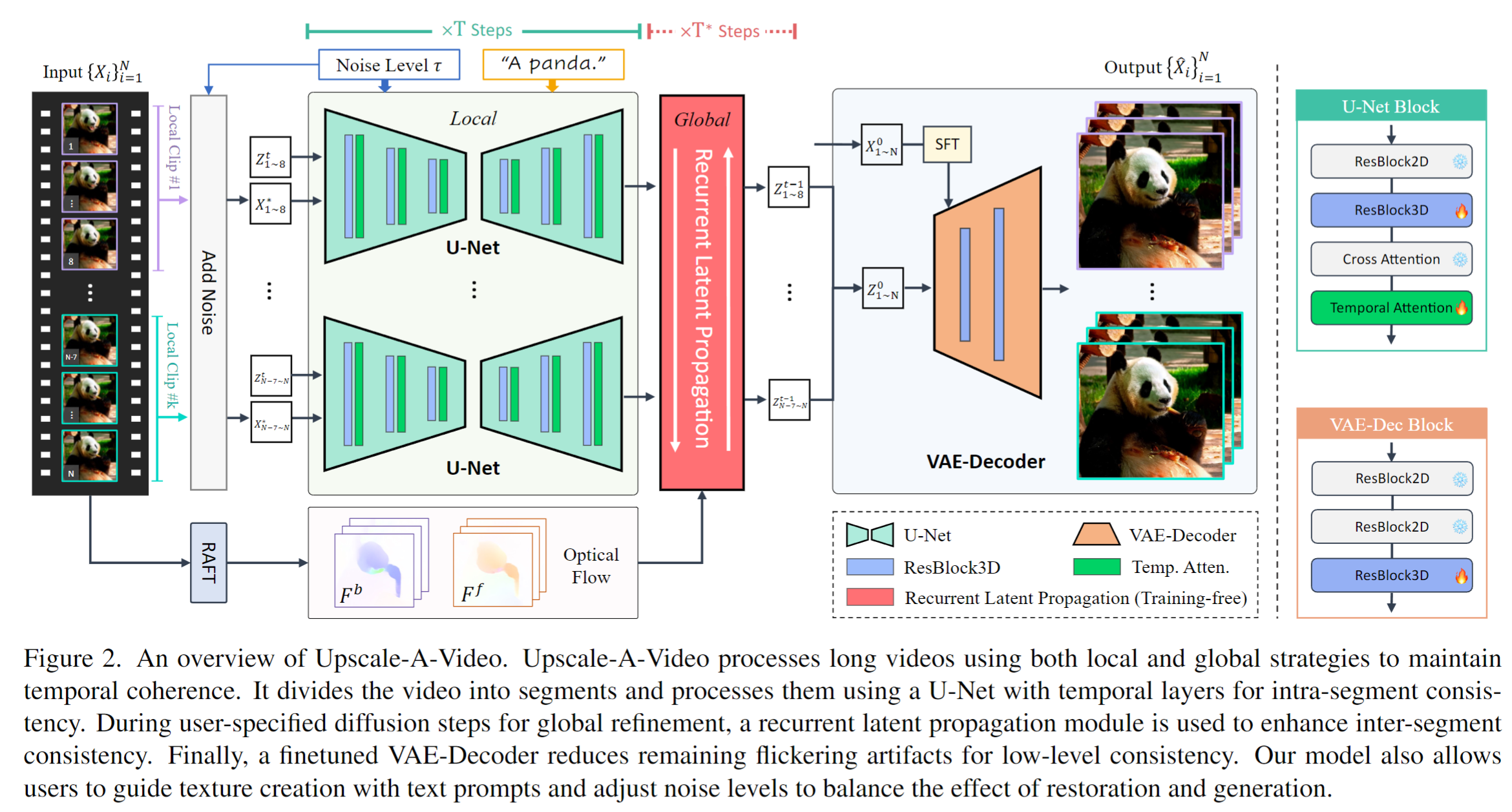
如图2所示,
1、增加基于3D卷积的3D residual blocks作为时序层,插入预训练空间层中
2、时间注意力层沿时间维度执行自注意力,并关注所有局部帧。
3、加入了旋转位置嵌入(RoPE)60,以便为模型提供时间的位置信息。
4、训练时候冻结2D结构的参数,保证单帧的生成效果
3.2.2 微调时序VAE-Decoder
如图2所示
1、同样加入3D residual blocks保证低级尺度的一致性
2、从输入通过Spatial Feature Transform (SFT)模块引入到VAE-Decoder第一层
3、同样只训练新添加的时序3D结构
4、损失函数用到L1 loss、 LPIPS perceptual loss 、 adversarial loss
3.3 跨片段的全局一致性 Global Consistency cross Video Segments
片段内一致性可以满足了,但是跨片段的一致性还是个问题,需要引入其他方式
3.3.1 无训练的递归隐码传播 Training-Free Recurrent Latent Propagation
1、RAFT计算光流optical flow
还需要计算有效区域,误差函数
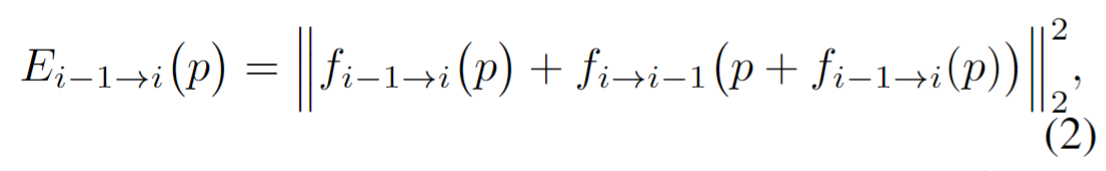
示意图如下

通过光流来更新掩码
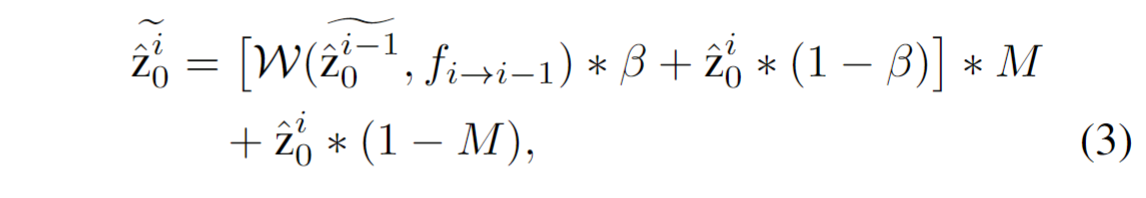
M是有效区域,β是光流信息的利用程度,通过选择默认值0.5
在推断过程中,并不需要在每个扩散步骤中应用此模块。相反,我们可以选择 T ∗ 步骤进行潜在传播和聚合。在处理轻微的视频抖动时,可以选择在扩散去噪过程中较早整合此模块,而对于严重的视频抖动,例如 AIGC 视频,最好在去噪过程的后期执行此模块。(为什么?)
3.4 Inference with Additional Conditions
调整文本提示和噪声水平的附加条件,以影响去噪扩散过程。
四、实验设置
4.1 数据集
1、subset of WebVid10M 335k 分辨率336×596
2、YouHQ dataset
3、额外增加的高质量数据集 large-scale high-definition (1080 × 1920) dataset from YouTube, containing around 37K video clips
LQ采用RealBasicVSR
贡献总结
1、局部一致性和全局一致性