在医学图像分割领域,传统卷积神经网络(CNNs)受限于局部感受野,难以捕捉长距离依赖关系,而基于 Transformer 的模型因自注意力机制的二次计算复杂度,在处理高分辨率图像时效率低下。近年来,状态空间模型(SSMs)如 Mamba 展现出线性复杂度建模长序列的优势,其视觉变体 Vision Mamba(VMamba)通过引入二维选择性扫描机制,进一步提升了在图像任务中的全局特征提取能力。VSS Block 作为 VMamba 的核心组件,旨在解决传统模型在全局上下文建模与计算效率之间的矛盾,为医学图像分割提供更优的特征表达方案。
上面是原模型,下面是改进模型
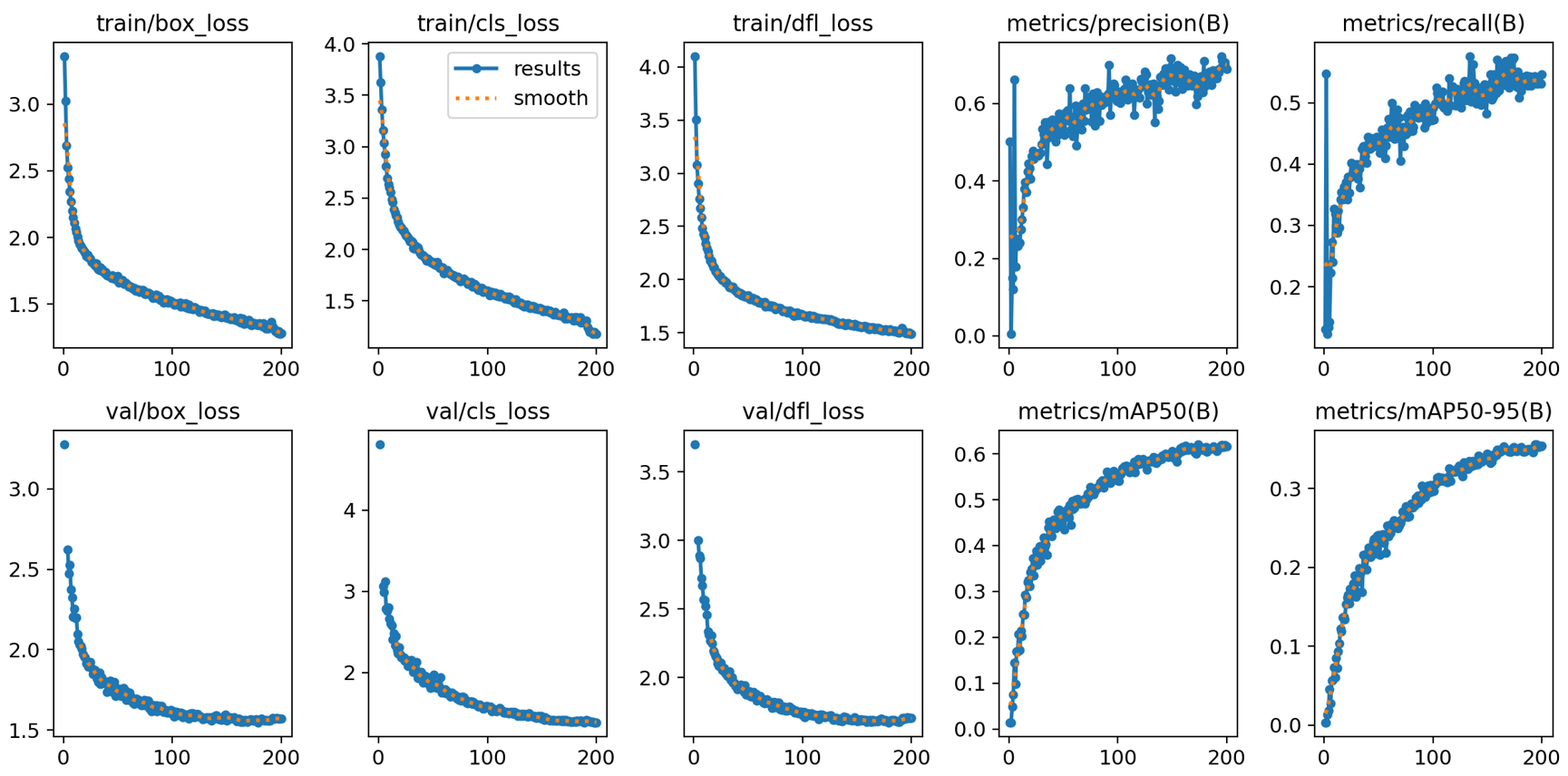
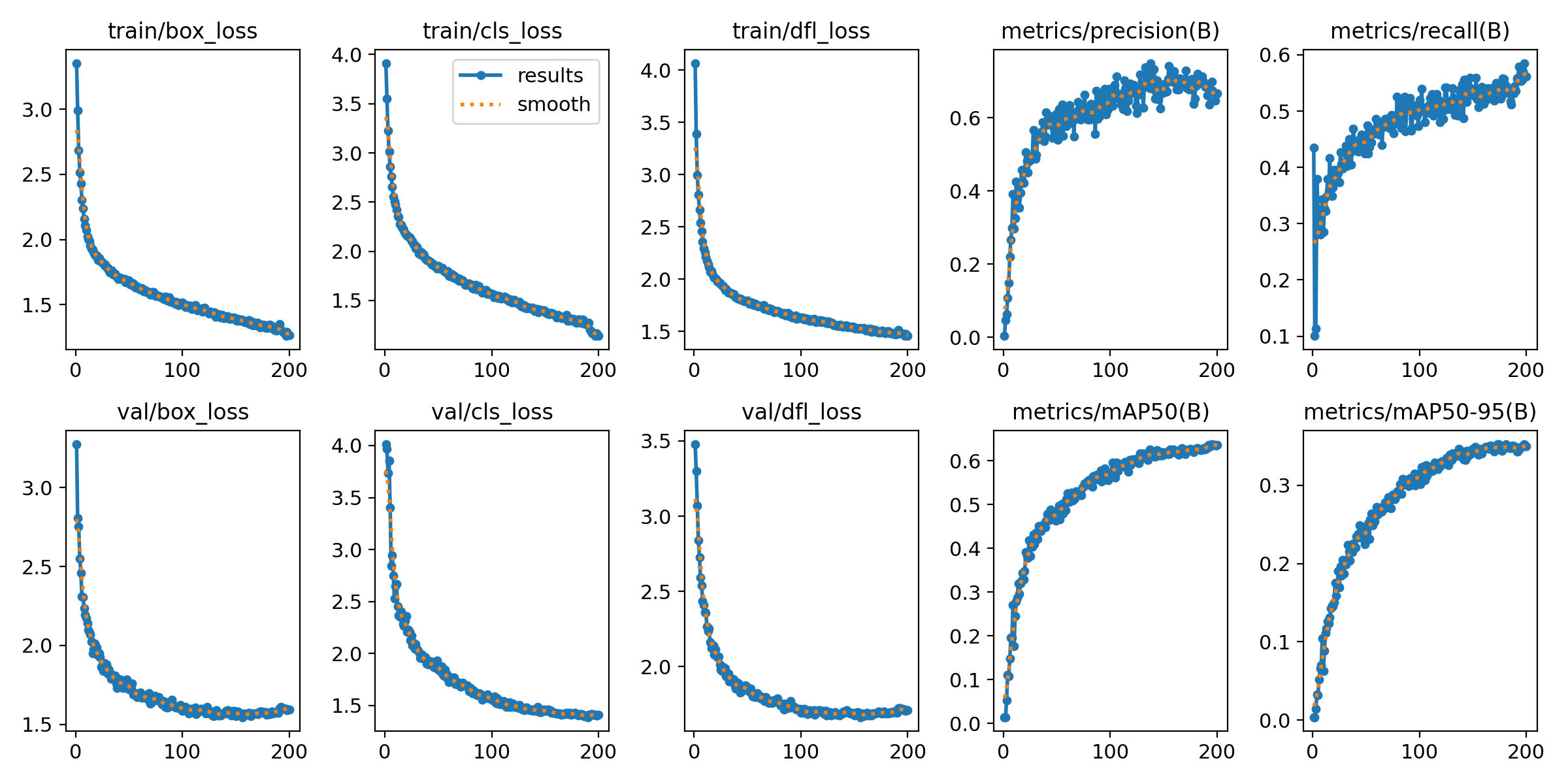
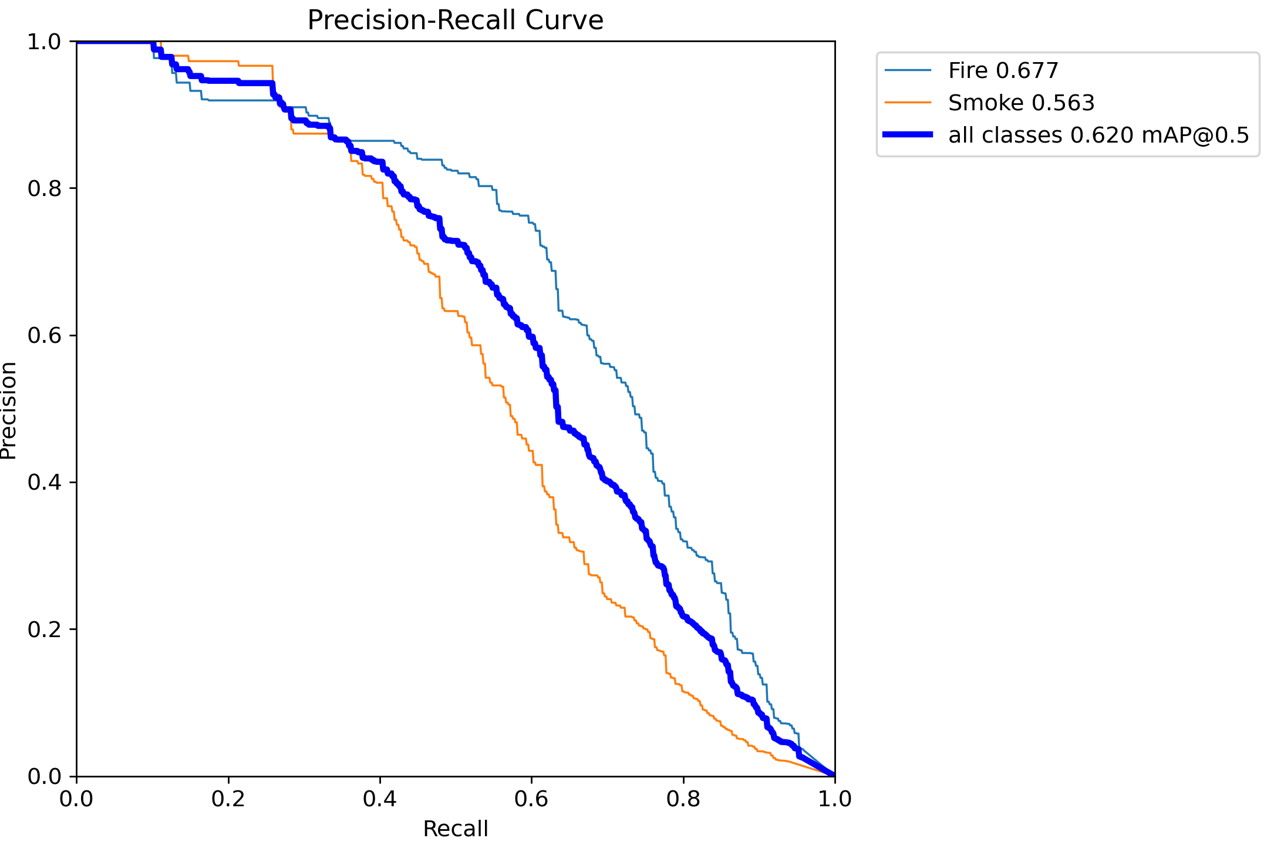
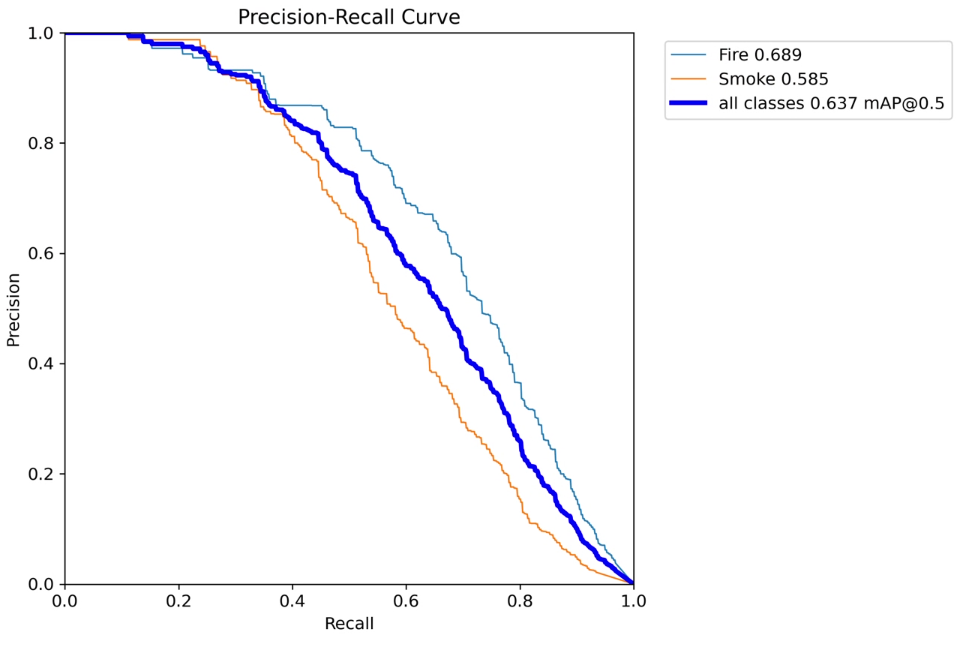
1. 视觉状态空间模块VSS Block介绍
VSS Block 基于状态空间模型的离散化理论,通过线性常微分方程(ODE)建模动态系统,并通过时间尺度参数 Δ 将连续系统转化为离散序列处理。其核心模块 2D 选择性扫描(SS2D)借鉴结构化状态空间模型(S4)的多方向扫描策略,将二维图像沿水平、垂直、对角线等方向展开为一维序列,利用选择性机制(如 S6 操作)实现线性时间复杂度的全局特征提取。同时,结合 SiLU 激活函数的非线性变换与特征融合策略,VSS Block 能够动态聚焦关键区域,增强模型对复杂图像结构的适应性。
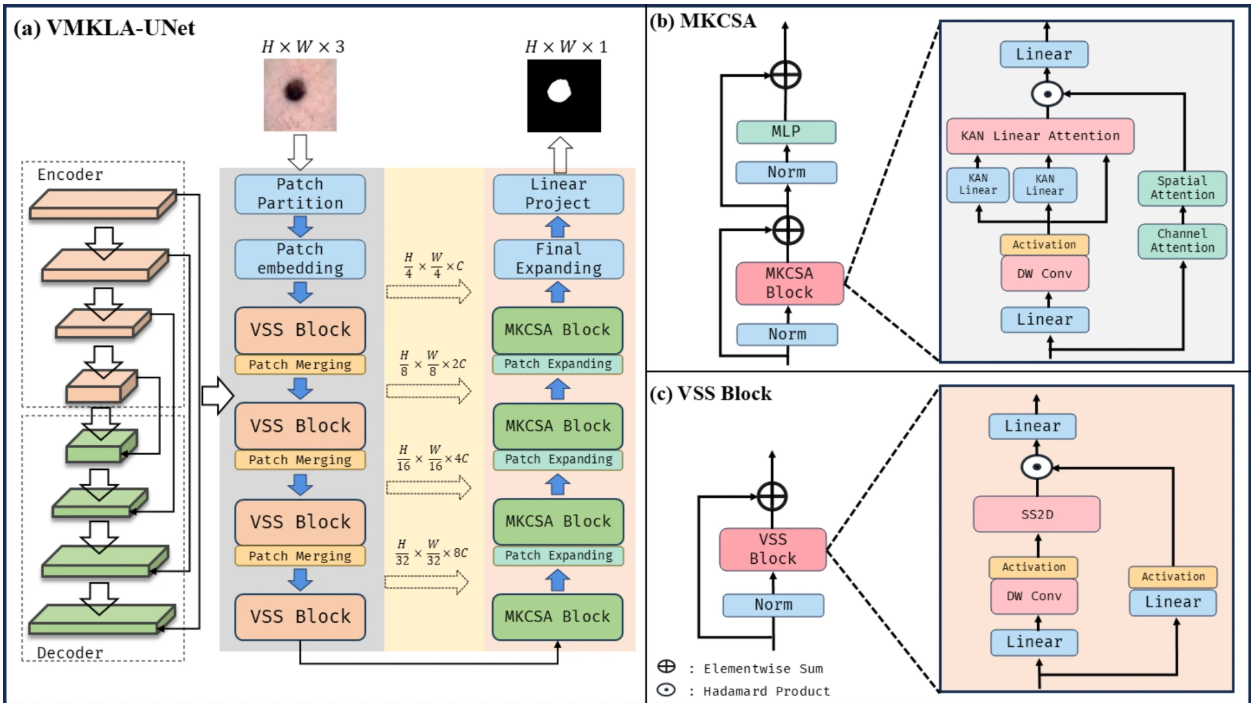
VSS Block 采用双分支并行架构(如图 2.c 所示):
主分支:输入图像经线性嵌入后,通过 3×3 深度卷积提取局部特征,再由 SS2D 模块进行四方向扫描,捕捉全局上下文,经层归一化后输出结构化特征。
副分支:直接对线性嵌入结果应用 SiLU 激活函数,保留原始特征的非线性响应。
特征融合:主副分支输出通过逐元素相乘(Hadamard Product)结合,生成最终特征图,实现全局结构信息与局部细节的互补。
2. YOLOv12与 视觉状态空间模块VSS Block的结合
将 VSS Block 插入 YOLO12 中,其双向状态空间模型与多方向扫描机制可高效捕捉图像全域上下文及多尺度细节 ,增强对复杂场景中目标的特征表征能力,尤其提升小目标检测精度;结合线性计算与动态注意力设计,在轻量化基础上优化特征跨层融合效率,助力 YOLO12 实现更快速精准的多目标定位与分类。
3. 视觉状态空间模块VSS Block代码部分
YOLO12模型改进方法,快速发论文,总有适合你的改进,还不改进上车_哔哩哔哩_bilibili
YOLO12 改进|融入 Mamba 架构 助你轻松发三四区论文_哔哩哔哩_bilibili
更多代码: YOLOv8_improve/YOLOV12.md at master · tgf123/YOLOv8_improve · GitHub
4. 将视觉状态空间模块VSS Block引入到YOLOv12中
第一: 先新建一个v12_changemodel,将下面的核心代码复制到下面这个路径当中,如下图如所示。E:\Part_time_job_orders\YOLO_NEW\YOLOv12\ultralytics\v12_changemodel。

第二:在task.py中导入 包
第三:在task.py中的模型配置部分下面代码
第四:将模型配置文件复制到YOLOV12.YAMY文件中
第五:运行代码
python
from ultralytics.models import NAS, RTDETR, SAM, YOLO, FastSAM, YOLOWorld
if __name__=="__main__":
# 使用自己的YOLOv12.yamy文件搭建模型并加载预训练权重训练模型
model = YOLO(r"E:\Part_time_job_orders\YOLO_NEW\YOLOv12\ultralytics\cfg\models\12\yolo12_VMKLA.yaml")\
.load(r'E:\Part_time_job_orders\YOLO_NEW\YOLOv12\yolo12n.pt') # build from YAML and transfer weights
results = model.train(data=r'E:\Part_time_job_orders\YOLO\YOLOv12\ultralytics\cfg\datasets\VOC_my.yaml',
epochs=300,
imgsz=640,
batch=64,
# cache = False,
# single_cls = False, # 是否是单类别检测
# workers = 0,
# resume=r'D:/model/yolov8/runs/detect/train/weights/last.pt',
amp = True
)