映射:详解 _source & store 字段
- [1._source 字段](#1._source 字段)
-
- [1.1 特点](#1.1 特点)
- [1.2 示例](#1.2 示例)
- [2.store 字段](#2.store 字段)
-
- [2.1 特点](#2.1 特点)
- [2.2 示例](#2.2 示例)
- 3.两者对比
-
- [3.1 使用建议](#3.1 使用建议)
- [3.2 实际应用示例](#3.2 实际应用示例)
1._source 字段
_source 是 Elasticsearch 中一个特殊的元字段,它存储了文档在索引时的原始 JSON 内容。
1.1 特点
- 默认启用 :所有文档都会自动存储原始 JSON 数据在
_source中。 - 完整存储:保存文档的完整原始结构。
- 重要用途 :
- 返回搜索结果中的原始文档内容。
- 支持高亮显示。
- 支持重新索引操作。
- 支持更新文档(因为需要原始内容)。
1.2 示例
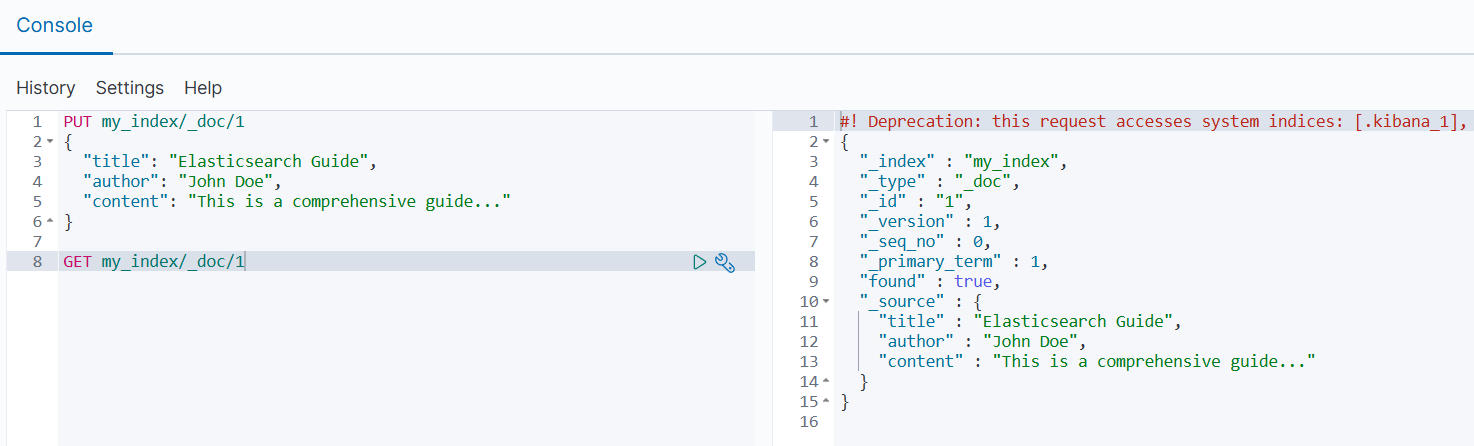
json
PUT my_index/_doc/1
{
"title": "Elasticsearch Guide",
"author": "John Doe",
"content": "This is a comprehensive guide..."
}
GET my_index/_doc/1返回结果中会包含完整的 _source 内容。
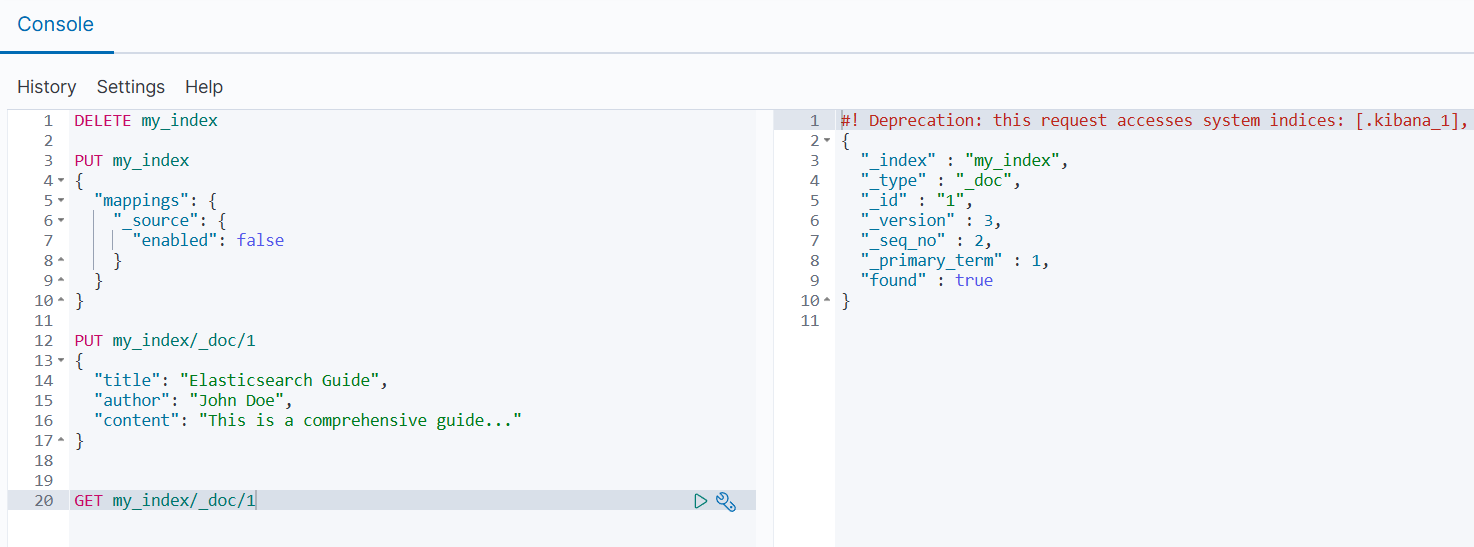
禁用 _source。
json
PUT my_index
{
"mappings": {
"_source": {
"enabled": false
}
}
}禁用后无法获取原始文档内容,且某些功能将不可用。
2.store 字段
store 是字段级别的属性,决定是否将字段值单独存储在 Lucene 中(独立于 _source)。
2.1 特点
- 默认关闭:大多数情况下不需要单独存储字段。
- 特定场景使用 :
- 当只需要检索个别字段,而不需要整个
_source时。 - 当
_source被禁用,但仍需要某些字段时。
- 当只需要检索个别字段,而不需要整个
- 存储方式:以列式存储,单独存储。
2.2 示例
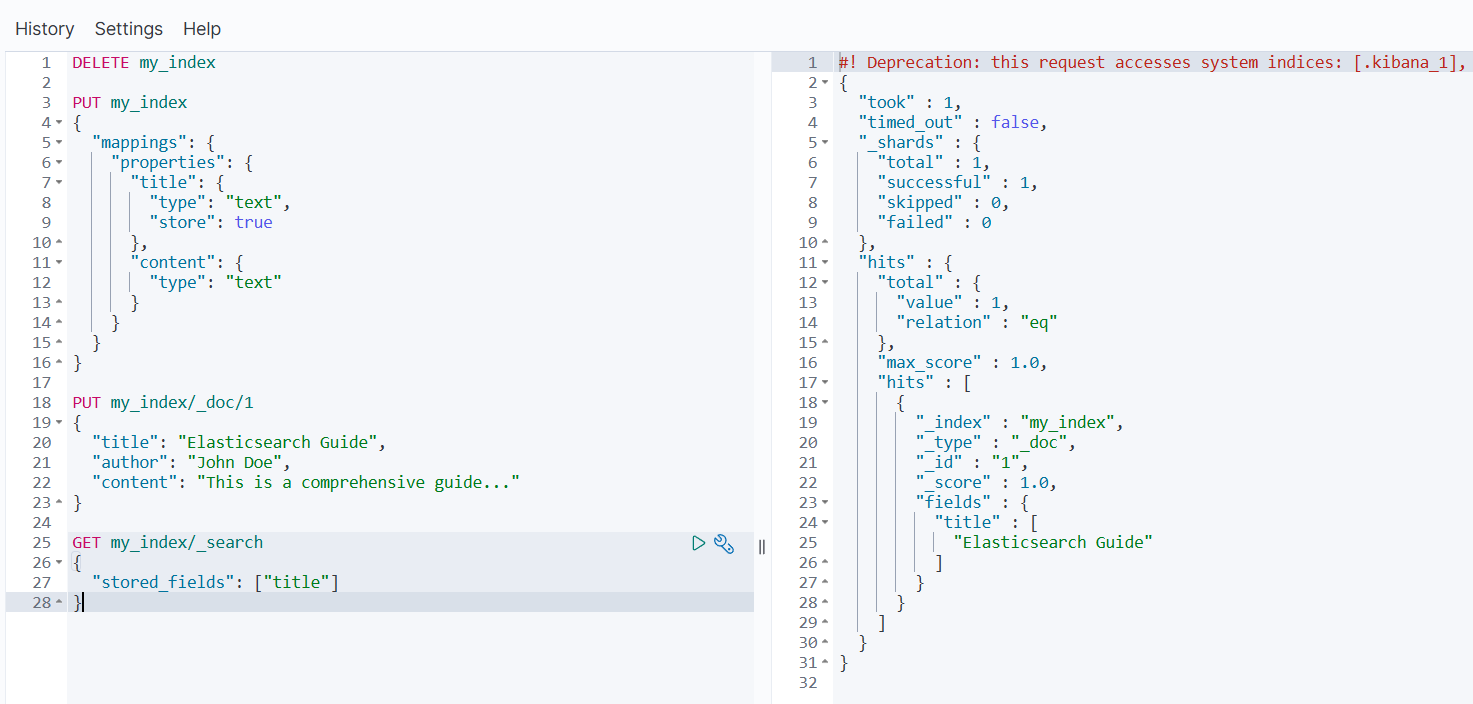
json
PUT my_index
{
"mappings": {
"properties": {
"title": {
"type": "text",
"store": true
},
"content": {
"type": "text"
}
}
}
}检索存储字段。
json
GET my_index/_search
{
"stored_fields": ["title"]
}
3.两者对比
| 特性 | _source 字段 |
store 属性 |
|---|---|---|
| 存储级别 | 文档级(整个原始文档) | 字段级(单个字段) |
| 默认值 | 启用 | 禁用 |
| 存储方式 | 原始 JSON | 单独列式存储 |
| 主要用途 | 获取完整文档、重新索引、更新等操作 | 高效检索特定字段 |
| 存储开销 | 较高(存储完整文档) | 较低(只存储指定字段) |
| 检索方式 | 通过 _source 获取 |
通过 stored_fields 获取 |
3.1 使用建议
- 大多数情况 :保持
_source启用,不需要设置store: true。 - 禁用
_source时 :对需要检索的字段设置store: true。 - 性能优化:当文档很大但只需要少量字段时,可考虑存储特定字段。
- 注意:存储字段会增加索引大小,应谨慎使用。
3.2 实际应用示例
json
PUT news_articles
{
"mappings": {
"_source": {
"enabled": true
},
"properties": {
"headline": {
"type": "text",
"store": true
},
"body": {
"type": "text"
},
"publish_date": {
"type": "date",
"store": true
}
}
}
}这样设计可以:
- 通过
_source获取完整文章内容。 - 快速单独访问
headline和publish_date字段(如用于列表展示)。 body内容只通过_source获取,减少存储开销。