一、引言:为什么测试工程师需要关注RAG?
作为一名测试工程师,你是否遇到过以下场景?
- 需要快速验证文档中某个关键数据的准确性
- 想通过自动化工具提取测试用例中的关键信息
- 希望构建智能问答系统辅助测试需求分析
RAG(检索增强生成)技术恰好能解决这些问题!本文将以电影《肖申克的救赎》为案例,手把手教你使用LangChain框架构建一个完整的RAG系统,通过代码实战展示如何将静态文档转化为可交互的知识库。需提取申请好deepseek的api-key及阿里的通义千问的api-key。本文使用deepseek作为chat大模型,通义千问的text-embedding-v2作为嵌入式模型。与项目源码同目录创建.env,内容如下图所示。

二、技术架构解析
1. 核心组件
| 模块 | 技术选型 | 作用 |
|---|---|---|
| 文档处理 | PyPDFLoader | 加载PDF文档 |
| 文本分割 | RecursiveCharacterTextSplitter | 将文档切分为可检索片段 |
| 向量生成 | DashScopeEmbeddings | 将文本转化为向量表示 |
| 向量存储 | ChromaDB | 构建语义索引 |
| 大模型 | DeepSeek-Chat | 生成最终回答 |
| 框架 | LangChain | 统一工作流编排 |
三、实战步骤详解
1. 环境准备
bash
pip install langchain langchain_community langchain_core
pip install deepseek-ai dashscope chromadb2. 关键代码解析
(1)文档加载与分割
python
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("shrek_redemption.pdf")
documents = loader.load()
# 分片策略:500字/块,50字重叠
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50
)
docs = text_splitter.split_documents(documents)文档内容:

(2)向量化存储
python
from langchain_community.embeddings import DashScopeEmbeddings
embed_model = DashScopeEmbeddings(
model="text-embedding-v2",
dashscope_api_key=os.getenv("DASHSCOPE_API_KEY")
)
chroma = chromadb.PersistentClient(path='./chroma_db')
collection = chroma.get_or_create_collection(
name='shrek_docs3',
metadata={"hnsw:space":"cosine"}
)
db = Chroma(
client=chroma,
collection_name='shrek_docs3',
embedding_function=embed_model
)
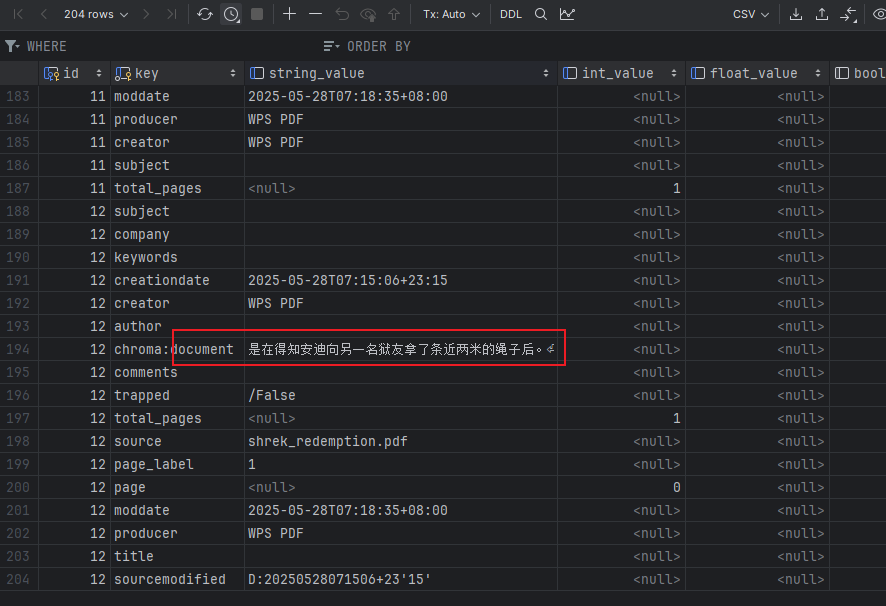
db.add_documents(docs)向量数据库初始化后如图所示:
文档向量化后存入到向量数据库中。
(3)构建RAG链
python
from langchain import hub
prompt = hub.pull("rlm/rag-prompt")
rag_chain = (
{"context": retriever | (lambda docs: "\n\n".join(doc.page_content for doc in docs)),
"question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)效果:
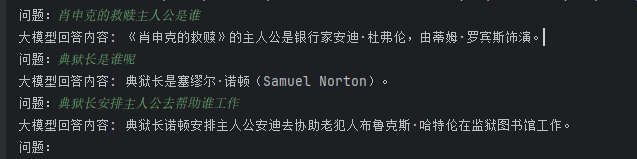
四、测试工程师的实践价值
1. 自动化测试场景
- 测试用例生成:从需求文档中提取关键要素,自动生成测试用例
- 缺陷定位:当测试失败时,快速关联相关设计文档
- 数据验证:验证系统输出是否符合文档规范
2. 典型测试案例
| 测试场景 | RAG应用 |
|---|---|
| 接口文档查询 | 快速定位接口字段定义 |
| 用户故事验证 | 核对实现功能与原始需求 |
| 数据库校验 | 比对数据库结构与设计文档 |
五、验证与调试技巧
1. 质量验证矩阵
| 指标 | 验证方法 |
|---|---|
| 准确性 | 对比系统输出与原始文档 |
| 召回率 | 检查是否覆盖所有关键信息 |
| 时效性 | 监控文档更新同步机制 |
| 完整性 | 验证分片是否包含上下文关联 |
2. 常见问题排查
- 空响应:检查向量数据库是否正常写入
- 错误答案:验证检索结果是否包含相关上下文
- 性能瓶颈:优化分片粒度和向量检索参数
六、进阶优化方向
- 多模态支持:扩展支持图片、表格等非文本内容
- 增量更新:实现文档变更的自动同步机制
- 权重调整:通过测试反馈优化检索排序算法
- 安全增强:添加敏感信息过滤模块
七、结语
通过本次实战,我们成功构建了一个基于《肖申克的救赎》文档的智能问答系统。作为测试工程师,掌握RAG技术不仅能提升测试效率,更能推动测试智能化转型。建议读者尝试以下练习:
- 将该方案应用于实际测试文档
- 对比不同分片策略的检索效果
- 集成到现有的测试自动化框架中
八、完整源码
python
from langchain_deepseek import ChatDeepSeek
from dotenv import load_dotenv
import os
from pprint import pprint
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.embeddings import DashScopeEmbeddings
import chromadb
from langchain_community.vectorstores import Chroma
from langchain import hub
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
load_dotenv() # 加载环境变量
llm = ChatDeepSeek(
model="deepseek-chat", # 使用 DeepSeek-V3 模型
api_key=os.getenv("DEEPSEEK_API_KEY"),
api_base=os.getenv("DEEPSEEK_API_BASE"),
temperature=0.7, # 控制生成多样性
max_tokens=512, # 最大输出长度
)
# 加载 PDF 文档
loader = PyPDFLoader("shrek_redemption.pdf")
documents = loader.load()
# 切分文档为片段
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
docs = text_splitter.split_documents(documents)
pprint(docs)
# 初始化嵌入模型
embed_model = DashScopeEmbeddings(
model="text-embedding-v2",
dashscope_api_key=os.getenv("DASHSCOPE_API_KEY")
)
# 提取分片文档内容
texts = [doc.page_content for doc in docs]
# 批量生成向量
# vectors = embeddings.embed_documents(texts)
# 创建Chroma客户端
chroma = chromadb.PersistentClient(path='./chroma_db')
chroma.delete_collection(name='shrek_docs3')
collection = chroma.get_or_create_collection(name='shrek_docs3', metadata={"hnsw:space":"cosine"})
db=Chroma(client=chroma,collection_name='shrek_docs3', embedding_function=embed_model)
db.add_documents(docs)
# 检索器
retriever = db.as_retriever()
# 构造一个RAG"链"
prompt = hub.pull("rlm/rag-prompt")
# 正确构造 rag_chain
rag_chain = (
{"context": retriever | (lambda docs: "\n\n".join(doc.page_content for doc in docs)), "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
while True:
user_input = input("问题:")
if user_input.lower() == 'exit':
break
response = rag_chain.invoke(user_input)
print("大模型回答内容:", response)