引言
在计算机视觉领域,目标检测模型YOLO(You Only Look Once)系列以其高效的检测性能而闻名。随着YOLOv8的发布,这一系列模型在精度和速度上又达到了新的高度。然而,在实际部署场景中,特别是在边缘设备上,模型的计算复杂度和参数量仍然是重要的考量因素。模型剪枝作为一种有效的模型压缩技术,可以显著减少模型大小和计算量,同时尽量保持模型的性能。本文将深入探讨基于DepGraph(依赖图)的YOLOv8模型剪枝方法,并提供详细的实战指南。
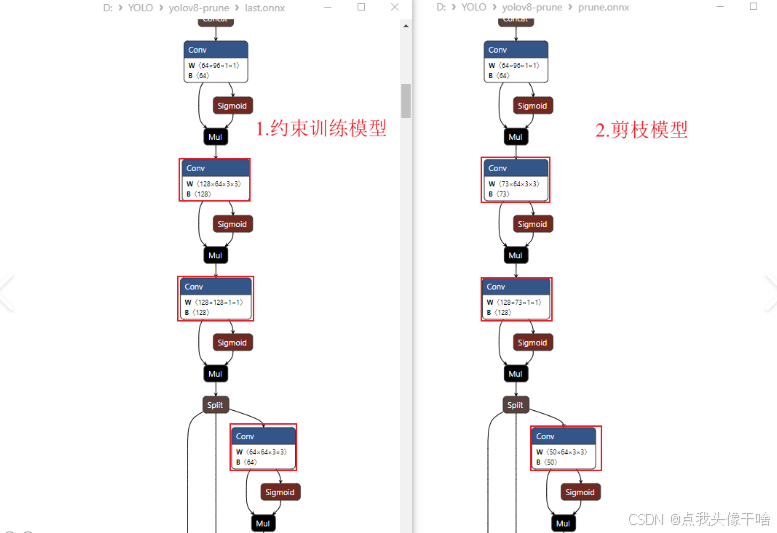
一、模型剪枝概述
1.1 什么是模型剪枝
模型剪枝(Network Pruning)是一种通过移除神经网络中冗余或不重要的部分来减小模型大小的技术。其核心思想是识别并删除对模型性能影响较小的权重、神经元或整个层,从而得到一个更轻量级但性能相近的模型。
1.2 剪枝的主要类型
-
非结构化剪枝:移除单个权重或连接,导致稀疏的权重矩阵
-
结构化剪枝:移除整个神经元、通道或层,保持密集的矩阵结构
-
全局剪枝:在整个网络范围内评估和剪枝
-
局部剪枝:在单个层或模块内部进行剪枝
1.3 剪枝的重要性
-
减少模型大小,便于在资源受限设备上部署
-
降低计算复杂度,提高推理速度
-
减少内存带宽需求
-
降低能耗,适合移动和嵌入式应用
二、DepGraph(依赖图)方法原理
2.1 DepGraph基本概念
DepGraph(Dependency Graph)是一种表示神经网络中各层之间依赖关系的图结构。它能够清晰地展示模型中不同组件之间的连接和依赖,为结构化剪枝提供理论基础。
2.2 依赖图的构建
-
节点表示:图中的节点代表网络中的层或操作
-
边表示:边表示数据流和依赖关系
-
依赖类型:
-
数据依赖:一个层的输出是另一个层的输入
-
控制依赖:一个层的执行依赖于另一个层的条件
-
2.3 基于DepGraph的剪枝流程
-
构建模型的依赖图
-
分析各层之间的依赖关系
-
识别可剪枝的通道或层
-
评估剪枝对模型的影响
-
执行剪枝并微调模型
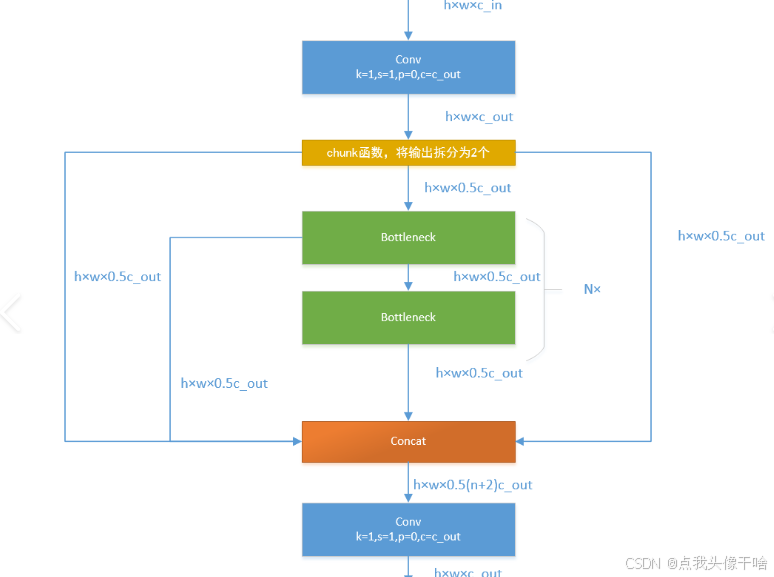
三、YOLOv8模型结构分析
3.1 YOLOv8架构概述
YOLOv8采用了一种新的骨干网络和neck设计,主要包括:
-
Backbone:特征提取网络
-
Neck:特征金字塔网络(FPN)
-
Head:检测头
3.2 YOLOv8的关键模块
-
CSPDarknet:改进的骨干网络
-
SPPF:空间金字塔池化快速版
-
PANet:路径聚合网络
-
Detect:检测头
3.3 YOLOv8的剪枝挑战
-
复杂的跨层连接
-
多尺度特征融合
-
深度可分离卷积的使用
-
残差连接和密集连接
四、YOLOv8 DepGraph剪枝实战
4.1 环境准备
# 安装必要库
pip install torch torchvision ultralytics torch-pruner4.2 加载预训练模型
from ultralytics import YOLO
# 加载预训练的YOLOv8模型
model = YOLO('yolov8n.pt') # 以yolov8n为例4.3 构建依赖图
from torch_pruner import DependencyGraph
# 获取模型的torch模型
torch_model = model.model
# 构建依赖图
dg = DependencyGraph()
dg.build_dependency(torch_model, example_inputs=torch.randn(1, 3, 640, 640))4.4 剪枝策略设计
4.4.1 通道重要性评估
# 定义重要性评估函数
def channel_importance(weight):
# 使用L1范数作为重要性指标
return torch.sum(torch.abs(weight), dim=(1, 2, 3))
# 获取所有卷积层的权重
conv_layers = [module for module in torch_model.modules()
if isinstance(module, torch.nn.Conv2d)]4.4.2 剪枝比例设置
python
# 设置全局剪枝比例
global_prune_ratio = 0.3 # 剪枝30%的通道
# 或者按层设置不同的剪枝比例
layer_prune_ratios = {
'model.0.conv': 0.2,
'model.1.conv': 0.3,
# ...其他层配置
}4.5 执行剪枝
python
from torch_pruner import pruner
# 创建剪枝器
pruner = pruner.MagnitudePruner(
model=torch_model,
importance=channel_importance,
global_prune_ratio=global_prune_ratio,
dependency_graph=dg
)
# 执行剪枝
pruner.prune()
# 查看剪枝后的模型
print(torch_model)4.6 模型微调
python
# 定义微调参数
finetune_epochs = 50
learning_rate = 0.001
# 创建优化器
optimizer = torch.optim.Adam(torch_model.parameters(), lr=learning_rate)
# 微调循环
for epoch in range(finetune_epochs):
for images, targets in dataloader:
optimizer.zero_grad()
outputs = torch_model(images)
loss = compute_loss(outputs, targets)
loss.backward()
optimizer.step()
print(f'Epoch {epoch+1}, Loss: {loss.item()}')五、剪枝效果评估
5.1 模型大小对比
python
import os
# 计算原始模型大小
original_size = os.path.getsize('yolov8n.pt') / (1024 * 1024) # MB
# 保存剪枝后模型
torch.save(torch_model.state_dict(), 'yolov8n_pruned.pt')
pruned_size = os.path.getsize('yolov8n_pruned.pt') / (1024 * 1024)
print(f'原始模型大小: {original_size:.2f}MB')
print(f'剪枝后模型大小: {pruned_size:.2f}MB')
print(f'压缩率: {(1 - pruned_size/original_size)*100:.2f}%')5.2 推理速度测试
python
import time
# 原始模型推理时间
start = time.time()
original_output = model.predict(test_image)
original_time = time.time() - start
# 剪枝模型推理时间
pruned_model = YOLO('yolov8n_pruned.pt')
start = time.time()
pruned_output = pruned_model.predict(test_image)
pruned_time = time.time() - start
print(f'原始模型推理时间: {original_time:.4f}s')
print(f'剪枝模型推理时间: {pruned_time:.4f}s')
print(f'加速比: {original_time/pruned_time:.2f}x')5.3 精度评估
python
from ultralytics.yolo.utils.metrics import box_iou
# 在验证集上评估原始模型
original_metrics = model.val(data='coco128.yaml')
# 评估剪枝模型
pruned_metrics = pruned_model.val(data='coco128.yaml')
print('原始模型mAP:', original_metrics.box.map)
print('剪枝模型mAP:', pruned_metrics.box.map)
print('精度下降:', original_metrics.box.map - pruned_metrics.box.map)六、高级剪枝技巧
6.1 分层剪枝策略
python
# 根据层深度设置不同的剪枝比例
def layer_depth_aware_prune_ratio(layer_name):
depth = int(layer_name.split('.')[1]) # 假设层名格式为model.x.conv
base_ratio = 0.3
# 深层网络剪枝比例较低
return base_ratio * (1 - 0.05 * depth)
# 应用分层剪枝
for layer in conv_layers:
ratio = layer_depth_aware_prune_ratio(layer.name)
pruner.set_layer_prune_ratio(layer, ratio)6.2 渐进式剪枝
python
# 渐进式剪枝
num_iterations = 5
total_prune_ratio = 0.5
for i in range(num_iterations):
current_ratio = (i + 1) / num_iterations * total_prune_ratio
pruner.global_prune_ratio = current_ratio
pruner.prune()
# 每次剪枝后微调
finetune_for_epochs(1)6.3 敏感层分析
python
# 敏感层分析
sensitive_layers = []
for layer in conv_layers:
original_output = model.predict(test_image)
# 临时剪枝该层
temp_pruner = pruner.MagnitudePruner(
model=torch_model,
importance=channel_importance,
layer_prune_ratios={layer.name: 0.3}, # 固定30%剪枝
dependency_graph=dg
)
temp_pruner.prune()
pruned_output = model.predict(test_image)
iou = box_iou(original_output, pruned_output)
if iou < 0.9: # 如果IOU下降严重
sensitive_layers.append(layer.name)
# 恢复模型
model = YOLO('yolov8n.pt')
print('敏感层:', sensitive_layers)七、常见问题与解决方案
7.1 剪枝后模型崩溃
问题现象:剪枝后模型输出全为0或完全不合理
解决方案:
-
降低剪枝比例
-
检查依赖图是否正确构建
-
确保剪枝后各层的通道数兼容
7.2 精度下降严重
问题现象:mAP下降超过10%
解决方案:
-
增加微调epoch
-
使用更小的学习率微调
-
采用渐进式剪枝策略
-
对敏感层使用更保守的剪枝比例
7.3 推理速度未提升
问题现象:模型大小减小但推理时间未减少
解决方案:
-
确保剪枝是结构化的
-
检查是否剪枝了计算密集型层
-
验证部署环境是否支持稀疏计算
八、结论与展望
本文详细介绍了基于DepGraph的YOLOv8模型剪枝方法,从理论原理到实践操作,提供了完整的剪枝流程。通过依赖图分析,我们可以更安全、更有效地对复杂模型进行结构化剪枝,在保持模型性能的同时显著减小模型大小和计算量。
未来,模型剪枝技术可能会在以下方向继续发展:
-
自动化剪枝策略搜索
-
硬件感知的剪枝方法
-
与其他模型压缩技术(如量化、知识蒸馏)的结合
-
针对特定硬件架构的定制化剪枝
通过合理应用这些剪枝技术,我们可以将强大的YOLOv8模型部署到更广泛的边缘设备上,推动计算机视觉应用在现实世界中的普及。
参考文献
-
Liu, Z., et al. "Pruning Filters for Efficient ConvNets." ICLR 2017.
-
Molchanov, P., et al. "Pruning Convolutional Neural Networks for Resource Efficient Transfer Learning." arXiv 2016.
-
Fang, J., et al. "DepGraph: Towards Any Structural Pruning." CVPR 2023.
-
Ultralytics YOLOv8 Documentation. Home - Ultralytics YOLO Docs
-
PyTorch Pruner Toolkit. https://github.com/VainF/Torch-Pruner
希望这篇博客能帮助您理解和应用YOLOv8模型剪枝技术。如有任何问题或建议,欢迎留言讨论。