今天向大家介绍EMAGE,这是一个由清华大学、东京大学和庆应义塾大学等机构联合推出的全身共语手势框架。它能够根据音频内容生成与之同步的全身手势动作。这个模型原本是我非常关注的一个解决方案,特别适合用于数字人的肢体动作生成。后来作者在此基础上开发的Tango数字人生成模型表现不尽如人意,因此我没有继续深入研究。不过EMAGE本身仍有参考价值,尤其是它所采用的BEAT2数据集值得重点关注。
一. 前言/动机
目标 :根据音频生成全身人类姿态,包括面部表情,局部动作、手部动作和整体移动
解决方案:
- 创建BEAT2数据集, 在已有 BEAT 数据集基础上扩展和精细化制作的,其目的是为了支持 全身(含面部、手、身体等)共语姿态生成任务。
- 提出EMAGE,引入遮蔽的身体动作先验,以提升推理性能 该框架包含一个掩码音频-姿态 Transformer 模型,能够联合训练音频到动作生成与遮蔽动作重建两个任务,从而有效编码音频信息和身体动作提示,遮蔽动作中编码得到的身体提示随后被分别用于生成面部表情与身体动作。 EMAGE 自适应融合了音频中的节奏与内容特征,并利用四个组合式 VQ-VAE 模块来提升生成结果的真实感与多样性。
数据集地址 :
● https://huggingface.co/datasets/H-Liu1997/BEAT2
使用此数据集:
python
from datasets import load_dataset
ds = load_dataset("H-Liu1997/BEAT2")这是一个新的基于网格级别的整体共语动作(即与语音同步的人体动作)数据集。BEAT2 将 MoSh 驱动的 SMPL-X 身体模型与 FLAME 头部参数结合,并进一步精细建模头部、脖子和手指的运动,提供了一个面向社区的、标准化的高质量 3D 动作捕捉数据集。
EMAGE 的主要流程包括:
- 首先从被遮蔽的身体关节中聚合空间特征;
- 然后,借助可切换的动作时间自注意力模块与音频-动作交叉注意力机制,对预训练动作的潜在空间进行重建;
- 通过不同的前向路径选择,模型能够分别有效建模"动作到动作"以及"音频到动作"的先验信息;
- 在获得重建后的潜在特征后,EMAGE 使用**四个预训练的组合式 VQ-VAE(向量量化变分自编码器)**来分别解码局部面部和身体动作,同时利用一个预训练的全局运动预测器来解码整体平移运动。
MAGE的主要功能:
- 生成与音频同步的手势:根据输入的音频信号,生成与音频节奏与语义匹配的全身手势
- 接受部分预定义姿势输入:基于用户提供的部分姿势(如特定动作或姿势)作为提示,生成完整的、自然的动作序列
- 生成多样化的人体动作姿态:组合多个预训练的VQ-VAE,生成丰富多样的人体动作,避免单一和重复的结果
主要贡献(创新点):
- 发布了 BEAT2:一个统一表示、基于网格的动作数据集,结合了 MoShed SMPL-X 身体参数与 FLAME 头部参数。
- 提出了 EMAGE 框架:一个简单而有效的整体动作生成方法,能够基于部分动作和音频先验生成连贯的全身动作。
二. 方法
输入:音频或者部分人体动作姿态(遮罩后的身体动作提示)
输出:全身动作和脸部表情 (SMPL-X + FLAME )
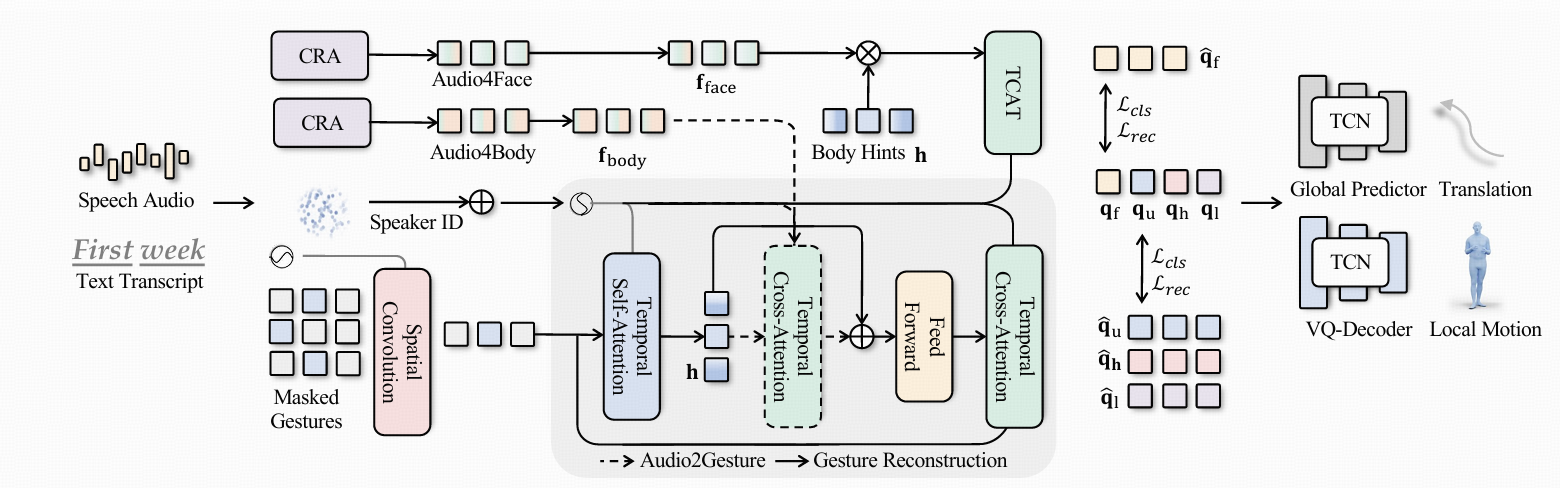
2.1 内容与节奏自注意力机制(Content and Rhythm Self-Attention)
给定语音音频 s,EMAGE使用音频起始点(onset) o o o 和幅度(amplitude) a a a 作为显式的音频节奏信息,同时结合由转录文本生成的预训练嵌入 e e e 作为语义内容信息,之前的方法通常将节奏特征和内容特征简单地相加,而EMAGE采用自注意力机制对这两种特征进行自适应融合, 这一设计基于观察:在某些帧中,手势更依赖于语义内容(semantic-aware);而在另一些帧中,手势更多地受节奏控制(beat-aware)。
具体实现如下:
- 节奏特征 r1:T:通过一个 时间卷积网络(TCN) 编码;
- 内容特征 c1:T:通过一个 线性映射 得到;
- 在每个时间步 t∈{1,...,T},我们融合两者为:
f 1 : T = α ⋅ r 1 : T + ( 1 − α ) ⋅ c 1 : T f 1:T =α⋅r 1:T +(1−α)⋅c 1:T f1:T=α⋅r1:T+(1−α)⋅c1:T
其中,
α = S o f t m a x ( A T ( r 1 : T , c 1 : T ) ) α=Softmax(AT(r 1:T ,c 1:T )) α=Softmax(AT(r1:T,c1:T))
A T ( ⋅ ) AT(⋅) AT(⋅) 是一个 两层的多层感知机(MLP),用于动态计算融合权重 α α α , 最后 ,为面部和身体分别使用两个独立的 CRA 编码器(Content Rhythm Self-Attention encoders),以捕捉它们不同的时序依赖与语音关联特征。
2.2 面部和位移解码(Face and Translation Decoding)
目标:有效地解码面部和位移信息,特别是在音频和身体提示的条件下。
2.2.1. 面部解码:
面部动作与身体运动的关系较弱,因此不再像处理身体运动那样简单地重新组合音频特征和身体提示。
直接将音频特征与身体提示进行连接,作为面部潜变量的解码输入:
q f ^ = T C A T ( f f a c e ⊕ h , p t ) \hat{qf} =T CAT(f_{face}⊕h,pt) qf^=TCAT(fface⊕h,pt)
其中, 𝑓 f a c e 𝑓_{face} fface 是面部特征, h h h 是从身体提示中获得的潜在信息, p t pt pt 是学到的说话人嵌入与PPE(头部姿势嵌入)。
2.2.2 全局位移预测:
- 局部下半身运动特征 g l ~ \widetilde{gl} gl 从 VQ 解码器中获取
- 使用预训练的全局运动预测器 G ( g l ~ ) G(\widetilde{gl}) G(gl ) 估计全局位移,该步骤能显著减少脚部滑动现象。
关键点:
- 面部解码与身体解码的处理方式有所不同,主要是由于面部与身体动作之间的弱相关性。
- 通过全局位移预测,可以有效减少由于局部下半身运动引起的脚部滑动问题,改善动作的自然度。
三. 实验
3.1 BEAT2数据集质量评估
将BEAT2与当前最先进的数据集TalkSHOW进行了对比,主要针对面部和身体数据。此外,还将其与AMASS数据集(主要用于身体数据)和VOCA数据集(主要用于面部数据)进行了对比。
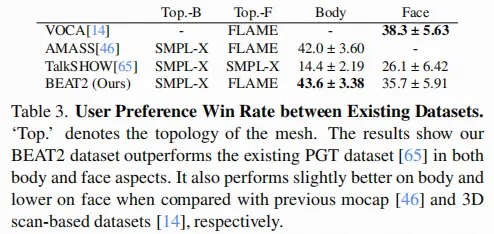
结果表明,BEAT2 数据集在身体和面部两个方面的表现都优于现有的PGT数据集 。与之前的动作捕捉数据集 [46和基于 3D 扫描的数据集 相比,BEAT2 在身体方面表现略优,而在面部方面略逊一筹。
评价指标:
- FGD: 衡量生成动作分布与真实动作分布之间的距离,越小越好,说明生成动作与真实动作在特征分布上越接近。
- BC: 衡量的是动作节奏点(比如肢体高峰或加速度变化)与语音节拍(beats)的一致性程度
- Diversity : 衡量生成动作序列之间的差异程度, 越大越好,表示生成模型没有产生重复或单一的动作
- MSE: 生成动作与真实动作在坐标级别的平均平方误差, 越小越好,表示生成动作在数值上更接近真实动作。
- LVD : 衡量局部运动变化(例如肢体的小幅运动)的统计差异。 越小越好,表示生成动作的局部动态变化更真实自然。
3.2 定量分析(使用四帧种子姿势):
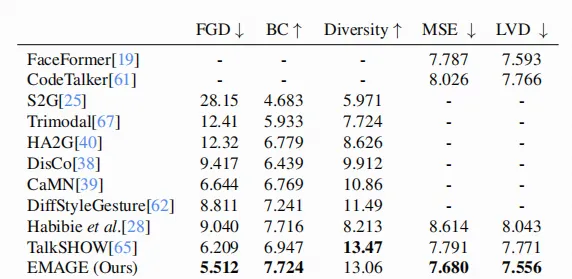
对于身体动作,EMAGE 在 FGD 指标上显著提升,表明生成结果更加接近真实值(GT)。这表明来自遮蔽动作建模的身体提示在提升效果方面是有效的。
3.3 定性结果分析
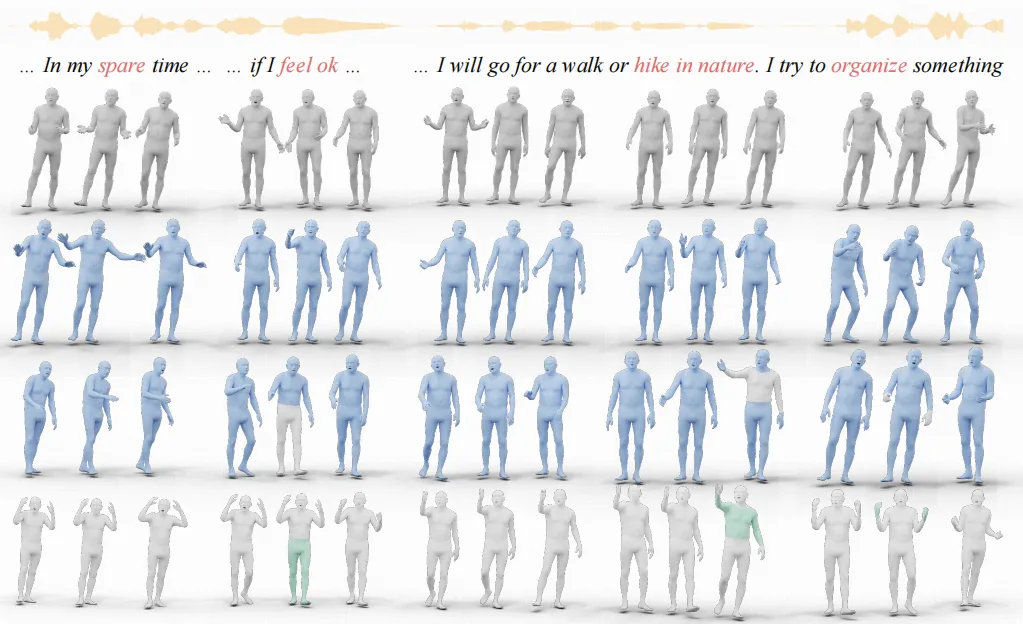
自上而下分别为:真实动作、不使用身体提示生成的结果、使用身体提示生成的结果、可见身体提示。
EMAGE 能够生成多样化的、具备语义感知能力且与音频同步的身体动作,例如在"spare time(空闲时间)"时举起双手,或在"hike in nature(在自然中徒步)"时做出放松的动作。此外,如第三行和最下方一行所示,EMAGE 也支持在任意帧或关节处插入非音频同步的身体提示,以显式引导或定制生成的动作,例如:重复类似的举手动作、改变行走方向等。

展示了EMAGE与现有最先进的说话人脸生成方法(如 FaceFormer 和 CodeTalker )以及整体手势生成方法如 Habibie 等和 TalkSHOW )的比较。需要注意的是,尽管 CodeTalker 在 BEATv2 上的顶点均方误差(MSE)高于 EMAGE(表 4,MSE 越低越好),但从主观视觉效果来看,EMAGE的生成结果仍显得更为真实自然。
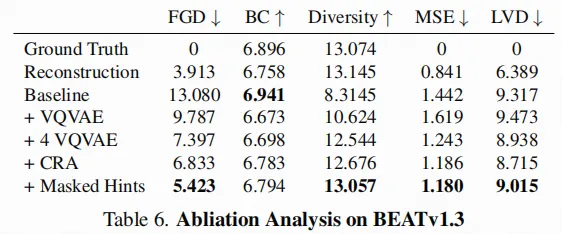
3.4 消融实验:
多个 VQ-VAE 的影响:简单地应用一个 VQ-VAE 来处理全身运动(包括面部),会降低面部动作的性能。这是因为 VQ-VAE 被训练来最小化全身的平均损失,而某些演讲者最常见的动作与音频无关。实施分离的 VQ-VAE 使模型能够更好地利用离散先验的优势。