### 文章目录
- [@toc](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [栈与队列:数据结构中的双生花](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [1. 栈:后进先出的有序世界](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [1.1 概念及结构剖析](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [1.2 实现方式深度解析](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [数组 vs 链表实现](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [1.3 动态栈实现详解(附程序源码)](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [1.定义一个动态栈](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [2.初始化](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [3.销毁](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [4.入栈](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [5.出栈](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [6.取栈顶数据](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [7.判空](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [8.获取数据个数](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [9.访问栈](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [10.程序源码](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [1.4 栈的应用场景](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [1. 函数调用栈](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [2. 表达式求值](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [3. 浏览器历史记录](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [4. 撤销操作(Undo)](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [2. 队列:先进先出的公平之师](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [2.1 概念及结构剖析](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [2.2 实现方式](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [为什么链表实现更优?](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [2.3 队列实现详解(附程序源码)](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [核心数据结构定义](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [1.初始化](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [2.队列的销毁](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [3.队尾插入](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [4.队头删除](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [5.统计队列中数据个数](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [6.取队头数据](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [7.取队尾数据](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [8.判空](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [9.访问队列](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [10.程序源码](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [2.4 队列的应用场景](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [1. 消息队列系统](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [2. 打印机任务调度](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [3. 广度优先搜索(BFS)](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [4. CPU任务调度](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [3. 栈与队列的对比分析](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [4. 高级变体与应用](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [4.1 双端队列(Deque)](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [4.2 优先队列(Priority Queue)](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)
- [5. 总结:选择合适的数据结构](#文章目录 @[toc] 栈与队列:数据结构中的双生花 1. 栈:后进先出的有序世界 1.1 概念及结构剖析 1.2 实现方式深度解析 数组 vs 链表实现 1.3 动态栈实现详解(附程序源码) 1.定义一个动态栈 2.初始化 3.销毁 4.入栈 5.出栈 6.取栈顶数据 7.判空 8.获取数据个数 9.访问栈 10.程序源码 1.4 栈的应用场景 1. 函数调用栈 2. 表达式求值 3. 浏览器历史记录 4. 撤销操作(Undo) 2. 队列:先进先出的公平之师 2.1 概念及结构剖析 2.2 实现方式 为什么链表实现更优? 2.3 队列实现详解(附程序源码) 核心数据结构定义 1.初始化 2.队列的销毁 3.队尾插入 4.队头删除 5.统计队列中数据个数 6.取队头数据 7.取队尾数据 8.判空 9.访问队列 10.程序源码 2.4 队列的应用场景 1. 消息队列系统 2. 打印机任务调度 3. 广度优先搜索(BFS) 4. CPU任务调度 3. 栈与队列的对比分析 4. 高级变体与应用 4.1 双端队列(Deque) 4.2 优先队列(Priority Queue) 5. 总结:选择合适的数据结构)

栈与队列:数据结构中的双生花
在计算机科学的世界里,栈和队列如同双生花般存在------它们看似相似却各有千秋,共同构成了最基本也是最强大的数据结构工具集。
1. 栈:后进先出的有序世界
1.1 概念及结构剖析
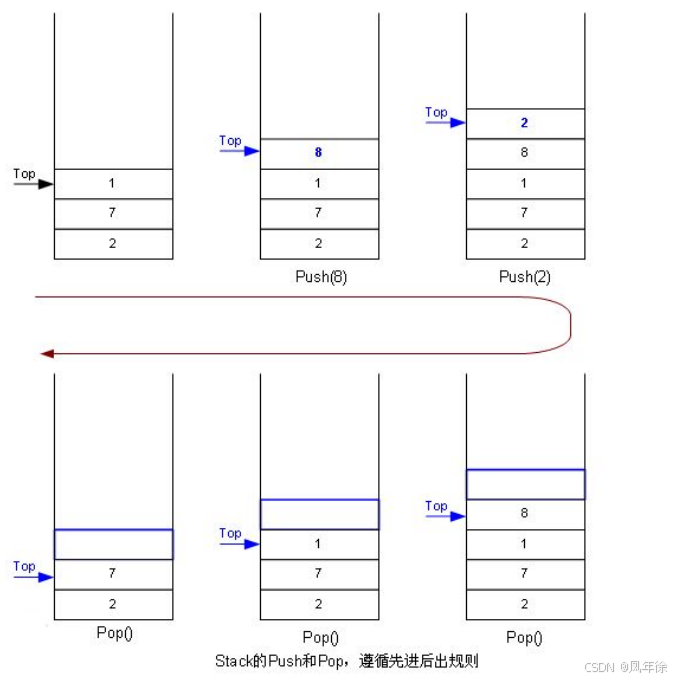
栈(Stack)是一种特殊的线性表,其核心特性是只允许在固定一端(栈顶)进行插入和删除操作。这种结构遵循**后进先出(LIFO)**原则:最后进入的元素最先被移除。
关键术语解析:
- 压栈/入栈(Push):在栈顶插入新元素
- 出栈(Pop):从栈顶删除元素
- 栈顶(Top):唯一允许操作的一端
- 栈底(Bottom):不允许操作的一端
结构可视化:
栈顶 → D → C → B → A ← 栈底
出栈顺序:D → C → B → A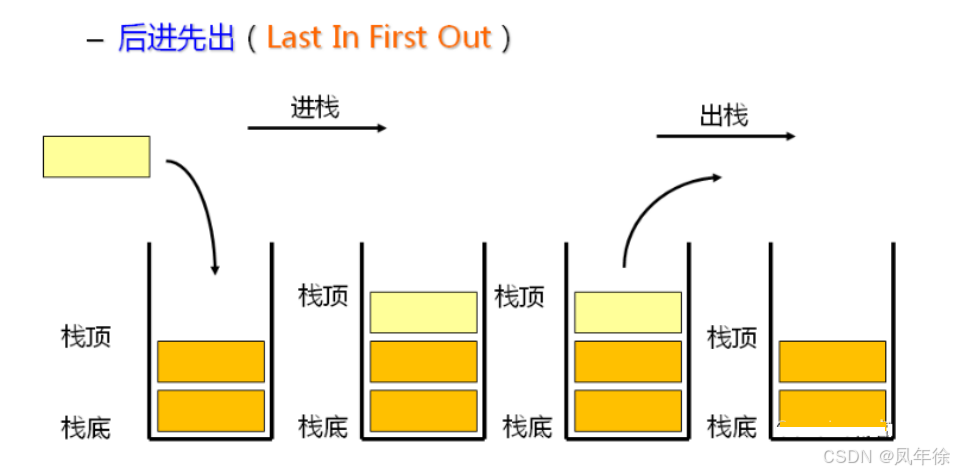
1.2 实现方式深度解析
数组 vs 链表实现
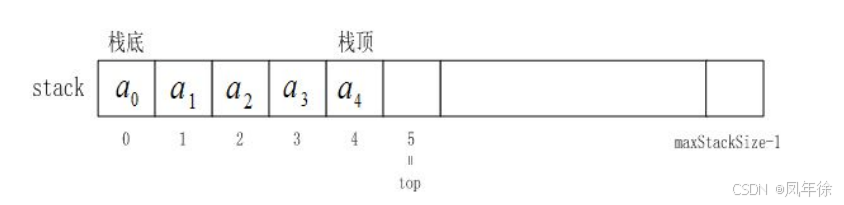
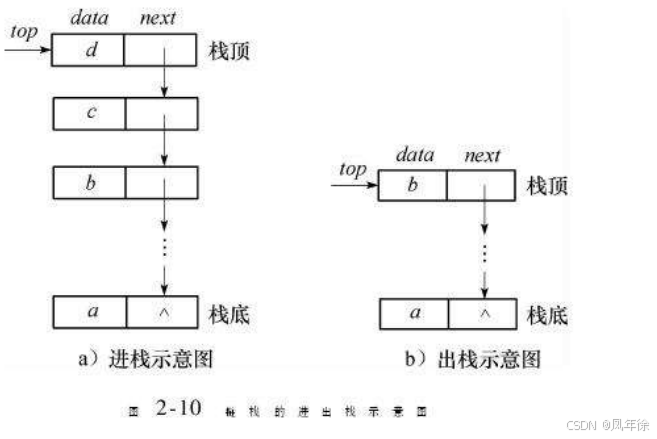
在栈的实现中,数组和链表各有优劣:
| 特性 | 数组实现 | 链表实现 |
|---|---|---|
| 内存使用 | 连续内存空间 | 非连续内存空间 |
| 扩容成本 | 较高(需重新分配) | 较低(动态分配) |
| 访问速度 | O(1) 随机访问 | O(n) 顺序访问 |
| 缓存友好性 | 高 | 低 |
| 实现复杂度 | 简单 | 中等 |
为什么数组实现更优?
对于栈这种主要在尾部操作的数据结构,数组的尾部插入/删除操作时间复杂度为O(1),且CPU缓存预取机制对连续内存访问更友好。虽然扩容时需要重新分配内存,但通过倍增策略可以摊还这一成本。
1.3 动态栈实现详解(附程序源码)
跟链表一样,我们采用多文件操作
1.定义一个动态栈
c
typedef int STDataType;
typedef struct Stack {
STDataType* _a; // 动态数组
int _top; // 栈顶位置
int _capacity; // 容量
} ST;2.初始化
c
void STInit(ST* pst)
{
assert(pst);
pst->a = 0;
pst->capacity = 0;
pst->top = 0;
}在这有两种写法,第一种是top指向栈顶,第二种是top指向栈顶的下一个位置
我个人更推荐第二种写法 这种写法的top类似于链表中的size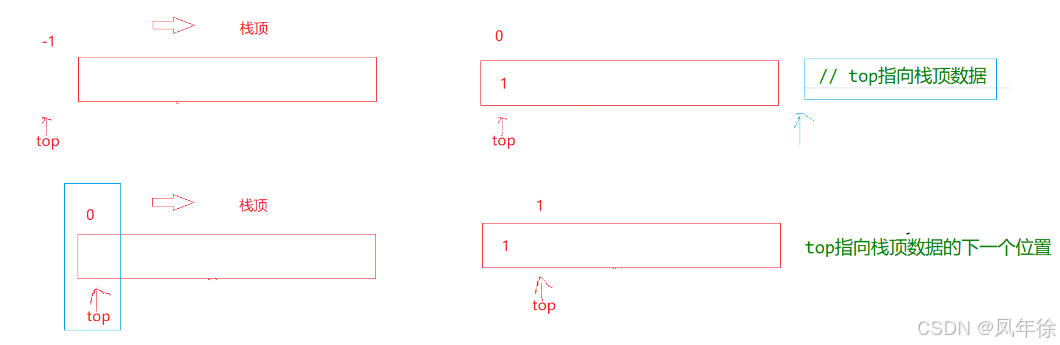
3.销毁
c
void STDestroy(ST* pst)
{
assert(pst);
free(pst->a);
pst->a = NULL;
pst->top = pst->capacity = 0;
}4.入栈
c
void STPush(ST* pst, STDataType x)
{
assert(pst);
//扩容
if (pst->top == pst->capacity)
{
int newcapcacity =pst->capacity==0 ? 4 : pst->capacity * 2;//起始空间为0则申请4个空间 不为0则二倍
STDataType* tmp = (STDataType*)ralloc(pst->a, newcapcacity * sizeof(STDataType));//pst->a为NULL时,realloc相当与malloc
if (tmp == NULL)
{
perror("realloc fail");
}
pst->a = tmp;
pst->capacity = newcapcacity;
}
pst->a[pst->top] = x;
pst->top++;//top指向栈顶下一个元素
}5.出栈
c
void STPop(ST* pst)
{
assert(pst);
pst->top--;
}6.取栈顶数据
c
STDataType STTop(ST* pst)
{
assert(pst);
assert(pst->top > 0);//top大于0才能取
return pst->a[pst->top - 1];//top是栈顶的下一个数据 所以要-1
}7.判空
c
bool STEmpty(ST* pst)
{
assert(pst);
return pst->top == 0;//==0就是空
}8.获取数据个数
c
int STSize(ST* pst)
{
assert(pst);
return pst->top;//也就是获取top 因为这里的top相当于size
}9.访问栈
c
#define _CRT_SECURE_NO_WARNINGS
#include"Stack.h"
int main()
{
ST s;
STInit(&s);
STPush(&s, 1);
STPush(&s, 2);
STPush(&s, 3);
STPush(&s, 4);
while (!STEmpty(&s))
{
printf("%d ", STTop(&s));
STPop(&s);//打印一删除一个
}
STDestroy(&s);
return 0;
}10.程序源码
Stack.h ---------函数声明
c
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<stdbool.h>
#include<assert.h>
typedef int STDataType;
typedef struct Stack
{
STDataType* a;
int top;
int capacity;
}ST;
//初始化和销毁
void STInit(ST* pst);
void STDestroy(ST* pst);
//入栈出栈
void STPush(ST* pst, STDataType x);
void STPop(ST* pst);
//取栈顶数据
STDataType STTop(ST* pst);
//判空
bool STEmpty(ST* pst);
//获取数据个数
int STSize(ST* pst);Stack.c---------函数的实现
c
#define _CRT_SECURE_NO_WARNINGS
#include"Stack.h"
//初始化和销毁
void STInit(ST* pst)
{
assert(pst);
pst->a = 0;
pst->capacity = 0;
pst->top = 0;
}
void STDestroy(ST* pst)
{
assert(pst);
free(pst->a);
pst->a = NULL;
pst->top = pst->capacity = 0;
}
//入栈出栈
void STPush(ST* pst, STDataType x)
{
assert(pst);
//扩容
if (pst->top == pst->capacity)
{
int newcapcacity =pst->capacity==0 ? 4 : pst->capacity * 2;//起始空间为0则申请4个空间 不为0则二倍
STDataType* tmp = (STDataType*)realloc(pst->a, newcapcacity * sizeof(STDataType));//pst->a为NULL时,realloc相当与malloc
if (tmp == NULL)
{
perror("realloc fail");
}
pst->a = tmp;
pst->capacity = newcapcacity;
}
pst->a[pst->top] = x;
pst->top++;//top指向栈顶下一个元素
}
void STPop(ST* pst)
{
assert(pst);
pst->top--;
}
//取栈顶数据
STDataType STTop(ST* pst)
{
assert(pst);
assert(pst->top > 0);
return pst->a[pst->top - 1];
}
//判空
bool STEmpty(ST* pst)
{
assert(pst);
return pst->top == 0;//==0就是空
}
//获取数据个数
int STSize(ST* pst)
{
assert(pst);
return pst->top;
}test.c------测试
c
#define _CRT_SECURE_NO_WARNINGS
#include"Stack.h"
int main()
{
ST s;
STInit(&s);
STPush(&s, 1);
STPush(&s, 2);
STPush(&s, 3);
STPush(&s, 4);
while (!STEmpty(&s))
{
printf("%d ", STTop(&s));
STPop(&s);
}
STDestroy(&s);
return 0;
}1.4 栈的应用场景
1. 函数调用栈
程序执行时,每次函数调用都会在栈中创建一个栈帧(Stack Frame),存储:
-
返回地址
-
局部变量
-
函数参数
-
寄存器状态
cvoid funcA() { int a = 10; // 栈帧创建 funcB(); // 返回后栈帧销毁 } void funcB() { int b = 20; // 新栈帧 }2. 表达式求值
栈用于处理各种表达式:
- 中缀转后缀:操作数栈和运算符栈
- 括号匹配:遇到左括号入栈,右括号出栈
- 计算后缀表达式:操作数入栈,遇到运算符出栈计算
示例:
(1 + 2) * 3的后缀表达式1 2 + 3 *3. 浏览器历史记录
浏览器的后退功能使用栈实现:
pythonclass BrowserHistory: def __init__(self): self.back_stack = [] # 后退栈 self.forward_stack = [] # 前进栈 def visit(self, url): self.back_stack.append(url) self.forward_stack = [] # 清空前进栈 def back(self): if len(self.back_stack) > 1: self.forward_stack.append(self.back_stack.pop()) return self.back_stack[-1]4. 撤销操作(Undo)
文本编辑器中的撤销机制:
javapublic class TextEditor { private StringBuilder text = new StringBuilder(); private Stack<String> history = new Stack<>(); public void type(String words) { history.push(text.toString()); // 保存状态 text.append(words); } public void undo() { if (!history.isEmpty()) { text = new StringBuilder(history.pop()); } } }
2. 队列:先进先出的公平之师
2.1 概念及结构剖析
队列(Queue)是一种只允许在一端(队尾)插入 ,在另一端(队头)删除的线性表。这种结构遵循**先进先出(FIFO)**原则:最先进入的元素最先被移除。
关键术语解析:
- 入队(Enqueue):在队尾插入新元素
- 出队(Dequeue):从队头删除元素
- 队头(Front):删除操作端
- 队尾(Rear):插入操作端
结构可视化:
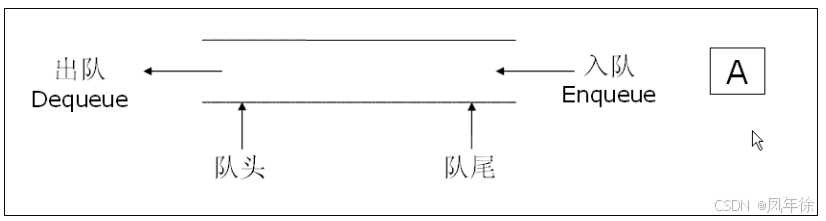
队头 → A → B → C → D → E ← 队尾
出队顺序:A → B → C → D → E2.2 实现方式
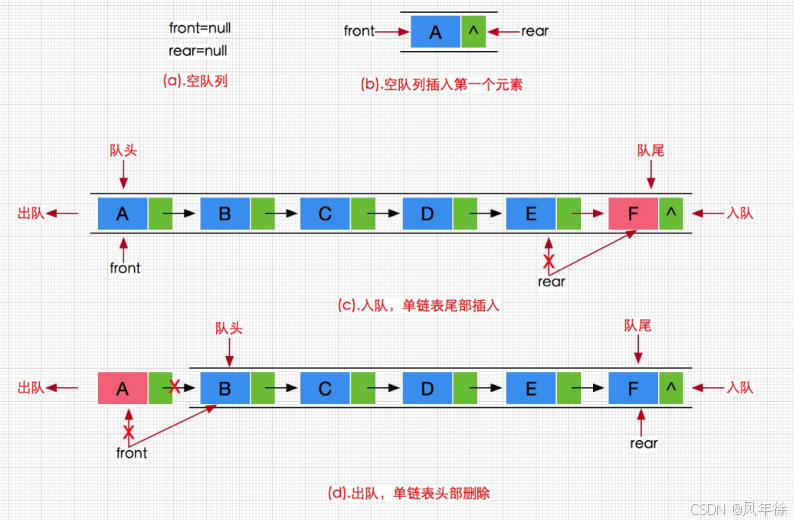
实现方案 :队列也可以数组和链表的结构实现,使用链表的结构实现更优一些,因为如果使用数组的结构,出队列在数组头上出数据,效率会比较低。
为什么链表实现更优?
对于队列这种需要在两端操作的数据结构:
- 数组实现问题 :
- 出队操作需要移动所有元素(O(n)时间复杂度)
- 假溢出问题(实际空间可用但无法入队)
- 需要复杂的环形缓冲区处理
- 链表实现优势 :
- O(1)时间复杂度的入队/出队操作
- 动态内存分配,无固定大小限制
- 自然避免假溢出问题
2.3 队列实现详解(附程序源码)
核心数据结构定义
c
typedef int QDataType;
typedef struct QueueNode
{
struct QueueNode* next;
QDataType val;
}QNode;
// 队列结构
typedef struct Queue {
QNode* phead; // 队头指针
QNode* ptail; // 队尾指针
int size;//用来计数
} Queue;//用一个结构题体来放头节点跟尾节点,这样传参就可以只传一个1.初始化
c
void QueueInit(Queue* pq)
{
assert(pq);
pq->phead = NULL;
pq->ptail = NULL;
pq->size = 0;
}2.队列的销毁
c
void QueueDestroy(Queue* pq)
{
assert(pq);
QNode* cur = pq->phead;
while (cur)
{
QNode* next = cur->next;
free(cur);
cur = next;
}
pq->phead = pq->ptail = NULL;
pq->size = 0;
}3.队尾插入
c
void QueuePush(Queue* pq, QDataType x)
{
QNode* newnode = (QNode*)malloc(sizeof(QNode));
if (newnode == NULL)
{
perror("malloc fail");
return;
}
newnode->next = NULL;
newnode->val = x;
if (pq->ptail == NULL)
{
pq->phead = pq->ptail = newnode;
}
else
{
pq->ptail->next = newnode;
pq->ptail = newnode;
}
pq->size++;
}4.队头删除
c
void QueuePop(Queue* pq)
{
assert(pq);
assert(pq->phead);
if (pq->phead->next == NULL)//一个节点
{
free(pq->phead);
pq->phead = pq->ptail = NULL;
}
else//多个节点
{
QNode* next = pq->phead->next;
free(pq->phead);
pq->phead = next;
}
pq->size--;
}5.统计队列中数据个数
c
int QueueSize(Queue* pq)
{
assert(pq);
return pq->size;
}6.取队头数据
c
QDataType QueueFront(Queue* pq)
{
assert(pq);
assert(pq->phead);
return pq->phead->val;
}7.取队尾数据
c
QDataType QueueBack(Queue* pq)
{
assert(pq);
assert(pq->phead);
return pq->ptail->val;
}8.判空
c
bool QueueEmpty(Queue* pq)
{
assert(pq);
return pq->size == 0;
}9.访问队列
c
int main()
{
Queue q;
QueueInit(&q);
QueuePush(&q, 1);
QueuePush(&q, 2);
QueuePush(&q, 3);
QueuePush(&q, 4);
while (!QueueEmpty(&q))
{
printf("%d ", QueueFront(&q));//取队头数据
QueuePop(&q);
}
printf("\n");
return 0;
}10.程序源码
Queue.h
c
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<stdbool.h>
#include<assert.h>
typedef int QDataType;
typedef struct QueueNode
{
struct QueueNode* next;
QDataType val;
}QNode;
typedef struct Queue
{
QNode* phead;
QNode* ptail;
int size;
}Queue;
//初始化
void QueueInit(Queue* pq);
//队列的销毁
void QueueDestroy(Queue* pq);
//队尾插入
void QueuePush(Queue* pq, QDataType x);
//队头删除
void QueuePop(Queue* pq);
//统计队列中数据的个数
int QueueSize(Queue* pq);
//取队头数据
QDataType QueueFront(Queue* pq);
//取队尾数据
QDataType QueueBack(Queue* pq);
//判空
bool QueueEmpty(Queue* pq);Queue.c
c
#define _CRT_SECURE_NO_WARNINGS
#include"Queue.h"
void QueueInit(Queue* pq)
{
assert(pq);
pq->phead = NULL;
pq->ptail = NULL;
pq->size = 0;
}
void QueuePush(Queue* pq, QDataType x)
{
QNode* newnode = (QNode*)malloc(sizeof(QNode));
if (newnode == NULL)
{
perror("malloc fail");
return;
}
newnode->next = NULL;
newnode->val = x;
if (pq->ptail == NULL)
{
pq->phead = pq->ptail = newnode;
}
else
{
pq->ptail->next = newnode;
pq->ptail = newnode;
}
pq->size++;
}
int QueueSize(Queue* pq)
{
assert(pq);
return pq->size;
}
void QueuePop(Queue* pq)
{
assert(pq);
assert(pq->phead);
if (pq->phead->next == NULL)//一个节点
{
free(pq->phead);
pq->phead = pq->ptail = NULL;
}
else//多个节点
{
QNode* next = pq->phead->next;
free(pq->phead);
pq->phead = next;
}
pq->size--;
}
QDataType QueueFront(Queue* pq)
{
assert(pq);
assert(pq->phead);
return pq->phead->val;
}
QDataType QueueBack(Queue* pq)
{
assert(pq);
assert(pq->phead);
return pq->ptail->val;
}
bool QueueEmpty(Queue* pq)
{
assert(pq);
return pq->size == 0;
}
void QueueDestroy(Queue* pq)
{
assert(pq);
QNode* cur = pq->phead;
while (cur)
{
QNode* next = cur->next;
free(cur);
cur = next;
}
pq->phead = pq->ptail = NULL;
pq->size = 0;
}test.c
c
#define _CRT_SECURE_NO_WARNINGS
#include"Queue.h"
int main()
{
Queue q;
QueueInit(&q);
QueuePush(&q, 1);
QueuePush(&q, 2);
QueuePush(&q, 3);
QueuePush(&q, 4);
while (!QueueEmpty(&q))
{
printf("%d ", QueueFront(&q));//取队头数据
QueuePop(&q);
}
printf("\n");
return 0;
}2.4 队列的应用场景
1. 消息队列系统
现代分布式系统的核心组件:
java
public class MessageQueue {
private Queue<Message> queue = new LinkedList<>();
public synchronized void enqueue(Message msg) {
queue.add(msg);
notifyAll(); // 唤醒等待的消费者
}
public synchronized Message dequeue() throws InterruptedException {
while (queue.isEmpty()) {
wait(); // 等待消息到达
}
return queue.remove();
}
}2. 打印机任务调度
多任务打印的公平处理:
python
class Printer:
def __init__(self):
self.print_queue = deque()
self.current_task = None
def add_document(self, document):
self.print_queue.append(document)
print(f"Added document: {document}")
def print_next(self):
if self.print_queue:
self.current_task = self.print_queue.popleft()
print(f"Printing: {self.current_task}")
else:
print("No documents to print")3. 广度优先搜索(BFS)
图遍历算法核心:
c
void BFS(Graph* graph, int start) {
bool visited[MAX_VERTICES] = {false};
Queue queue;
QueueInit(&queue);
visited[start] = true;
QueuePush(&queue, start);
while (!QueueEmpty(&queue)) {
int current = QueueFront(&queue);
QueuePop(&queue);
printf("Visited %d\n", current);
// 遍历所有邻接节点
for (int i = 0; i < graph->vertices; i++) {
if (graph->adjMatrix[current][i] && !visited[i]) {
visited[i] = true;
QueuePush(&queue, i);
}
}
}
}4. CPU任务调度
操作系统核心调度算法:
c
struct Task {
int pid;
int priority;
// 其他任务信息
};
void scheduleTasks(Queue* highPriority, Queue* normalQueue) {
while (!QueueEmpty(highPriority) || !QueueEmpty(normalQueue)) {
Task* task;
// 优先处理高优先级队列
if (!QueueEmpty(highPriority)) {
task = QueueFront(highPriority);
QueuePop(highPriority);
} else {
task = QueueFront(normalQueue);
QueuePop(normalQueue);
}
executeTask(task);
// 任务未完成则重新入队
if (!task->completed) {
if (task->priority == HIGH) {
QueuePush(highPriority, task);
} else {
QueuePush(normalQueue, task);
}
}
}
}3. 栈与队列的对比分析
| 特性 | 栈 (Stack) | 队列 (Queue) |
|---|---|---|
| 操作原则 | LIFO (后进先出) | FIFO (先进先出) |
| 插入位置 | 栈顶 (Top) | 队尾 (Rear) |
| 删除位置 | 栈顶 (Top) | 队头 (Front) |
| 典型操作 | Push, Pop | Enqueue, Dequeue |
| 实现方式 | 数组(更优)/链表 | 链表(更优)/循环数组 |
| 空间复杂度 | O(n) | O(n) |
| 时间复杂度 | Push/Pop: O(1) | Enqueue/Dequeue: O(1) |
| 应用场景 | 函数调用、表达式求值、回溯 | 消息传递、BFS、缓冲、调度 |
| 抽象层次 | 递归结构 | 管道结构 |
4. 高级变体与应用
4.1 双端队列(Deque)
双端队列结合了栈和队列的特性,允许在两端进行插入和删除操作:
c
typedef struct DequeNode {
int data;
struct DequeNode* prev;
struct DequeNode* next;
} DequeNode;
typedef struct {
DequeNode* front;
DequeNode* rear;
} Deque;
// 前端插入
void insertFront(Deque* dq, int data) {
DequeNode* newNode = createNode(data);
if (dq->front == NULL) {
dq->front = dq->rear = newNode;
} else {
newNode->next = dq->front;
dq->front->prev = newNode;
dq->front = newNode;
}
}
// 后端删除
int deleteRear(Deque* dq) {
if (dq->rear == NULL) return -1; // 错误值
DequeNode* temp = dq->rear;
int data = temp->data;
if (dq->front == dq->rear) {
dq->front = dq->rear = NULL;
} else {
dq->rear = dq->rear->prev;
dq->rear->next = NULL;
}
free(temp);
return data;
}4.2 优先队列(Priority Queue)
优先队列是队列的变体,元素按优先级出队:
c
typedef struct {
int* heap; // 堆数组
int capacity; // 最大容量
int size; // 当前大小
} PriorityQueue;
void enqueue(PriorityQueue* pq, int value) {
if (pq->size == pq->capacity) {
// 扩容逻辑
}
// 将新元素添加到堆尾
int i = pq->size++;
pq->heap[i] = value;
// 上滤操作
while (i != 0 && pq->heap[(i-1)/2] > pq->heap[i]) {
swap(&pq->heap[i], &pq->heap[(i-1)/2]);
i = (i-1)/2;
}
}
int dequeue(PriorityQueue* pq) {
if (pq->size <= 0) return INT_MIN;
int root = pq->heap[0];
pq->heap[0] = pq->heap[--pq->size];
// 下滤操作
int i = 0;
while (true) {
int smallest = i;
int left = 2*i + 1;
int right = 2*i + 2;
if (left < pq->size && pq->heap[left] < pq->heap[smallest])
smallest = left;
if (right < pq->size && pq->heap[right] < pq->heap[smallest])
smallest = right;
if (smallest != i) {
swap(&pq->heap[i], &pq->heap[smallest]);
i = smallest;
} else {
break;
}
}
return root;
}5. 总结:选择合适的数据结构
栈和队列作为基础数据结构,在算法设计和系统开发中无处不在:
- 选择栈的场景 :
- 需要回溯操作(如撤销功能)
- 递归算法实现
- 深度优先搜索(DFS)
- 语法解析和表达式求值
- 选择队列的场景 :
- 需要公平处理(如任务调度)
- 广度优先搜索(BFS)
- 缓冲区和数据传输
- 消息传递系统
- 混合使用场景 :
- 使用队列实现栈(需要两个队列)
- 使用栈实现队列(需要两个栈)
- 双端队列满足双向操作需求
- 优先队列处理带优先级的任务