目录
卷积层介绍
卷积层是卷积神经网络(CNN)的核心组件,它通过卷积运算提取输入数据的特征。
基本原理
卷积层通过卷积核(过滤器)在输入数据(如图像)上滑动,进行逐元素乘法并求和,从而提取局部特征。每个卷积核学习不同的特征(如边缘、纹理),最终生成多个特征图。
-
局部连接:卷积核只关注输入的局部区域,减少参数数量。
-
权值共享:同一个卷积核在整个输入上滑动,降低过拟合风险。
-
特征提取:不同卷积核可以检测不同特征,如水平边缘、垂直边缘等。
核心参数
-
卷积核大小:通常为 3x3、5x5 等,决定感受野。
-
步长(Stride):卷积核滑动的步距,影响输出尺寸。
-
填充(Padding):在输入周围添加零值,控制输出尺寸与输入一致。
-
卷积核数量:决定输出特征图的通道数。
Conv2d
Conv2d:二维卷积操作
相关参数如下:

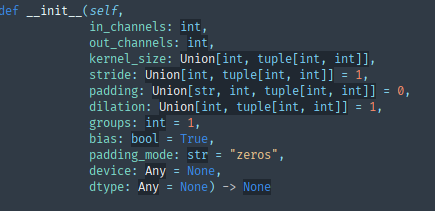
参数:
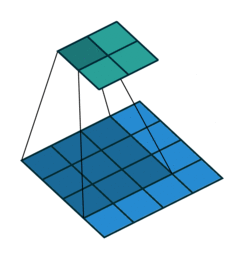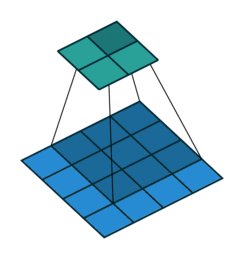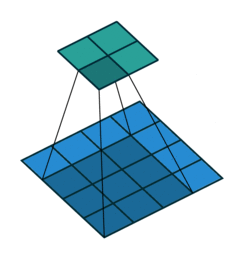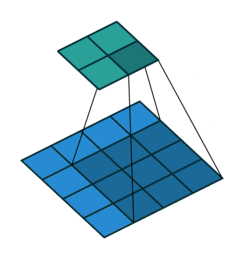
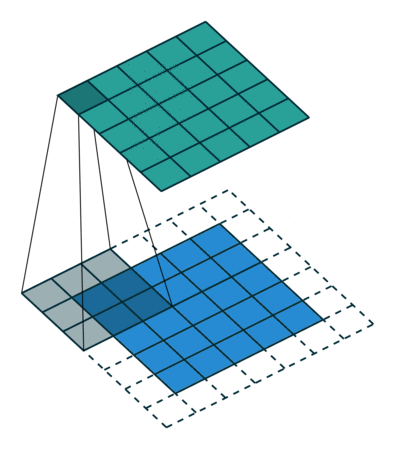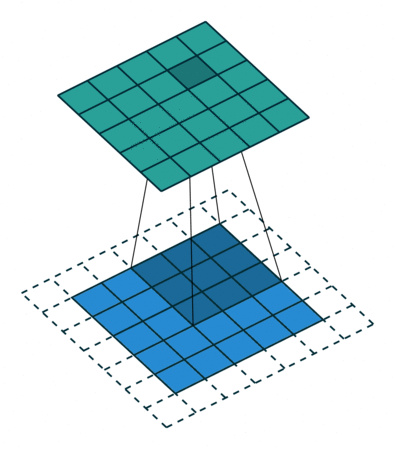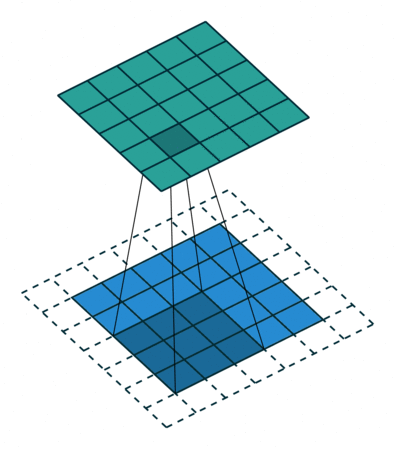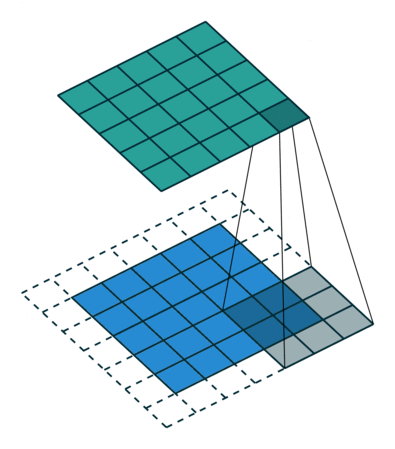
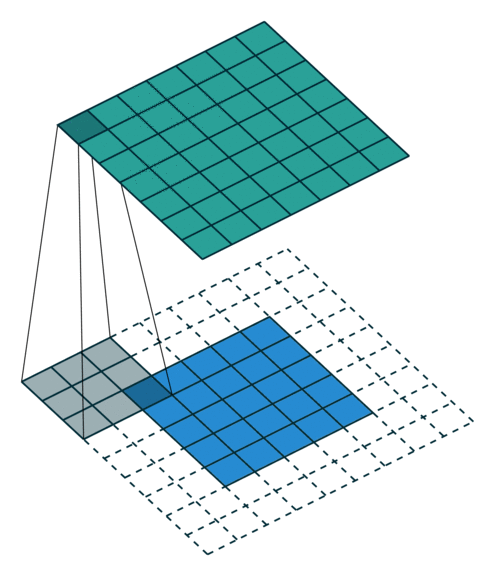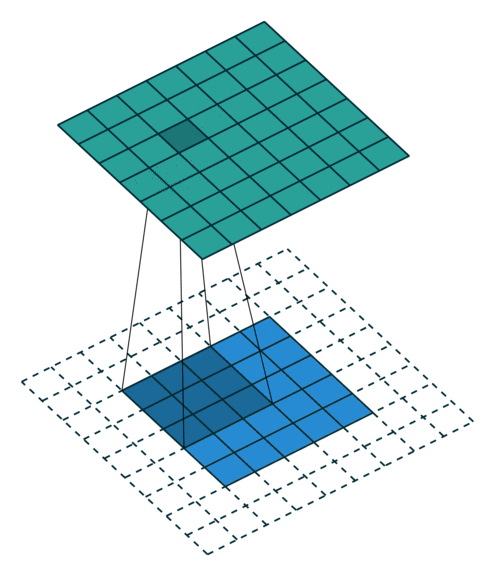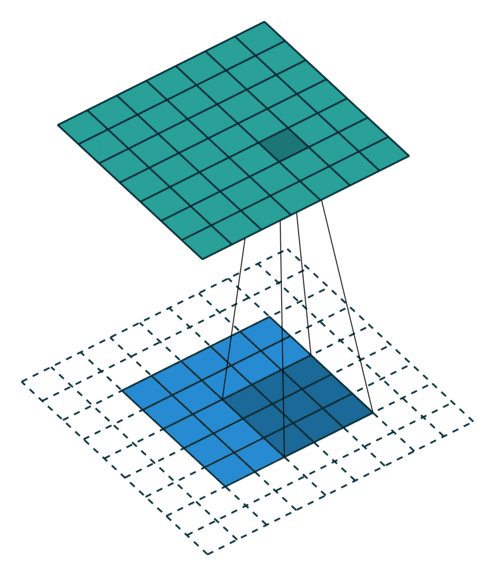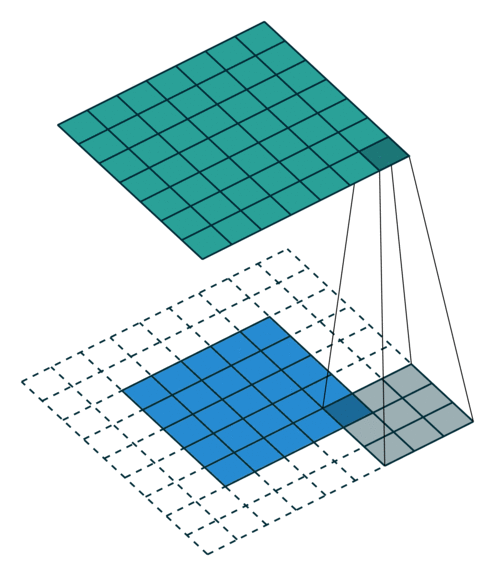
卷积动画演示
注意:蓝色映射是输入,青色映射是输出。
No padding, no strides Arbitrary padding, no strides
没有填充,没有步幅 任意填充,无步幅
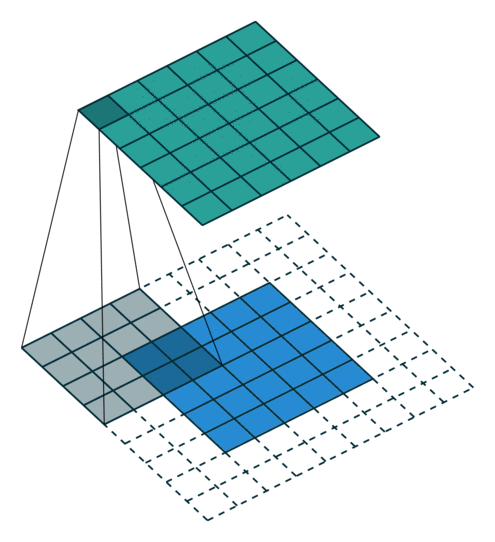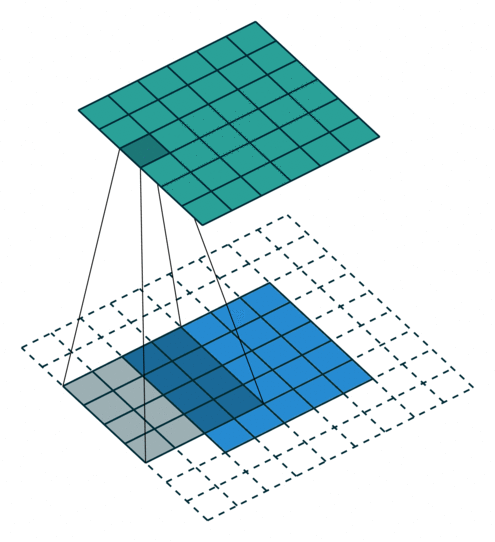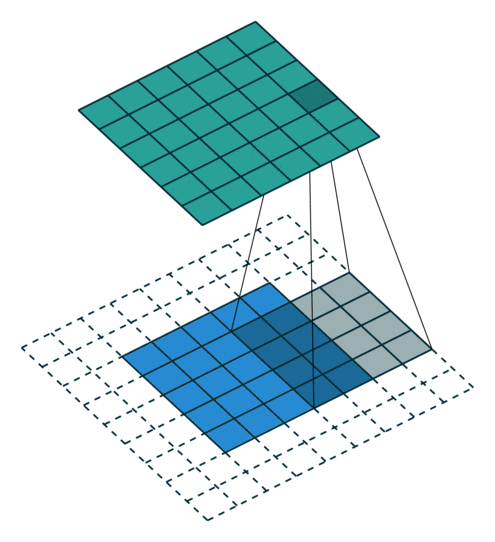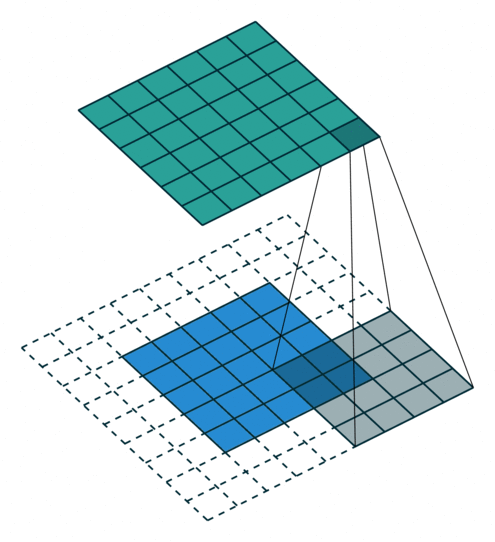
Half padding, no strides Full padding, no strides
半填充,无步幅 全填充,无步幅
No padding, strides Padding, strides
没有填充,没有步幅 填充、步幅
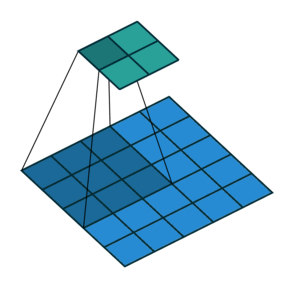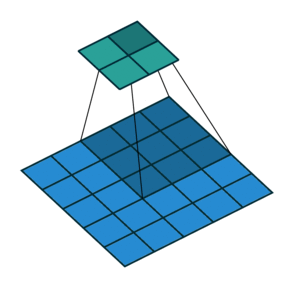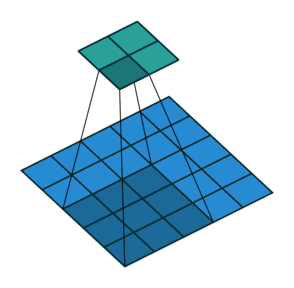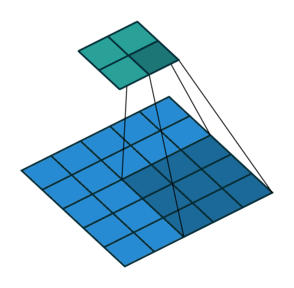
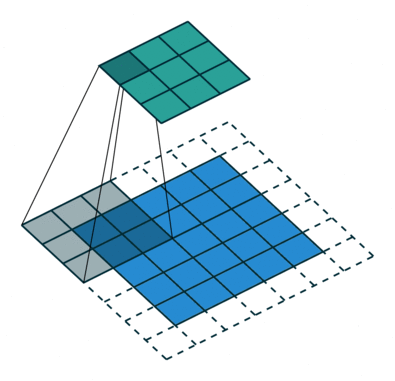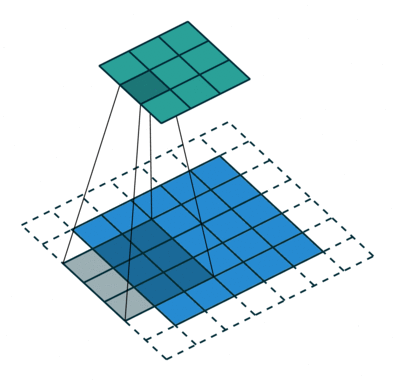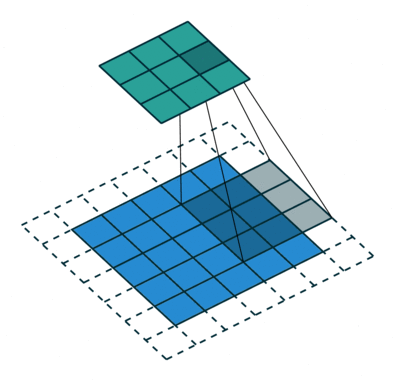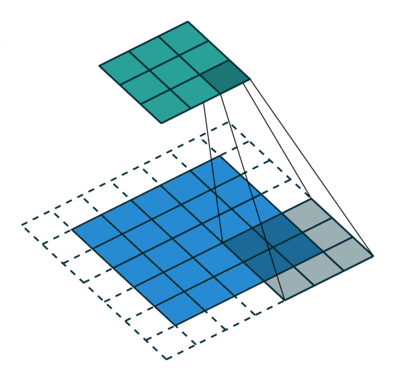
Padding, strides (odd)
填充、步幅(奇数)
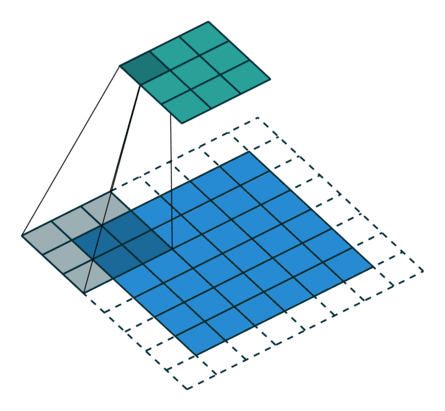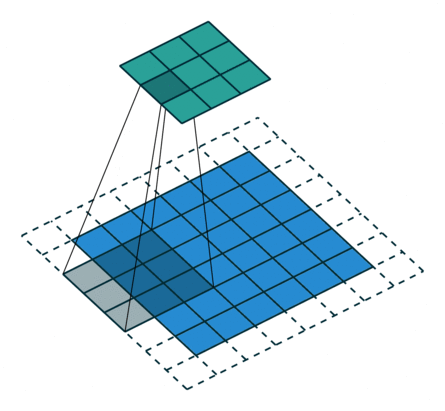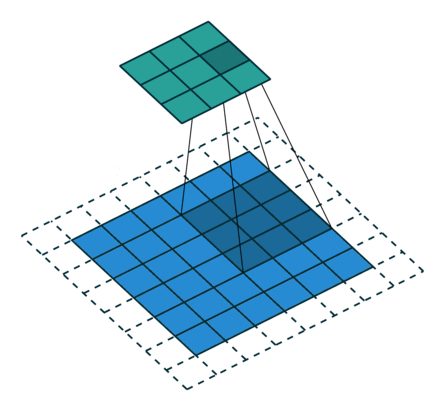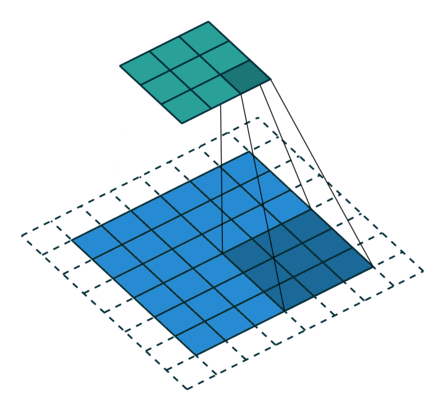
卷积代码演示
python
import torch
import torch.nn.functional as F
input = torch.tensor([
[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]
])
kernel = torch.tensor([
[1, 2, 1],
[0, 1, 0],
[2, 1, 0]
])
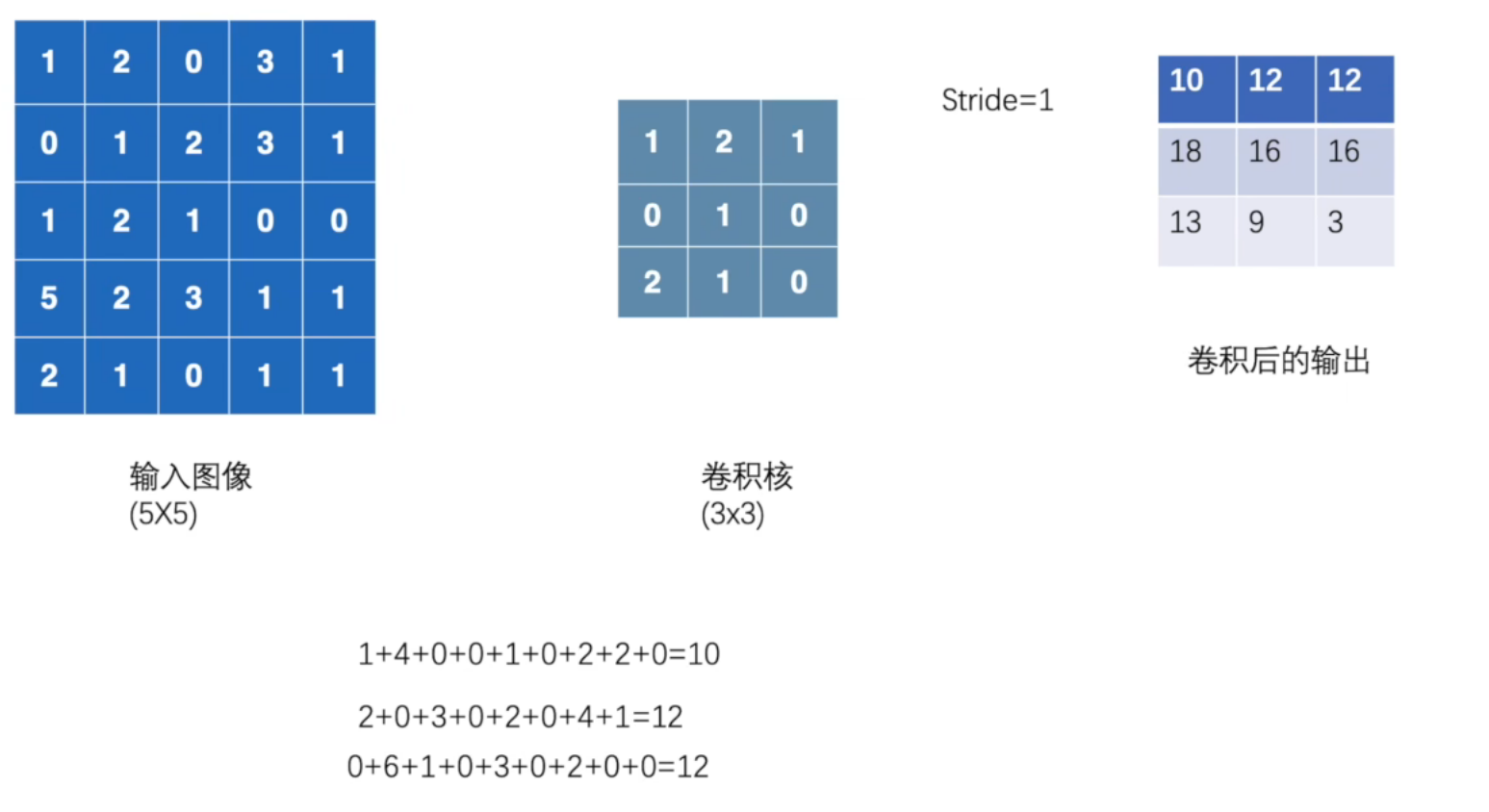
print(input.shape)
print(kernel.shape)
"""
打印结果:
torch.Size([5, 5])
torch.Size([3, 3])
不符合卷积层的输入要求
在最简单的情况下,输入尺寸为 (N,C,H,W)
N:批量数
C:通道数
H:高度
W:宽度
"""
# 尺寸变换
input = torch.reshape(input, (1, 1, 5, 5))
kernel = torch.reshape(kernel, (1, 1, 3, 3))
print(input.shape)
print(kernel.shape)
"""
打印结果:
torch.Size([1, 1, 5, 5])
torch.Size([1, 1, 3, 3])
"""
output = F.conv2d(input, kernel, stride=1)
print(output)
"""
打印结果:
tensor([[[[10, 12, 12],
[18, 16, 16],
[13, 9, 3]]]])
"""
# stride为2时
output2 = F.conv2d(input, kernel, stride=2)
print(output2)
"""
打印结果:
tensor([[[[10, 12],
[13, 3]]]])
"""卷积操作分析:
当设置了padding时候 ,输入的量得到了填充 默认填充为0
进行卷积操作的时候,还是从左上角开始

python
# 设置padding
output3=F.conv2d(input,kernel,stride=1,padding=1)
print(output3)
"""
打印结果:
tensor([[[[ 1, 3, 4, 10, 8],
[ 5, 10, 12, 12, 6],
[ 7, 18, 16, 16, 8],
[11, 13, 9, 3, 4],
[14, 13, 9, 7, 4]]]])
"""综合代码案例
python
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../torchvision_dataset", train=False,
transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64)
class MyModel(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = Conv2d(3, 6, 3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
return x
module1 = MyModel()
step = 0
writer = SummaryWriter("logs_test3")
for data in dataloader:
imgs, target = data
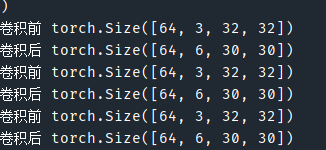
output = module1(imgs)
print("卷积前", imgs.shape)
print("卷积后", output.shape)
# 卷积前 torch.Size([64, 3, 32, 32])
writer.add_images("input", imgs, step)
# 卷积后 torch.Size([64, 6, 30, 30])
# 直接用会报错 因为6通道不好显示
# 一个不严谨的方法:reshape为3通道
# [64, 6, 30, 30]->[***, 3, 30, 30]
output = torch.reshape(output, (-1, 3, 30, 30)) # 参数为-1时,会根据后面的自己计算
writer.add_images("output", output, step)
step += 1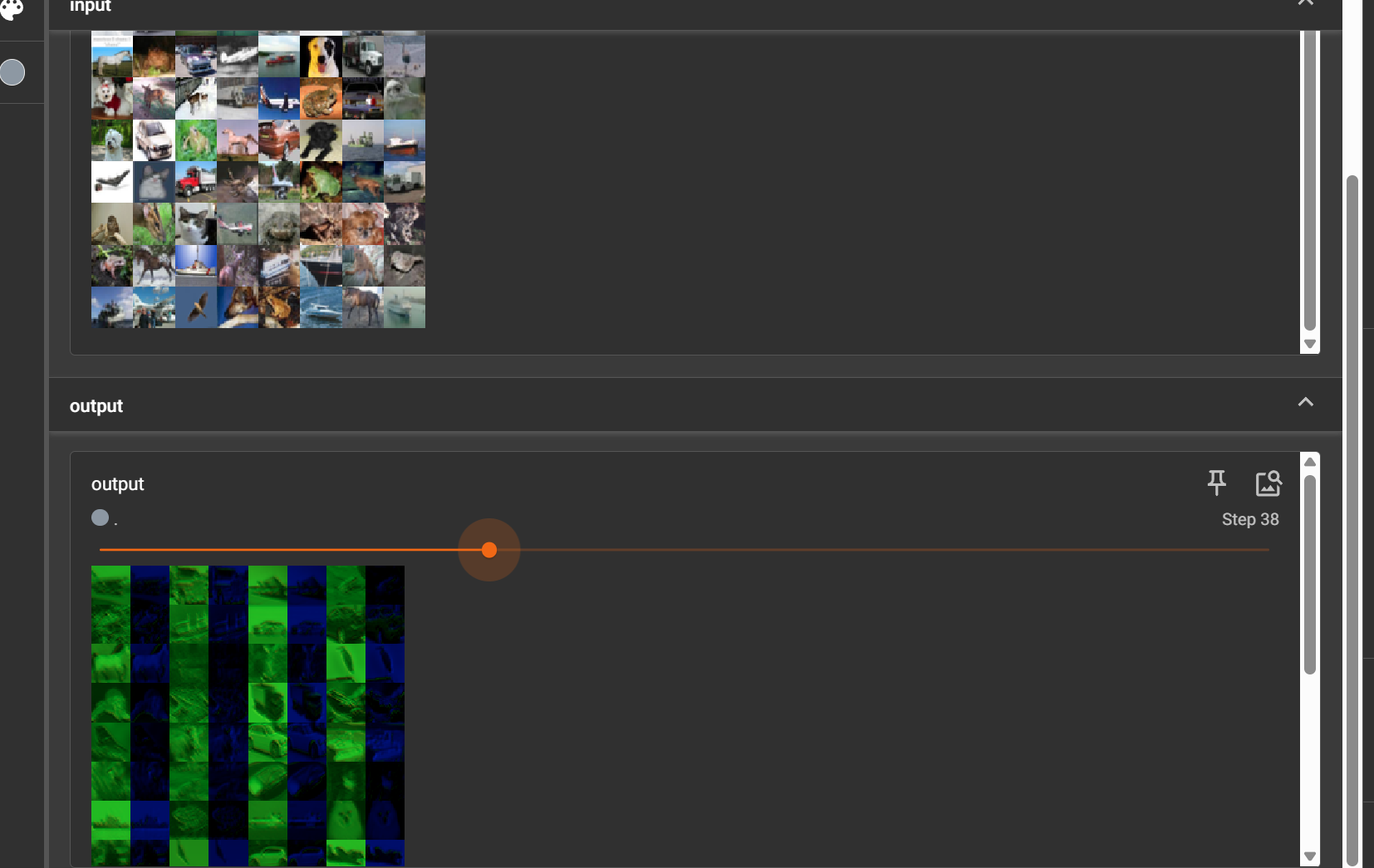
在卷积操作中,输出通道数由卷积核的数量决定。
每个输出通道由一个卷积核扫描 3 个输入通道后求和
bash
输入: 32×32×3(3通道)
┌───────────┐ ┌───────────┐ ┌───────────┐
│ 红通道 │ │ 绿通道 │ │ 蓝通道 │
│ 32×32×1 │ │ 32×32×1 │ │ 32×32×1 │
└───────────┘ └───────────┘ └───────────┘
│ │ │
└────────┬────────┴────────┬────────┘
│ │
6个3×3×3卷积核 │
│ │
┌────────┴─────────────────┘
▼
输出: 30×30×6(6通道)
┌───────────┐ ┌───────────┐ ┌───────────┐
│ 特征图1 │ │ 特征图2 │ │ 特征图3 │
│ 30×30×1 │ │ 30×30×1 │ │ 30×30×1 │
└───────────┘ └───────────┘ └───────────┘
│ │ │
┌───────────┐ ┌───────────┐ ┌───────────┐
│ 特征图4 │ │ 特征图5 │ │ 特征图6 │
│ 30×30×1 │ │ 30×30×1 │ │ 30×30×1 │
└───────────┘ └───────────┘ └───────────┘3*3*3卷积核的理解:
不是3个一样的3*3的子核(每一个子核也不一样),也不是3个卷积核
一个完整的卷积核是包含所有输入通道对应子核的集合,而不是单个通道的子核。
输出第 1 个通道的特征图,就是由 "第 1 个完整卷积核"(包含 3 个子核)分别对 RGB 三个通道计算后相加得到的。
"卷积核" 指的是对应 1 个输出通道的整体结构(3×3×3),而子核只是其内部组成部分。就像 "1 辆汽车由 4 个轮子组成,但我们说'1 辆车'而不是'4 个轮子'"------ 这里的逻辑是一致的。
调用前后图片尺寸发生变化
图像尺寸从 32×32 变为 30×30 是由卷积操作的数学特性 决定的。因为使用了3×3 的卷积核且没有添加填充(padding=0),导致边缘像素无法被卷积核完全覆盖。
计算输出尺寸的公式:
bash
输出尺寸 = 向下取整[(输入尺寸 - 卷积核大小 + 2×填充) ÷ 步长] + 1
官方公式:

为什么需要多个输出通道?
卷积神经网络的核心思想是用多个卷积核提取不同的特征。每个输出通道对应一个独特的卷积核,它会学习检测特定的模式(如边缘、纹理、颜色等)。
例如:
-
第 1 个卷积核可能学会检测水平边缘。
-
第 2 个卷积核可能学会检测垂直边缘。
-
第 3-6 个卷积核可能学会检测更复杂的纹理或颜色模式。