基础知识
-
张量Tensor:多维
创建张量:
pythonimport tendorflow as tf tf.constant(张量内容,dtype)转换成张量:
pythontf.convert_to_tenor(数据名,dtype)全0 全1 填充
pythontf.zero(维度) tf.ones(维度) tf.fill(维度,指定值)生成正态分布的随机数
pythontf.random.normal(维度,mean,stddev)生成截断式正太分布的随机数 (μ-2σ,μ+2σ)
pythontf.random.truncated_normal(维度,mean,stddev)生成均匀分布随机数
tf.random.uniform(维度,minval,maxval)常见函数
python#tensor->其他数据类型 tf.cast(张量,dtype) #最小值 最大值 tf.reduce_min(张量,axis) tf.reduce_max(张量,axis) #axis:axis=1:行;axis=0:列 #将变量标记为 可训练 tf.Variable() #四则运算 需要维度相同 tf.add(tensor1,tensor2) tf.substract(t1,t2) tf.multiply(t1,t2) tf.divide(t1,t2) #平方 次方 开方 tf.square(t) tf.pow(t,n) tf.sqrt(t) #矩阵乘 tf.matmul(矩阵1,矩阵2) #切分传入张量的第一维度 生成输入的特征和标签对 构建数据集 data = tf.data.Dataset.from_tensor_slices((特征,标签)) #求梯度 with tf.GradientTape() as tape: ... ... grad = tape.gradient(函数,对谁求导) #遍历每个元素 for imgs,labels in enumerate(datas): print(imgs) print(labels) #独热编码 tf.one_hot(待转换数据,depth=几分类) #n分类的n个输出通过softmax() 符合概率分布 tf.nn.softmax(x) #赋值 w = tf.Variable(4) w.assign_sub(1) # w -= 1 #最大值索引 tf.argmax(tensor1,axis) #条件 tf.where(条件,真返回A,假返回B) #返回随机数 seed=常数 每次生成随机数相同 np.random.RandomState(seed) #两个数组按垂直方向叠加 np.vstack((a,b)) #还有一些函数 np.mgrid[ 起始值 : 结束值 : 步长 ,起始值 : 结束值 : 步长 , ... ] x.ravel( ) 将x变为一维数组,"把 . 前变量拉直" np.c_[ ] 使返回的间隔数值点配对
神经网络优化过程
-
神经网络NN 复杂度
-
层数 = 隐藏层数 + 输出层(除了输入层)
-
空间复杂度 = 总的权值个数+总的偏置个数
-
时间复杂度 = 总的权值个数
-
-
学习率 learning rate:lr
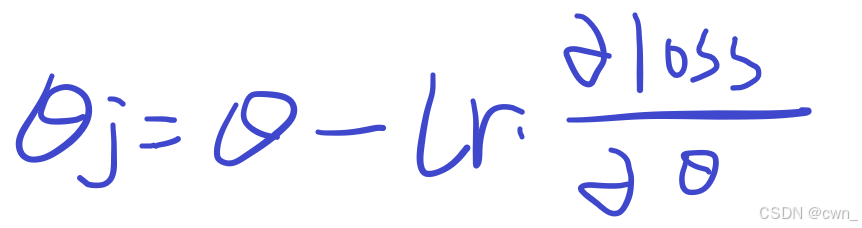
学习率过小:参数更新慢 模型收敛慢
学习率过大:不容易找到梯度的极小值 来回震荡
策略:
指数衰减学习率:先用较大的学习率,快速得到最优解,逐步减小学习率,使模型在训练后期稳定
指数衰减学习率 = 初始学习率 * 学习率衰减率 ^( 当前轮数/ 多少轮衰减一次 )
-
激活函数
非线性函数
为了增加模型的复杂度,防止模型过拟合
常见:
-
sigmoid()
f(x) = 1/(1+exp(-x))
-
Tanh()
f(x) = (1-exp(-2x))/(1+exp(-2x))
-
Relu()
f(x) = {0|x<0;x|x>=0}
-
Leaky Relu()
f(x) = max(ax,a)
-
初学者建议:
首选relu()
lr设置较小值
特征标准化(0,1)
初始参数正态分布(0,sqrt(2/当前层输入特征个数))
-
-
损失函数loss
-预测值y与真实值y_的差距
-
均方误差 MSE
pythonloss_mse = tf.reduce_mean(tf.square(y_-y)) -
交叉熵损失函数 CE
pythontf.losses.categorical_crossentropy(y_,y) -
softmax 和 CE 结合
pythontf.nn.softmax_cross_entropy_with_logits(y_,y)
-
-
欠拟合 & 过拟合
-
欠拟合:训练集拟合效果差
解决:增加输入特征项 增加参数 减少正则化参数
-
过拟合:训练太多了 泛化能力差 验证集测试集拟合效果差 待优化的参数过多容易导致模型过拟合
解决:数据清洗 增大训练集 采用正则化 增大正则化参数
-
-
正则化
正则化在损失函数中引入模型复杂度指标 利用给参数加权值 弱化数据集的噪声
-
L1 正则化
会使很多参数变为0,因此L1正则化可以通过稀疏参数,减少参数数量,降低复杂度
-
L2 正则化
会使很多参数接近0,因此L2正则化可以通过减小参数的值来降低复杂度
pythontf.nn.l2_loss(weight)
-
-
优化器
-
SGD 随机梯度下降
pythonw1.assign_sub(lr*grads[0]) b1.assign_sub(lr*grads[1]) -
SGDM 增加一阶动量
pythonm_w = beta * m_w + (1 - beta) * grads[0] w1.assign_sub(lr*m_w) -
Adagrad 增加二阶动量
pythonv_w += tf.square(grads[0]) w1.assign_sub(lr*grads[0]/tf.sqrt(v_w)) -
RMSProp 增加二阶动量
pythonv_w += beta * v_w + (1 - beta) * tf.square(grads[0]) w1.assign_sub(lr*grads[0]/tf.sqrt(v_w)) -
Adam 结合一阶和二阶
python省略
-
搭建神经网络
-
tensorflow搭建神经网络
- import 导入各种包
- train test 训练集&测试集
- model=tf.keras.models.Sequential 网络结构
- model.compile 优化器 损失函数 评判标准
- model.fit 训练模型
- model.summary 我称之为文字版可视化
- code:
pythonimport tensorflow as tf from sklearn import datasets import numpy as np x_train = datasets.load_iris().data y_train = datasets.load_iris().target np.random.seed() np.random.shuffle(x_train) np.random.seed() np.random.shuffle(y_train) tf.random.set_seed() model = tf.keras.models.Sequential([ tf.keras.layer.Dense(3,activation='softmax',kernel_reqularizer=tf.keras.regularizers.l2()) ]) model.compile(optimizer=tf.keras.optimizers.SGD(lr=0.1), loss = tf.keras.losses.SparesCategoricalCrossentropy(from_logits=False), metrics = ['sparse_categorical_accuracy']) model.fit(x_train,y_train,batch_size=32,epochs=500,validation_split=0.2,validation_freq=20) model.summary() -
model
可以定义成一个类
pythonclass MyModel(Model): def __init__(self): super(MyModel,self).__init__() 定义网络结构 #前向传播 def call(self,x): 调用上面定义的网络结构 return result myModel = MyModel() result = myModel(x) -
神经网络功能扩展
-
自制数据集
-
数据增强
pythonimage_gen_train = tf.keras.preprocessing.image.ImageDataGenerator( rescale = 所有的数据将乘以该数值 rotation_range = 随机旋转角度数范围 width_shift_range = 随机宽度偏移量 height_shift_range = 随机高度偏移量 horizontal_flip = 是否随机水平翻转 zoom_range = 随机缩放的范围[1-n,1+n] ) image_gen_train.fit(x_train) ... ... model.fit(image_gen_train.flow(x_train,y_train,batch_size=32),....) -
断点续训,存取模型
-
python
#读取模型
checkpoint_save_path = '保存路径'
if os.path.exists(checkpoint_save_path+'.index'):
print('-----load the model-----')
model.load.weights(checkpoint_save_path)
#保存模型
cp_callback = tf.keras.callbacks.ModelCheckpoint(
filepath = checkpoint_save_path,
save_weights_only = True,
save_best_only = True
)
history = model.fit(x_train,y_train,batch_size=32,epochs=5,
validation_data = (x_test,y_test),validation_freq=1,
callbacks = [cp_callback]
)-
参数提取 把参数存入文本
python#threshold:超过多少省略显示 np.set_printoptions(threshold=np.inf) #inf:无穷大 ... ... print(model.trainable_variables) file = open('./weight.txt,'w) for v in model.trainable_variables: file.write(str(v.name)+'\n') file.write(str(v.shape)+'\n') file.write(str(v.numpy())+'\n') file.close() -
训练指标可视化 查看训练效果
acc loss:
pythonacc = history.history['sparse_categorical_accuracy'] val_acc = history.history['val_sparse_categorical_accuracy'] loss = history.history['losss'] val_loss = history.history['val_loss'] plt......... -
应用
python#复现模型 前向传播 model = tf.keras.models.Sequential([ #拉直层 tf.keras.layers.Flatten(), #全连接层 tf.keras.layers.Dense(128,activation='relu'), tf.keras.layers.Dense(10,activation='softmax') ]) #加载参数 model.load_weights(model_save_path) #预测 result = model.predict(x_predict)
卷积神经网络 CNN
-
卷积层
卷积:图像特征提取
-
池化层
池化:下采样 减少特征数
-
全连接层
全连接NN :每个神经元与前后相邻层的每一个神经元都有连接关系,输入是特征,输出为预测的结果
会先对原始图像进行特征提取 再把提取到的特征送给全连接网络
-
CNN
-
CNN:卷积神经网络
借助卷积核提取特征后,送入全连接网络
卷积就是特征提取器
-
CNN主要模块流程
- 卷积层 Conv2D
- 批标准化层 BatchNormalization
- 激活层 Activation
- 池化层 MaxPool2D
- 舍弃层 Dropout
- 拉直层 Flatten
- 全连接层 Dense
-
说明
根据网络结构具体编码
有的网络结构包含多个卷积层和池化层 也是为了更好的提取特征
-
-
感受野:CNN各输出特征图中的每个像素点 在原始的输入图片上映射区域的大小
-
padding
全零填充:可以保证输入图片的维度和输出的特征图的维度相同
padding -SAME:全0填充 输出特征图的维度=输入特征图的维度/步长 (向上取整)
padding -VALID:不全0填充 输出特征图的维度=(输入特征图的维度-卷积核维度+1)/ 步长 (向上取整)
-
卷积层 conv
pythonConv2D(filters,kernel_size,strides,padding,activation,input_shape)filters = 卷积核个数
kernel_size = 卷积核尺寸
strides = 步长
activation = 激活函数(有BN此处不写)
input_shape = (高,宽,通道数) 可省略
-
批标准化BN batch normalization
标准化:mean:0 std:1
批标准化:对一小批数据batch 做标准化处理
BN层位于卷积层之后 激活层之前
pythonBatchNormalization() -
池化 pooling
最大池化:提取图片纹理
均值池化:保留背景特征
pythontf.keras.layers.MaxPool2D(pool_size,strides,padding) tf.keras.layers.AveragePooling2D() -
舍弃 dropout
在神经网络训练时,将一部分神经元按照一定概率从神经网络中暂时舍弃,神经网络使用的时候,被舍弃的神经元恢复连接
pythonDropout(舍弃的概率)
-
-
经典CNN
-
LeNet
共享卷积核,减少网络参数
-
ALexNet
使用relu激活函数,使用dropout
-
VGGNet
小尺寸卷积核减少参数,网络结构规整,适合并行加速
-
Inception
一层内使用不同尺寸卷积核,提升感知力,使用BN,缓解梯度消失
-
ResNet
层间残差跳连,引入前方信息,缓解模型退化,使神经网络参数加深成为可能
-
循环神经网络 RNN
-
网络结构
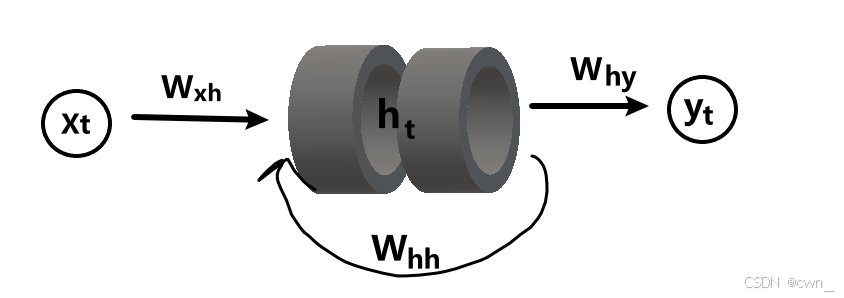
-
循环核
参数时间共享 循环层提取时间信息
ht = tanh(Xt×Wxh+ht-1×Whh+bh)
yt = softmax(ht×why+by)
前向传播:记忆体内存储的状态信息ht,在每个时刻都被刷新,三个参数矩阵Wxh Whh Why固定不变
反向传播:三个参数矩阵被梯度下降法更新
-
循环计算层
层数:循环核个数
pythontf.keras.layers.SimpleRNN(记忆体个数,activation,return_sequences=是否每个时刻输出ht到下一层) #return_sequences = True:各时间步输出ht #return_sequences = False:仅最后时间步输出ht -
Embedding 独热编码
用低维向量实现了编码,这种编码通过神经网络训练优化,能表达出单词见的相关性
pythontf.keras.layers.Embedding(词汇表大小,编码维度)编码维度:用几个数字表达一个单词
-
RNN
借助循环核提取时间特征后,送入全连接网络
- RNN主要模块流程
- 循环层 SimpleRNN / LSTM / GRU
- 批标准化层 BatchNormalization
- 激活层 Activation
- 池化层 GlobalMaxPool1D/GlobalAvgPool1D
- 舍弃层 Dropout
- 展平层 Reshape
- 全连接层 Dense
- RNN主要模块流程
-
经典RNN
-
简单RNN
-
LSTM
增加遗忘门 细胞态(长期记忆)记忆体(短期记忆)候选态(归纳出的新知识)
pythontf.keras.layers.LSTM(记忆体个数,return_sequences=是否返回输出) -
GRU
更新门 重置门 记忆体 候选隐藏层
pythontf.keras.layers.GPU(记忆体个数,return_sequences=是否返回输出) -
RNN 的核心是循环层(LSTM 和 GRU 是改进型循环层,解决长序列依赖问题)
-