基于MySQL实现基础图数据库
一、概念
图数据库是一种用于存储和查询具有复杂关系的数据的数据库。在这种数据库中,数据被表示为节点(实体)和边(关系)。图数据库的核心优势在于能够快速地查询和处理节点之间的关系。
图数据库特点:
- 高效处理复杂关系:图数据库擅长处理复杂、多层级的关系,这使得它在社交网络分析、推荐系统等领域具有显著优势。
- 灵活的查询语言:图数据库通常使用类似自然语言的查询语言,如Gremlin或Cypher,使得查询过程更加直观。
专业的图数据库,可以存储千万、甚至亿级别的边和节点,详情可参考文章:https://blog.csdn.net/weixin_45565886/article/details/149290447
但并非只有专业的图数据库可以实现图的一些操作,比如:图挖掘,实际也可以通过MySQL来实现。本文主要讲解如何通过MySQL构建图数据存储,当然MySQL构建图结构数据与专业图数据库还是有能力上的差异,比如:图算法需要自己通过SQL实现、整体效率不及专业图数据库等。
二、应用场景
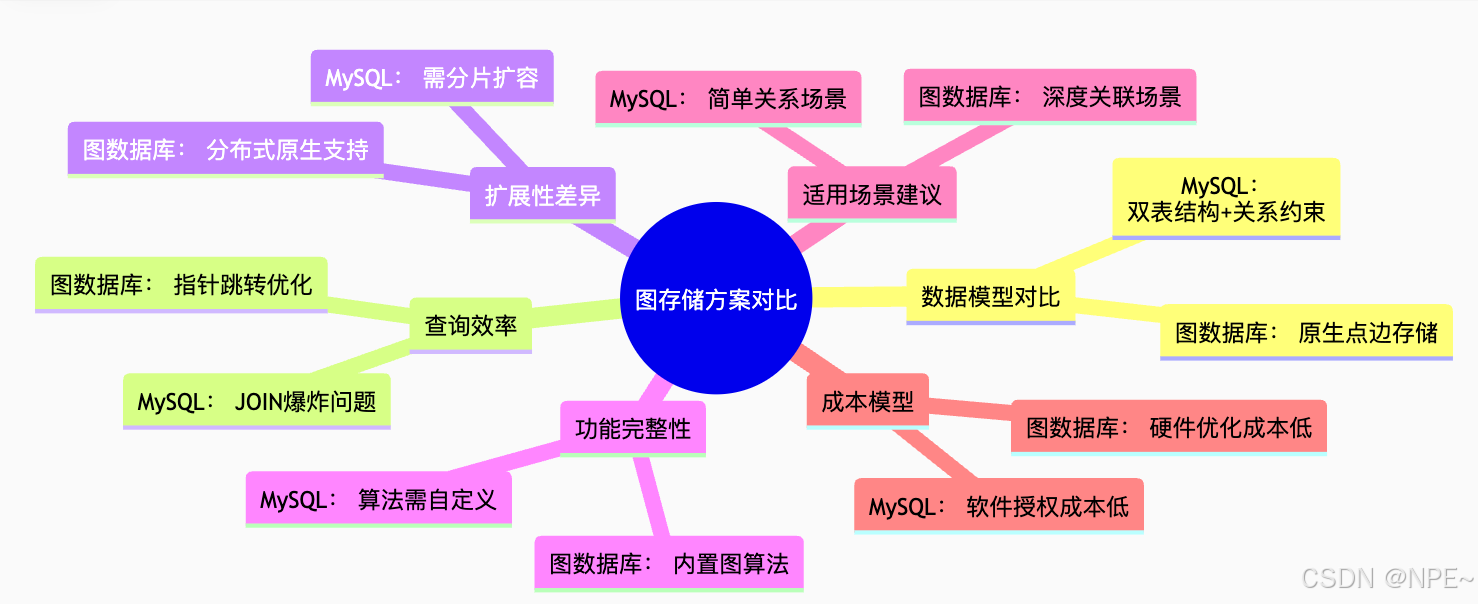
基于MySQL实现图数据库,是通过多表关联来实现操作,因此性能和整体能力肯定不及专业图数据库。
MySQL实现图存储最适合场景:
- 中小规模图数据(≤10万节点)
- 需要强事务保证的业务系统
- 图查询以1-3度关系为主
- 已有MySQL基础设施且预算有限
专业图数据库场景:
- 大规模图数据(≥100万节点)
- 需要复杂图算法(社区发现等)
- 深度路径查询(≥4度关系)
- 实时图分析需求
三、实现
环境搭建
首先我们需要有MySQL环境,我这里为了方便就直接通过docker搭建MySQL:
bash
docker run -d \
--name mysql8 \
--restart always \
-p 3306:3306 \
-e TZ=Asia/Shanghai \
-e MYSQL_ROOT_PASSWORD=123456 \
-v /Users/ziyi2/docker-home/mysql/data:/var/lib/mysql \
mysql:8.0
存储结构定义
图主要包含节点、边,因此我们这里选择定义两个数据表来实现。同时节点和边都具有很多属性,且为kv对,这里我们就采用MySQL中的JSON格式存储。
sql
-- 节点表
CREATE TABLE IF NOT EXISTS node (
node_id BIGINT NOT NULL AUTO_INCREMENT PRIMARY KEY,
properties JSON COMMENT '节点属性'
);
-- 边表
CREATE TABLE IF NOT EXISTS edge (
edge_id BIGINT NOT NULL AUTO_INCREMENT PRIMARY KEY,
source_id BIGINT NOT NULL COMMENT '源节点ID',
target_id BIGINT NOT NULL COMMENT '目标节点ID',
properties JSON COMMENT '边属性',
FOREIGN KEY(source_id) REFERENCES node(node_id) ON DELETE CASCADE,
FOREIGN KEY(target_id) REFERENCES node(node_id) ON DELETE CASCADE
);
-- 索引创建
CREATE INDEX idx_edge_source ON edge(source_id);
CREATE INDEX idx_edge_target ON edge(target_id);基础功能
创建
节点创建:
sql
-- 创建用户节点
INSERT INTO node (properties) VALUES
('{"type": "user", "name": "张三", "age": 28, "interests": ["篮球","音乐"]}'),
('{"type": "user", "name": "李四", "age": 32, "interests": ["电影","美食"]}'),
('{"type": "user", "name": "王五", "age": 27, "interests": ["跑步","美食"]}');边创建:
sql
-- 创建好友关系
INSERT INTO edge (source_id, target_id, properties) VALUES
(1, 3, '{"type": "friend", "since": "2023-01-01"}'),
(2, 3, '{"type": "friend", "since": "2023-01-01"}');查询
- 根据节点属性查询节点
sql
SELECT * from node
where properties->>'$.name' = '张三';
- 查询某个节点关联的另一个节点
sql
-- 查询张三的好友
SELECT n2.node_id, n2.properties->>'$.name' AS friend_name
FROM edge e
JOIN node n1 ON e.source_id = n1.node_id
JOIN node n2 ON e.target_id = n2.node_id
WHERE n1.properties->>'$.name' = '张三'
AND e.properties->>'$.type' = 'friend';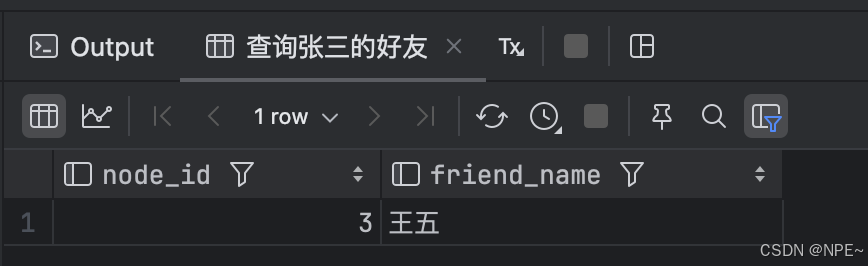
- 查询两个节点的公共节点。查询共同好友,因为张三、王五是好友,李四、王五是好友,所以张三跟李四的共同好友就是王五
sql
-- 查询共同好友
SELECT n3.properties->>'$.name' AS common_friend
FROM edge e1
JOIN edge e2 ON e1.target_id = e2.target_id
JOIN node n1 ON e1.source_id = n1.node_id
JOIN node n2 ON e2.source_id = n2.node_id
JOIN node n3 ON e1.target_id = n3.node_id
WHERE n1.properties->>'$.name' = '张三'
AND n2.properties->>'$.name' = '李四'
AND e1.properties->>'$.type' = 'friend'
AND e2.properties->>'$.type' = 'friend';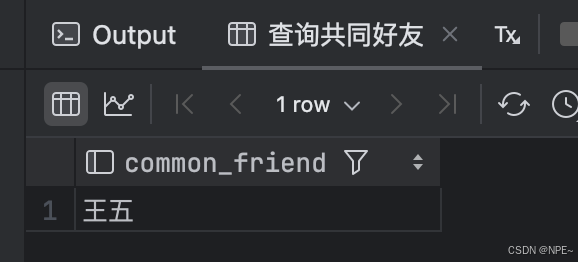
递归
查找某个节点关联的所有节点,类似与Neo4j中的Expand展开。
sql
-- 递归查找所有关联节点
WITH RECURSIVE node_path AS (
SELECT
source_id,
target_id,
properties,
1 AS depth
FROM edge
WHERE source_id = 1
UNION ALL
SELECT
np.source_id,
e.target_id,
e.properties,
np.depth + 1
FROM node_path np
JOIN edge e ON np.target_id = e.source_id
WHERE np.depth < 5 -- 控制最大深度
)
SELECT * FROM node_path;效果:

更新
sql
-- 更新节点已有属性值【更新完之后查询效果】
SELECT * from node
where properties->>'$.name' = '张三';
UPDATE node
SET properties = JSON_SET(properties, '$.age', 29)
WHERE properties->>'$.name' = '张三';
-- 新增节点属性:添加新兴趣
UPDATE node
SET properties = JSON_ARRAY_APPEND(properties, '$.interests', '游泳')
WHERE properties->>'$.name' = '张三';
SELECT * from node
where properties->>'$.name' = '张三';
删除
sql
-- 删除关系
DELETE FROM edge
WHERE source_id = (SELECT node_id FROM node WHERE properties->>'$.name' = '张三')
AND target_id = (SELECT node_id FROM node WHERE properties->>'$.name' = '王五');
-- 删除节点及其关系
DELETE FROM node WHERE properties->>'$.name' = '张三';下面演示删除关系过程,删除节点同理:
- 删除之前
sql
select * from edge
WHERE source_id = (SELECT node_id FROM node WHERE properties->>'$.name' = '张三')
AND target_id = (SELECT node_id FROM node WHERE properties->>'$.name' = '王五');
- 执行SQL删除后
sql
-- 删除关系
DELETE FROM edge
WHERE source_id = (SELECT node_id FROM node WHERE properties->>'$.name' = '张三')
AND target_id = (SELECT node_id FROM node WHERE properties->>'$.name' = '王五');
图算法实现
1. 度中心性算法
度中心性算法(Degree Centrality)
- 介绍:中心性是刻画节点中心性的最直接度量指标。节点的度是指一个节点连接的边的数量,一个 节点的度越大就意味着这个节点的度中心性越高,该节点在网络中就越重要。对于有向图,还 要分别考虑出度/入度/出入度。
- 计算:统计节点连接的边数量。
- 应用:计算某个领域的KOL关键人物,头部商家、用户、up主...
数据构造:
sql
-- 删除之前数据,避免用户数据重复等
DELETE FROM edge;
DELETE FROM node;
ALTER TABLE node AUTO_INCREMENT = 1;
ALTER TABLE edge AUTO_INCREMENT = 1;
-- 创建用户节点
INSERT INTO node (properties) VALUES
('{"type":"user","name":"张三","title":"科技博主"}'),
('{"type":"user","name":"李四","title":"美食达人"}'),
('{"type":"user","name":"王五","title":"旅行摄影师"}'),
('{"type":"user","name":"赵六","title":"投资专家"}'),
('{"type":"user","name":"钱七","title":"健身教练"}'),
('{"type":"user","name":"周八","title":"宠物博主"}'),
('{"type":"user","name":"吴九","title":"历史学者"}');
-- 创建关注关系
INSERT INTO edge (source_id, target_id, properties) VALUES
-- 张三被关注关系
(2,1, '{"type":"follow","timestamp":"2023-01-10"}'),
(3,1, '{"type":"follow","timestamp":"2023-01-12"}'),
(4,1, '{"type":"follow","timestamp":"2023-01-15"}'),
(5,1, '{"type":"follow","timestamp":"2023-01-18"}'),
-- 李四被关注关系
(1,2, '{"type":"follow","timestamp":"2023-01-20"}'),
(3,2, '{"type":"follow","timestamp":"2023-01-22"}'),
(6,2, '{"type":"follow","timestamp":"2023-01-25"}'),
-- 王五被关注关系
(1,3, '{"type":"follow","timestamp":"2023-02-01"}'),
(7,3, '{"type":"follow","timestamp":"2023-02-05"}'),
-- 赵六被关注关系
(4,4, '{"type":"follow","timestamp":"2023-02-10"}'); -- 自关注(特殊情况)度中心性算法实现:
sql
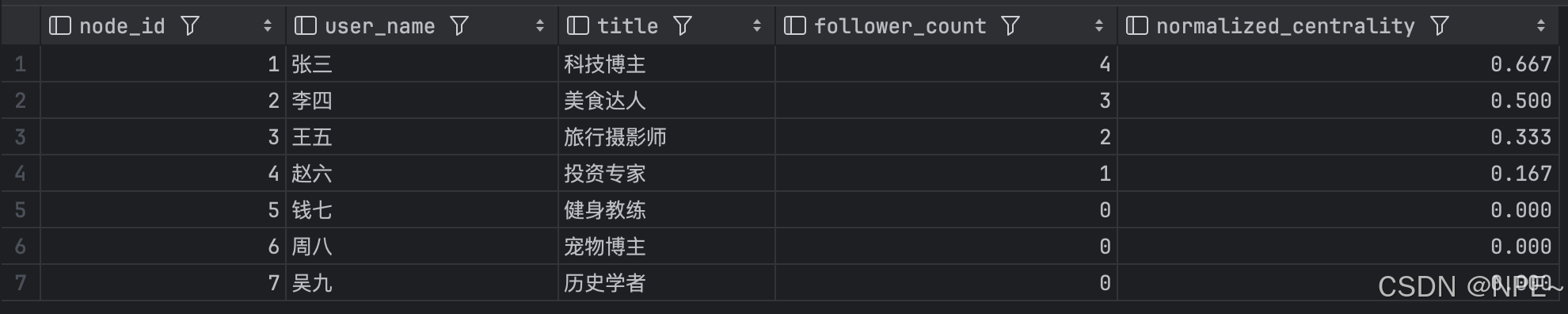
-- 计算用户被关注度(入度中心性)
SELECT
n.node_id,
n.properties->>'$.name' AS user_name,
n.properties->>'$.title' AS title,
COUNT(e.edge_id) AS follower_count,
-- 计算标准化中心性(0-1范围)
ROUND(COUNT(e.edge_id) / (SELECT COUNT(*)-1 FROM node WHERE properties->>'$.type'='user'), 3) AS normalized_centrality
FROM node n
LEFT JOIN edge e ON n.node_id = e.target_id
AND e.properties->>'$.type' = 'follow'
WHERE n.properties->>'$.type' = 'user'
GROUP BY n.node_id
ORDER BY follower_count DESC;效果:
2. 相似度算法
图场景中相似度算法主流的主要包含:余弦相似度、杰卡德相似度。这里主要介绍下Jaccard相似度算法。
- 杰卡德相似度(Jaccard Similarity)
- 介绍:节点A和节点B的杰卡德相似度定义为,节点A邻居和节点B邻居的交集节点数量除以并集节点 数量。Jaccard系数计算的是两个节点的邻居集合的重合程度,以此来衡量两个节点的相似度。
- 计算:计算两个节点邻居集合的交集数量和并集数量,然后再相除。公式:|A ∩ B| / (|A| + |B| - |A ∩ B|)
- 应用:共同好友推荐、电商商品推荐猜你喜欢
数据构造:
sql
-- 清理之前数据,避免混淆
DELETE FROM edge;
DELETE FROM node;
ALTER TABLE node AUTO_INCREMENT = 1;
ALTER TABLE edge AUTO_INCREMENT = 1;
-- 创建用户节点(包含风险标记)
INSERT INTO node (properties) VALUES
('{"type":"user","name":"张三","phone":"13800138000","risk_score":5,"register_time":"2023-01-01"}'),
('{"type":"user","name":"李四","phone":"13900139000","risk_score":85,"register_time":"2023-01-05"}'), -- 黑产用户
('{"type":"user","name":"王五","phone":"13700137000","risk_score":92,"register_time":"2023-01-10"}'), -- 黑产用户
('{"type":"user","name":"赵六","phone":"13600136000","risk_score":15,"register_time":"2023-01-15"}'),
('{"type":"user","name":"钱七","phone":"13500135000","risk_score":8,"register_time":"2023-01-20"}'),
('{"type":"user","name":"孙八","phone":"13400134000","risk_score":95,"register_time":"2023-01-25"}'); -- 黑产用户
-- 创建设备节点
INSERT INTO node (properties) VALUES
('{"type":"device","device_id":"D001","model":"iPhone12","os":"iOS14"}'),
('{"type":"device","device_id":"D002","model":"HuaweiP40","os":"Android10"}'),
('{"type":"device","device_id":"D003","model":"Xiaomi11","os":"Android11"}'),
('{"type":"device","device_id":"D004","model":"OPPOReno5","os":"Android11"}');
-- 创建银行卡节点
INSERT INTO node (properties) VALUES
('{"type":"bank_card","card_no":"622588******1234","bank":"招商银行"}'),
('{"type":"bank_card","card_no":"622848******5678","bank":"农业银行"}'),
('{"type":"bank_card","card_no":"622700******9012","bank":"建设银行"}'),
('{"type":"bank_card","card_no":"622262******3456","bank":"交通银行"}');
-- 创建IP地址节点
INSERT INTO node (properties) VALUES
('{"type":"ip","ip_address":"192.168.1.101","location":"广东深圳"}'),
('{"type":"ip","ip_address":"192.168.2.202","location":"浙江杭州"}'),
('{"type":"ip","ip_address":"192.168.3.303","location":"江苏南京"}'),
('{"type":"ip","ip_address":"192.168.4.404","location":"北京朝阳"}');
-- 创建关联关系
INSERT INTO edge (source_id, target_id, properties) VALUES
-- 用户-设备关系
(1,7, '{"type":"use","first_time":"2023-01-01"}'), -- 张三使用D001
(2,7, '{"type":"use","first_time":"2023-01-05"}'), -- 李四使用D001
(2,8, '{"type":"use","first_time":"2023-01-06"}'), -- 李四使用D002
(3,8, '{"type":"use","first_time":"2023-01-10"}'), -- 王五使用D002
(3,9, '{"type":"use","first_time":"2023-01-11"}'), -- 王五使用D003
(4,10,'{"type":"use","first_time":"2023-01-15"}'), -- 赵六使用D004
(5,9, '{"type":"use","first_time":"2023-01-20"}'), -- 钱七使用D003
(6,7, '{"type":"use","first_time":"2023-01-25"}'), -- 孙八使用D001
-- 用户-银行卡关系
(1,11, '{"type":"bind","time":"2023-01-02"}'), -- 张三绑定银行卡1
(2,11, '{"type":"bind","time":"2023-01-05"}'), -- 李四绑定银行卡1
(2,12, '{"type":"bind","time":"2023-01-07"}'), -- 李四绑定银行卡2
(3,12, '{"type":"bind","time":"2023-01-11"}'), -- 王五绑定银行卡2
(3,13, '{"type":"bind","time":"2023-01-12"}'), -- 王五绑定银行卡3
(4,14, '{"type":"bind","time":"2023-01-16"}'), -- 赵六绑定银行卡4
(5,13, '{"type":"bind","time":"2023-01-21"}'), -- 钱七绑定银行卡3
(6,11, '{"type":"bind","time":"2023-01-26"}'), -- 孙八绑定银行卡1
-- 用户-IP关系
(1,15, '{"type":"login","time":"2023-01-03"}'), -- 张三登录IP1
(2,15, '{"type":"login","time":"2023-01-05"}'), -- 李四登录IP1
(2,16, '{"type":"login","time":"2023-01-08"}'), -- 李四登录IP2
(3,16, '{"type":"login","time":"2023-01-10"}'), -- 王五登录IP2
(3,17, '{"type":"login","time":"2023-01-13"}'), -- 王五登录IP3
(4,18, '{"type":"login","time":"2023-01-17"}'), -- 赵六登录IP4
(5,17, '{"type":"login","time":"2023-01-22"}'), -- 钱七登录IP3
(6,15, '{"type":"login","time":"2023-01-27"}'); -- 孙八登录IP1算法实现:
Jaccard相似度数学公式:|A ∩ B| / (|A| + |B| - |A ∩ B|)
sql
-- 基于Jaccard相似度的图相似度算法实现
WITH user_entities AS (
SELECT
u.node_id AS user_id,
(
SELECT JSON_ARRAYAGG(ed.target_id)
FROM edge ed
WHERE ed.source_id = u.node_id
AND ed.properties->>'$.type' = 'use'
AND ed.target_id IN (SELECT node_id FROM node WHERE properties->>'$.type' = 'device')
) AS devices,
(
SELECT JSON_ARRAYAGG(ec.target_id)
FROM edge ec
WHERE ec.source_id = u.node_id
AND ec.properties->>'$.type' = 'bind'
AND ec.target_id IN (SELECT node_id FROM node WHERE properties->>'$.type' = 'bank_card')
) AS cards,
(
SELECT JSON_ARRAYAGG(ei.target_id)
FROM edge ei
WHERE ei.source_id = u.node_id
AND ei.properties->>'$.type' = 'login'
AND ei.target_id IN (SELECT node_id FROM node WHERE properties->>'$.type' = 'ip')
) AS ips
FROM node u
WHERE u.properties->>'$.type' = 'user'
),
-- 已知黑产用户
black_users AS (
SELECT node_id
FROM node
WHERE properties->>'$.type' = 'user'
AND CAST(properties->>'$.risk_score' AS UNSIGNED) > 80
),
-- 相似度计算
similarity_calc AS (
SELECT
u1.user_id AS target_user,
u2.user_id AS black_user,
-- 设备相似度 (Jaccard系数): |A ∩ B| / (|A| + |B| - |A ∩ B|)
CASE
WHEN u1.devices IS NULL OR u2.devices IS NULL
OR JSON_LENGTH(u1.devices) = 0 OR JSON_LENGTH(u2.devices) = 0
THEN 0
ELSE (
-- 分子部分: |A ∩ B| (交集的大小)
SELECT COUNT(DISTINCT d1.device_id)
FROM JSON_TABLE(u1.devices, '$[*]' COLUMNS(device_id BIGINT PATH '$')) d1
INNER JOIN JSON_TABLE(u2.devices, '$[*]' COLUMNS(device_id BIGINT PATH '$')) d2
ON d1.device_id = d2.device_id
) * 1.0 / (
-- 分母部分: (|A| + |B| - |A ∩ B|) (并集的大小)
JSON_LENGTH(u1.devices) + -- |A| 集合A的大小
JSON_LENGTH(u2.devices) - -- |B| 集合B的大小
(
-- |A ∩ B| 交集的大小(再次计算用于分母)
SELECT COUNT(DISTINCT d1.device_id)
FROM JSON_TABLE(u1.devices, '$[*]' COLUMNS(device_id BIGINT PATH '$')) d1
INNER JOIN JSON_TABLE(u2.devices, '$[*]' COLUMNS(device_id BIGINT PATH '$')) d2
ON d1.device_id = d2.device_id
)
)
END AS device_sim,
-- 银行卡相似度 (Jaccard系数): |A ∩ B| / (|A| + |B| - |A ∩ B|)
CASE
WHEN u1.cards IS NULL OR u2.cards IS NULL
OR JSON_LENGTH(u1.cards) = 0 OR JSON_LENGTH(u2.cards) = 0
THEN 0
ELSE (
-- 分子部分: |A ∩ B| (交集的大小)
SELECT COUNT(DISTINCT c1.card_id)
FROM JSON_TABLE(u1.cards, '$[*]' COLUMNS(card_id BIGINT PATH '$')) c1
INNER JOIN JSON_TABLE(u2.cards, '$[*]' COLUMNS(card_id BIGINT PATH '$')) c2
ON c1.card_id = c2.card_id
) * 1.0 / (
-- 分母部分: (|A| + |B| - |A ∩ B|) (并集的大小)
JSON_LENGTH(u1.cards) + -- |A| 集合A的大小
JSON_LENGTH(u2.cards) - -- |B| 集合B的大小
(
-- |A ∩ B| 交集的大小(再次计算用于分母)
SELECT COUNT(DISTINCT c1.card_id)
FROM JSON_TABLE(u1.cards, '$[*]' COLUMNS(card_id BIGINT PATH '$')) c1
INNER JOIN JSON_TABLE(u2.cards, '$[*]' COLUMNS(card_id BIGINT PATH '$')) c2
ON c1.card_id = c2.card_id
)
)
END AS card_sim,
-- IP相似度 (Jaccard系数): |A ∩ B| / (|A| + |B| - |A ∩ B|)
CASE
WHEN u1.ips IS NULL OR u2.ips IS NULL
OR JSON_LENGTH(u1.ips) = 0 OR JSON_LENGTH(u2.ips) = 0
THEN 0
ELSE (
-- 分子部分: |A ∩ B| (交集的大小)
SELECT COUNT(DISTINCT i1.ip_id)
FROM JSON_TABLE(u1.ips, '$[*]' COLUMNS(ip_id BIGINT PATH '$')) i1
INNER JOIN JSON_TABLE(u2.ips, '$[*]' COLUMNS(ip_id BIGINT PATH '$')) i2
ON i1.ip_id = i2.ip_id
) * 1.0 / (
-- 分母部分: (|A| + |B| - |A ∩ B|) (并集的大小)
JSON_LENGTH(u1.ips) + -- |A| 集合A的大小
JSON_LENGTH(u2.ips) - -- |B| 集合B的大小
(
-- |A ∩ B| 交集的大小(再次计算用于分母)
SELECT COUNT(DISTINCT i1.ip_id)
FROM JSON_TABLE(u1.ips, '$[*]' COLUMNS(ip_id BIGINT PATH '$')) i1
INNER JOIN JSON_TABLE(u2.ips, '$[*]' COLUMNS(ip_id BIGINT PATH '$')) i2
ON i1.ip_id = i2.ip_id
)
)
END AS ip_sim
FROM user_entities u1
JOIN user_entities u2 ON u2.user_id IN (SELECT node_id FROM black_users)
WHERE u1.user_id NOT IN (SELECT node_id FROM black_users) -- 排除已知黑产
)
-- 最终结果查询
SELECT
u.properties->>'$.name' AS target_user,
u.properties->>'$.phone' AS phone,
CAST(u.properties->>'$.risk_score' AS UNSIGNED) AS risk_score,
bu.properties->>'$.name' AS black_user,
ROUND(sc.device_sim, 3) AS device_similarity,
ROUND(sc.card_sim, 3) AS card_similarity,
ROUND(sc.ip_sim, 3) AS ip_similarity,
ROUND((sc.device_sim * 0.5 + sc.card_sim * 0.3 + sc.ip_sim * 0.2), 3) AS total_similarity,
CASE
WHEN (sc.device_sim * 0.5 + sc.card_sim * 0.3 + sc.ip_sim * 0.2) > 0.7 THEN '高风险'
WHEN (sc.device_sim * 0.5 + sc.card_sim * 0.3 + sc.ip_sim * 0.2) > 0.4 THEN '中风险'
ELSE '低风险'
END AS risk_level
FROM similarity_calc sc
JOIN node u ON sc.target_user = u.node_id
JOIN node bu ON sc.black_user = bu.node_id
ORDER BY total_similarity DESC
LIMIT 5;效果:

四、项目实战
基于MySQL搭建的图数据库,模拟实现好友推荐功能。
- 数据准备:
sql
-- 创建用户
INSERT INTO node (properties) VALUES
('{"type":"user","name":"张三","age":25,"city":"北京"}'),
('{"type":"user","name":"李四","age":28,"city":"北京"}'),
('{"type":"user","name":"王五","age":30,"city":"上海"}'),
('{"type":"user","name":"赵六","age":26,"city":"广州"}'),
('{"type":"user","name":"钱七","age":27,"city":"深圳"}'),
('{"type":"user","name":"Jack","age":18,"city":"杭州"}'),
('{"type":"user","name":"Tom","age":45,"city":"贵州"}'),
('{"type":"user","name":"Mike","age":35,"city":"上海"}');
-- 创建好友关系
INSERT INTO edge (source_id, target_id, properties) VALUES
(1,2, '{"type":"friend"}'),
(1,3, '{"type":"friend"}'),
(2,4, '{"type":"friend"}'),
(3,5, '{"type":"friend"}'),
(4,5, '{"type":"friend"}'),
(6,7, '{"type":"friend"}'),
(7,8, '{"type":"friend"}');- 具体实现
sql
-- 综合推荐算法:为张三推荐3个好友,排除现有好友
WITH target_user AS (
SELECT
node_id,
properties->>'$.city' AS city
FROM node
WHERE properties->>'$.name' = '张三'
),
existing_friends AS (
SELECT target_id
FROM edge
WHERE source_id = (SELECT node_id FROM target_user)
AND properties->>'$.type' = 'friend'
),
common_friends AS (
SELECT
f2.target_id AS candidate_id,
COUNT(*) AS common_friend_count
FROM edge f1
JOIN edge f2 ON f1.target_id = f2.source_id
WHERE f1.source_id = (SELECT node_id FROM target_user)
AND f2.target_id NOT IN (SELECT target_id FROM existing_friends) -- 排除现有好友
AND f2.target_id != (SELECT node_id FROM target_user) -- 排除自己
AND f1.properties->>'$.type' = 'friend'
AND f2.properties->>'$.type' = 'friend'
GROUP BY f2.target_id
),
same_city AS (
SELECT
n.node_id AS candidate_id,
1 AS same_city_score
FROM node n
WHERE n.properties->>'$.city' = (SELECT city FROM target_user)
AND n.node_id != (SELECT node_id FROM target_user)
AND n.node_id NOT IN (SELECT target_id FROM existing_friends) -- 排除现有好友
),
final_candidates AS (
SELECT
cf.candidate_id,
COALESCE(cf.common_friend_count, 0) AS common_friends,
COALESCE(sc.same_city_score, 0) AS same_city,
COALESCE(cf.common_friend_count, 0) * 0.6 +
COALESCE(sc.same_city_score, 0) * 0.4 AS recommendation_score
FROM common_friends cf
LEFT JOIN same_city sc ON cf.candidate_id = sc.candidate_id
UNION ALL
SELECT
sc.candidate_id,
0 AS common_friends,
sc.same_city_score AS same_city,
sc.same_city_score * 0.4 AS recommendation_score
FROM same_city sc
WHERE sc.candidate_id NOT IN (SELECT candidate_id FROM common_friends)
)
SELECT
n.properties->>'$.name' AS recommended_name,
fc.common_friends,
fc.same_city,
fc.recommendation_score
FROM final_candidates fc
JOIN node n ON fc.candidate_id = n.node_id
ORDER BY recommendation_score DESC
LIMIT 3;- 效果展示
可以看到最后只给张三推荐了赵六和钱七,并没有推荐Tom、Jack等用户。
