目录
[1.2 主要类型](#1.2 主要类型)
[1.2.1 监督学习(Supervised Learning)](#1.2.1 监督学习(Supervised Learning))
[1.2.2 无监督学习(Unsupervised Learning)](#1.2.2 无监督学习(Unsupervised Learning))
[1.2.3 强化学习(Reinforcement Learning)](#1.2.3 强化学习(Reinforcement Learning))
[1.2.4 扩展类型](#1.2.4 扩展类型)
[2.1 基本介绍](#2.1 基本介绍)
[2.1.1 简单介绍](#2.1.1 简单介绍)
[2.1.2 优点介绍](#2.1.2 优点介绍)
[2.1.3 不足](#2.1.3 不足)
[2.2 主要模块](#2.2 主要模块)
[2.3 流程概述](#2.3 流程概述)
[2.3.1 获取数据阶段(Data Acquisition)](#2.3.1 获取数据阶段(Data Acquisition))
[2.3.2 数据预处理阶段(Data Preprocessing)](#2.3.2 数据预处理阶段(Data Preprocessing))
[(1)MinMaxScaler 归一化](#(1)MinMaxScaler 归一化)
[(3)StandardScaler 标准化](#(3)StandardScaler 标准化)
[2.3.3 特征工程阶段(Feature Engineering)](#2.3.3 特征工程阶段(Feature Engineering))
[(1)特征选择(Feature Selection)](#(1)特征选择(Feature Selection))
[(2)特征降维(Dimensionality Reduction)](#(2)特征降维(Dimensionality Reduction))
[2.3.4 模型构建阶段(Modeling / Training)](#2.3.4 模型构建阶段(Modeling / Training))
[2.3.5 模型评估阶段(Evaluation)](#2.3.5 模型评估阶段(Evaluation))
[2.3.6 模型优化阶段(Tuning)](#2.3.6 模型优化阶段(Tuning))
[(1)超参数调优(Hyperparameter Tuning)](#(1)超参数调优(Hyperparameter Tuning))
[(2)管道 (Pipeline)](#(2)管道 (Pipeline))
[(3)交叉验证(Cross Validation)](#(3)交叉验证(Cross Validation))
[2.3.7 部署与应用阶段(deployment)](#2.3.7 部署与应用阶段(deployment))
[(2)构建 API 接口(常用 Flask)](#(2)构建 API 接口(常用 Flask))
一、机器学习概念
1.1基本概念
机器学习(Machine Learning) 是人工智能的一个分支,主要研究让计算机从数据中自动学习规律,并根据学习到的规律进行预测或决策。简言之,它是"用数据训练模型,再用模型处理任务"。
机器学习的核心思想是让计算机通过数据 "自主学习" 规律,而非依赖人工编写的固定规则。传统编程是 "输入规则→输出结果",而机器学习是 "输入数据和结果→输出规则",再用学到的规则预测新数据。
1.2 主要类型
1.2.1 监督学习(Supervised Learning)
(1)基本介绍
- 模型在训练时使用带有标签的数据集,学习"输入 ➜ 输出"的映射关系。
- 目的是在给定新输入时预测对应的输出。
(2)任务目标
-
分类:输出是离散的类别标签
-
回归:输出是连续的数值
(3)常见算法
- 分类算法:KNN算法,决策树,支持向量机SVM,朴素贝叶斯
- 回归算法:线性回归,Lasso回归,支持向量回归 SVR,决策树回归
(4)应用场景
邮件分类,气温预测,图像识别,人脸识别等
1.2.2 无监督学习(Unsupervised Learning)
(1)基本概念
- 训练数据没有标签,算法通过分析数据的结构、自主发现隐藏模式或规律。
(2)应用任务
-
聚类:将数据自动分组
-
降维:压缩特征维度,保持信息
(3)常见算法
- 聚类算法:K-Means,DBSCAN,层次聚类
- 降维算法:主成分分析(PCA),t-SNE(非线性降维),自编码器(Autoencoder)
(4)应用场景
用户分群(电商客户画像),异常检测(信用卡欺诈),数据可视化
1.2.3 强化学习(Reinforcement Learning)
(1)基本概念
- 智能体(Agent)在环境中不断试错,通过"奖赏-惩罚"机制学习如何采取最优策略以最大化长期回报。
- 关键词 :状态(State),动作(Action),奖励(Reward),策略(Policy)
(2)经典方法
-
Q-learning(离线强化学习)
-
深度强化学习(Deep Q Network, DDPG, PPO)
(3)应用场景
游戏 AI(下棋、打 Atari),自动驾驶,机器人控制,股票交易策略优化等
1.2.4 扩展类型
(1)半监督学习
- 半监督学习(Semi-Supervised):结合少量有标签数据 + 大量无标签数据
- 应用场景:医学影像(标签难获得)
(2)自监督学习
- 自行构造伪标签从数据中学习表示
- 应用场景:应用于自然语言处理、图像识别;如:BERT、SimCLR、GPT 等深度学习模型的预训练阶段
二、关于sklearn机器学习库
2.1 基本介绍
2.1.1 简单介绍
- scikit-learn
(简称sklearn)是 Python 中最流行的机器学习库之一,其对初学者友好、功能完整、工程可用 ,是学习与应用机器学习的常用工具。我们现在就从sklearn开始学习。
2.1.2 优点介绍
| 优点 | 说明 |
|---|---|
| 丰富的算法库 | 包含常用的分类、回归、聚类、降维等算法(如 KNN、SVM、决策树、随机森林、KMeans、PCA) |
| 模块化设计 | 拆分为预处理、建模、调参、评估等步骤,接口统一 |
| 一致的 API 设计 | 所有模型都支持 **.fit()、.predict()、.score()**等方法,学习成本低 |
| 集成交叉验证与调参工具 | 提供 GridSearchCV、cross_val_score 等方法简化模型选择 |
| 数据预处理与特征工程工具 | 如归一化(Scaler)、特征选择(SelectKBest)、降维(PCA)等 |
| 文档丰富,社区活跃 | 有详细文档和大量教程,便于学习与查错 |
| 兼容 NumPy / Pandas | 可与主流数据分析库无缝衔接 |
2.1.3 不足
- 不适合大数据量分布式训练(推荐用 PyTorch、TensorFlow、XGBoost 等工具搭配)
2.2 主要模块
| 模块 | 功能 |
|---|---|
sklearn.datasets |
提供常用数据集,如 load_iris()、load_digits() 等 |
sklearn.model_selection |
数据划分、交叉验证、网格搜索 |
sklearn.preprocessing |
数据预处理(标准化、归一化、编码等) |
sklearn.feature_selection |
特征选择工具 |
sklearn.decomposition |
降维算法,如 PCA |
sklearn.neighbors |
KNN 相关算法 |
sklearn.tree |
决策树、随机森林 |
sklearn.linear_model |
线性回归、逻辑回归等 |
sklearn.svm |
支持向量机 |
sklearn.metrics |
模型评估指标,如准确率、混淆矩阵等 |
2.3 流程概述
本文将以基本讲解与代码示例相结合的方式为读者介绍,这里先简单介绍一下各个阶段:
2.3.1 获取数据阶段(Data Acquisition)
目标:获取结构化的数据,形成特征矩阵 X 和标签 y
(1)sklearn玩具数据集
- 数据量小,数据在sklearn库的本地,只要安装了sklearn,不用上网就可以获取
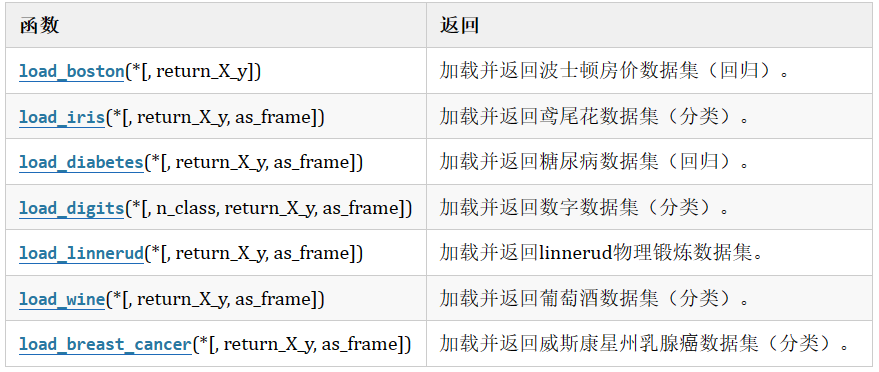
(2)sklearn现实世界数据集
- 数据量大,数据只能通过网络获取

(3)sklearn加载玩具数据集
1、以鸢尾花数据集为例:
from sklearn.datasets import load_iris
iris = load_iris()#鸢尾花数据
2、特征:
- 花萼长 sepal length
- 花萼宽sepal width
- 花瓣长 petal length
- 花瓣宽 petal width
3、分类:
- 0-Setosa山鸢尾
- 1-versicolor变色鸢尾
- 2-Virginica维吉尼亚鸢尾
4、相关代码介绍:
python
print(iris.data) #得到特征
print(iris.feature_names) #特征描述
print(iris.target) #目标形状
print(iris.target_names) #目标描述
print(iris.filename) #iris.csv 保存后的文件名
print(iris.DESCR) #数据集的描述2.3.2 数据预处理阶段(Data Preprocessing)
目标:清洗数据,转化为算法能接受的形式
(1)数据清洗(Data Cleaning)
使用 Pandas清洗数据:
- 去除重复数据:数据集中的重复记录会影响模型的学习,可能导致过拟合。
- 处理异常值:例如,数值过大或过小的异常数据,这些值通常并不代表真实世界的情况。
- 数据类型转换:确保每一列的数据类型正确,如数值型变量不应是文本类型。
(2)数据集划分(Data Splitting)
使用 train_test_split 划分数据:
-
训练集:用于训练模型,让模型学习数据中的规律。
-
验证集:用于调整模型的超参数,避免过拟合。
-
测试集:用于评估最终模型的性能。
(3)缺失值处理(Handling Missing Values)
- 删除缺失值:对于缺失值较少的情况,可以直接删除。
- 填充缺失值:使用均值、中位数、众数或者通过模型预测来填充缺失值。
- 插补法:使用预测模型或插值方法填充缺失值。
(4)数据编码(Encoding Categorical Variables)
许多机器学习算法无法直接处理文本数据(如分类变量),需要将其转换为数值型数据。
- 标签编码(Label Encoding):将每个类别映射为一个唯一的数字,适用于有序类别。
- 独热编码(One-Hot Encoding):将每个类别转换为二进制列,适用于无序类别。
2.3.3 特征工程阶段(Feature Engineering)
目的:构造/选择/提取对模型有用的特征
(1)特征选择(Feature Selection)
进行特征提取,比如字典特征提取,文本特征提取
- 过滤法 (Filter):
SelectKBest, **f_classif,**选择与目标变量最相关的 K 个特征 - 包裹法 (Wrapper):RFE(递归特征消除)
- 嵌入法 (Embedded):使用模型选择特征,如 Lasso、树模型
(2)特征转换(Feature Transformation)
目的:对现有特征进行转化,使其更适合用于训练机器学习模型,或者更易于理解。
- 对数变换(Log Transformation):当数据呈现高度偏态分布时,使用对数变换来使其更接近正态分布。
- 多项式特征(Polynomial Features):生成现有特征的多项式特征,扩展特征空间,适用于非线性模型。
- 交互特征(Interaction Features):通过将特征之间的交互(乘积、比值)作为新的特征添加。
(3)特征缩放(Feature Scaling)
目的:调整特征的数值范围,使其标准化或归一化,避免某些特征在模型训练中占主导地位。
- 归一化(Normalization):将特征缩放到固定范围(通常是 0, 1),适用于一些要求特征在同一尺度上的算法,如神经网络。
- 标准化(Standardization):将特征转换为均值为 0,标准差为 1 的分布,适用于大多数机器学习算法,尤其是基于距离的算法(如 KNN、SVM)
(4)特征构造(Feature Creation)
目的:基于现有的原始特征,创造新的、更具代表性的特征,提供给模型学习更多的模式。
(5)特征降维(Dimensionality Reduction)
目的:减少特征的数量,同时尽量保留原数据的信息,有助于减少计算复杂度和过拟合。
- **主成分分析 PCA:sklearn.decomposition.PCA
:**将数据从高维空间映射到低维空间,保留尽可能多的方差信息。 - 线性判别分析 LDA(带标签):一种有监督的降维方法,适用于分类任务,最大化类间差异,最小化类内差异。
- t-SNE(可视化用):一种常用于高维数据降维的算法,特别是在数据可视化中,它可以将高维数据映射到二维或三维空间。
2.3.4 模型构建阶段(Modeling / Training)
目标:使用算法对数据建模,寻找规律
经过上述的获取数据、数据处理、特征工程后,就可以交给预估器进行机器学习,流程和常用API如下:
1.实例化预估器(估计器)对象(estimator), 预估器对象很多,都是estimator的子类
(1)用于分类的预估器
sklearn.neighbors.KNeighborsClassifier k-近邻
sklearn.naive_bayes.MultinomialNB 贝叶斯
sklearn.linear_model.LogisticRegressioon 逻辑回归
sklearn.tree.DecisionTreeClassifier 决策树
sklearn.ensemble.RandomForestClassifier 随机森林
(2)用于回归的预估器
sklearn.linear_model.LinearRegression线性回归
sklearn.linear_model.Ridge岭回归
(3)用于无监督学习的预估器
sklearn.cluster.KMeans 聚类
2.进行训练,训练结束后生成模型
estimator.fit(x_train, y_train)
3.模型评估
(1)方式1,直接对比
y_predict = estimator.predict(x_test)
y_test == y_predict
(2)方式2, 计算准确率
accuracy = estimator.score(x_test, y_test)
4.使用模型(预测)
y_predict = estimator.predict(x_true)
2.3.5 模型评估阶段(Evaluation)
目标:验证模型的预测能力。
(1)对于分类
| 指标 | 意义 | sklearn 工具 |
|---|
|---------------|------------|--------------------|
| 准确率(Accuracy) | 分类正确的样本数占比 | accuracy_score() |
|----------------|------------|---------------------|
| 精准率(Precision) | 正类中被预测对的比例 | precision_score() |
|-------------|-------------|------------------|
| 召回率(Recall) | 实际正类中被识别的比例 | recall_score() |
|----------------|--------------|--------------|
| F1 值(F1-score) | 精准率和召回率的调和均值 | f1_score() |
|------|------------|----------------------|
| 混淆矩阵 | 预测对/错的具体分布 | confusion_matrix() |
|--------------|-----------|----------------------------------|
| ROC 曲线 / AUC | 综合评价分类器性能 | roc_curve(), roc_auc_score() |
(2)对于回归
| 指标 | 意义 | sklearn 工具 |
|---|---|---|
| 均方误差(MSE) | 误差平方平均 | mean_squared_error() |
| 平均绝对误差(MAE) | 误差绝对值平均 | mean_absolute_error() |
| 决定系数 R² | 模型拟合程度 | r2_score() |
2.3.6 模型优化阶段(Tuning)
目的:进一步提升模型性能,提高泛化能力,防止过拟合、欠拟合
(1)超参数调优(Hyperparameter Tuning)
超参数(Hyperparameter) 是在模型训练之前手动设置的参数,用于控制模型的结构、训练过程或优化策略,其值无法通过训练数据自动学习得到,需要通过人工调试、网格搜索、随机搜索等方式确定。超参数是模型设计的核心,直接影响模型的性能。
1、方法:
- Grid Search(网格搜索):枚举所有参数组合
- Randomized Search(随机搜索):从参数分布中随机选择组合
- 贝叶斯优化等高级方法 (用第三方库如
optuna)
2、工具:
GridSearchCVRandomizedSearchCV
3、示例代码:
这里以KNN算法作一个示例:在KNN算法中,k是一个可以人为设置的参数,所以就是一个超参数。使用网格搜索能自动的帮助我们找到最好的超参数值。
python
from sklearn.model_selection import GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
x,y = load_iris(return_X_y=True)
knn = KNeighborsClassifier(n_neighbors=5)
model = GridSearchCV(knn, param_grid={"n_neighbors": [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]}, cv=5)
model.fit(x, y)
print("参数:", model.best_params_)
print("分数:", model.best_score_)
print("最佳K:",model.best_index_)
print("模型:", model.best_estimator_)
# print("结果:", model.cv_results_)
# 模型model即可进行预测
model.predict(x)(2)管道 (Pipeline)
将多个步骤(预处理、特征选择、模型)串联起来自动执行,避免数据泄露。
python
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
pipe = Pipeline([
('scaler', StandardScaler()),
('clf', RandomForestClassifier())
])
pipe.fit(X_train, y_train)(3)交叉验证(Cross Validation)
- 交叉验证是一种评估模型泛化能力的核心方法,其核心目标是解决 "如何用有限数据更可靠地判断模型是否能在新数据上表现良好" 的问题。
-
保留交叉验证(HoldOut Cross-validation )
-
k 折交叉验证(k-fold Cross-Validation)
-
分层 k 折交叉验证(Stratified k-fold)
-
留一交叉验证(Leave-One-Out CV, LOOCV)
-
时间序列交叉验证(Time Series CV)
2.3.7 部署与应用阶段(deployment)
目标:将训练好的模型部署到生产环境中,比如放到 Web 页面、API 接口中使用。
(1)模型保存与加载
- 保存模型:
python
import joblib
# 保存模型到指定路径
joblib.dump(model, "../src/modle/KNN.pkl")
# 保存转换器(可选)
joblib.dump(transfer, "../src/modle/transfer.pkl")- 加载模型:
python
import joblib
model = joblib.load("../src/modle/KNN.pkl")
transfer = joblib.load("../src/modle/transfer.pkl")(2)构建 API 接口(常用 Flask)
简单举个例子:
python
from flask import Flask, request, jsonify
import joblib
app = Flask(__name__)
model = joblib.load('my_model.pkl')
@app.route('/predict', methods=['POST'])
def predict():
data = request.get_json()
features = [data['feature1'], data['feature2']]
result = model.predict([features])
return jsonify({'prediction': int(result[0])})
# 启动服务:flask run(3)打包发布的常见方式
| 部署方式 | 说明 |
|---|---|
| Flask / FastAPI | 构建 RESTful API,适合原型与小项目 |
| Web前端(React/Vue) | 调用 API 接口进行预测 |
| Docker 容器化 | 封装成镜像部署在任意服务器 |
| 云部署(阿里云、AWS、GCP) | 在云端创建可访问服务 |
| 使用 Streamlit | 快速搭建交互式 Web 应用展示模型效果 |
三、文末总结
本篇文章的学习路线和标准流程的设计,旨在帮助初学者快速建立起一个知识架构,全面地理解机器学习项目的每个环节,并掌握从数据到部署的完整技术栈。每个阶段都对应了机器学习的核心技能和思维方式,进而培养独立解决实际问题的能力。从流程入手,逐个突破每个环节的核心技能,再通过完整项目串联,是掌握机器学习的高效路径。
在学习机器学习的过程中,需要注意几点核心原则:首先是理论与实践结合 ,在学习过程中我们会不断接触到高等数学的知识(线性代数、概率论等),要能够将数学基础与模型原理结合起来理解和学习,再通过具体项目进行实践;其次是以业务为导向 ,所有步骤都需围绕 "解决实际问题",归根到底我们是要面向应用、服务于实际生产的,在之后文章中也会着重体现这一点;再有就是要具备迭代思维,机器学习是 "数据→模型→评估→优化" 的循环,没有 "完美模型",只有 "更适合当前场景的模型"。暂时想到这么多。