Set集合
定义
- Set集合是一种不重复元素 的抽象数据结构,是一个包含一系列不重复元素 的集合
数据结构原理
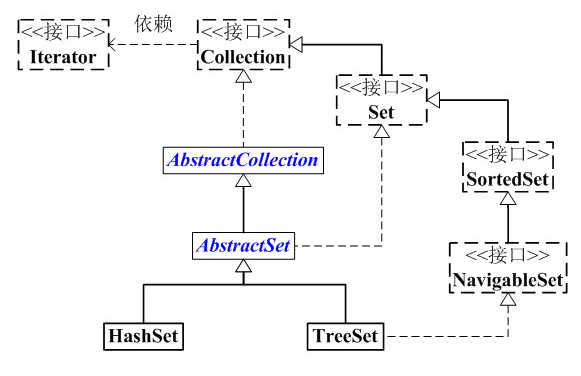
- 通过哈希表(HashTable)实现
-
Hash函数定位存储位置
- 每个元素通过哈希函数映射到一个哈希值,用于快速定位内存中存储位置(bucket桶)
-
解决哈希冲突
- 如果出现哈希冲突,通过开放地址法 或链表法解决冲突
-
判断数据已存在
- 插入时,再判断如果已经存在相同数据,不进行保存;否则进行保存
-
动态扩容
- 当负载因子 (元素数量/桶数量)超过阈值 (
0.75),自动扩容 并进行重新哈希(rehash)
- 当负载因子 (元素数量/桶数量)超过阈值 (
-
引申问题:为什么需要动态扩容?
-
核心目的:降低哈希冲突概率 、防止操作效率下降
-
原理:
- 哈希表底层是一个数组,元素会通过哈希函数映射到数组某个位置(即桶)
- 随着元素的的增加,
哈希冲突会越来越频繁(即不同元素映射到同一个桶的概率越来越高),而哈希冲突会导致性能下降,所以需要扩容来降低哈希冲突概率 - 随着元素的增加,操作效率也会趋向于线性时间(
O(1)会退化到O(n)),即效率会越来越低
引申问题:负载因子的意义
-
定义负载因子=元素个数桶的数量 \text{负载因子} = \frac{\text{元素个数}}{\text{桶的数量}} 负载因子=桶的数量元素个数
-
作用
- 体现哈希表的"拥挤程度"
- 哈希表的阈值 为
0.75,如果超过阈值,说明哈希表太满了,此时哈希冲突概率很高,需要扩容
引申问题:为什么扩容后需要rehash?
-
原因
- 哈希值一般是
取模运算来得出内存位置(桶位置)的,而扩容一般是将内容大小翻倍(桶的数量翻倍) - 所以扩容后,再进行取模运算时,原来的哈希值对应的内存位置(桶位置)已经发生了变化,需要重新进行哈希(即重新计算每个元素的内存位置/桶位置)
- 哈希值一般是
-
rehash执行过程
- 创建更大的数组,用于对应更多的桶
- 遍历原哈希表里的所有元素
- 对每个元素重新计算哈希 并存到新的桶中
操作类型
核心操作(基础操作)
- 添加
- 删除
- 查询
派生操作(可通过核心操作实现)
- 遍历
- 并集:所有元素的合集
- 交集:两个集合共有元素
- 差集:属于a不属于b的集合,即a-b
- 子集判断:b集合包含所有a集合的元素,a为b的子集
特点
-
数据不重复
- 元素唯一性 是set集合最大的特点,即不会有数据重复 ,该特征可以用来去重
-
无序性
- Set集合中的数据是无序 的,不能 通过索引 访问
- 若需要有序集合可以使用OrderedSet(如 collections.OrderedDict 的变种)或者SortedSet
- Set集合中的数据是无序 的,不能 通过索引 访问
优点
-
查找效率高
- 基于哈希表实现,查询效率非常高
-
自动去重
- 插入时自动去重,自动去除重复元素
-
集合运算
- 便于并集、交集、差集等数学集合运算
缺点
-
哈希冲突
- 实现需要处理哈希冲突
- 当随着负载因子的提高,哈希冲突会变得越来越频繁,为了应对这一点,还需要在负载因子超过阈值后进行rehash
-
无序
- 不能保证元素的插入顺序
- 也无法按索引访问元素
-
内存占用较大
- 哈希表结构通常比数组或者列表占用更大的内存
使用场景
-
数据去重
- 利用Set元素唯一特性,去除集合中的重复元素
-
快速查找
- 使用set来判断集合中是否包含这个元素
-
集合运算
- 对两个集合进行交集、并集、差集的运算
-
判断唯一性
- 通过Set元素唯一特性,统计唯一元素的个数
实际代码案例
场景一:列表去重
说明:
将一个包含重复元素的列表转换为不重复的集合。
Java 示例:
java
import java.util.*;
public class SetDeduplication {
public static void main(String[] args) {
List<String> names = Arrays.asList("Alice", "Bob", "Alice", "David", "Bob");
Set<String> uniqueNames = new HashSet<>(names);
System.out.println("去重后的名字集合: " + uniqueNames);
}
}场景二:判断元素是否存在(快速查找)
说明:
使用 Set 来判断某个元素是否在黑名单中。
Java 示例:
java
import java.util.*;
public class BlacklistCheck {
public static void main(String[] args) {
Set<String> blacklist = new HashSet<>(Arrays.asList("192.168.1.1", "10.0.0.1"));
String ip = "192.168.1.1";
if (blacklist.contains(ip)) {
System.out.println("该 IP 在黑名单中,拒绝访问!");
} else {
System.out.println("该 IP 允许访问。");
}
}
}场景三:集合运算(交集、并集、差集)
说明:
找出两个集合的交集、并集和差集。
Java 示例:
java
import java.util.*;
public class SetOperations {
public static void main(String[] args) {
Set<Integer> setA = new HashSet<>(Arrays.asList(1, 2, 3, 4));
Set<Integer> setB = new HashSet<>(Arrays.asList(3, 4, 5, 6));
// 交集
Set<Integer> intersection = new HashSet<>(setA);
intersection.retainAll(setB);
System.out.println("交集: " + intersection);
// 并集
Set<Integer> union = new HashSet<>(setA);
union.addAll(setB);
System.out.println("并集: " + union);
// 差集
Set<Integer> difference = new HashSet<>(setA);
difference.removeAll(setB);
System.out.println("差集 (A - B): " + difference);
}
}场景四:判断集合关系(子集、超集)
Java 示例:
java
import java.util.*;
public class SetRelations {
public static void main(String[] args) {
Set<String> setA = new HashSet<>(Arrays.asList("a", "b"));
Set<String> setB = new HashSet<>(Arrays.asList("a", "b", "c"));
System.out.println("A 是 B 的子集: " + setB.containsAll(setA));
System.out.println("B 是 A 的超集: " + setB.containsAll(setA));
}
}场景五:统计唯一访问用户(UV)
Java 示例:
java
import java.util.*;
public class UniqueVisitors {
public static void main(String[] args) {
List<String> userVisits = Arrays.asList("user1", "user2", "user1", "user3", "user2");
Set<String> uniqueUsers = new HashSet<>(userVisits);
System.out.println("独立访客数(UV): " + uniqueUsers.size());
}
}