在人群分析领域,人群计数是一项基础性任务,但仅提供人数统计结果已难以满足下游高级任务(如人群跟踪、异常检测、行为预测等)的实际需求。传统方法要么依赖密度图回归,无法提供个体精确位置;要么通过伪边界框进行检测,存在标注繁琐、后处理复杂且易出错等问题。为此,腾讯优图实验室等机构的研究者提出了一种纯粹的点基框架(Purely Point-Based Framework),并设计了对应的 Point-to-Point Network(P2PNet),实现了人群计数与个体定位的联合优化。
原文链接:2107.12746
代码链接:https://github.com/TencentYoutuResearch/CrowdCounting-P2PNet
沐小含持续分享前沿算法论文,欢迎关注...
一、研究背景与动机
1.1 人群分析的核心痛点
人群分析的核心需求已从 "单纯计数" 向 "精细定位 + 计数" 演进。下游任务(如人群跟踪、异常行为检测)不仅需要知道人群数量,更需要获取每个个体的精确位置。然而,现有方法存在明显缺陷:
- 基于密度图的方法:通过回归像素级密度图并求和得到人数,无法提供个体位置信息,且密度图的中间表示与人类标注逻辑(点标注)不一致,存在固有偏差。
- 基于定位的方法:
- 基于边界框的方法:需要密集的边界框标注(耗时耗力),或通过点标注生成伪边界框(不准确),后续 NMS 等后处理易导致漏检。
- 基于点 /blob 的方法:在拥挤区域难以处理近距离个体的重复预测或分割问题,鲁棒性不足。
1.2 研究动机
为解决上述问题,研究者提出:
- 采用纯点基表示:直接以人体头部中心点作为标注和预测目标,既符合人类标注习惯(标注成本低),又能提供精确位置信息。
- 设计端到端框架:绕过密度图、伪边界框等中间步骤,直接预测点集,简化流程并减少误差传播。
- 提出更全面的评估指标:现有指标要么只关注计数误差,要么忽略人群密度差异或重复预测惩罚,需设计同时衡量定位精度与计数准确性的指标。
二、核心贡献
论文的核心贡献可概括为三点,贯穿 "框架 - 指标 - 模型" 三个层面:
- 提出纯点基联合框架:首次明确以点标注为学习目标,直接输出个体中心点集,同时完成计数与定位,适配下游任务需求。
- 设计密度归一化平均精度(nAP):解决了现有指标的缺陷,能同时评估定位误差、计数准确性,并考虑人群密度差异。
- 提出 P2PNet 模型:作为点基框架的具体实现,通过匈牙利算法实现预测点与真实点的一对一匹配,避免重复或漏检,取得了 SOTA 性能。
三、核心技术详解
3.1 纯点基框架定义
该框架的核心思想是:输入图像 + 点标注(头部中心点)→ 输出预测点集(含坐标与置信度),无需任何中间表示。
形式化定义
- 给定图像含
个个体,真实点集为
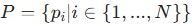 ,其中
,其中 - 模型
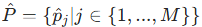 和对应的置信度集
和对应的置信度集 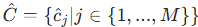 ,M 为预测个体数。
,M 为预测个体数。 - 目标:使预测点与真实点的距离尽可能小(定位准),且
框架优势
- 标注成本低:仅需标注头部中心点,无需边界框或密度图。
- 定位精度高:直接输出点坐标,无中间表示的误差传递。
- 适配下游任务:提供的个体位置可直接用于跟踪、行为分析等。
3.2 评估指标:密度归一化平均精度(nAP)
现有指标的不足:
- 图像级 MAE/MSE:仅衡量计数误差,忽略定位精度。
- 局部误差指标(如 Patch-level MAE):定位评估粗糙。
- 基于 AP 的指标:未考虑人群密度差异(拥挤区域允许更大定位误差),或缺乏重复预测惩罚。
nAP 的设计逻辑
nAP 基于目标检测中的 AP(Precision-Recall 曲线下面积),但引入了密度归一化 和一对一匹配策略,同时解决定位、计数、密度差异三大问题。
计算步骤
-
预测点排序:将所有预测点
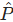 按置信度
按置信度 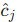 从高到低排序。
从高到低排序。 -
一对一匹配:按排序顺序,依次判断每个预测点是否为真阳性(TP):
- 仅当预测点
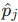 能匹配到未被匹配过的真实点
能匹配到未被匹配过的真实点 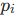 ,且满足密度归一化距离准则时,标记为 TP;否则为假阳性(FP)。
,且满足密度归一化距离准则时,标记为 TP;否则为假阳性(FP)。
- 仅当预测点
-
密度归一化距离准则避免拥挤区域(真实点密集)与稀疏区域采用相同距离阈值,定义匹配准则:
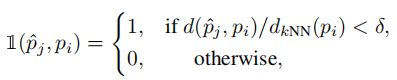
其中: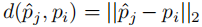 :预测点与真实点的欧氏距离。
:预测点与真实点的欧氏距离。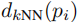 :真实点
:真实点 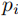 到其
到其 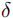 :定位精度阈值(
:定位精度阈值(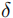 =0.5 为常用值,代表预测点需落在真实点的 "局部密度半径" 的 50% 以内)。
=0.5 为常用值,代表预测点需落在真实点的 "局部密度半径" 的 50% 以内)。
阈值设置与整体评估
- 不同
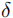 对应不同定位精度要求:
对应不同定位精度要求:
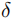 =0.05:严格定位(仅允许极小误差)。
=0.05:严格定位(仅允许极小误差)。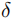 =0.25:高精度定位。
=0.25:高精度定位。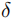 =0.5:满足多数实际场景的定位需求。
=0.5:满足多数实际场景的定位需求。
- 整体性能:计算
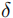 从 0.05 到 0.50(步长 0.05)的 nAP 平均值,记为 nAP0.05:0.05:0.50。
从 0.05 到 0.50(步长 0.05)的 nAP 平均值,记为 nAP0.05:0.05:0.50。
示意图
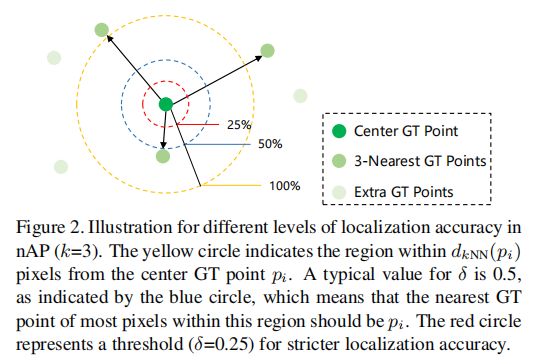
(注:黄色圆为 范围,蓝色圆为 =0.5 阈值,红色圆为 =0.25 阈值。=0.5 时,该区域内多数像素的最近真实点为 ,符合实际定位需求。)
3.3 关键问题:预测点与真实点的匹配策略
纯点基框架的核心挑战是:如何为预测点分配真实目标 (即确定哪个预测点对应哪个真实点),因为预测点数量 与真实点数量
可能不相等,且存在重复或漏检风险。
三种匹配策略对比
- 1 对 N 匹配:为每个真实点分配最近的预测点。缺陷:多个真实点可能匹配到同一个预测点,导致计数低估(如图 3 (a))。
- N 对 1 匹配:为每个预测点分配最近的真实点。缺陷:多个预测点可能匹配到同一个真实点,导致计数高估(如图 3 (b))。
- 一对一匹配:通过匈牙利算法找到预测点与真实点的最优双向匹配,未匹配的预测点标记为负样本。优势:无计数偏差,且无需手动设置负样本阈值(如图 3 (c))。
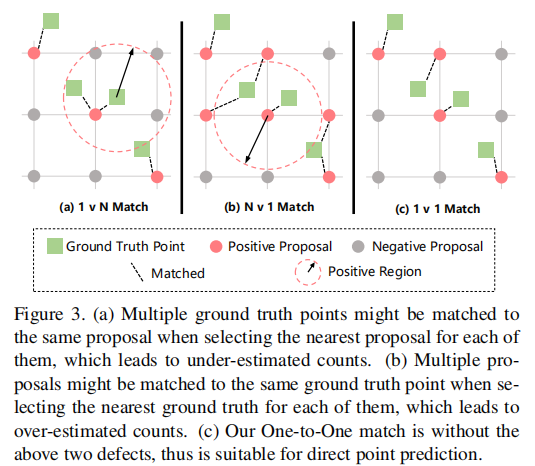
(注:绿色为真实点,红色为正样本预测点,灰色为负样本预测点。一对一匹配避免了高估 / 低估问题。)
匹配成本矩阵
为了让高置信度的预测点优先匹配到真实点,匹配成本不仅考虑距离,还引入置信度权重:
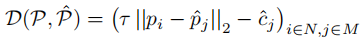
其中:
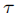 :距离权重(平衡距离与置信度的影响,默认值 5e-2)。
:距离权重(平衡距离与置信度的影响,默认值 5e-2)。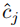 :预测点的置信度(高置信度降低匹配成本,优先被匹配)。
:预测点的置信度(高置信度降低匹配成本,优先被匹配)。
3.4 P2PNet 模型细节
P2PNet 是纯点基框架的具体实现,分为特征提取、点提案生成、一对一匹配、损失函数四大模块。
网络架构
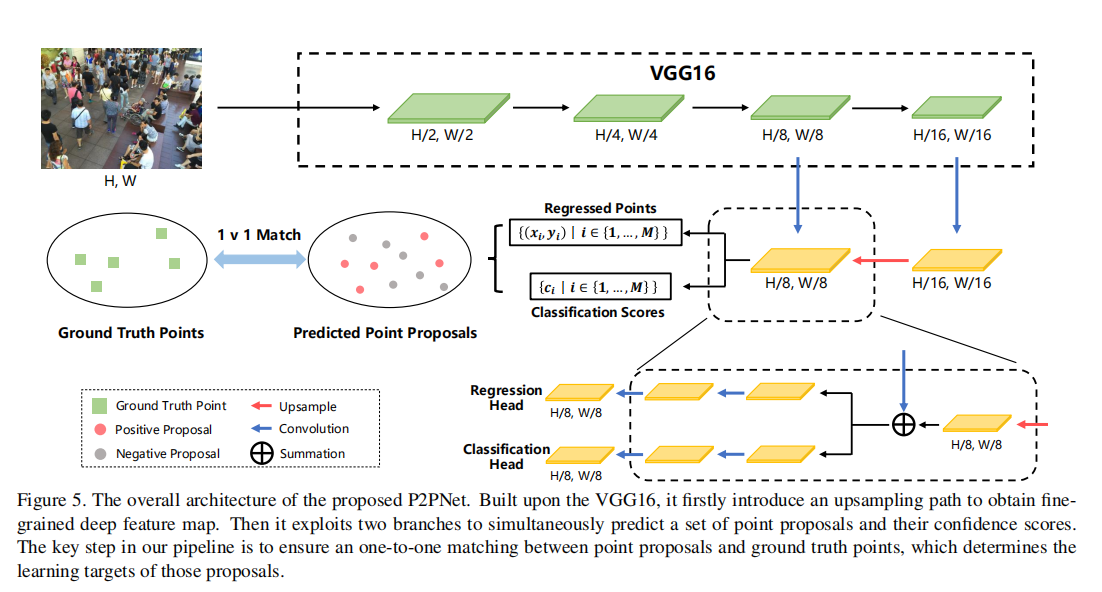
-
特征提取 backbone:
- 基于 VGG-16 bn 的前 13 层卷积层,提取深层特征。
- 引入上采样( nearest neighbor interpolation,缩放因子 2)和横向连接(lateral connection),融合浅层特征,提升特征图分辨率(最终步长
- 最终输出特征图
-
点提案生成(双分支预测) :基于
-
参考点设置 :特征图
- 中心布局(Center Layout):参考点为补丁中心。
- 网格布局(Grid Layout):参考点均匀分布在补丁内(如图 4),更适合拥挤区域。
-
坐标回归分支:预测每个参考点的偏移量
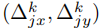 ,最终预测点坐标计算为:
,最终预测点坐标计算为: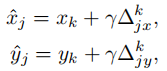
其中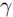 =100 为归一化项,用于缩放偏移量。
=100 为归一化项,用于缩放偏移量。 -
置信度分类分支:通过 Softmax 输出每个预测点的置信度
(判断该点是否为真实头部中心)。
-
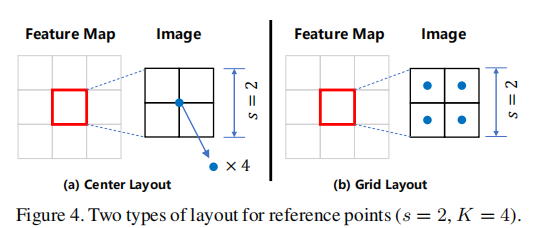
(注:s=2 时,K=4 的两种布局。网格布局覆盖更全面,适合拥挤场景。)
-
一对一匹配:训练阶段,通过匈牙利算法对预测点提案与真实点进行一对一匹配,确定正样本(匹配成功的预测点)和负样本(未匹配的预测点)。
-
损失函数:联合分类损失(置信度优化)和回归损失(坐标优化):
-
分类损失(交叉熵):
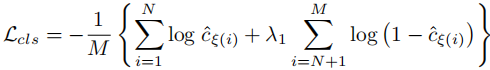
其中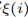 为匹配后的索引,
为匹配后的索引,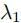 =0.5 为负样本权重(平衡正负样本)。
=0.5 为负样本权重(平衡正负样本)。 -
回归损失(欧氏距离):
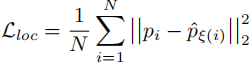
-
总损失:
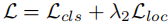
其中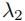 =2e−4 为回归损失权重。
=2e−4 为回归损失权重。
-
四、实验验证
4.1 实验设置
数据集
采用 5 个主流人群计数数据集,覆盖不同密度、分辨率场景:
- ShanghaiTech PartA(高密度)、PartB(低密度)。
- UCF CC 50(场景复杂,人数波动大)。
- UCF-QNRF(人数范围广,挑战性强)。
- NWPU-Crowd(大规模高密度,含边界框标注用于定位评估)。
数据增强与超参数
- 数据增强:随机缩放(0.7-1.3 倍)、随机裁剪(128×128 补丁)、随机翻转(概率 0.5)。
- 超参数:批量大小 8,Adam 优化器(backbone 学习率 1e-5,其他层 1e-4),参考点 K=4(UCF-QNRF 设为 8)。
4.2 主要实验结果
1. nAP 指标性能
表 1 展示了 P2PNet 在不同 下的 nAP 表现:

关键结论:
- δ=0.5 时,所有数据集的 nAP 均超过 83%,部分达 94%,证明定位精度优异。
- 即使 δ=0.25(高精度要求),nAP 仍超过 55%,鲁棒性强。
- δ=0.05 时性能较低,因标注偏差和极端定位要求导致,属正常现象。
2. 计数性能(MAE/MSE)
与 SOTA 方法对比,P2PNet 在多数数据集上取得最优结果:表 2 主流数据集计数性能对比(MAE/MSE)
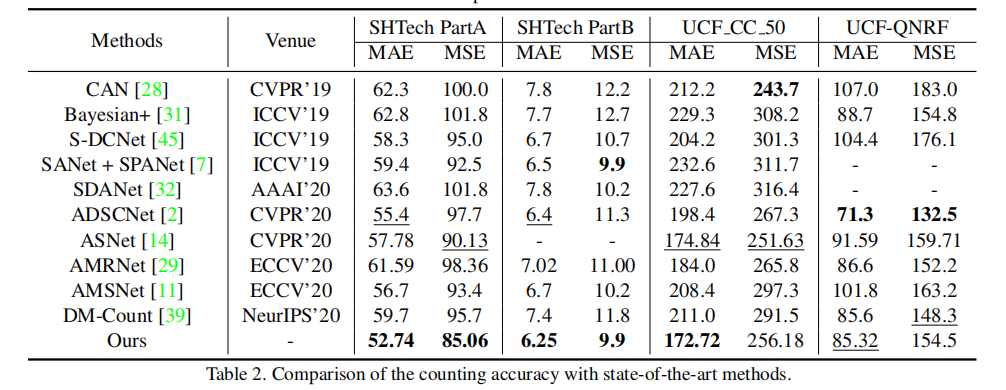
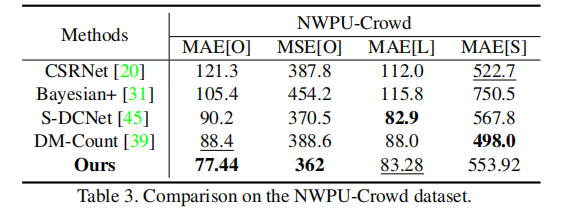
表 3 NWPU-Crowd 数据集计数性能对比
关键结论:
- SHTech PartA(高密度):MAE=52.74,比第二名 ADSCNet 降低 4.8%,MSE 降低 12.9%。
- SHTech PartB(低密度):MAE=6.25,为所有方法最优。
- UCF CC 50:MAE=172.72,显著优于其他方法。
- NWPU-Crowd:MAE O=77.44,比第二名 DM-Count 降低 12.4%,整体计数性能 SOTA。
3. 定位性能(NWPU-Crowd 数据集)
利用 NWPU-Crowd 的边界框标注,对比 F1-Measure/Precision/Recall:
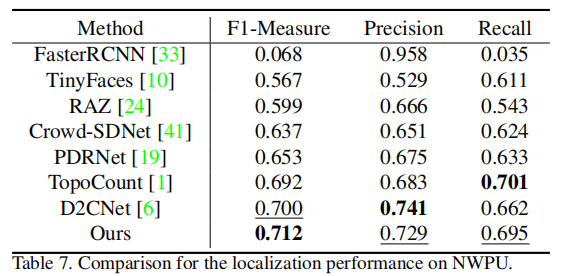
P2PNet 的 F1-Measure 达 71.2%,为所有对比方法最优,证明定位精度领先。
4. 定性结果

(注:白色数字为真实计数 / 预测计数,红色点为预测点,绿色点为真实点。P2PNet 在稀疏、中等、高密度场景下均能精准匹配真实点,计数误差小。)
4.3 消融实验
1. 参考点布局影响
表 4 参考点布局对比(SHTech PartA)
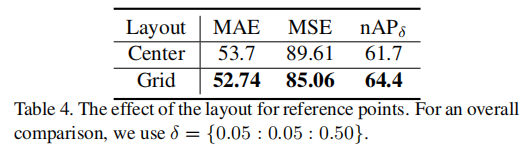
网格布局更优,因密集分布的参考点能更好覆盖拥挤区域的头部。
2. 特征图步长影响
表 5 特征图步长对比(SHTech PartA)
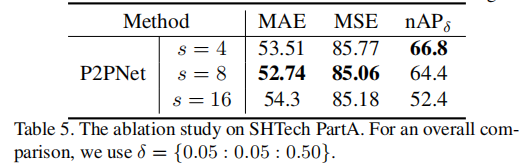
- 步长 s=8 时计数性能最优(平衡分辨率与计算量)。
- 步长 s=4 时 nAP 最高(特征图分辨率最高,定位更准),证明高分辨率特征对定位的重要性。
3. 参考点数量 K 影响
表 6 参考点数量 对比(SHTech PartA)
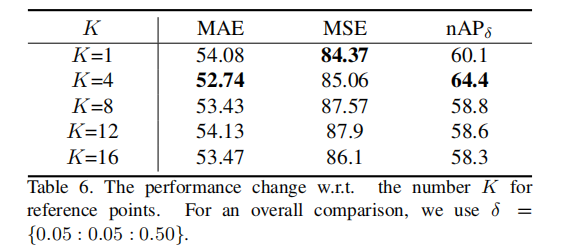
=4 时性能最优,
过大导致负样本增多,性能下降;
=1 时仍能保持 SOTA 水平,证明框架鲁棒性。
五、讨论与展望
5.1 优势与创新点总结
- 范式创新:首次提出纯点基框架,彻底抛弃密度图、伪边界框等中间表示,直接建模 "点标注→点预测",符合人类认知与下游任务需求。
- 指标创新:nAP 指标同时解决定位、计数、密度差异三大问题,为联合任务提供统一评估标准。
- 方法创新:一对一匹配策略(匈牙利算法)避免计数偏差,双分支预测与特征融合保证定位与计数精度。
5.2 局限性与未来方向
- 未明确处理尺度变化:虽然点表示本身与尺度无关,但极端尺度(超大 / 超小头部)仍可能影响性能,可结合多尺度特征融合(如 FPN)进一步优化。
- 灰色图像 / 老照片适应性不足:需增加更多此类数据训练,提升模型泛化能力。
- 实时性优化:当前模型基于 VGG-16,可替换为轻量级 backbone(如 MobileNet),适配实时场景。
5.3 应用场景
P2PNet 的定位 + 计数能力可直接应用于:
- 公共安全:人群密集度监测、异常行为检测(如踩踏预警)。
- 智能交通:路口行人计数与跟踪。
- 商业分析:商场、景区人流量统计与热点区域定位。
六、总结
本文提出的纯点基框架与 P2PNet 模型,重新定义了人群计数与定位任务的解决范式。通过直接预测头部中心点集,避免了中间表示的误差;nAP 指标提供了全面的性能评估;一对一匹配策略保证了计数与定位的准确性。实验证明,P2PNet 在多个数据集上取得 SOTA 性能,既满足了下游任务对个体位置的需求,又保持了计数精度,为人群分析领域提供了新的研究思路。未来,结合多尺度融合、轻量级架构等优化,该方法有望在更多实际场景中落地应用。