文章目录
- [一、CNN 基础认知](#一、CNN 基础认知)
-
- [1.1 图像在计算机中的存储形式](#1.1 图像在计算机中的存储形式)
- [1.2 图像识别的核心需求:画面不变性](#1.2 图像识别的核心需求:画面不变性)
- [1.3 传统神经网络的局限](#1.3 传统神经网络的局限)
- [二、CNN 核心原理:三大核心层与关键操作](#二、CNN 核心原理:三大核心层与关键操作)
-
- [2.1 卷积层](#2.1 卷积层)
- [2.2 池化层](#2.2 池化层)
- [2.3 全连接层](#2.3 全连接层)
- [三、CNN 的网络结构与经典模型](#三、CNN 的网络结构与经典模型)
-
- [3.1 CNN 的典型架构](#3.1 CNN 的典型架构)
- [3.2 经典 CNN 模型](#3.2 经典 CNN 模型)
- [四、总结:CNN 的核心优势与应用场景](#四、总结:CNN 的核心优势与应用场景)
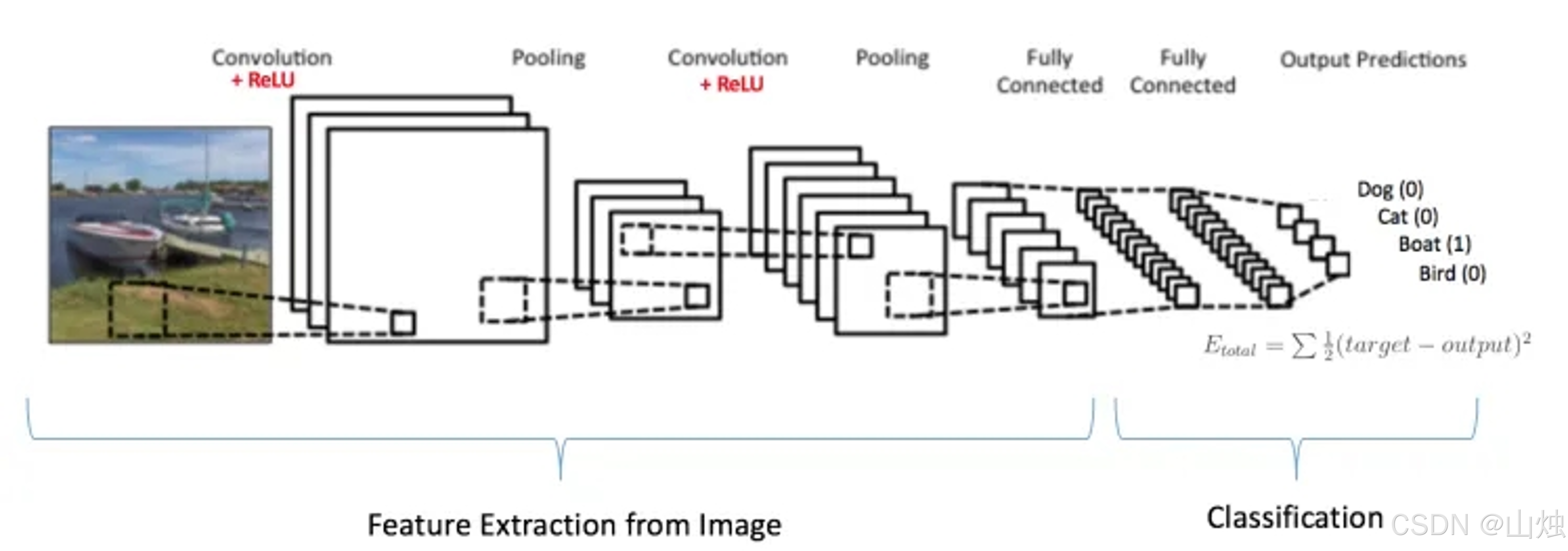
在深度学习领域,卷积神经网络(CNN)在图像识别、计算机视觉等任务中应用广泛,主要因为它能高效提取图像特征。下面就从基础原理、核心结构和实践要点三个方面,结合图示,把 CNN 的相关知识讲清楚。
一、CNN 基础认知
要懂 CNN,先得知道计算机是怎么处理图像的 ------ 图像在计算机里其实就是按顺序排列的数字矩阵。
1.1 图像在计算机中的存储形式
-
灰度图 :黑白灰度图用二维矩阵表示,每个元素的数值在 0 到 255 之间,0 是最暗,255 是最亮,矩阵的行和列分别对应图像的高度和宽度。

-
RGB 彩色图 :彩色图常用 RGB 三原色模型,存储为三维张量(宽 × 高 × 深),其中 "深" 指 3 个通道,分别是红(R)、绿(G)、蓝(B)通道,每个通道都是独立的二维矩阵,三个通道的数值组合起来就形成了各种颜色。
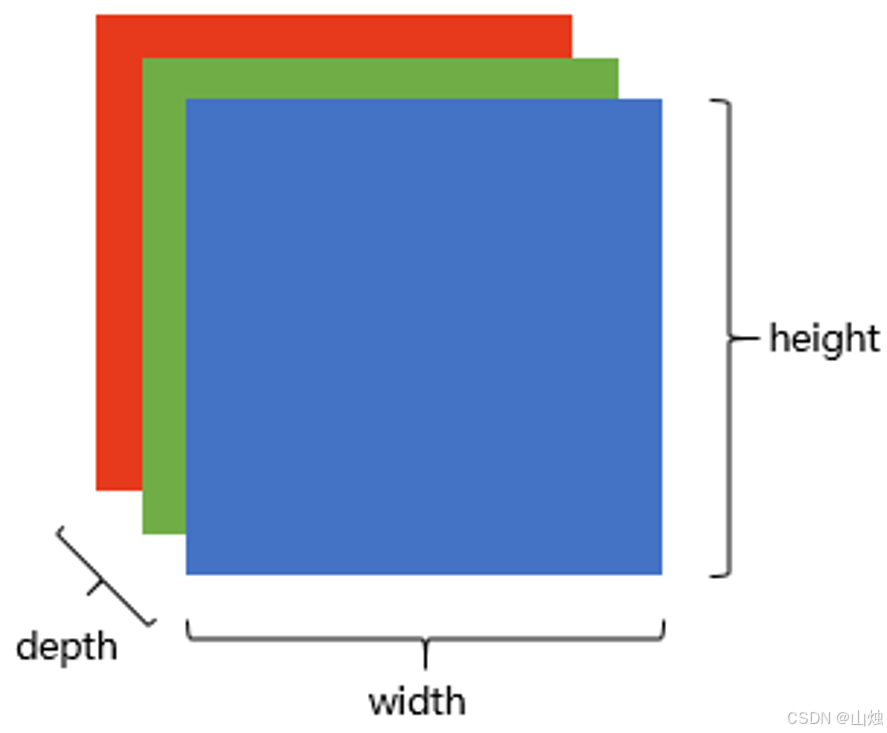
1.2 图像识别的核心需求:画面不变性
CNN 设计的一个重要目标是满足图像不变性,也就是说,不管物体在图像里的位置、角度、大小怎么变,或者光照条件不同,都能准确识别出来。具体有四种不变性需求:
-
平移不变性:物体在画面左边或右边,都能认出是同一个物体;
-
旋转 / 视角不变性:物体转了方向,或者从不同角度拍,识别结果不受影响;
-
尺寸不变性:物体放大或缩小后,依然能正确分类;
-
光照不变性 :在不同光照下,物体的特征不会被干扰。

1.3 传统神经网络的局限
传统神经网络处理图像时,要把二维矩阵改成一维向量才能输入,这样会丢失图像的空间结构信息。比如数字 "0-9" 和字母 "a-f",只要位置不一样,改成一维向量后就完全不同,传统网络就认不出来了。只能靠大量数据训练,再增加隐藏层来优化,效率很低。

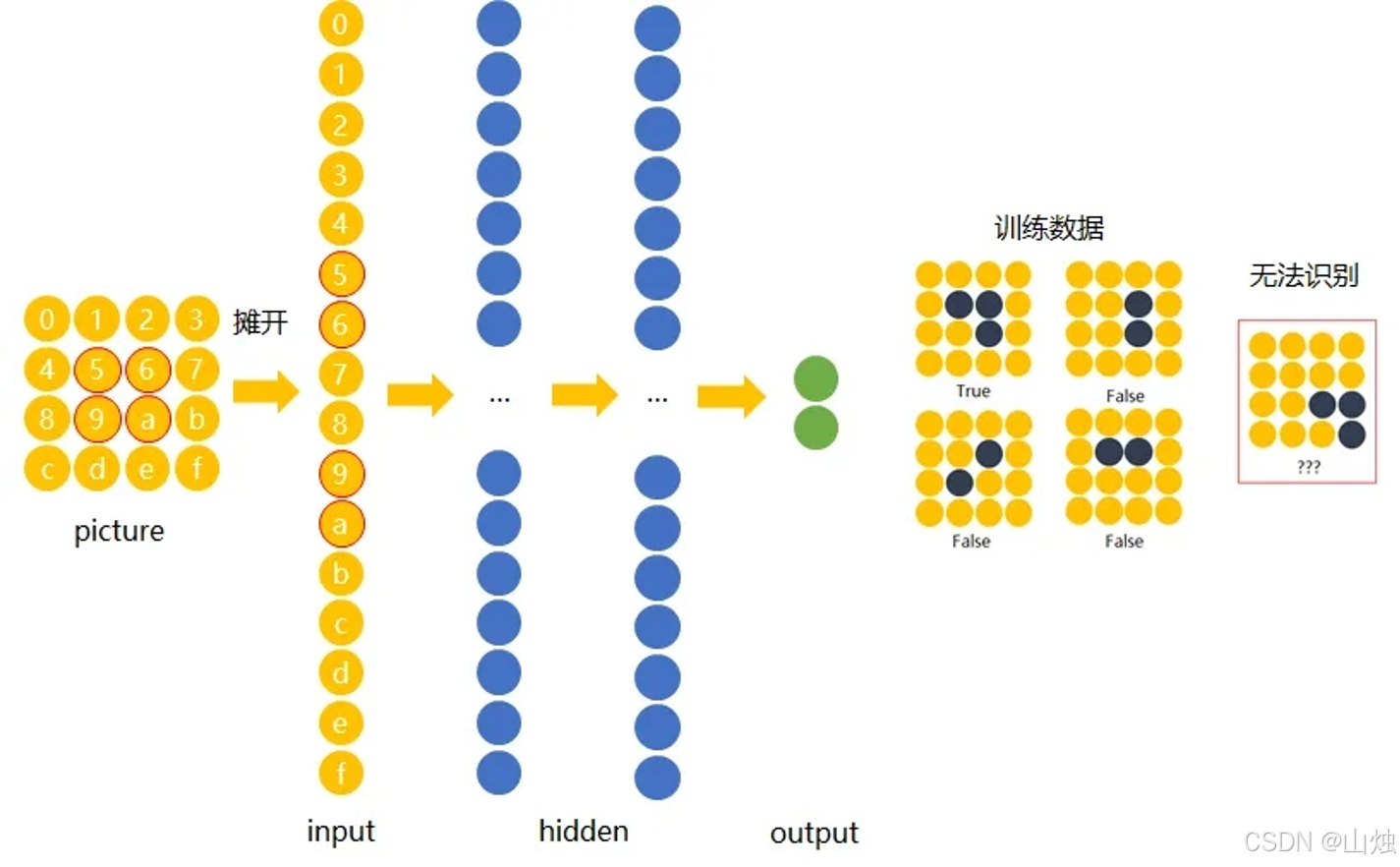
二、CNN 核心原理:三大核心层与关键操作
CNN 的优势来自它特殊的分层结构,主要包括卷积层、池化层、全连接层,每层有明确的作用,一起完成特征提取和分类。
2.1 卷积层
卷积层是 CNN 的核心,通过卷积操作提取图像的局部特征,比如边缘、纹理、颜色块这些。
(1)什么是卷积操作?
卷积就是拿图像局部窗口的数,和卷积核(Filter)做内积 ------ 也就是对应元素相乘再相加。卷积核是一组固定权重的小矩阵,就像 "特征探测器",不同的卷积核能提取不同的特征,比如检测边缘、让图像变模糊等。
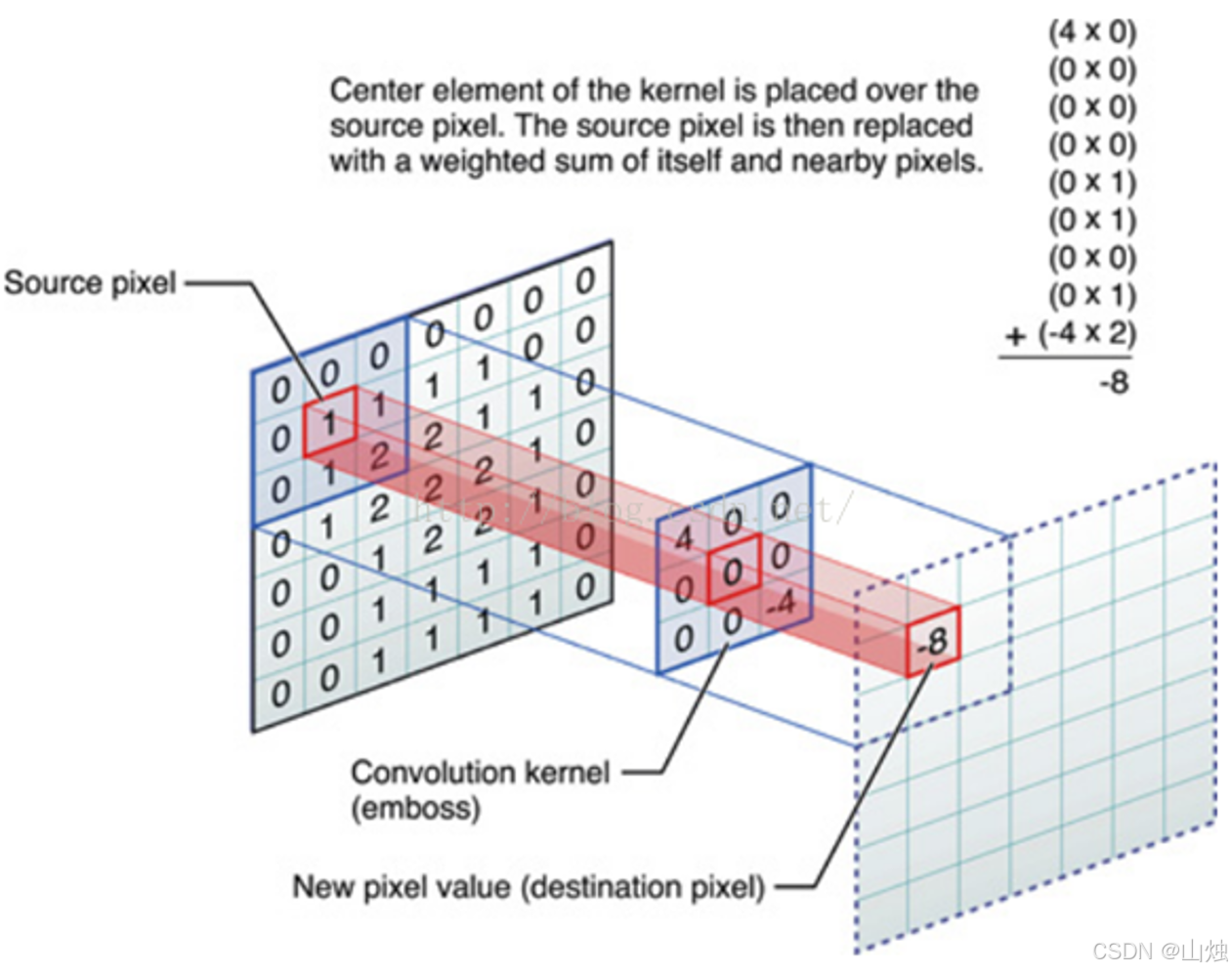
-
把卷积核的中心对准输入图像的某个像素,然后把这个像素和周围像素的数值,跟卷积核的权重分别相乘,再把结果加起来,就是输出的像素值;
-
举个例子:输入图像某区域的像素是 1,2;0,1,卷积核是 0,1;-4,2,那输出像素值就是(1×0)+(2×1)+(0×-4)+(1×2)=4。
(2)卷积层的关键参数
卷积操作的输出结果,受三个核心参数影响,我们用 7×7×3 的输入和 3×3×3 的卷积核来举例说明:
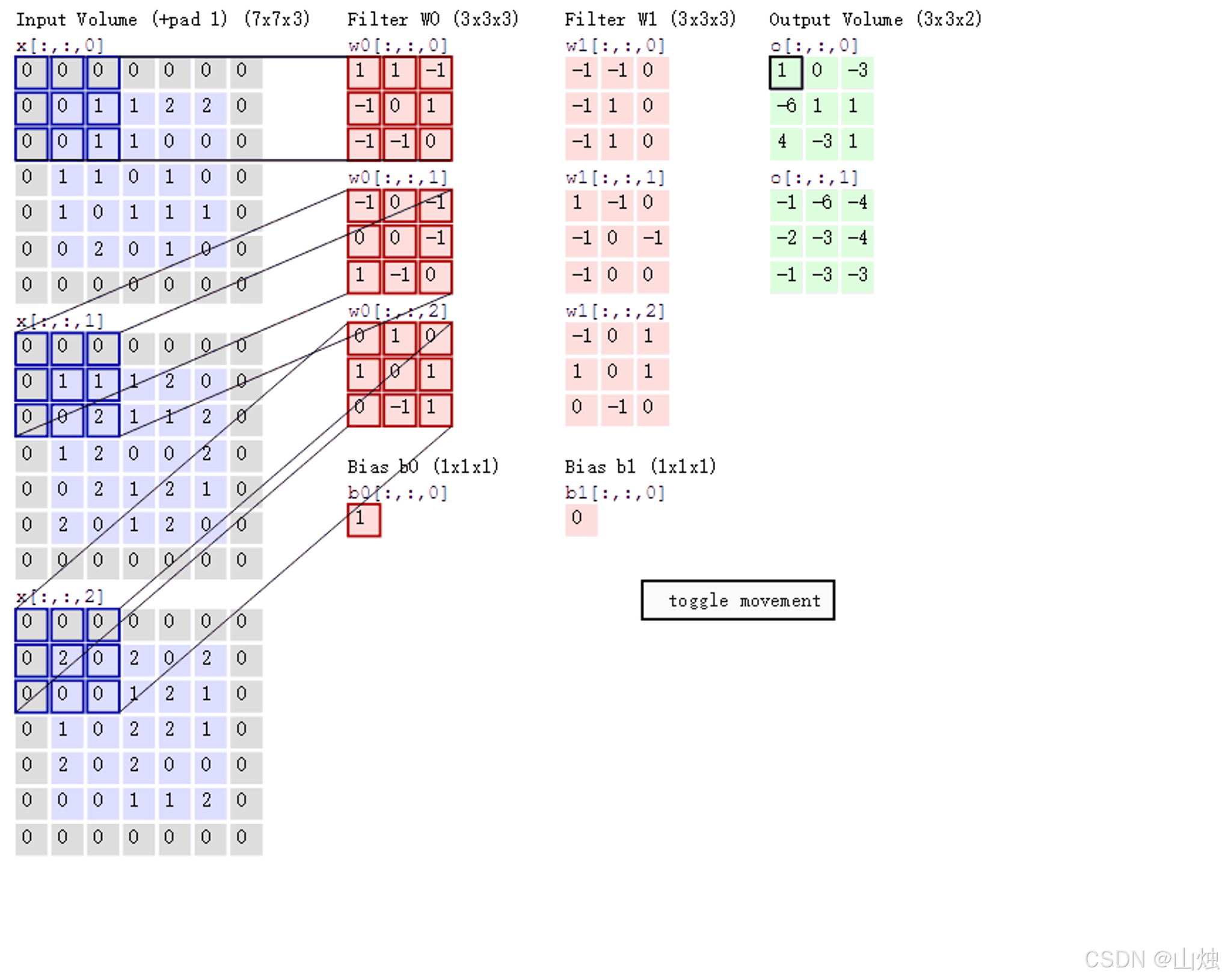
-
步长(Stride):指卷积核每次在图像上滑动的像素数。步长是 1,就每次移 1 个像素;步长是 2,就每次移 2 个像素,步长越大,输出的特征图尺寸越小。
-
卷积核个数:决定输出特征图的 "深度(Depth)"。比如用 2 个卷积核,输出的特征图就有 2 个通道,对应 2 种不同的特征。
-
填充(Zero-Padding):为了不让图像边缘的特征丢失,也为了让图像尺寸能被步长整除,会在图像边缘补几圈 0。比如 7×7 的图像,补 1 圈 0 后变成 9×9,这样步长为 2 时,卷积核就能完整滑动。
(3)输出特征图尺寸计算
卷积层输出尺寸有固定公式:
-
长度: H 2 = H 1 − F H + 2 P S + 1 H_2 = \frac{H_1 - F_H + 2P}{S} + 1 H2=SH1−FH+2P+1
-
宽度: W 2 = W 1 − F W + 2 P S + 1 W_2 = \frac{W_1 - F_W + 2P}{S} + 1 W2=SW1−FW+2P+1
其中, H 1 H_1 H1和 W 1 W_1 W1是输入图像的长度和宽度, F H F_H FH和 F W F_W FW是卷积核的长度和宽度, P P P是填充数, S S S是步长。
示例 :输入 32×32×3 的图像,用 10 个 5×5×3 的卷积核,步长 1,填充 2,按照公式计算,输出的长度和宽度都是 32 − 5 + 2 × 2 1 + 1 = 32 \frac{32-5+2×2}{1}+1=32 132−5+2×2+1=32,所以最终输出 32×32×10 的特征图。
2.2 池化层
池化层一般在卷积层后面,主要作用是降采样 ------ 减少数据量和计算量,同时能控制过拟合,让模型对物体的位置变化更不敏感。
(1)池化层的操作逻辑
池化层和卷积层类似,也是用 "池化窗口" 在特征图上滑动,但没有可学习的参数,只按固定规则计算输出。以 2×2 的最大池化为例:
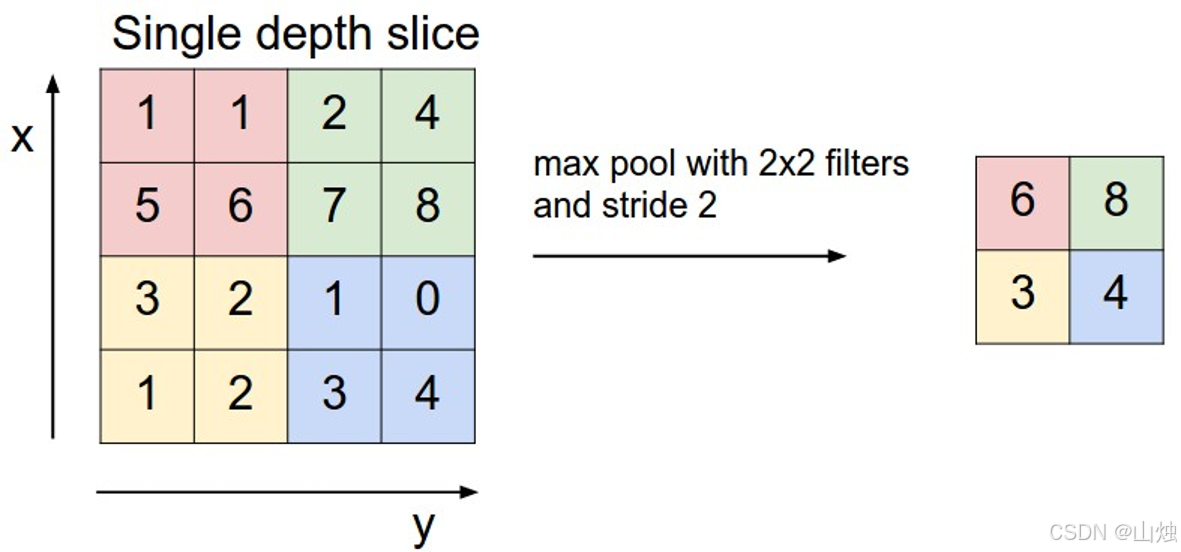
-
池化窗口按设定的步长滑动,对每个窗口里的像素计算输出值;
-
比如 2×2 最大池化,就是取窗口里的最大值作为输出,像窗口 1,2;6,8,输出就是 8。
(2)常见池化方式
主流的池化方式有三种:
-
最大池化(Max Pooling):取窗口内的最大值,能保留关键特征,比如边缘的强度,用得最多;
-
平均池化(Average Pooling):取窗口内的平均值,能保留图像整体的灰度信息;
-
全局平均池化 / 全局最大池化:把整个特征图当一个池化窗口,计算平均值或最大值,直接输出一维向量,常用来代替全连接层以减少参数(可分别插入这几种池化方式在图像上操作的对比图)。
(3)最大池化的优势
用 3×3 最大池化的例子来说明:最大池化能把特征图 "压缩",但不会影响识别结果。因为卷积后的特征图有冗余信息,最大池化能保留最关键的特征信号,还能降低过拟合的风险。
2.3 全连接层
等卷积层和池化层提取到足够的特征后,就轮到全连接层发挥作用了 ------ 它把这些特征映射到类别空间,完成最终的分类。
(1)全连接层的工作流程
全连接层的工作逻辑分两步:
-
特征摊平(Flatten):把卷积层、池化层输出的多维特征图,比如 32×32×10 的,改成一维向量,这个向量的长度就是 32×32×10=10240;
-
线性映射:把一维向量输入全连接层,层里每个神经元都和前一层所有神经元相连,通过权重计算,把特征映射到类别对应的维度。比如做 10 分类任务,就输出 10 个神经元,分别对应 0-9 这 10 个类别的概率。
(2)全连接层的作用
全连接层就像 "分类器",通过学习权重参数,把边缘、纹理这些低级特征,整合变成物体形状、结构这类高级特征,最后输出每个类别的概率。比如识别手写数字时,哪个神经元输出的概率最大,模型就认为输入的图像是对应的数字。
三、CNN 的网络结构与经典模型
3.1 CNN 的典型架构
一个完整的 CNN,结构通常是 "输入层→卷积层→激活层→池化层→(重复卷积 - 激活 - 池化)→全连接层→输出层"。
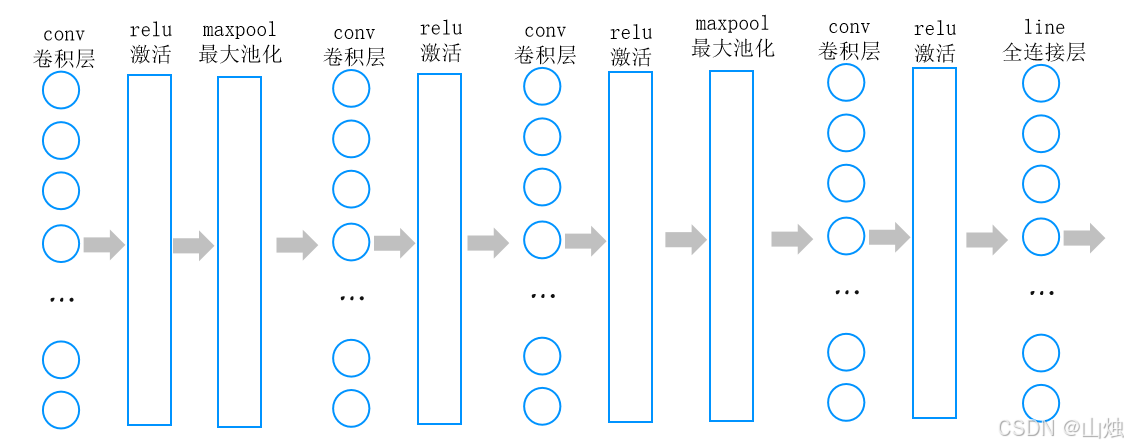
-
浅层:通过卷积层提取边缘、颜色这些低级特征;
-
中层:反复用卷积层和池化层,把低级特征组合成纹理、局部形状等中级特征;
-
深层:全连接层整合高级特征,输出分类结果。
3.2 经典 CNN 模型
有 6 种经典的 CNN 模型,能看出技术的发展过程:
| 模型名称 | 核心特点 | 应用价值 |
|---|---|---|
| LeNet | 第一个成功应用的 CNN,结构是卷积 - 池化 - 全连接 | 手写数字识别 |
| AlexNet | 网络更深更大,用了 ReLU 激活函数和 GPU 加速 | 实现 ImageNet 图像分类的突破 |
| ZF Net | 缩小了第一层的步长和卷积核尺寸,提高了特征提取精度 | 优化图像分类精度 |
| GoogLeNet | 加入 Inception 模块,减少参数,用全局池化代替全连接 | 高效融合特征 |
| VGGNet | 只用 3×3 的卷积核和 2×2 的池化层堆叠,加深了网络深度 | 增强特征抽象能力 |
| ResNet | 加入残差连接和 Batch Normalization,解决了梯度消失问题 | 实现 152 层这类超深网络的训练 |
四、总结:CNN 的核心优势与应用场景
总结一下 CNN 的核心优势,主要有三点:
-
局部连接与权值共享:卷积层只和图像的局部区域连接,而且同一个卷积核的权重在整个图像上都能用,大大减少了参数数量,降低了计算成本;
-
层次化特征提取:从低级特征到高级特征逐步抽象,符合人眼认识图像的规律,能提高识别精度;
-
平移不变性:池化层和卷积操作配合,就算物体位置变了,也不影响识别结果,能适应复杂的场景。
现在,CNN 已经广泛用在图像识别(比如人脸识别、车牌识别)、目标检测(比如自动驾驶里的障碍物检测)、图像分割(比如医学影像中的器官分割)等领域,是人工智能视觉技术的重要基础。