机器学习一般流程
机器学习一般需要先定义问题、收集数据、探索数据、预处理数据,对数据处理后,
接下来开始训练模型、评估模型,然后优化模型等步骤,图5-3为机器学习一般流程图。
通过这个图形可直观地了解机器学习的一般步骤或整体框架,接下来就对各部分分别
加以说明。
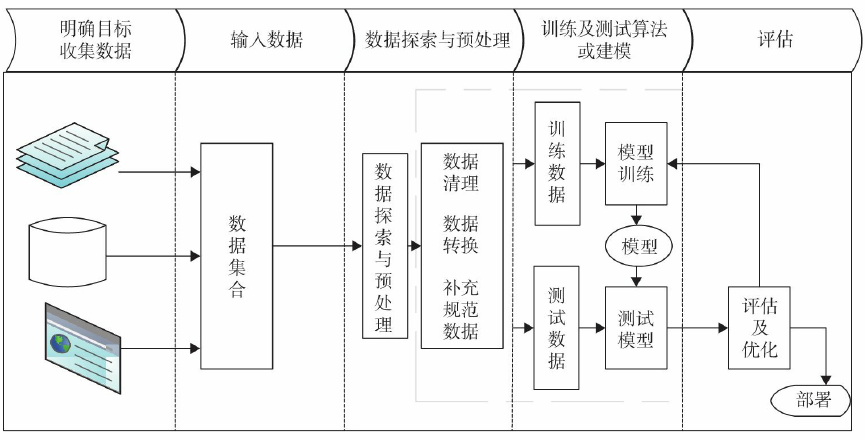
明确目标
在实施一个机器学习项目之初,定义需求、明确目标、了解要解决的问题以及目标涉
及的范围等都非常重要,它们直接影响后续工作的质量甚至成败。1)明确目标,首先需
要明确大方向,比如当前的需求是分类问题还是预测问题或聚类问题等。2)清楚大方向
后,需要进一步明确目标的具体含义。如果是分类问题,还需要区分是二分类、多分类还
是多标签分类;如果是预测问题,要区别是标量预测还是向量预测;其他方法类似。3)
确定问题,明确目标有助于选择模型架构、损失函数及评估方法等。
当然,明确目标还包含需要了解目标的可行性,因为并不是所有问题都可以通过机器
学习来解决。
收集数据
目标明确后,接下来就是了解数据。为解决这个问题,需要哪些数据?数据是否充
分?哪些数据能获取?哪些无法获取?这些数据是否包含我们学习的一些规则等,都需要
全面把握。
接下来就是收集数据,数据可能涉及不同平台、不同系统、不同部分、不同形式等,
对这些问题的了解有助于确定具体数据收集方案、实施步骤等。
能收集的数据尽量实现自动化、程序化。
数据探索与预处理
收集到的数据,不一定规范和完整,这就需要对数据进行初步分析或探索,然后根据
探索结果与问题目标,确定数据预处理方案。
对数据探索包括了解数据的大致结构、数据量、各特征的统计信息、整个数据质量情
况、数据的分布情况等。为了更好地体现数据分布情况,数据可视化是一个不错的方法。
通过对数据探索后,可能会发现不少问题:如存在缺失数据、数据不规范、数据分布
不均衡、存在奇异数据、有很多非数值数据、存在很多无关或不重要的数据等。这些问题
的存在直接影响数据质量,为此,数据预处理工作就应该是接下来的重点工作。数据预处
理是机器学习过程中必不可少的重要步骤,特别是在生产环境中的机器学习,数据往往是
原始、未加工和未处理过的,数据预处理常常占据整个机器学习过程的大部分时间。
数据预处理过程中,一般包括数据清理、数据转换、规范数据、特征选择等工作。
选择模型及损失函数
数据准备好以后,接下来就是根据目标选择模型。模型选择上可以先用一个简单、自
身比较熟悉的方法来实现,用这个方法开发一个原型或比基准更好一点的模型。通过这个
简单模型有助于读者快速了解整个项目的主要内容。
- 了解整个项目的可行性、关键点。
- 了解数据质量、数据是否充分等。
- 为读者开发一个更好的模型奠定基础。
在模型选择时,一般不存在某种对任何情况都表现很好的算法(这种现象又称为"没
有免费的午餐")。因此在实际选择时,一般会选用几种不同的方法来训练模型,然后比
较它们的性能,从中选择最优的那个。
模型选择后,还需要考虑以下几个关键点: - 最后一层是否需要添加softmax或sigmoid激活层。
- 选择合适损失函数。
- 选择合适的优化器。
表5-1列出了常见问题类型最后一层激活函数和损失函数的对应关系,供大家参考。
| 问题类型 | 最后一层激活函数 | 损失函数 |
|---|---|---|
| 二分类,单标签 | 添加 sigmoid 层 | nn.BCELoss |
| 二分类,单标签 | 不添加 sigmoid 层 | nn.BCEWithLogitsLoss |
| 二分类,多标签 | 无 | nn.SoftMarginLoss(target 为 1 或 -1) |
| 多分类,单标签 | 不添加 softmax 层 | nn.CrossEntropyLoss(target 的类型为 torch.LongTensor 的 one-hot) |
| 多分类,单标签 | 添加 softmax 层 | nn.NLLLoss |
| 多分类,多标签 | 无 | nn.MultiLabelSoftMarginLoss(target 为 0 或 1) |
| 回归 | 无 | nn.MSELoss |
| 识别 | 无 | nn.TripleMarginLoss |
| 识别 | 无 | nn.CosineEmbeddingLoss(margin 在 -1,1 之间) |
评估及优化模型
模型确定后,还需要确定一种评估模型性能的方法,即评估方法。评估方法大致有以
下3种。
-
留出法(Holdout):留出法的步骤相对简单,直接将数据集划分为两个互斥的集
合,其中一个集合作为训练集,另一个作为测试集。在训练集上训练出模型后,用测试集
来评估测试误差,作为泛化误差的估计。使用留出法,还可以优化出一种更好的方法,就
是把数据分成3部分:训练数据集、验证数据集、测试数据集。训练数据集用来训练模
型,验证数据集用来调优超参数,测试集则用来测试模型的泛化能力。数据量较大时可采
用这种方法。
-
K折交叉验证:不重复地随机将训练数据集划分为k个,其中k-1个用于模型训练,剩
余的一个用于测试。
-
重复的K折交叉验证:当数据量比较小,数据分布不很均匀时可以采用这种方法。
使用训练数据构建模型后,通常使用测试数据对模型进行测试,测试模型对新数据的
适应情况。如果对模型的测试结果满意,就可以用此模型对以后的数据进行预测;如果测
试结果不满意,可以优化模型。优化的方法很多,其中网格搜索参数是一种有效方法,当
然我们也可以采用手工调节参数等方法。如果出现过拟合,尤其是回归类的问题,可以考
虑正则化的方法来降低模型的泛化误差。