你一定听过 "物以类聚,人以群分" 这句话 ------ 把味道相似的零食归为一类,把兴趣相近的朋友分成小圈子,这些日常行为其实都藏着 "聚类" 的思想。在机器学习中,聚类是无监督学习的核心任务,它不需要提前给数据贴标签,就能自动把 "相似的对象" 归为一组。
这篇文章会从 "生活化例子" 切入,帮你吃透聚类的定义、核心思想、关键概念,再结合实际场景讲清聚类的价值,全程贴合入门学生的认知节奏,不堆砌复杂公式,只讲 "能理解、能关联生活" 的干货,让你彻底搞懂 "聚类到底在做什么"。
一、开篇:从 "区分糖和盐" 理解聚类的核心思想
要理解聚类,不用先看复杂定义,我们从两个最直观的生活场景入手 ------ 这些场景和机器学习中的聚类逻辑完全一致。
1.1 场景 1:如何区分糖和盐?------ 特征不同,聚类结果不同
假设你面前放着一堆糖和盐,没有任何标签,怎么把它们分成两组?答案取决于你 "关注什么特征":
- 按 "味道" 分:尝一口,甜味的归为 "甜味簇",咸味的归为 "咸味簇"------ 这是最直观的聚类方式,因为味道是糖和盐的核心差异;
- 按 "形态" 分:观察颗粒大小,颗粒粗的归为 "颗粒簇",粉末细的归为 "粉末簇"------ 如果糖是颗粒状、盐是粉末状,就会形成这两组聚类。
这个场景告诉我们聚类的第一个核心原则:聚类的结果由 "选择的特征参数" 决定。你关注的特征不同,最终的分组方式就不同。
1.2 场景 2:如何区分味精和盐?------ 相似性是聚类的核心
再看一个更贴近的例子:味精和盐都是白色、颗粒状,味道却不同(味精鲜、盐咸)。如果只看 "颜色 + 形态" 这两个特征,味精和盐会被归为同一簇(因为特征相似);但如果加入 "味道" 特征,它们就会被分成两个簇(特征差异大)。
这个场景进一步说明:聚类的本质是 "基于相似性分组"------ 同一个簇中的对象 "特征相似",不同簇中的对象 "特征相异"。
二、聚类的准确定义:拆解专业表述中的关键信息
了解了生活场景后,我们来看聚类的专业定义 ------ 这些定义来自权威百科,但我们会把它转化为入门学生能懂的语言,避免生硬的术语堆砌。
2.1 核心定义:两个权威表述的通俗解读
表述 1(维基百科):
"聚类是把相似的对象通过静态分类的方法分成不同的组别或者更多的子集 (subset),这样让在同一个子集中的成员对象都有相似的一些属性。"
通俗解读:
- "静态分类":不是动态变化的分组(比如不会今天把糖归为甜味簇,明天归为颗粒簇),而是基于固定特征的一次性分组;
- "子集(簇)":每个分组就是一个 "簇(Cluster)",比如甜味簇、咸味簇都是簇;
- "相似的属性":就是我们前面说的 "特征",比如味道、形态、颜色等。
表述 2(百度百科):
"聚类分析指将物理或抽象对象的集合分组成为由类似的对象组成的多个类的分析过程。它是一种重要的人类行为。聚类是将数据分类到不同的类或者簇这样的一个过程,所以同一个簇中的对象有很大的相似性,而不同簇间的对象有很大的相异性。"
通俗解读:
- "物理或抽象对象":聚类的对象可以是看得见的(比如糖、盐、水果),也可以是看不见的(比如用户的消费数据、文本的关键词);
- "人类行为":聚类是人类的本能 ------ 比如你会自动把衣柜里的衣服按 "季节" 分(春装、夏装),这就是一种聚类行为。
2.2 聚类的核心特征:和 "分类" 划清界限
入门学生很容易把 "聚类" 和 "分类" 搞混,其实两者有本质区别 ------ 关键在于 "是否有提前标注的标签":
| 对比维度 | 聚类(无监督学习) | 分类(监督学习) |
|---|---|---|
| 数据标签 | 无标签(不知道最终要分几类,也不知道类是什么) | 有标签(提前知道类别的数量和含义,比如 "好瓜 / 坏瓜") |
| 核心目标 | 自动发现数据中的分组规律 | 学习 "特征→标签" 的映射,预测新数据的标签 |
| 生活类比 | 把一堆陌生水果按 "看起来像不像" 分组 | 知道 "苹果 / 香蕉" 的样子后,判断新水果是什么 |
| 典型例子 | 电商用户分群(不知道有多少群) | 垃圾邮件识别(知道 "垃圾 / 正常" 两个标签) |
简单说:分类是 "有老师教的学习"(老师告诉答案),聚类是 "自学找规律"(自己摸索分组)。
三、聚类的关键概念:簇、中心、距离 ------ 理解聚类的 "基本单位"
要深入理解聚类,必须掌握三个关键概念:簇、簇中心、距离 ------ 它们是所有聚类算法的 "基础积木"。
3.1 簇(Cluster):聚类的 "最终分组"
定义
簇是聚类后形成的 "相似对象的集合",就像学校里的 "班级"------ 同一个班级的学生有相似的属性(比如同一年级、同一位班主任),不同班级的学生有明显差异。
特点
- 内部相似性高:同一个簇中的对象,在我们关注的特征上高度相似(比如 "甜味簇" 里的所有对象都是甜的);
- 外部差异性大:不同簇的对象,特征差异明显(比如 "甜味簇" 和 "咸味簇" 的味道完全不同);
- 数量不固定:簇的数量由数据本身的规律决定,比如一堆水果可能分成 3 个簇(苹果、香蕉、橙子),也可能分成 2 个簇(带皮吃的、去皮吃的)。
3.2 簇中心:簇的 "代表性对象"
定义
簇中心是 "能代表整个簇特征的点",就像班级里的 "班长"------ 班长的某些属性(比如成绩、身高的平均值)能代表班级的整体水平。
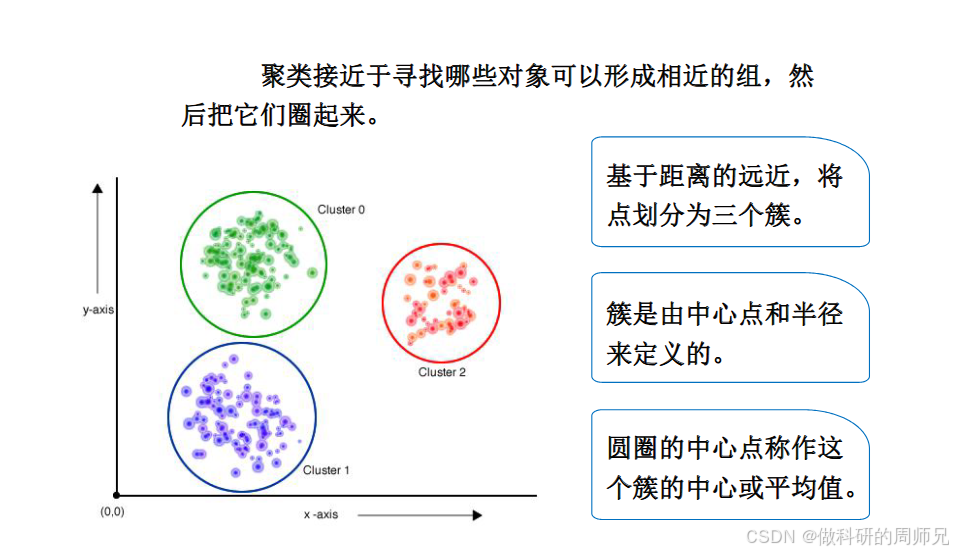
例子(坐标系中的簇)
假设我们把数据点放在二维坐标系中(x 轴和 y 轴是两个特征),形成 3 个簇(Cluster 0、Cluster 1、Cluster 2):
- 每个簇都是一群 "离得近的点";
- 簇中心就是这个簇中所有点的 "平均值"(x 坐标的平均值,y 坐标的平均值),比如 Cluster 0 的中心是(x0, y0),Cluster 1 的中心是(x1, y1);
- 簇的 "半径":可以理解为 "簇中心到簇内最远点的距离"------ 半径越小,说明簇内的点越集中(相似性越高)。
3.3 距离:判断 "相似性" 的 "尺子"
定义
距离是衡量 "两个对象相似程度" 的指标 ------ 距离越小,说明两个对象越相似;距离越大,说明差异越大。这是聚类的 "核心判断标准"。
入门必懂的距离:欧氏距离
欧氏距离就是我们日常生活中说的 "直线距离",比如在二维坐标系中,点 A(x1, y1)和点 B(x2, y2)的欧氏距离公式是:\(\text{距离} = \sqrt{(x1 - x2)^2 + (y1 - y2)^2}\)
应用场景
比如判断两个用户是否相似(特征是 "月消费金额" 和 "每月购物次数")
- 用户 A:(1000 元,10 次);
- 用户 B:(1050 元,12 次);
- 用户 C:(200 元,2 次);
- 计算欧氏距离:A 和 B 的距离很小(相似),A 和 C 的距离很大(不相似)------ 所以 A 和 B 会被归为同一簇,C 会被归为另一簇。
 图片来源于网络,仅供学习参考
图片来源于网络,仅供学习参考
四、聚类的实际应用场景:从理论到落地,看聚类能做什么
学习聚类,最终要知道 "能用它解决什么问题"。我们列举几个入门学生能直观感知的应用场景,帮你理解聚类的价值。
4.1 电商领域:用户分群与精准营销
电商平台会收集用户的 "消费数据"(月消费额、购买频率、喜欢的商品类型),用聚类算法把用户分成不同的簇:
- 簇 1(高价值用户):月消费 5000+,每月购买 10 + 次,喜欢高端家电;
- 簇 2(潜力用户):月消费 1000-3000,每月购买 5-8 次,喜欢平价服饰;
- 簇 3(低频用户):月消费 < 500,每月购买 < 2 次,偶尔买日用品。
针对不同簇的用户,平台会推送不同的营销活动:给簇 1 推高端新品,给簇 2 推满减券,给簇 3 推 "新人福利"------ 这就是聚类在 "精准营销" 中的应用。
4.2 图像领域:图像分割与目标识别
在图像处理中,聚类可以把 "相似的像素" 归为同一簇,实现 "图像分割":
- 比如一张 "猫的图片",聚类会把 "猫的毛发像素" 归为一个簇,"背景天空像素" 归为另一个簇,"猫的眼睛像素" 归为第三个簇;
- 分割后的图像能帮助计算机快速定位 "目标对象"(比如猫),为后续的 "目标识别"(判断这是一只猫)打下基础。
4.3 金融领域:异常检测与风险防控
银行会用聚类算法分析用户的 "信用卡交易数据"(交易金额、交易地点、交易时间):
- 正常交易形成多个簇(比如 "日常小额消费簇""每月工资入账簇");
- 异常交易(比如 "凌晨 3 点在国外大额消费")会成为 "离群点"------ 它不属于任何一个正常簇,距离所有簇中心都很远;
- 银行会把这类异常交易标记为 "疑似盗刷",触发预警,保护用户资金安全。
4.4 生活领域:物品整理与分类
聚类其实贯穿我们的日常生活:
- 衣柜整理:按 "季节" 聚类(春装、夏装、秋装、冬装),或按 "用途" 聚类(上衣、裤子、裙子);
- 手机相册:相册 APP 会自动按 "时间" 聚类(2024 年 5 月、2024 年 6 月),或按 "地点" 聚类(家里、公司、旅行);
- 音乐歌单:音乐 APP 会按 "曲风" 聚类(流行、摇滚、古典),帮你快速找到想听的歌曲。
五、入门学生学习聚类的建议
对于刚接触聚类的学生,不需要一开始就深入复杂的算法(比如 K-Means、DBSCAN),可以按以下步骤逐步学习,兼顾理论和直觉:
- 先建立 "聚类直觉":从生活场景出发,比如观察身边的 "分组行为"(比如超市货架的商品分类、班级同学的小圈子),思考 "这些分组用了什么特征""为什么这么分"------ 培养对 "相似性" 和 "分组" 的敏感度;
- 理解核心概念:记牢 "簇、簇中心、距离" 的定义,尤其是 "聚类 vs 分类" 的区别 ------ 这是后续学习算法的基础,避免混淆;
- 用简单工具可视化 :推荐用 Python 的
matplotlib或seaborn库,把二维数据点画出来,手动尝试 "按距离分组"------ 比如把 10 个点按 "离得近" 分成 2-3 组,直观感受聚类的过程; - 逐步学习基础算法:先学最简单的聚类算法(比如 K-Means),重点理解 "如何确定簇中心""如何更新簇的成员"------ 不要一开始就挑战复杂算法,循序渐进。
六、总结:聚类的核心逻辑链
最后用一条清晰的逻辑链,帮你串联聚类的所有核心内容:
- 本质:无监督学习,基于 "相似性" 自动分组,不需要提前贴标签;
- 关键要素 :
- 特征:聚类结果由 "选择的特征" 决定(比如糖和盐按味道分 vs 按形态分);
- 簇:相似对象的集合(内部相似、外部差异);
- 距离:衡量相似性的标准(距离越小越相似);
- 核心目标:发现数据中隐藏的分组规律,为后续分析(如精准营销、异常检测)提供支持;
- 应用:电商用户分群、图像分割、风险防控等,贯穿生活和工业场景。
聚类是机器学习中 "探索性数据分析" 的重要工具 ------ 当你拿到一堆无标签数据,不知道从何下手时,聚类能帮你 "先把数据分好组",再针对性分析每组的特点。下一章我们会深入学习最经典的聚类算法 ------K-Means,带你从 "理解概念" 走向 "掌握算法逻辑"。
如果这篇文章里有哪个概念没搞懂,欢迎在评论区留言,我们一起拆解!