✨作者主页 :IT研究室✨
个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。
文章目录
一、前言
本系统旨在构建一个基于大数据架构的痴呆症预测与数据可视化分析平台,通过整合 Hadoop 与 Spark 的分布式处理能力,实现对多源医疗数据的高效存储、清洗、分析与建模。系统后端采用 Django /Spring Boot 框架,结合 MySQL 数据库进行数据持久化存储,前端则利用 Vue、ElementUI 与 Echarts 构建直观的交互界面,使用户能够方便地浏览统计结果与预测趋势。在数据处理环节中,系统通过 Spark SQL、Pandas 和 NumPy 对大规模结构化与半结构化数据进行分析与特征提取,进一步调用训练好的预测模型,生成关于痴呆症发病风险的量化结果,并以可视化图表的形式呈现。平台的核心价值在于提供从数据收集、处理、建模到可视化的一体化解决方案,既能支持研究人员进行探索性分析,也能为医护人员和管理者提供数据支撑,帮助更直观地理解潜在风险分布和趋势。本系统不仅强调预测功能的准确性,也注重交互设计的实用性,保证最终结果能够被不同角色的用户有效使用,提升痴呆症相关研究与临床辅助决策的效率与质量。
选题背景
随着人口老龄化趋势的加快,痴呆症逐渐成为社会和医疗体系亟需应对的重要问题。痴呆症的早期症状往往隐匿,临床诊断依赖于大量的历史记录、医疗影像、行为数据以及个体的生活方式信息,而这些数据呈现出多源、异构和大规模的特点。传统的手工分析方式难以满足处理效率与精度的需求,亟需借助大数据和智能化方法来提升数据处理与建模能力。近年来,大数据框架在医疗健康领域的应用逐渐增加,能够为复杂病理过程提供数据支撑与趋势洞察。本课题正是在这样的背景下提出,尝试通过构建一个融合大数据存储与分布式计算的分析平台,对痴呆症相关数据进行高效处理和模型预测,以探索在技术与医疗结合方面的可行性。
选题意义
本系统的研究与实现具有一定的实践价值。对于医学研究人员而言,平台可以帮助快速处理和分析大规模样本数据,提供辅助性的趋势发现,从而为学术研究和临床验证提供参考。对于临床医生来说,系统的预测功能能够以可视化的方式呈现风险结果,帮助理解患者群体中潜在的发病特征,为早期筛查提供一定的辅助信息。对于医疗机构和管理者而言,平台可以作为一种数据管理与分析工具,在医疗资源有限的情况下,提供数据驱动的参考依据。虽然本课题在技术规模与医学应用上仍属于探索性质,但通过对 Hadoop、Spark、Django、Spring Boot、MySQL 等多种技术的集成与应用,验证了在痴呆症预测这一具体问题上,大数据技术能够发挥一定的辅助作用。这种实践不仅锻炼了系统开发与大数据应用的能力,也为后续进一步优化与扩展提供了基础。
二、开发环境
- 大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
- 开发语言:Python+Java(两个版本都支持)
- 后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
- 前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
- 详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy
- 数据库:MySQL
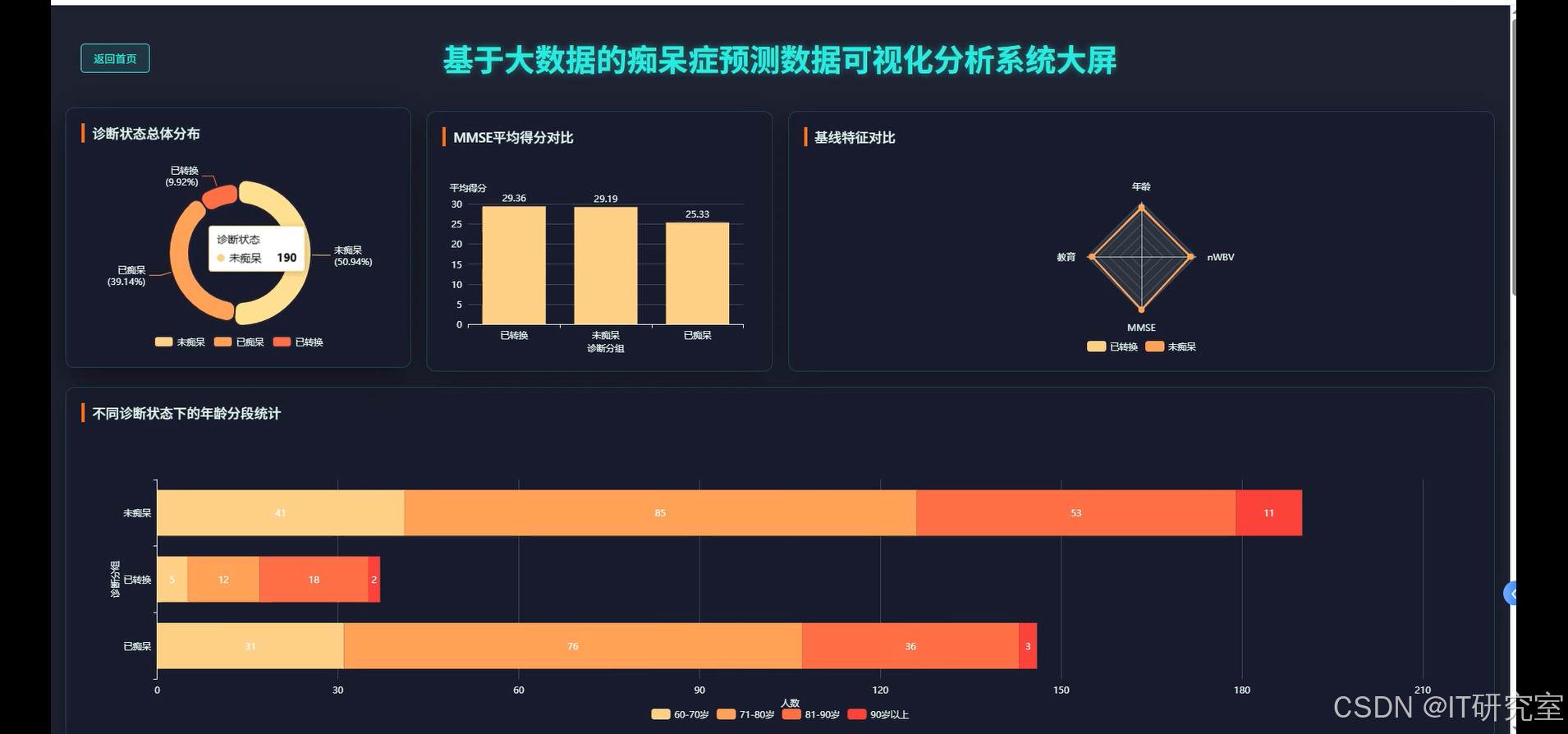
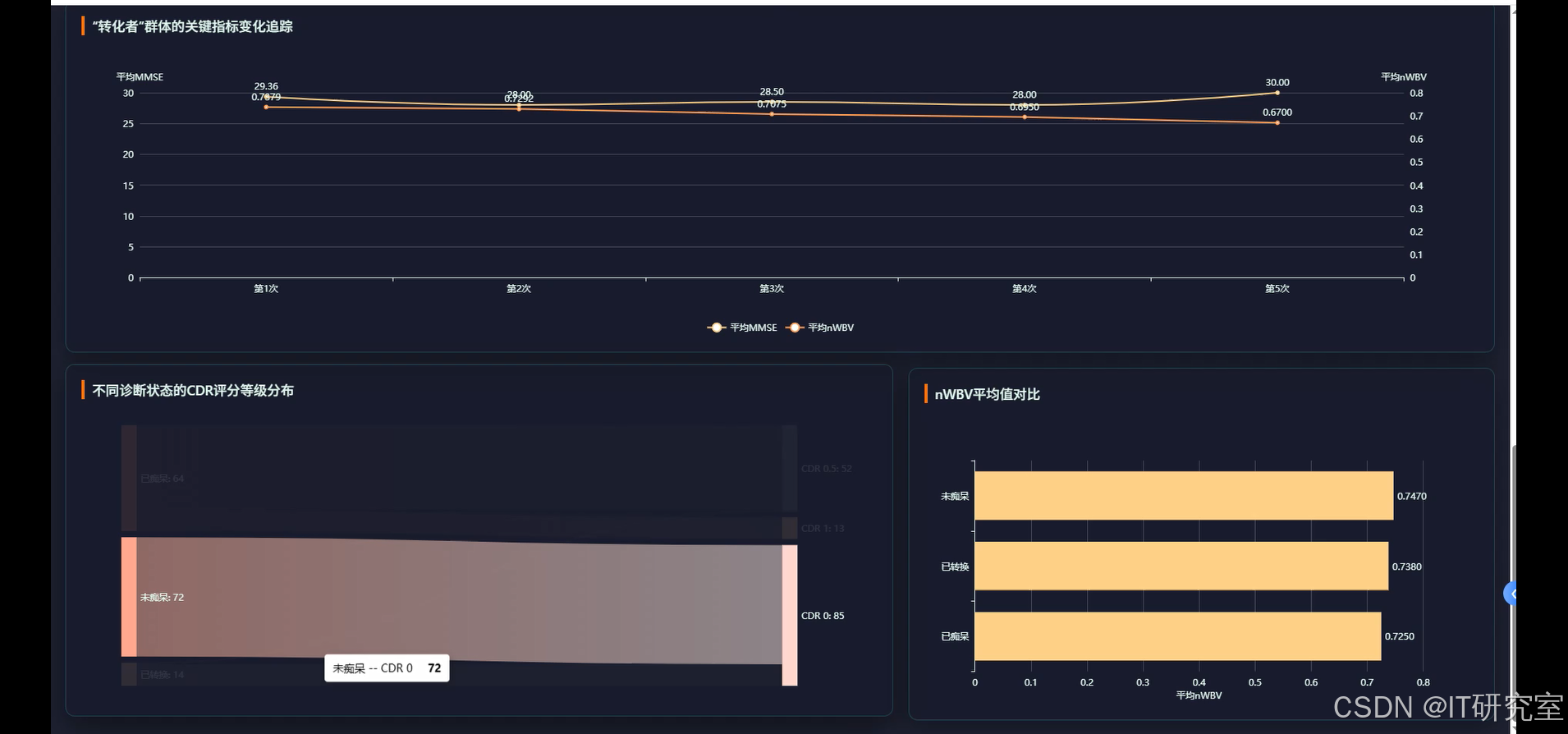
三、系统界面展示
- 基于大数据的痴呆症预测数据可视化分析系统界面展示:
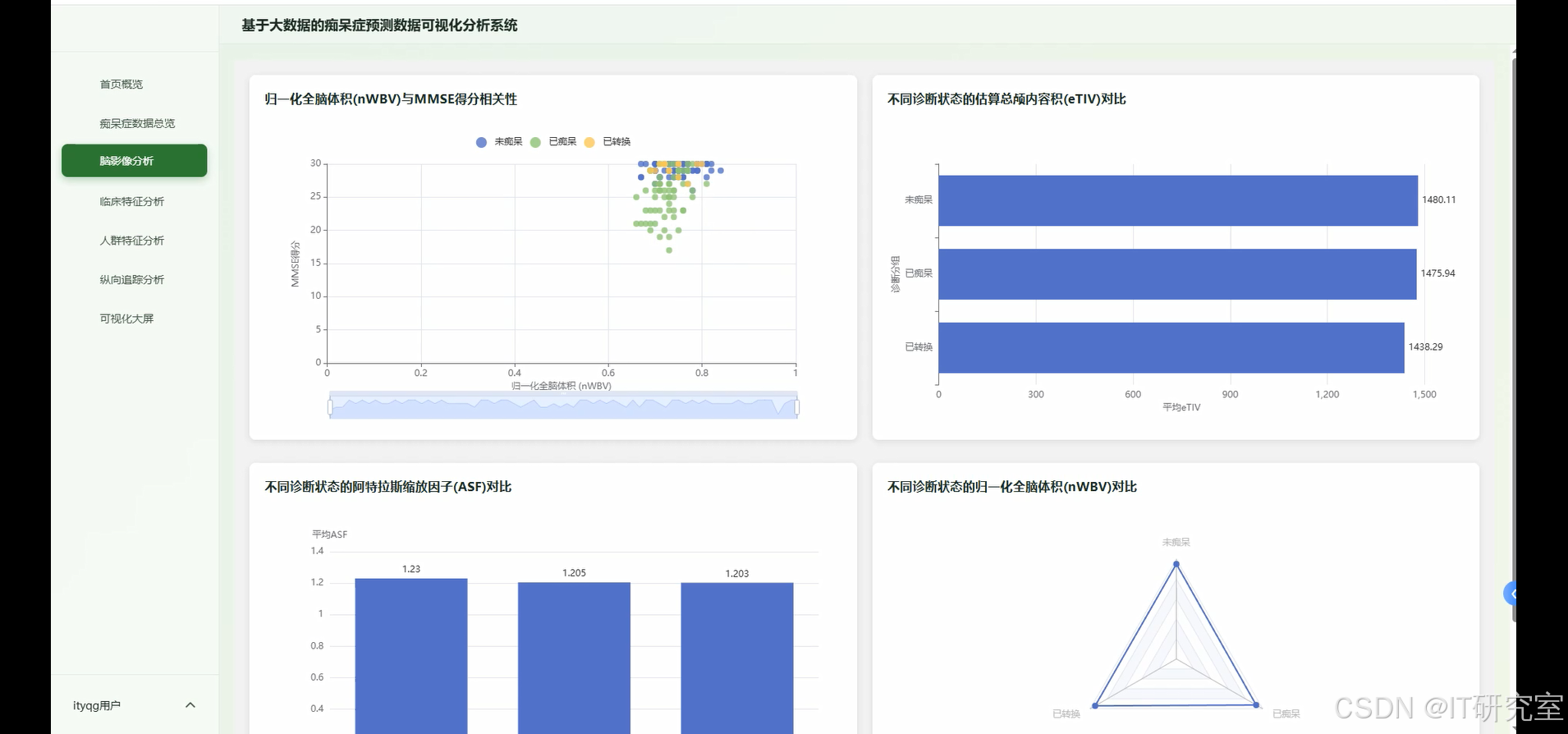
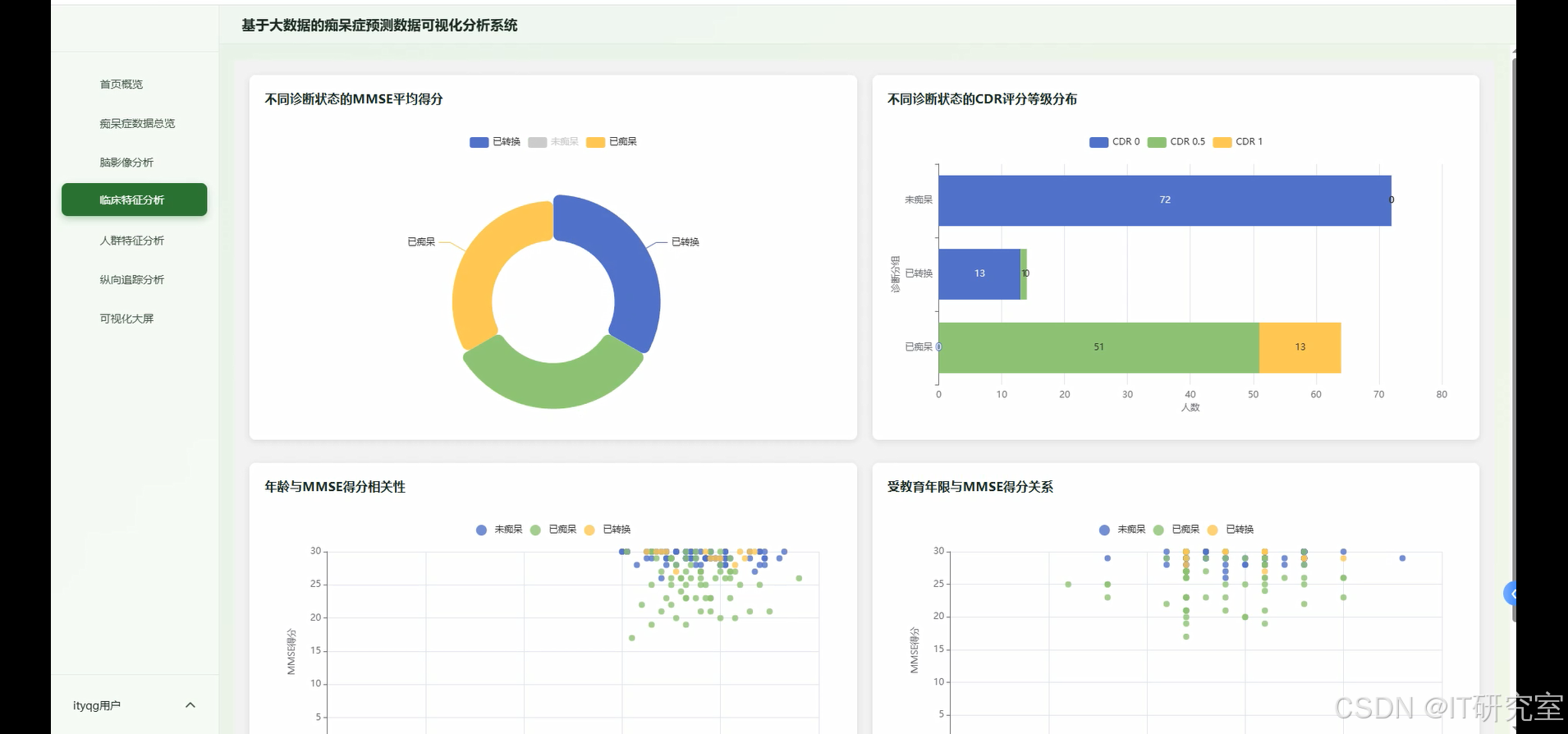
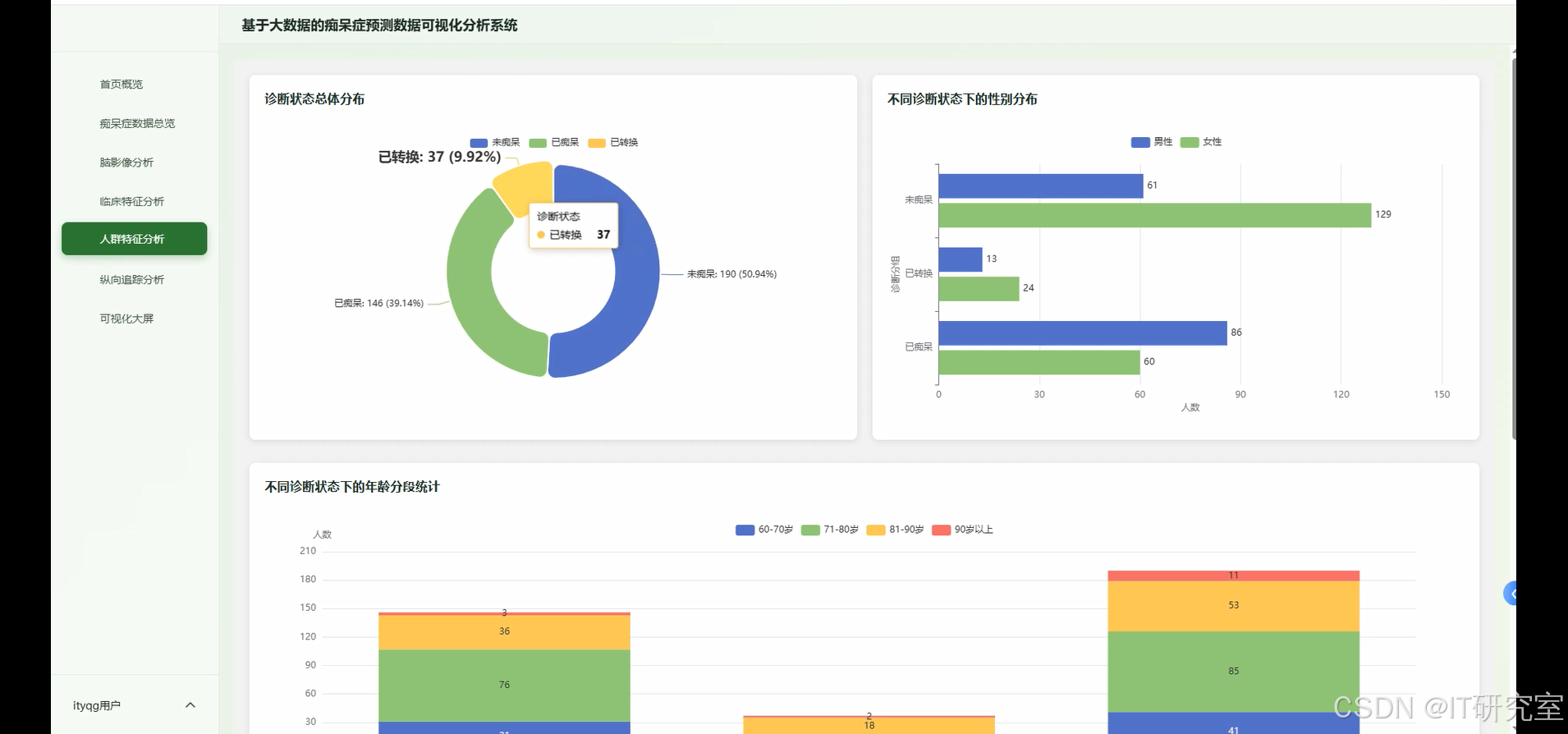
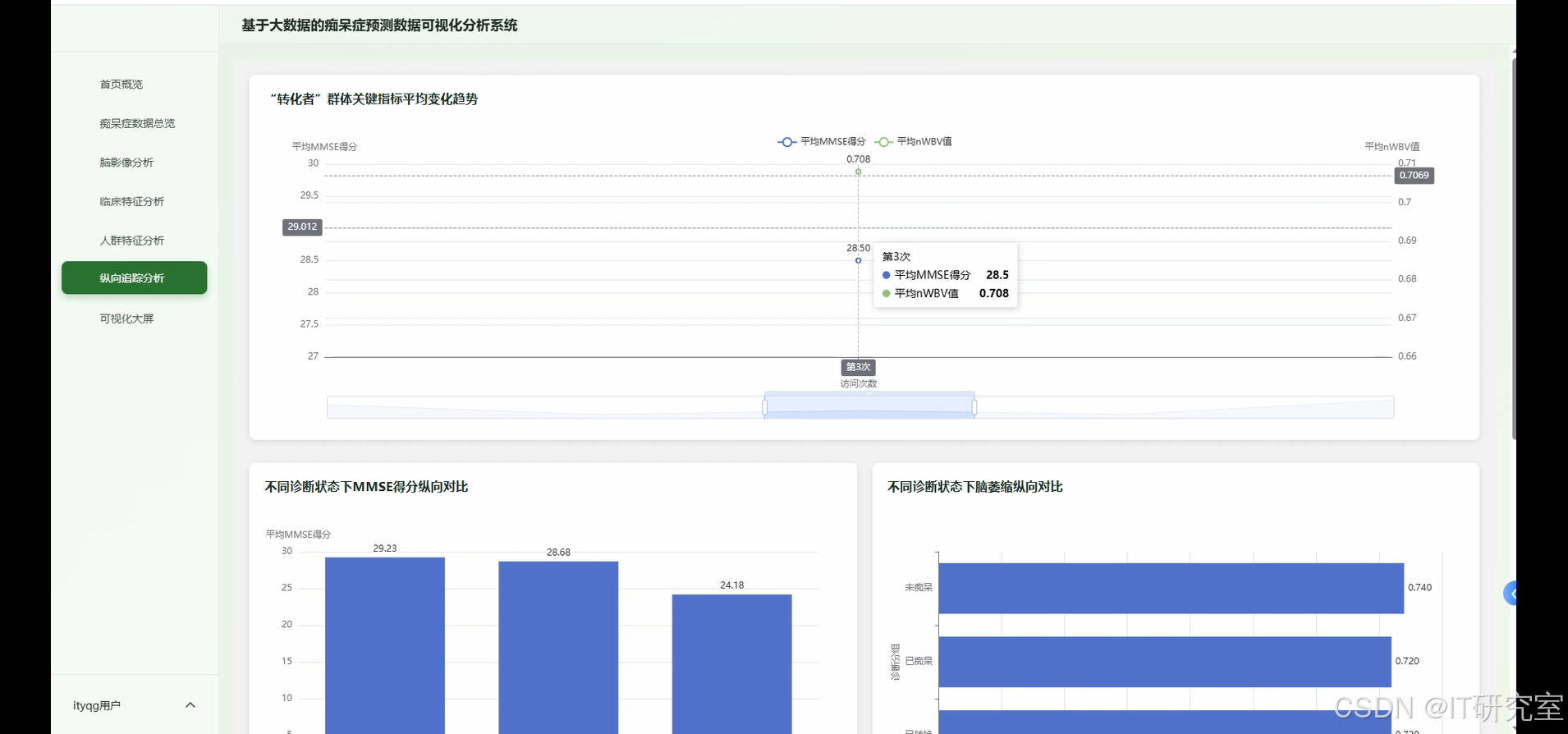
四、代码参考
- 项目实战代码参考:
java(贴上部分代码)
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, when, avg
import pandas as pd
import numpy as np
from django.http import JsonResponse
import joblib
spark = SparkSession.builder.appName("DementiaPredictionSystem").getOrCreate()
def load_and_clean_data(hdfs_path):
df = spark.read.csv(hdfs_path, header=True, inferSchema=True)
df = df.withColumn("age", col("age").cast("int"))
df = df.withColumn("gender", when(col("gender") == "M", 1).otherwise(0))
df = df.dropna()
df = df.filter((col("age") > 40) & (col("age") < 100))
df = df.withColumn("bmi", when(col("bmi").isNull(), avg("bmi").over()).otherwise(col("bmi")))
return df
def predict_dementia(data_path, model_path):
df = load_and_clean_data(data_path)
pandas_df = df.toPandas()
features = pandas_df.drop(columns=["label"])
model = joblib.load(model_path)
preds = model.predict(features)
pandas_df["prediction"] = preds
result = pandas_df[["age","gender","prediction"]].to_dict(orient="records")
return result
def generate_visualization_data(request):
df = load_and_clean_data("hdfs://localhost:9000/dementia/data.csv")
summary = df.groupBy("age").agg(avg("label").alias("risk"))
pandas_df = summary.toPandas()
result = []
for _,row in pandas_df.iterrows():
result.append({"age": int(row["age"]), "risk五、系统视频
基于大数据的痴呆症预测数据可视化分析系统项目视频:
大数据毕业设计选题推荐-基于大数据的痴呆症预测数据可视化分析系统-Spark-Hadoop-Bigdata
结语
大数据毕业设计选题推荐-基于大数据的痴呆症预测数据可视化分析系统-Spark-Hadoop-Bigdata
想看其他类型的计算机毕业设计作品也可以和我说~谢谢大家!
有技术这一块问题大家可以评论区交流或者私我~
大家可以帮忙点赞、收藏、关注、评论啦~
源码获取:⬇⬇⬇