PyTorch实战(3)------PyTorch vs. TensorFlow详解
0. 前言
PyTorch 是一个基于 Torch 库的 Python 机器学习库,广泛用于深度学习的科研和应用开发,主要由 Meta 开发。PyTorch 是另一个知名深度学习库 TensorFlow (由 Google 开发)的有力竞争者,最初,这两者的主要区别在于,PyTorch 基于即时执行 (eager execution),而 TensorFlow 1.x 基于图计算的延迟执行 (deferred execution),但现在 TensorFlow2.x 也提供了即时执行模式。
即时执行基本上是一种命令式编程模式,在这种模式下,数学操作会立即计算。而延迟执行模式会将所有操作存储在计算图中,不立即计算,直到构建完成才对整个图进行评估。即时执行的优势在于其直观的流程、易于调试以及更少的辅助代码。
PyTorch 通过类似 NumPy 的语法/接口,提供了张量计算能力,并能利用 GPU 实现加速计算。张量是计算单元,类似于 NumPy 数组,不同之处在于张量可以在 GPU 上使用,以加速计算。
凭借加速计算能力和创建动态计算图,PyTorch 提供了一个完整的深度学习框架。除此之外,它具有真正的 Python 风格,使 PyTorch 用户能够充分利用 Python 的所有特性,包括丰富的 Python 数据科学生态系统。
在本节中,我们将深入探讨张量的概念及其在 PyTorch 中的实现方式,以及张量具有的属性。我们还将了解一些常用的 PyTorch 模块,这些模块扩展了数据加载、模型构建以及训练过程中优化算法的功能。我们将这些 PyTorch API 与 TensorFlow 的对应功能进行对比,以了解两者在底层实现上的差异。
1. 张量
张量 (Tensor) 的概念类似于 NumPy 数组。张量是一个 n n n 维数组,我们可以对其执行数学函数、通过 GPU 加速计算,还可以跟踪计算图和梯度,这些功能对深度学习至关重要。为了在 GPU 上运行张量,只需将张量转换为特定的数据类型即可。
(1) 使用 PyTorch 实例化一个张量:
python
points = torch.tensor([1.0, 2.0, 3.0, 4.0, 5.0])(2) 获取第一个元素:
python
points[0](4) 查看张量的形状:
python
points.shape(5) 使用 TensorFlow 声明一个张量:
python
points_tf = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0])访问第一个元素或获取张量形状的命令与 PyTorch 相同。
(6) 在 PyTorch 中,张量是对存储在连续内存块中的一维数组的视图,这些数组称为存储实例。每个 PyTorch 张量都有一个 untyped_storage() 属性,可以调用它来输出张量的底层存储实例:
python
points = torch.tensor([[1.0, 2.0], [3.0, 4.0], [5.0, 6.0]])
points.untyped_storage()输出结果如下所示:
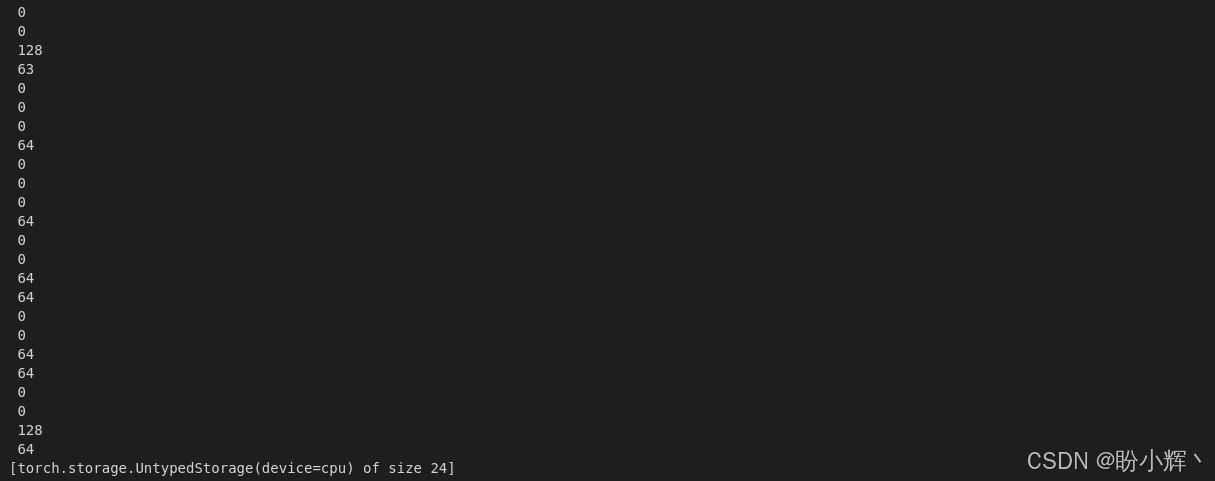
TensorFlow 张量没有 untyped_storage() 属性。PyTorch 张量是存储实例的视图,张量使用以下信息来实现该视图:
- 大小 (
Size) - 存储 (
Storage) - 偏移量 (
Offset) - 步长 (
Stride)
这些信息的含义如下:
-
size类似于NumPy中的shape属性,表示每个维度上的元素数量:pythonpoints.size()这些数字的乘积等于底层存储实例的长度(本例中为
6):shelltorch.Size([3, 2]) -
storage:底层存储实例 -
offset:张量的第一个元素在存储数组中的索引 -
stride:表示在每个维度上移动一个元素所需的步长
在 TensorFlow 中,张量的形状可以通过使用 shape 属性获取:
python
points_tf = tf.constant([[1.0, 2.0], [3.0, 4.0], [5.0, 6.0]])
points_tf.shape输出结果如下所示:
python
TensorShape([3, 2])我们已经了解了 PyTorch 张量的 untyped_storage() 属性,接下来我们看看偏移量 (offset):
python
points.storage_offset()输出结果如下所示:
shell
0offset 表示张量的第一个元素在存储数组中的索引。由于输出为 0,这意味着张量的第一个元素是存储数组的第一个元素。使用以下代码进行验证:
python
points[1].storage_offset()输出结果如下所示:
shell
2因为 points[1] 是 [3.0, 4.0],而存储数组是 [[1.0, 2.0], [3.0, 4.0], [5.0, 6.0]],可以看到张量中的第一个元素 [3.0, 4.0],在存储数组中的索引位置为 2。
接下来,查看 stride 属性:
python
points.stride()输出结果如下所示:
shell
(2, 1)可以看到,stride 属性表示在每个维度上访问下一个元素需要跳过的元素数量。因此,在以上例子中,沿着第一个维度,若要访问第一个元素之后的元素(即 1.0),我们需要跳过 2 个元素(即 1.0 和 2.0),才能访问下一个元素,即 3.0。类似地,沿着第二个维度,我们需要跳过 1 个元素,才能访问 1.0 之后的元素,即 2.0。因此,使用这些属性,张量可以从一个连续的一维存储数组中推导出来。TensorFlow 张量并没有 stride 或 storage_offset 属性。
(7) 张量中包含的数据是数值类型的。具体来说,PyTorch 提供了以下几种数据类型供张量使用:
torch.float32或torch.float---32位浮点数torch.float64或torch.double---64位双精度浮点数torch.float16或torch.half---16位半精度浮点数torch.int8--- 有符号8位整数torch.uint8--- 无符号8位整数torch.int16或torch.short--- 有符号16位整数torch.int32或torch.int--- 有符号32位整数torch.int64或torch.long--- 有符号64位整数
TensorFlow 也提供了类似的数据类型。
(8) 在 PyTorch 中,可以使用 dtype 属性为张量指定特定数据类型:
python
points = torch.tensor([[1.0,2.0],[3.0,4.0]], dtype=torch.float16)在 TensorFlow 中,可以通过以下等效代码实现:
python
points_tf = tf.constant([[1.0,2.0],[3.0,4.0]], dtype=tf.float16)(9) 除了数据类型,PyTorch 中的张量可以指定存储设备:
python
points = torch.tensor([[1.0,2.0],[3.0,4.0]], dtype=torch.float16, device='cuda')我们也可以在目标设备上创建张量的副本:
python
points_2 = points.to(device='cuda')从以上示例可以看出,我们可以将张量分配到 CPU (使用 device='cpu'),如果不指定设备,默认情况下会分配到 CPU,也可以将张量分配给 GPU (使用 device='cuda')。在 TensorFlow 中,可以使用以下方式分配设备:
python
with tf.device('/gpu:0'):
points_tf = tf.constant([[1.0,2.0],[3.0,4.0]], dtype=tf.float16)PyTorch 支持 NVIDIA (CUDA) 和 AMD GPU。
当张量被放置在 GPU 上时,计算速度会显著加快,并且由于 PyTorch 中的张量 API 在 CPU 和 GPU 张量间基本一致,因此可以很方便的在设备之间移动张量、执行计算并移回。
如果有多个相同类型的设备,比如多个 GPU,我们可以通过设备索引精确指定张量放置的设备:
python
points_3 = points.to(device='cuda:0')接下来,我们将介绍一些用于构建深度学习模型的重要 PyTorch 模块。
2. PyTorch 模块
PyTorch 库不仅提供了类似 NumPy 的计算功能,还提供了一系列模块,帮助开发者快速设计、训练和测试深度学习模型。
2.1 torch.nn
在构建神经网络架构时,网络的基本组成要素包括层数、每层的神经元数量,以及哪些神经元是可学习的等。PyTorch 的 nn 模块允许用户通过定义这些高层次特性快速实例化神经网络架构,而不需要手动指定所有的细节。如果不使用 nn 模块,需要使用以下方式进行单层神经网络初始化:
python
import math
weights = torch.randn(256, 4) / math.sqrt(256)
weights. requires_grad_()
bias = torch.zeros(4, requires_grad=True)而使用 nn 模块,nn.Linear(256, 4) 就可以实现相同的功能。在 TensorFlow 中,可以使用以下方式实现:
python
tf.keras.layers.Dense(256, input_shape=(4, ), activation=None)在 torch.nn 模块中,有一个 torch.nn.functional 子模块,包含了 torch.nn 模块中的所有函数,包括损失函数、激活函数,以及用于以函数式方式创建神经网络的函数(即将每一层表示为前一层输出的函数),例如池化、卷积和线性函数。使用 torch.nn.functional 模块定义损失函数:
python
import torch.nn.functional as F
loss_func = F.cross_entropy
loss = loss_func(model(X), y)其中,X 是输入,y 是目标输出,model 是神经网络模型。在 TensorFlow 中,上述代码可以写成:
python
import tensorflow as tf
loss_func = tf.keras.losses.SparseCategoricalCrossentropy()
loss = loss_func(y, model(X))2.2 torch.optim
在训练神经网络时,我们通过反向传播调整网络的权重或参数,这一过程称为优化。optim 模块包含了与训练深度学习模型时运行各种优化算法相关的工具和功能。
使用 torch.optim 模块在训练过程中定义优化器:
python
opt = optim.SGD(model.parameters(), lr=lr)如果,我们手动编写优化步骤:
python
with torch.no_grad():
for param in model.parameters():
param -= param.grad * lr
model.zero_grad()使用优化器可以简洁地写成如下形式:
python
opt.step()
opt.zero_grad()TensorFlow 不需要显式地编写梯度更新和清除步骤,使用优化器代码如下:
python
opt = tf.keras.optimizers.SGD(learning_rate=lr)
model.compile(optimizer=opt, loss=loss)2.3 torch.utils.data
在 utils.data 模块下,PyTorch 提供了 Dataset 和 DataLoader 类,这些类因其抽象且灵活的实现而非常实用,这些类提供了直观的方式来迭代数据和其他操作。通过使用这些类,我们可以确保高性能的张量计算,并实现可靠的数据输入/输出。可以通过以下方式使用 torch.utils.data.DataLoader:
python
from torch.utils.data import TensorDataset, DataLoader
train_dataset = TensorDataset(x_train, y_train)
train_dataloader = DataLoader(train_dataset, batch_sise)使用这种方式,我们就不需要手动遍历数据批次:
python
for i in range((n-1)//bs + 1):
x_batch = x_train[start_i:end_i]
y_batch = y_train[start_i:end_i]
pred = model(x_batch)我们可以简单地写成:
python
for x_batch, y_batch in train_dataloader:
pred = model(x_batch)torch.utils.data 类似于 TensorFlow 中的 tf.data.Dataset。在 TensorFlow 中,遍历数据批次的代码如下:
python
train_dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_dataloader = train_dataset.batch(bs)
for x_batch, y_batch in train_dataloader:
pred = model(x_batch)我们已经了解了 PyTorch 库,并了解了 PyTorch 的张量。接下来,我们将学习如何使用 PyTorch 训练神经网络。
3. 使用 PyTorch 训练神经网络
在本节中,我们将使用 MNIST 数据集,该数据集包含手写邮政编码数字( 0 到 9 )的图像及其对应的标签。MNIST 数据集包含 60000 个训练样本和 10000 个测试样本,每个样本都是一张 28x28 像素的灰度图像。PyTorch 在 Dataset 模块中提供了 MNIST 数据集。我们将使用 PyTorch 在 MNIST 数据集上训练一个深度学习多类分类器,并测试训练后的模型在测试样本上的表现。
(1) 首先,导入所需库:
python
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import matplotlib.pyplot as plt(2) 接下来,定义模型架构,如下图所示:
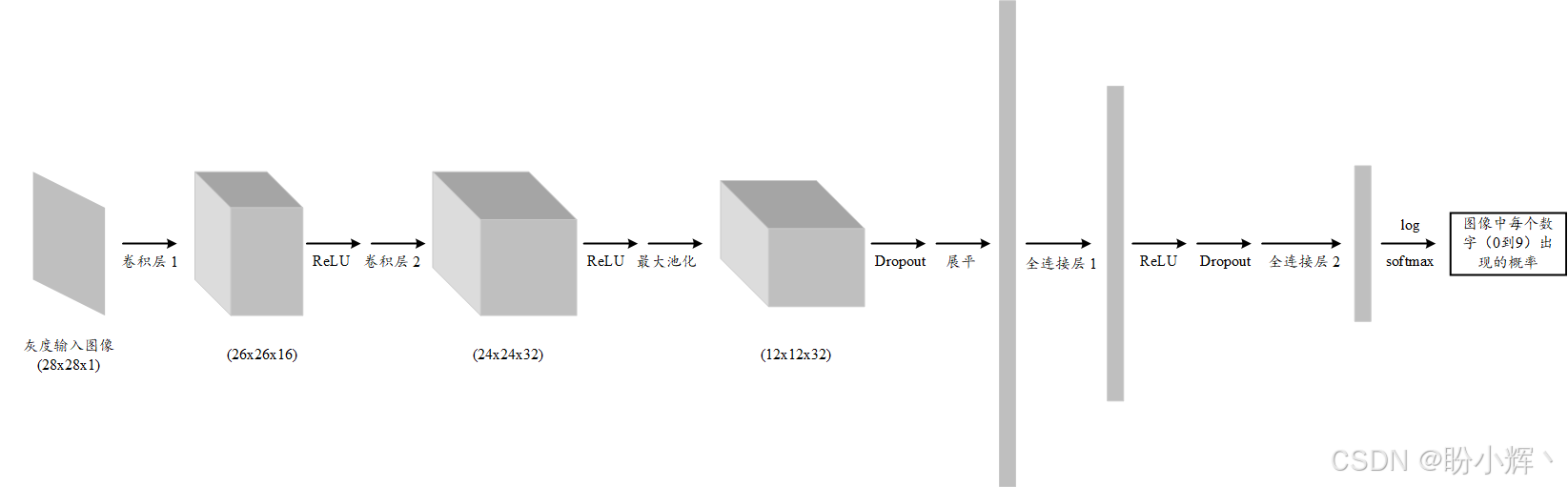
该模型由卷积层、Dropout 层以及线性(全连接)层组成,这些层都可以通过 torch.nn 模块实现:
python
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet, self).__init__()
self.cn1 = nn.Conv2d(1, 16, 3, 1)
self.cn2 = nn.Conv2d(16, 32, 3, 1)
self.dp1 = nn.Dropout(0.10)
self.dp2 = nn.Dropout(0.25)
self.fc1 = nn.Linear(4608, 64) # 4608 is basically 12 X 12 X 32
self.fc2 = nn.Linear(64, 10)
def forward(self, x):
x = self.cn1(x)
x = F.relu(x)
x = self.cn2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dp1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dp2(x)
x = self.fc2(x)
op = F.log_softmax(x, dim=1)
return op__init__ 函数定义了模型的核心架构,forward 函数执行网络的前向传播,它包括了每层的激活函数以及池化或 Dropout 操作,函数返回模型的最终输出(即预测值),其维度与目标输出(真实标签)相同。
第一个卷积层的输入通道为 1 (灰度图像),输出通道为 16,卷积核大小为 3,步幅为 1。输入通道为 1 是因为输入图像是灰度图,选择 3x3 的卷积核基于以下原因:
- 卷积核的大小通常是奇数,以便输入图像的像素围绕中心像素对称分布
1x1的卷积核太小,无法捕捉相邻像素的信息3x3是计算机视觉问题中最常用的卷积核大小之一,因为它能够捕捉局部视觉特征
不选择 5、7 或者 27 是由于当卷积核的大小过大时,比如 27x27,在 28x28 的图像上卷积,会得到非常粗略的特征。然而,图像中的最重要视觉特征通常是局部的(在较小的空间邻域内),因此使用一个小卷积核逐步查看邻近像素来提取视觉模式更为合理。3x3 是 CNN 中解决计算机视觉问题时最常用的卷积核大小之一。
需要注意的是,我们使用两个连续的卷积层,两个卷积层的卷积核大小都是 3x3。从空间覆盖的角度来看,这相当于使用一个 5x5 的卷积核进行一次卷积。然而,通常更倾向于使用多个小卷积核的层,因为这样可以构建更深的网络,从而学习到更复杂的特征,同时,由于卷积核较小,参数也较少。通过在多个层中使用多个小卷积核,会得到专门检测不同特征的卷积核------例如有些用于检测边缘,有些用于检测圆形,有些用于检测红色等。
第一个卷积层输入的是单通道数据,输出 16 个通道。这意味着该层正在尝试从输入图像中提取 16 种不同类型的信息。每个输出通道称为特征图,每个特征图都有一个专门的卷积核来提取其对应的特征。
第二个卷积层中将通道数从 16 增加到 32,旨在从图像中提取更多种类的特征。卷积层输出通道设计通常遵循先增加后减小的原则。
本节中,我们将步幅 (stride) 设置为 1,因为卷积核大小仅为 3。如果步幅值过大,卷积核会跳过图像中的许多像素,这不利于特征提取。如果卷积核大小是 100,那么可能会考虑将步幅设置为 10。步幅越大,卷积操作的次数越少,卷积核的视野 (field of view) 也会越小。
以上代码也可以使用 torch.nn.Sequential API 来编写:
python
model = nn.Sequential(
nn.Conv2d(1, 16, 3, 1),
nn.ReLU(),
nn.Conv2d(16, 32, 3,1 ),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Dropout(0.1),
nn.Flatten(),
nn.Linear(4068, 64),
nn.ReLU(),
nn.Dropout(0.25),
nn.Linear(64, 10),
nn.LogSoftmax(dim=1)
)通常推荐通过单独的 __init__ 和 forward 方法来初始化模型,以便在模型层并非顺序执行(例如并行或跳跃连接)时,能够更灵活地定义模型功能。使用 Sequential 的代码与使用 TensorFlow 非常相似:
python
import tensorflow as tf
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(16, 3, activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=(2, 2)),
tf.keras.layers.Dropout(0.1),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dropout(0.25),
tf.keras.layers.Dense(10, activation='softmax')
])而使用 __init__ 和 forward 方法的代码在 TensorFlow 中如下:
python
class ConvNet(tf.keras.Model):
def __init__(self):
super(ConvNet, self).__init__()
self.cn1 = tf.keras.layers.Conv2D(16, 3, activation='relu', input_shape=(28, 28, 1))
self.cn2 = tf.keras.layers.Conv2D(32, 3, activation='relu')
self.dp1 = tf.keras.layers.Dropout(0.10)
self.dp2 = tf.keras.layers.Dropout(0.25)
self.flatten = tf.keras.layers.Flatten()
self.fc1 = tf.keras.layers.Dense(64, activation='relu')
self.fc2 = tf.keras.layers.Dense(10, activation='softmax')
def call(self, x):
x = self.cn1(x)
x = self.cn2(x)
x = tf.keras.layers.MaxPooling2D(pool_size=(2, 2))(x)
x = self.dp1(x)
x = self.flatten(x)
x = self.fc1(x)
x = self.dp2(x)
x = self.fc2(x)
return x在 TensorFlow 中,使用 call 方法代替 forward,其余部分与 PyTorch 代码类似。
(3) 接下来,定义训练过程,即实际的反向传播步骤。可以看到,torch.optim 模块极大地简化了代码:
python
def train(model, device, train_dataloader, optim, epoch):
model.train()
for b_i, (X, y) in enumerate(train_dataloader):
X, y = X.to(device), y.to(device)
optim.zero_grad()
pred_prob = model(X)
loss = F.nll_loss(pred_prob, y) # nll is the negative likelihood loss
loss.backward()
optim.step()
if b_i % 10 == 0:
print('epoch: {} [{}/{} ({:.0f}%)]\t training loss: {:.6f}'.format(
epoch, b_i * len(X), len(train_dataloader.dataset),
100. * b_i / len(train_dataloader), loss.item()))train() 函数以批次遍历数据集,将数据复制到指定设备上,通过神经网络模型进行前向传播,计算模型预测值与真实标签之间的损失,使用优化器调整模型权重,并每 10 个批次打印一次训练日志。整个过程执行一次称为一个 epoch,即完整遍历一次数据集对于 TensorFlow,我们可以直接以高级方式直接运行训练。PyTorch 中详细的训练过程定义使我们能够更灵活地控制训练过程,而不是用一行高级代码完成训练。
(4) 与训练过程类似,编写一个测试过程,用于评估模型在测试集上的表现:
python
def test(model, device, test_dataloader):
model.eval()
loss = 0
success = 0
with torch.no_grad():
for X, y in test_dataloader:
X, y = X.to(device), y.to(device)
pred_prob = model(X)
loss += F.nll_loss(pred_prob, y, reduction='sum').item() # loss summed across the batch
pred = pred_prob.argmax(dim=1, keepdim=True) # us argmax to get the most likely prediction
success += pred.eq(y.view_as(pred)).sum().item()
loss /= len(test_dataloader.dataset)
print('\nTest dataset: Overall Loss: {:.4f}, Overall Accuracy: {}/{} ({:.0f}%)\n'.format(
loss, success, len(test_dataloader.dataset),
100. * success / len(test_dataloader.dataset)))test() 函数的大部分内容与 train() 函数类似。唯一的区别是,计算出的模型预测与真实标签之间的损失不会用来调整模型权重,而是用于计算整个测试批次的总体测试误差。
(5) 接下来,加载数据集。得益于 PyTorch 的 DataLoader 模块,我们可以方便的设置数据集加载机制:
python
train_dataloader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1302,), (0.3069,))])), # train_X.mean()/256. and train_X.std()/256.
batch_size=32, shuffle=True)
test_dataloader = torch.utils.data.DataLoader(
datasets.MNIST('./data', train=False,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1302,), (0.3069,))
])),
batch_size=500, shuffle=False)可以看到,我们将批大小 batch_size 设置为 32。通常,批大小的选择需要权衡:太小的批大小会导致训练速度变慢,因为需要频繁计算梯度,且梯度噪声较大;太大的批大小也会因等待梯度计算时间过长而减慢训练速度。通常不建议等待太长时间才进行一次梯度更新,更频繁但精度较低的梯度更新最终会引导模型学习到更好的参数。
对于训练集和测试集,我们指定了数据集保存的存储位置,并且设置了批大小,批大小决定了每次训练和测试运行中数据实例的数量。此外,我们还随机打乱训练数据实例,以确保数据样本在各个批次中均匀分布。
最后,将数据集归一化,使其符合具有指定均值和标准差的正态分布。如果我们从零开始训练模型,那么均值和标准差来自于训练数据集,如果我们是从一个预训练模型进行迁移学习,那么均值和标准差值将来自于预训练模型的原始训练数据集。
在 TensorFlow 中,我们可以使用 tf.keras.datasets 来加载 MNIST 数据,并使用 tf.data.Dataset 模块从数据集中创建训练数据批次:
python
# Load the MNIST dataset.
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
# Normalize pixel values between 0 and 1
x_train = x_train.astype("float32") / 255.0
x_test = x_test.astype("float32") / 255.0
# Add a channels dimension (required for CNN)
x_train = x_train[..., tf.newaxis]
x_test = x_test[..., tf.newaxis]
# Create a dataloader for training.
train_dataloader = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_dataloader = train_dataloader.shuffle(10000)
train_dataloader = train_dataloader.batch(32)
# Create a dataloader for testing.
test_dataloader = tf.data.Dataset.from_tensor_slices((x_test, y_test))
test_dataloader = test_dataloader.batch(500)(6) 定义优化器和设备,使用它们运行模型训练:
python
device = torch.device("cuda")
model = ConvNet().to(device=device)
optimizer = optim.Adadelta(model.parameters(), lr=0.5)在本节中,使用 Adadelta 作为优化器,学习率设置为 0.5。我们在介绍优化器时提到,如果我们处理的是稀疏数据,选用 Adadelta 可以得到不错的结果。MNIST 数据集就是一个稀疏数据的例子,因为并非图像中的所有像素都具有信息量。但我们也可以尝试其他优化器,如 Adam,来解决这个问题,观察不同优化器对训练过程和模型性能的影响。在 TensorFlow 中,可以使用以下等效代码实例化并编译模型:
python
model = ConvNet()
optimizer = tf.keras.optimizers.experimental.Adadelta(learning_rate=0.5)
model.compile(optimizer=optimizer, loss='sparse_categorical_crossentropy', metrics=['accuracy'])(7) 然后开始实际的模型训练过程,训练多个 epoch,并在每个训练 epoch 结束时测试模型:
python
for epoch in range(1, 3):
train(model, device, train_dataloader, optimizer, epoch)
test(model, device, test_dataloader)训练过程输出结果如下所示:
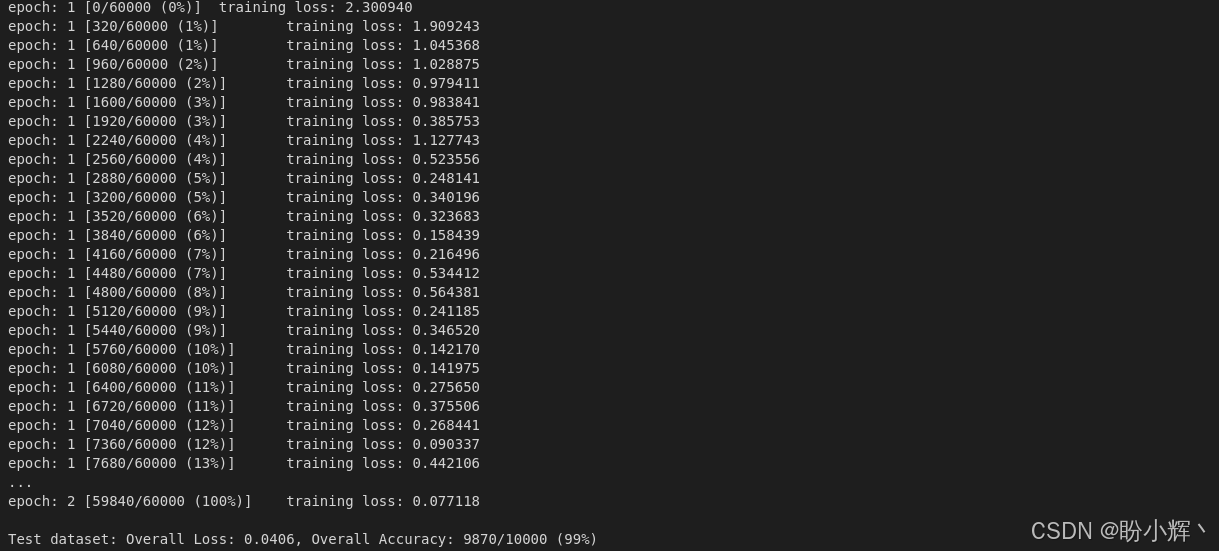
TensorFlow 中的训练循环等效代码如下:
python
model.fit(train_dataloader, epochs=2, validation_data=test_dataloader)(8) 模型训练完成后,我们可以手动检查模型在样本图像上的推理结果是否正确:
python
test_samples = enumerate(test_dataloader)
b_i, (sample_data, sample_targets) = next(test_samples)
plt.imshow(sample_data[0][0], cmap='gray', interpolation='none')
plt.show()输出结果如下所示:
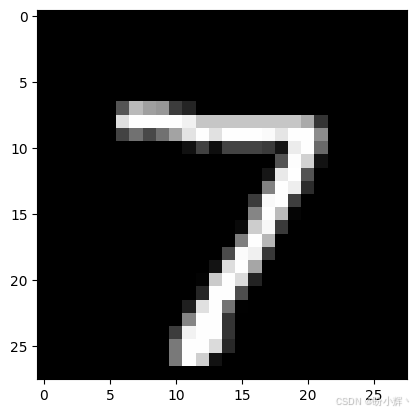
TensorFlow 中的等效代码基本相同,唯一不同的是使用 sample_data[0] 而不是 sample_data[0][0]:
python
test_samples = enumerate(test_dataloader)
b_i, (sample_data, sample_targets) = next(test_samples)
plt.imshow(sample_data[0], cmap='gray', interpolation='none')
plt.show()将图像输入训练后的模型,运行模型推理,并比较预测结果与真实标签:
python
print(f"Model prediction is : {model(sample_data.to(device=device)).data.max(1)[1][0]}")
print(f"Ground truth is : {sample_targets[0]}")需要注意的是,对于预测,首先使用 max() 函数在 axis=1 轴上计算概率最大的类别。max() 函数会输出两个列表------sample_data 中每个样本的类别概率列表和每个样本的类别标签列表。因此,我们使用索引 [1] 选择第二个列表(即类别标签列表),并通过索引 [0] 进一步选择第一个类别标签,以查看 sample_data 中的第一个样本。输出结果如下所示:
shell
Model prediction is : 7
Ground truth is : 7可以看到,得到了正确的预测结果。神经网络的前向传播通过 model() 完成,会得到类别概率。因此,我们使用 max() 函数输出最大概率对应的类别。在 TensorFlow 中,可以使用以下代码获取预测结果:
python
print(f"Model prediction is : {tf.math.argmax(model(sample_data)[0])}")
print(f"Ground truth is : {sample_targets[0]}")小结
在本节中,我们比较了 PyTorch 和 TensorFlow 两大深度学习库,并在模型训练的不同阶段(模型初始化、数据加载、训练循环和模型评估)分析了 PyTorch 与 TensorFlow 的 API 差异,最后,作为实践分别使用 PyTorch 和 TensorFlow 从零开始训练了一个深度学习模型。
系列链接
PyTorch实战(1)------深度学习概述
PyTorch实战(2)------使用PyTorch构建神经网络
PyTorch实战(4)------卷积神经网络(Convolutional Neural Network,CNN)