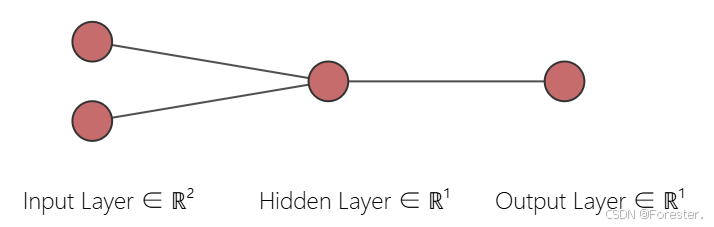
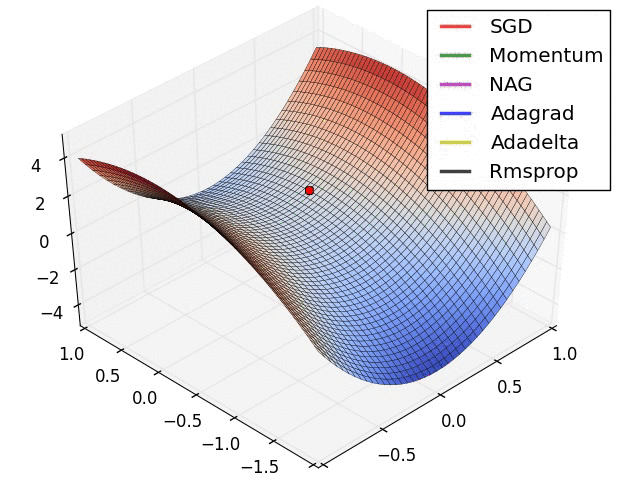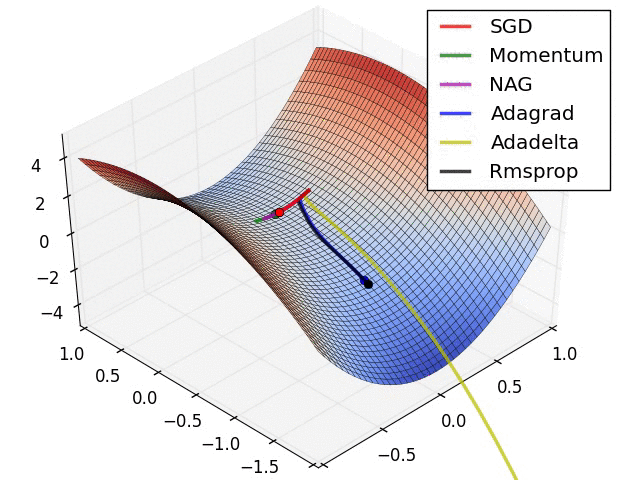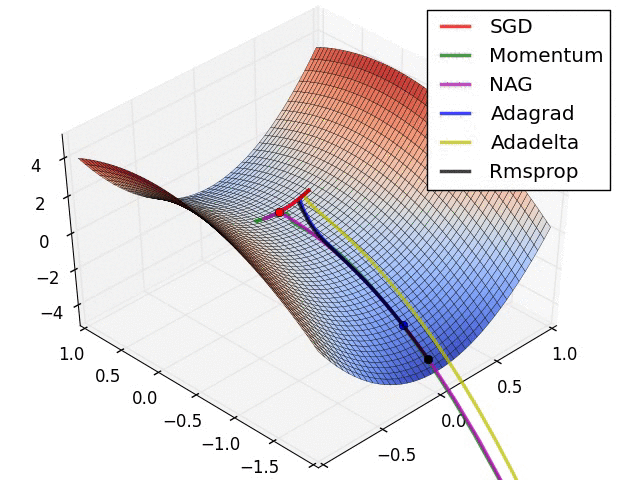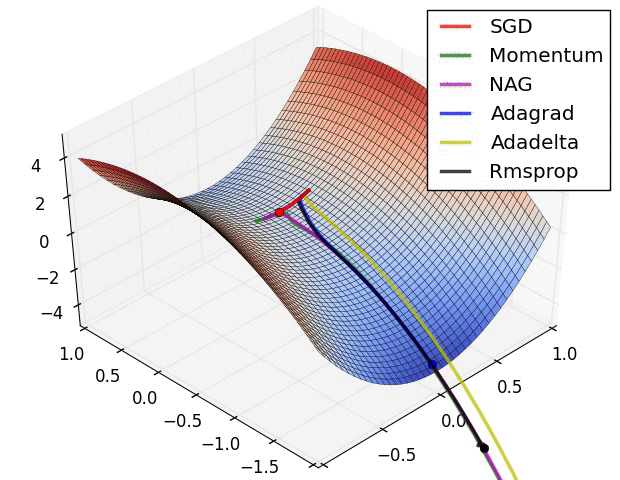
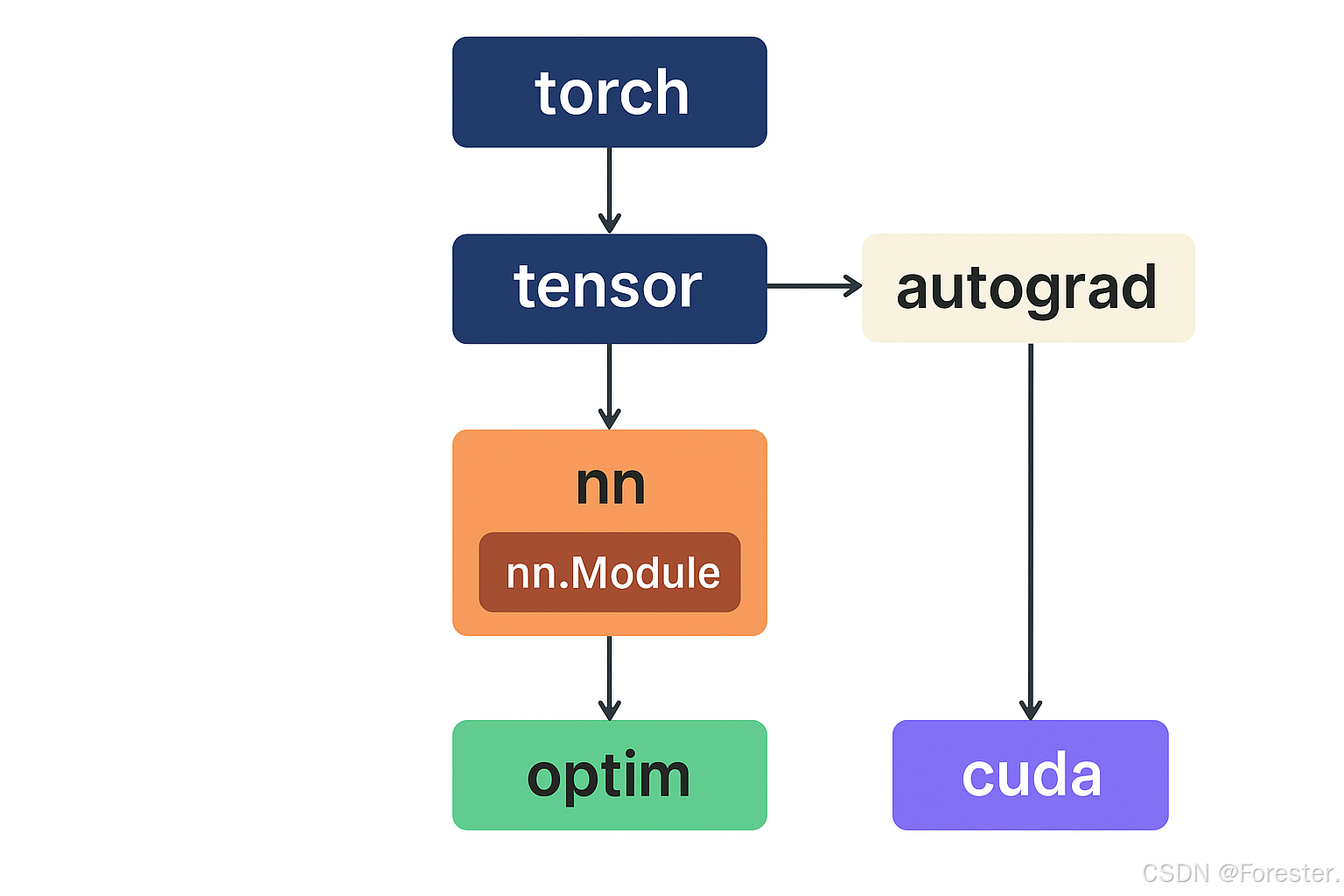
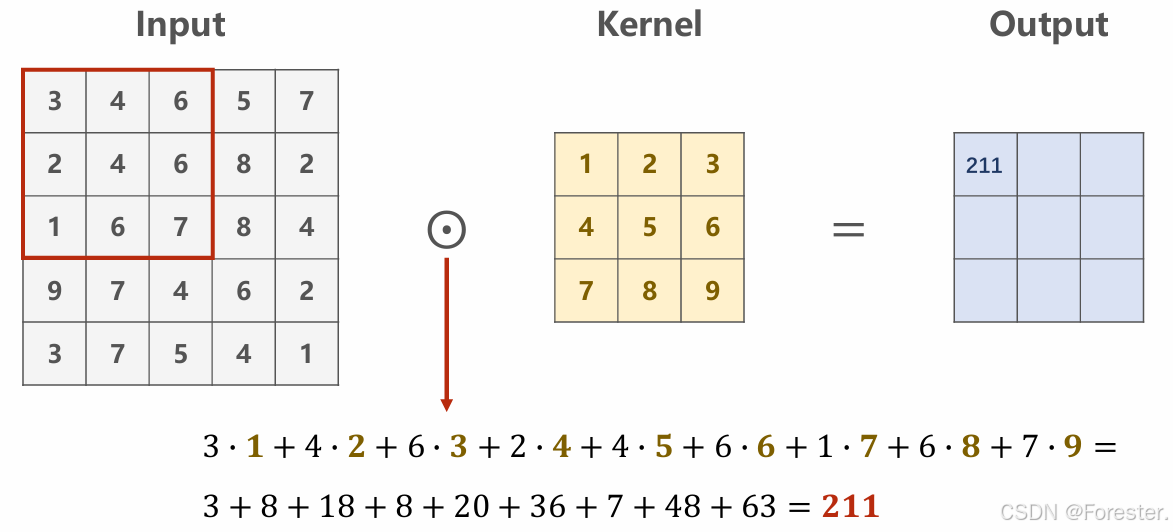
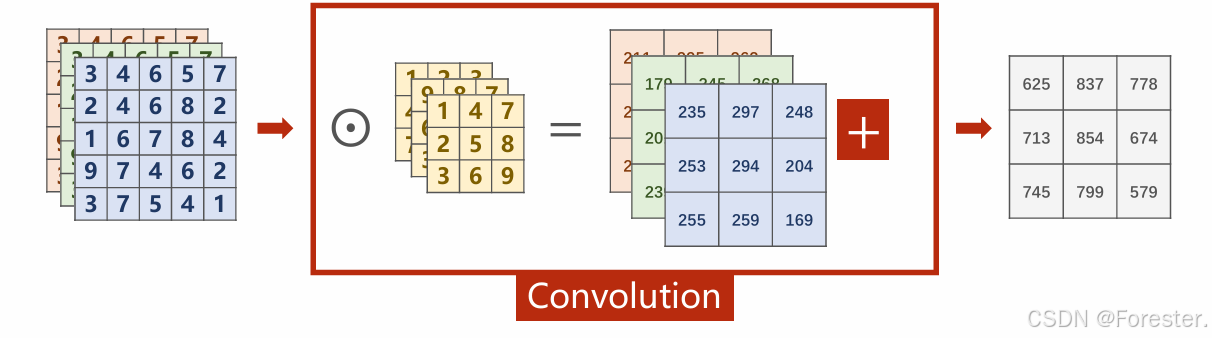
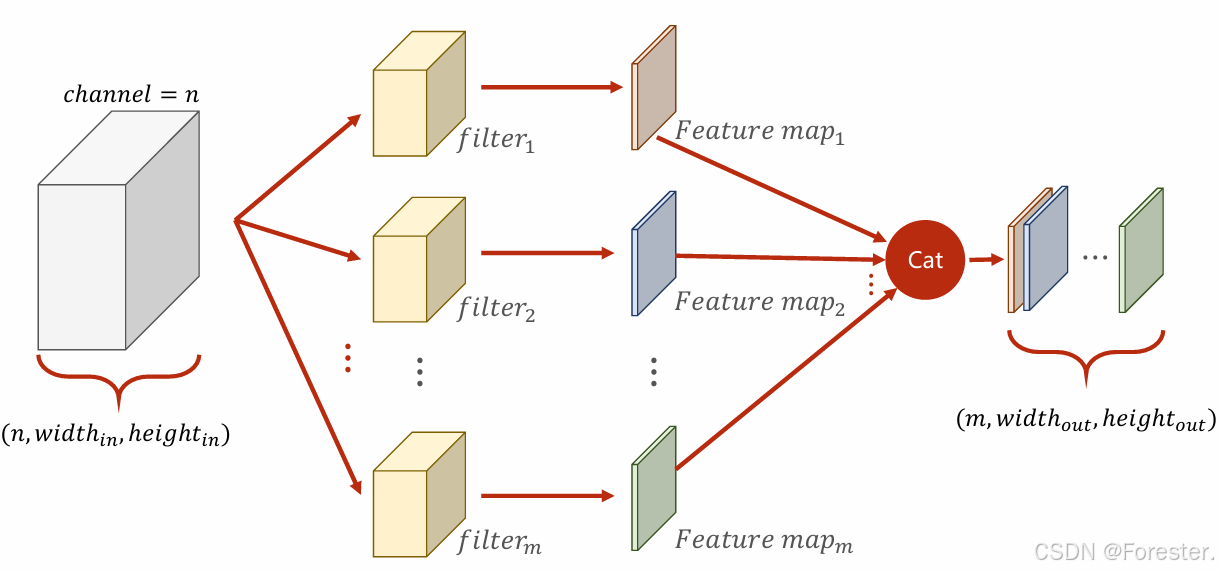
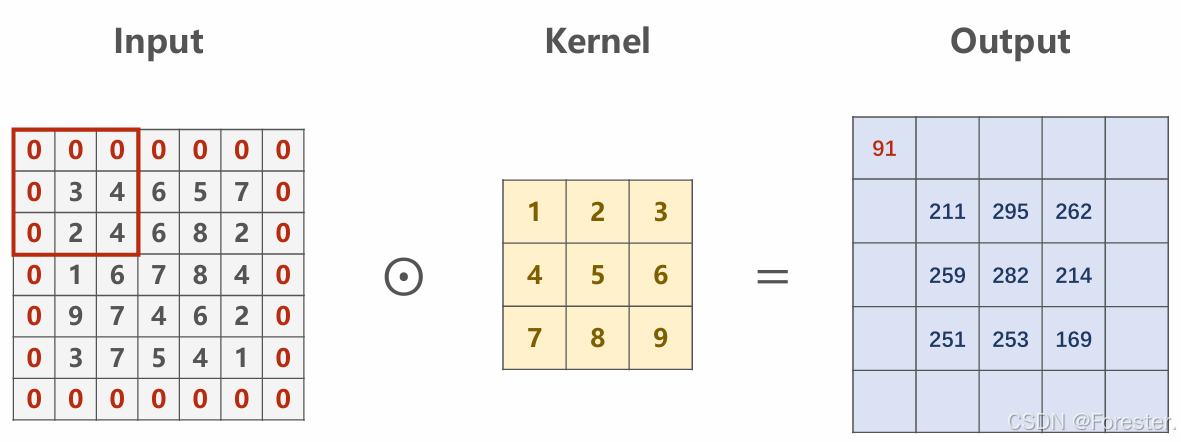
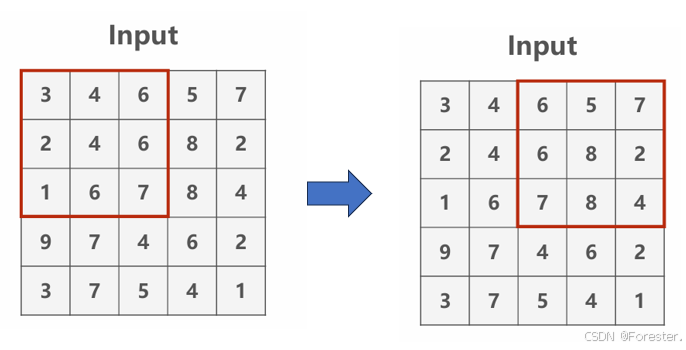
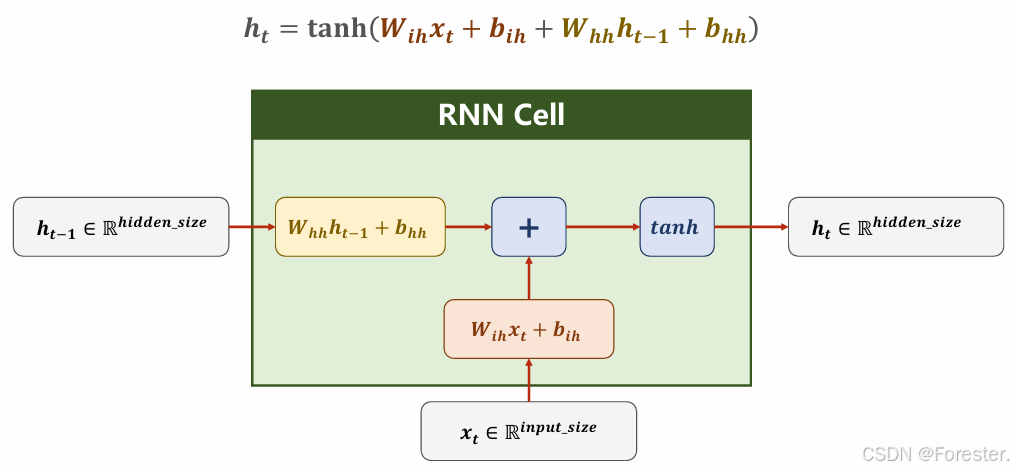
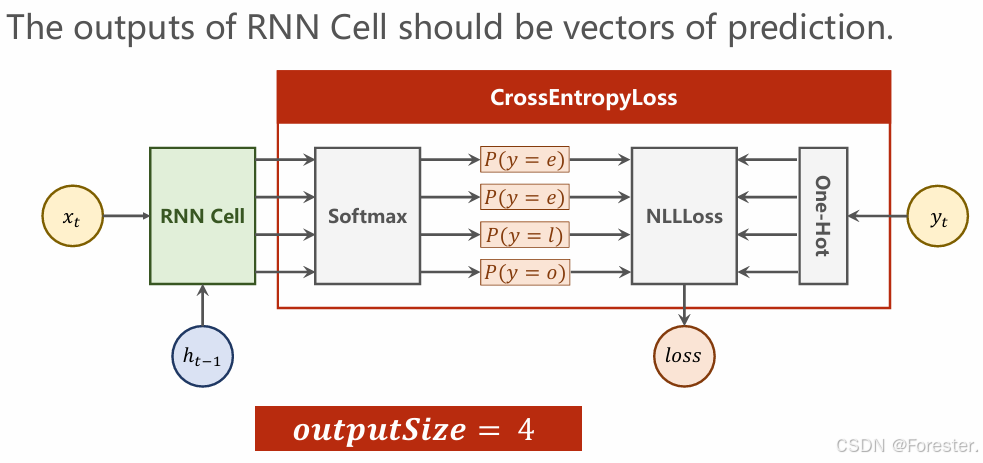
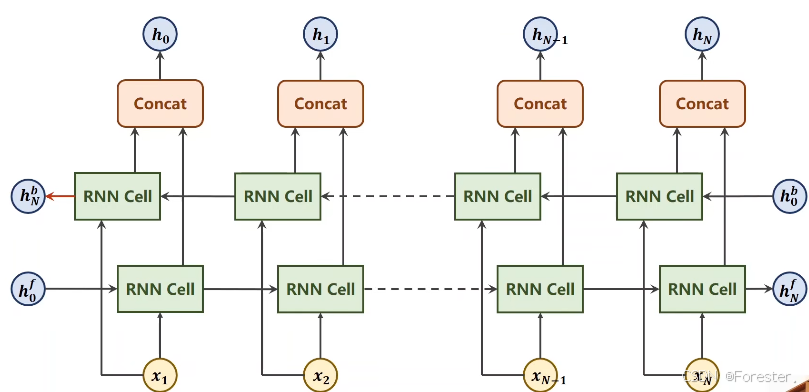
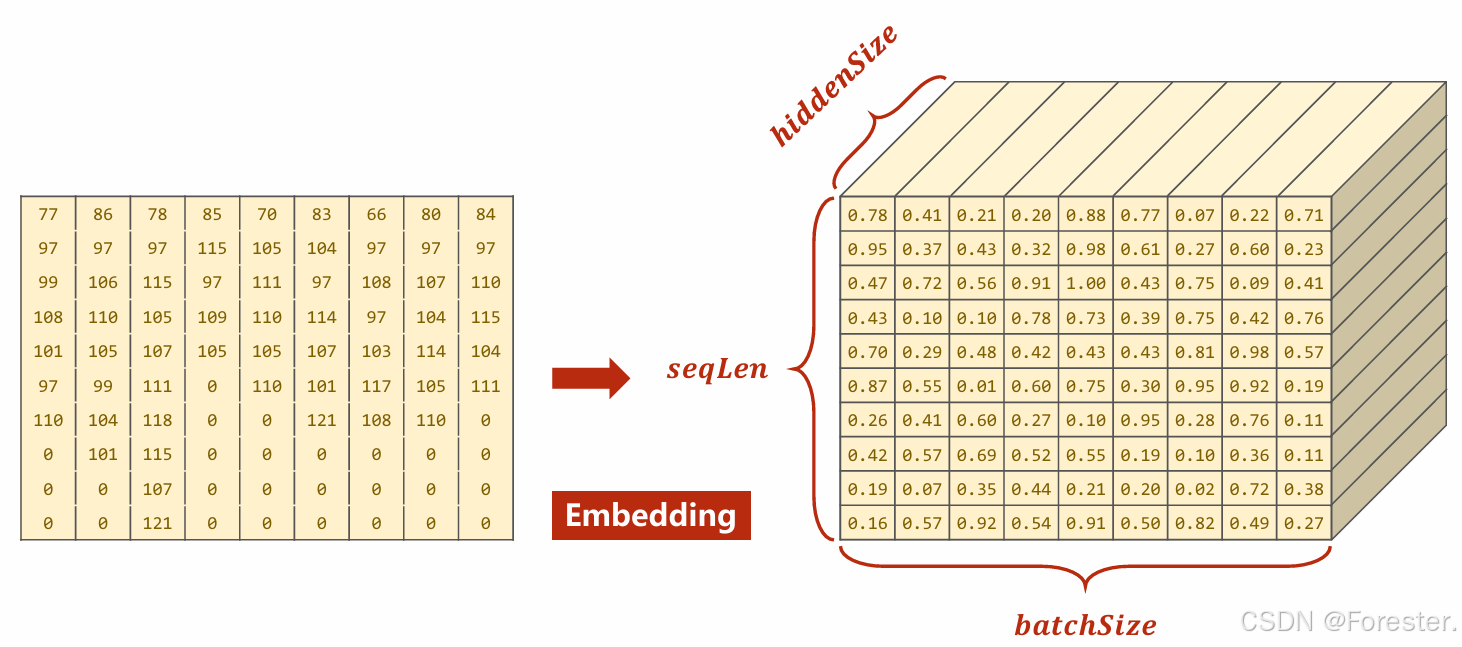
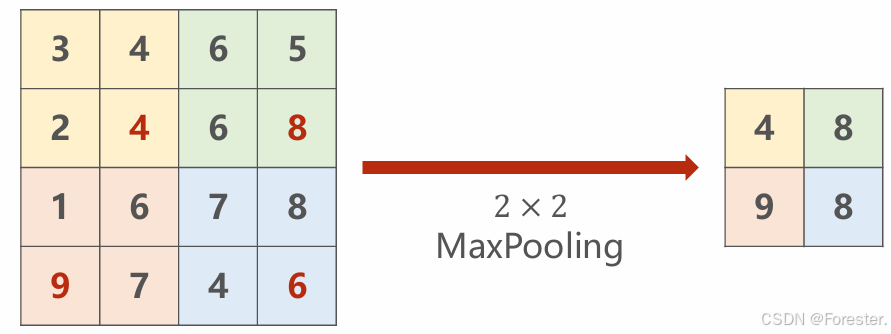深度学习本质思想 :使用 ++"线性函数与非线性激活函数相互嵌套形成的一个函数"++ ,例如式1:
g ( w 3 g ( w 1 x 1 + w 2 x 2 + b 1 ) + b 2 ) ) g(w_3g(w_1x_1+w_2x_2+b_1)+b_2)) g(w3g(w1x1+w2x2+b1)+b2))
来拟合任何函数,解决任何复杂问题。
而这样的函数代数形式过于复杂,将其化为 ++"神经网络"++ 的形式形象表达:
对应式1 :输入层两个节点x1与x2,隐藏层一个节点:
g ( w 1 x 1 + w 2 x 2 + b 1 ) g(w_1x_1+w_2x_2+b_1) g(w1x1+w2x2+b1)
其中需要求解的参数有w1、w2、b1;输出层一个节点:
g ( w 3 g ( w 1 x 1 + w 2 x 2 + b 1 ) + b 2 ) ) g(w_3g(w_1x_1+w_2x_2+b_1)+b_2)) g(w3g(w1x1+w2x2+b1)+b2))
其中参数w3、b2。
如何求解w和b呢?根据已知输入输出值去"猜测"。
先随机给定一组参数值,计算损失函数L(以均方误差MSE为例,后面一说损失函数即指该式)
L ( w , b ) = 1 N ∑ i = 1 N ( y i − y ^ i ) 2 L(w,b) = \frac{1}{N} \sum_{i=1}^{N} (y_i - \hat{y}_i)^2 L(w,b)=N1i=1∑N(yi−y^i)2
没办法直接求出来那就一点点试,仍以式2为例,梯度下降公式3如下:
w = w − η ⋅ ∂ L ( w , b ) ∂ w b = b − η ⋅ ∂ L ( w , b ) ∂ b w = w - \eta \cdot \frac{\partial L(w,b)}{\partial w}\\ b = b - \eta \cdot \frac{\partial L(w,b)}{\partial b} w=w−η⋅∂w∂L(w,b)b=b−η⋅∂b∂L(w,b)
公式表现:所有样本点损失进行MSE作为损失函数进行BP。
θ : = θ − η ⋅ 1 N ∑ i = 1 N ∇ θ L ( f ( x i ; θ ) , y i ) \theta := \theta - \eta \cdot \frac{1}{N} \sum_{i=1}^{N} \nabla_\theta L(f(x_i;\theta), y_i) θ:=θ−η⋅N1i=1∑N∇θL(f(xi;θ),yi)
公式表现:每个样本点单独计算损失作为损失函数进行BP。
θ : = θ − η ⋅ ∇ θ L ( f ( x i ; θ ) , y i ) , i = 1 , 2 , ... , N \theta := \theta - \eta \cdot \nabla_\theta L(f(x_i;\theta), y_i), \quad i = 1,2,\ldots,N θ:=θ−η⋅∇θL(f(xi;θ),yi),i=1,2,...,N
代码表现:
python复制代码
# Stochastic Gradient Descent
for epoch in range(num_epochs):
for i in range(N): # N为样本数
x_i, y_i = X[i], y_true[i]
y_pred = model(x_i) # 单样本前向传播
loss = loss_fn(y_pred, y_i)
grad = compute_gradients(loss, model)
model.parameters -= lr * grad # 每个样本都更新一次
公式表现:
θ : = θ − η ⋅ 1 m ∑ j = 1 m ∇ θ L ( f ( x j ; θ ) , y j ) , ( x j , y j ) ∈ Batch k \theta := \theta - \eta \cdot \frac{1}{m} \sum_{j=1}^{m} \nabla_\theta L(f(x_j;\theta), y_j), \quad (x_j, y_j) \in \text{Batch}_k θ:=θ−η⋅m1j=1∑m∇θL(f(xj;θ),yj),(xj,yj)∈Batchk
代码表现:
python复制代码
# Mini-Batch Gradient Descent
for epoch in range(num_epochs):
for batch_X, batch_y in DataLoader(X, y_true, batch_size):
y_pred = model(batch_X) # 小批量前向传播
loss = loss_fn(y_pred, batch_y)
grad = compute_gradients(loss, model)
model.parameters -= lr * grad # 每个批次更新一次
链式法则的应用:要求"偏导L/偏导w"和"偏导L/偏导W",W是包含w的多项表达式,自然地想到先求后者,然后
∂ L ∂ w = ∂ L ∂ W ⋅ ∂ W ∂ w \frac{\partial L}{\partial w} = \frac{\partial L}{\partial W} \cdot \frac{\partial W}{\partial w} ∂w∂L=∂W∂L⋅∂w∂W
# 3. Construct loss and optimizer
criterion = torch.nn.MSELoss(reduction='sum') #创建对象,调用MSELoss类,设置误差求和而非平均
optimizer = torch.optim.SGD(model.parameters(),lr=0.01) #model.parameters()寻找所有待更新参数
选择损失函数及优化器
根据问题类型选择损失函数,这里为MSE均方误差,优化器通常选择SGD。
Think-Help
损失函数的计算方式没有严格要求,但应注意:++是否取平均等操作会影响学习率的选择++ ,因为求导后1/N仍然存在,如下图:
θ : = θ − η ⋅ 1 N ∑ i = 1 N ∇ θ L ( f ( x i ; θ ) , y i ) \theta := \theta - \eta \cdot \frac{1}{N} \sum_{i=1}^{N} \nabla_\theta L(f(x_i;\theta), y_i) θ:=θ−η⋅N1i=1∑N∇θL(f(xi;θ),yi)
1.4 Train cycle
python复制代码
# 4. Train cycle
for epoch in range(1000):
#前向传播
y_pred = model(x_data)
loss = criterion(y_pred,y_data) #实例化对象
print(epoch,loss.item())
#反向传播
optimizer.zero_grad() #清空上一次计算的梯度(否则梯度会累加)
loss.backward() #自动计算每个参数的梯度
optimizer.step() #更新参数
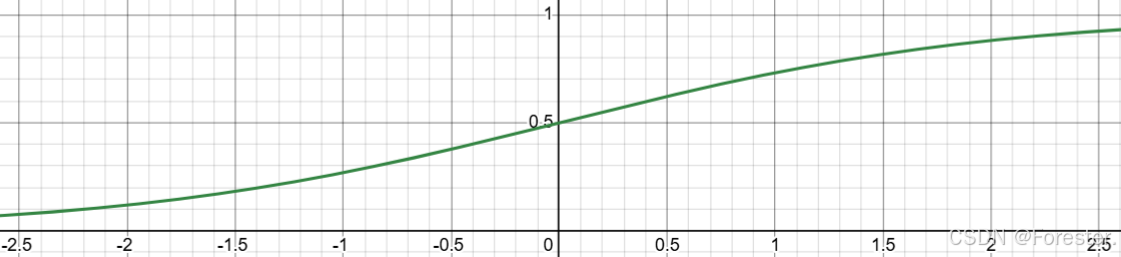
有趣的是,Logistics回归虽然叫回归,但实际是一种二分类方法,简单来说,它相比线性回归只增添了一个Sigmoid函数,将线性回归的输出值代入Sigmoid中实现分类。
σ ( x ) = 1 1 + e − x \sigma(x) = \frac{1}{1 + e^{-x}} σ(x)=1+e−x1
如图所示:
故无论线性回归输出值是什么一定能将其转为(0,1)范围之间,将连续值转化为概率值实现分类。
同时,需要一起变化的还有损失函数,最常用的二分类(y=0/1)损失函数即为BCELoss(Binary Cross Entropy Loss,二元交叉熵损失函数 ),对于单个样本:
L ( y , y ^ ) = − y log ( y \^ ) + ( 1 − y ) log ( 1 − y \^ ) L(y, \hat{y}) = - \left y \\log(\\hat{y}) + (1 - y) \\log(1 - \\hat{y}) \\right L(y,y^)=−ylog(y\^)+(1−y)log(1−y\^)
对于N个样本取平均损失:
BCE Loss = − 1 N ∑ i = 1 N y i log ( y \^ i ) + ( 1 − y i ) log ( 1 − y \^ i ) \text{BCE Loss} = -\frac{1}{N} \sum_{i=1}^{N} \left y_i \\log(\\hat{y}_i) + (1 - y_i) \\log(1 - \\hat{y}_i) \\right BCE Loss=−N1i=1∑Nyilog(y\^i)+(1−yi)log(1−y\^i)
Think-Help
用于记录当前模型输出的概率与真实标签的差距,为什么能做到呢?
首先要明确通常预测y值指的是预测为正类的概率值,即:
y ^ = P ( y = 1 ∣ x ) \hat{y} = P(y = 1 | x) y^=P(y=1∣x)
则:
L = − l o g ( 1 − y ^ ) , y = 0 L = − l o g ( y ^ ) , y = 1 L=-log(1-\hat{y}),y=0\\ L=-log(\hat{y}),y=1 L=−log(1−y^),y=0L=−log(y^),y=1
也就实现了预测正确的概率值越大,损失越小。
2.2 代码实践
在代码中,仅设计模型处多加一个Sigmoid函数,损失函数换为BCELoss即可。
python复制代码
# 1、Design model using Class
class LogisticRegressionModel(torch.nn.Module):
def __init__(self):
super(LogisticRegressionModel, self).__init__()
self.linear = torch.nn.Linear(1,1)
def forward(self, x):
y_pred = torch.sigmoid(self.linear(x)) # 此处加了sigmoid函数,对初始输出值进行sigmoid处理
return y_pred
model = LogisticRegressionModel()
# 2、Construct loss and optimizer
criterion = torch.nn.BCELoss(size_average=False) # Key:是否取均值影响学习率设置:Loss是否乘以1/N------Loss对参数的梯度是否乘以1/N
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
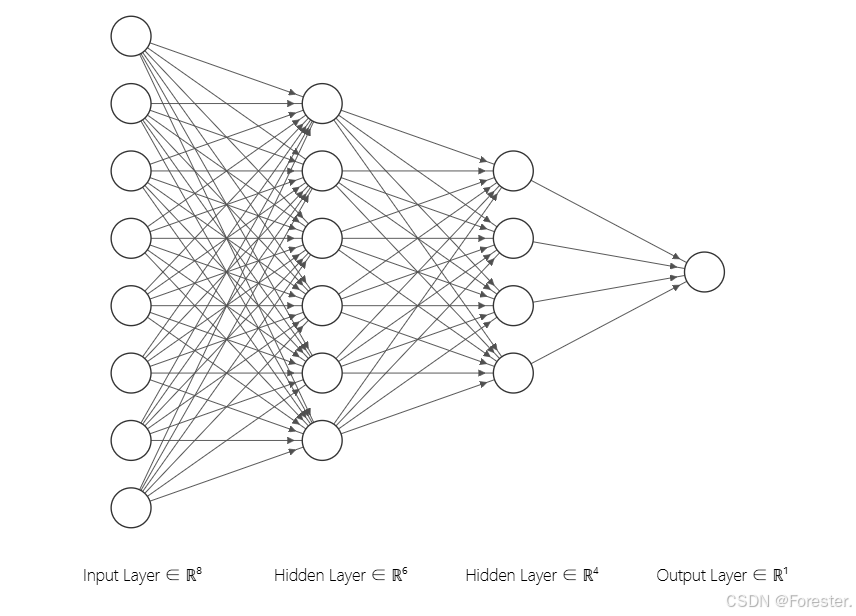
# 2.Design model using class
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model() #实例化
神经网络对应形式(从第一个隐含层开始输入值都要经过激活函数Sigmoid计算):
3.4 Construct loss and optimizer
python复制代码
# 3.Construct loss and optimizer
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 4.Train cycle
if __name__ == '__main__':
for epoch in range(100):
for i,data in enumerate(train_loader, 0):
inputs, labels = data
y_pred = model(inputs)
loss = criterion(y_pred, labels)
print(epoch, i, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
'''
Think-Help
if __name__ == '__main__':当该脚本被直接执行时运行。这里是为了防止trainloader报错。
enumerate返回索引i及数据值data,其中data又分为(inputs,labels)
0指从第0批次开始。
'''
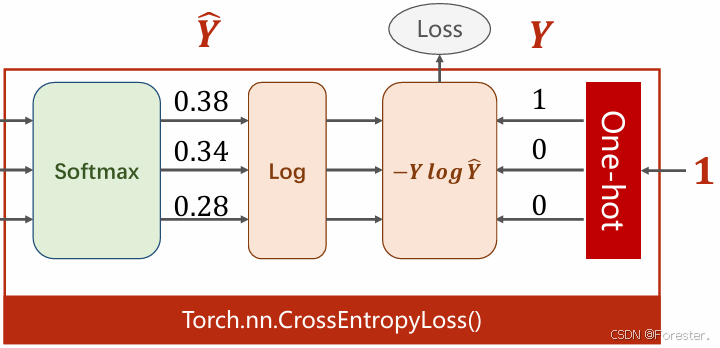
显然,仍将输出值都代入Sigmoid函数无法满足要求,而另一个函数却可以------Softmax函数:
P ( y = i ) = e z i ∑ j = 0 K − 1 e z j , i ∈ { 0 , . . . , K − 1 } P(y = i) = \frac{e^{z_i}}{\sum_{j=0}^{K-1} e^{z_j}}, i \in \{0, ..., K - 1\} P(y=i)=∑j=0K−1ezjezi,i∈{0,...,K−1}
其中z便是输出值,将全部K个值都带入,会得到一个"值都大于0且K个值和为1的分布"。
得到概率值后,如何计算损失呢?
Loss = − log ( y ^ c ) \text{Loss} = -\log(\hat{y}_c) Loss=−log(y^c)
log_probs = F.log_softmax(logits, dim=1)
loss = F.nll_loss(log_probs, target)
不要惊讶,这是因为考虑到数值稳定性(不会出现 exp(大数) 或 log(接近 0) 的溢出问题),要将softmax和log共同进行:
log ( e z i ∑ j e z j ) = z i − log ( ∑ j e z j ) \log\left(\frac{e^{z_i}}{\sum_j e^{z_j}}\right) = z_i - \log\left(\sum_j e^{z_j}\right) log(∑jezjezi)=zi−log(j∑ezj)
而nll_loss实际只起到了取值并取负的操作。
4.2 代码实践
本节实践是经典手写数字图像MNIST数据集,要求识别0-9的多分类问题。
流程仍是四部曲,重点在于使用到了图像识别的专用工具和操作,已在代码中详细注释。
python复制代码
import torch
from torchvision import transforms # 图像预处理
from torchvision import datasets # 图像数据集加载
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
# 1.Prepare dataset
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
'''
ToTensor将图片转为张量,Normalize将其像素值转为[0, 1]区间(标准化)
(0.2307,) 是整个数据集中所有像素的 平均值(mean);
(0.3081,) 是所有像素的 标准差(std);
Because:神经网络更喜欢正态分布数据【加快收敛速度、防止某些特征主导模型、保持激活函数在有效区间工作等】
'''
train_dataset = datasets.MNIST(root='../L_Pytorch/dataset', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../L_Pytorch/dataset', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
# 2.Design model using class
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 784) # 获得batch_size,摊平图片维度
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x)
model = Net()
# 3.Construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5) # 动量使收敛更快、更稳定:每次参数更新时,有 50% 的"惯性"来自上一次的梯度方向。
# 4.Train cycle
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, targets = data
outputs = model(inputs)
loss = criterion(outputs, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299: # 下标从0开始
print(f"[{epoch+1}, {batch_idx+1:5d}] loss: {running_loss/300:.3f}")
running_loss = 0
def test():
correct = 0
total = 0
with torch.no_grad(): # 测试无需更新参数,故不用计算梯度
for data in test_loader:
images, labels = data
outputs = model(images)
_, prediction = torch.max(outputs.data, dim=1)
'''
Think-Help
torch.max(tensor, dim=1):在指定维度 dim=1 上求最大值。
返回两个结果: 第一维是最大值;第二维是最大值所在的位置(索引 index)。
我们取概率值最大的类别索引,只关心类别索引而不关心概率值。
'''
total += labels.size(0) # labels是长度为size的一维张量,每次加上当前批次(batch)的样本数量
correct += (prediction == labels).sum().item()
print(f'Accuracy: {correct/total}')
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
ReLU (Rectified Linear Unit)是目前 CNN 中最常用的激活函数:
f ( x ) = m a x ( 0 , x ) f(x)=max(0,x) f(x)=max(0,x)
原因:计算简单、收敛更快、不容易梯度消失。
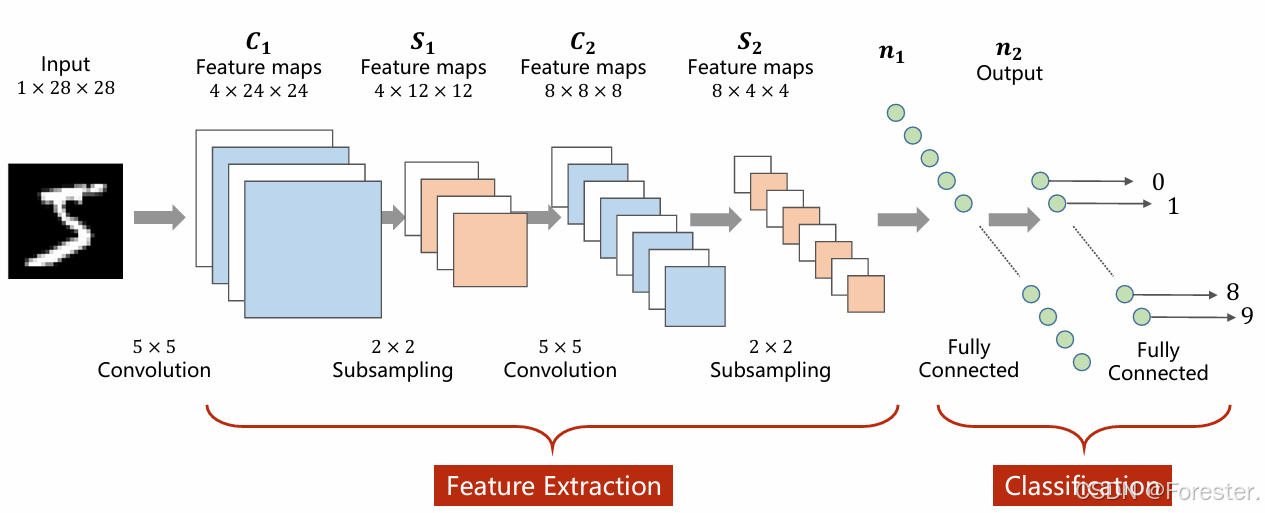
1.5 全连接层(Fully Connected Layer,FC Layer)
"卷积层是特征提取器,全连接层是分类器。"
保留特征图(Feature maps)形式,是没有办法判断最终类别滴,仍然需要"展平"(Flatten),将其变为一维向量,便于建立类别映射(如下),计算输出概率值。
y j = f ( ∑ i w i j x i + b j ) y_j = f\left( \sum_i w_{ij} x_i + b_j \right) yj=f(i∑wijxi+bj)
二、深入CNN
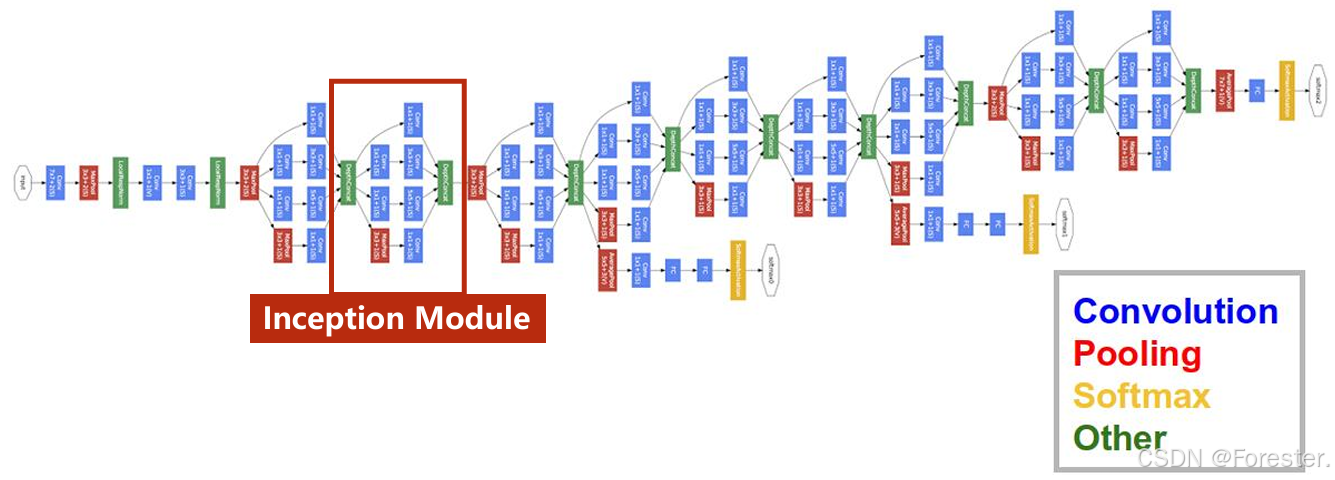
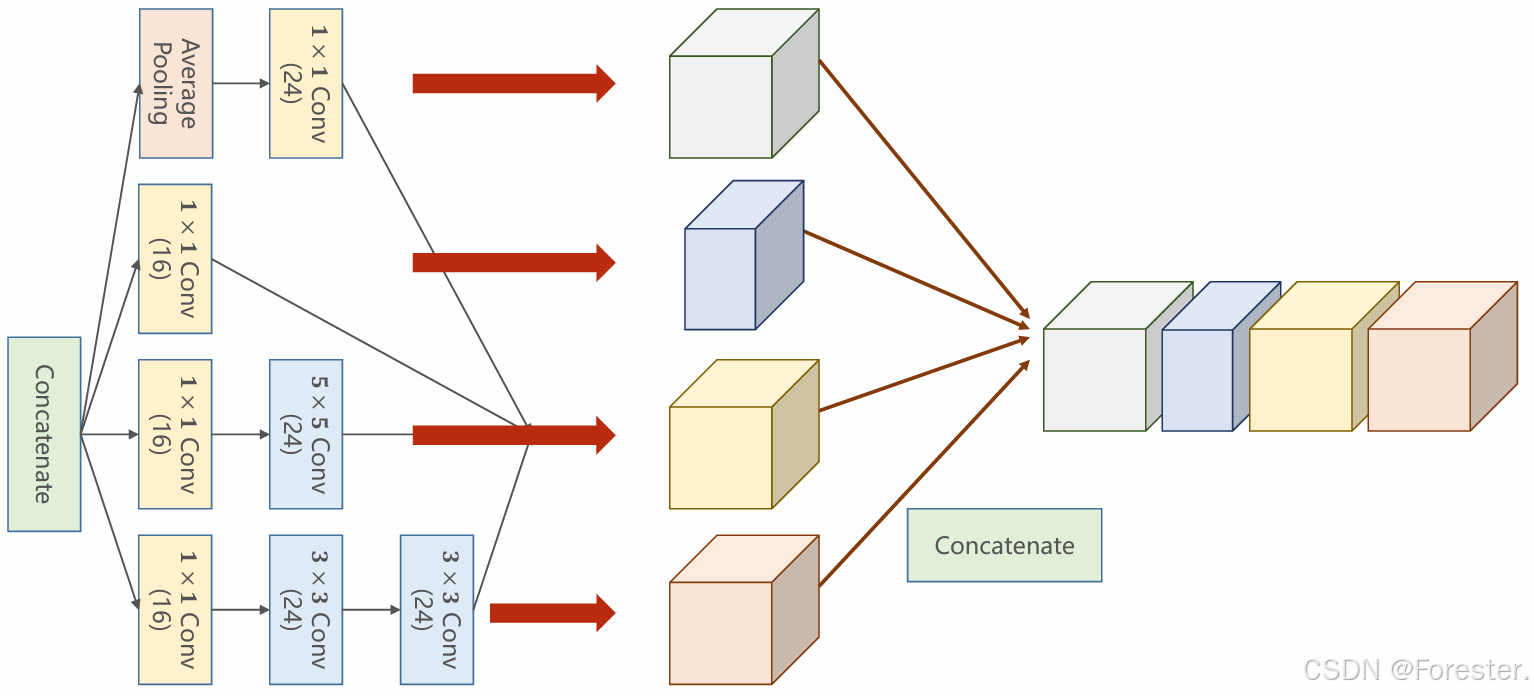
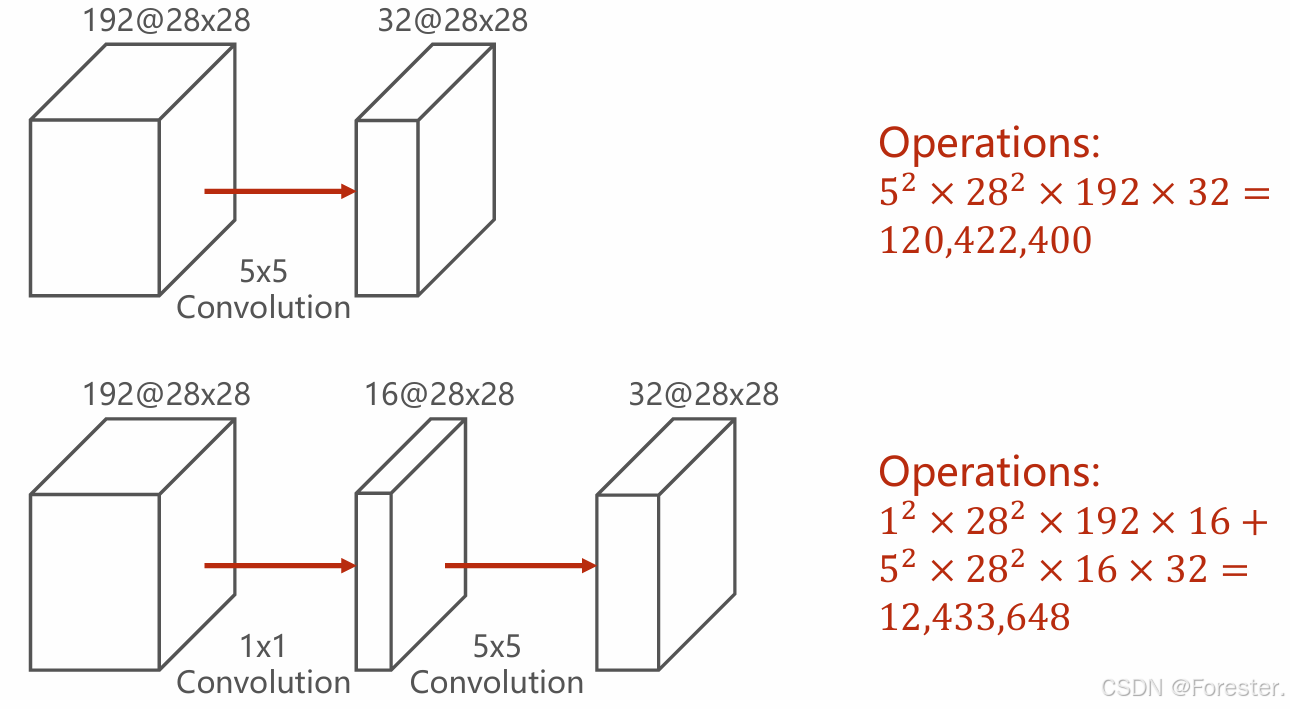
2.1 Inception Block
在学习完卷积神经网络常见的层次结构后,我们同样需要将其"组装"起来,以往我们学习到的神经网络设计模式都是线性,也就是将层次顺序链接起来,但实际应用中,往往需要功能更为复杂的设计模式,如下图(出自论文 《Going Deeper with Convolutions》,即 GoogLeNet ,这是 Google 在 2014 年提出的经典结构)。
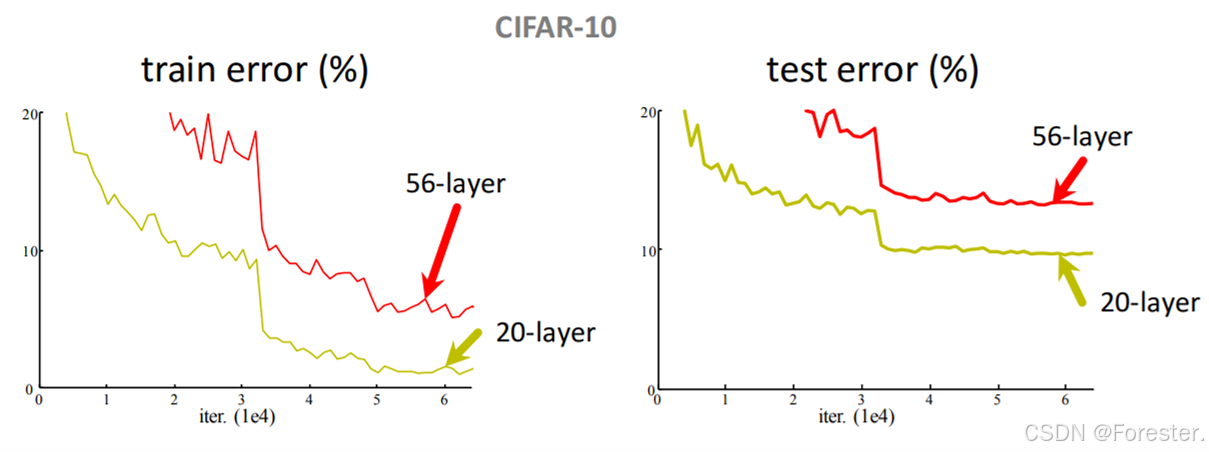
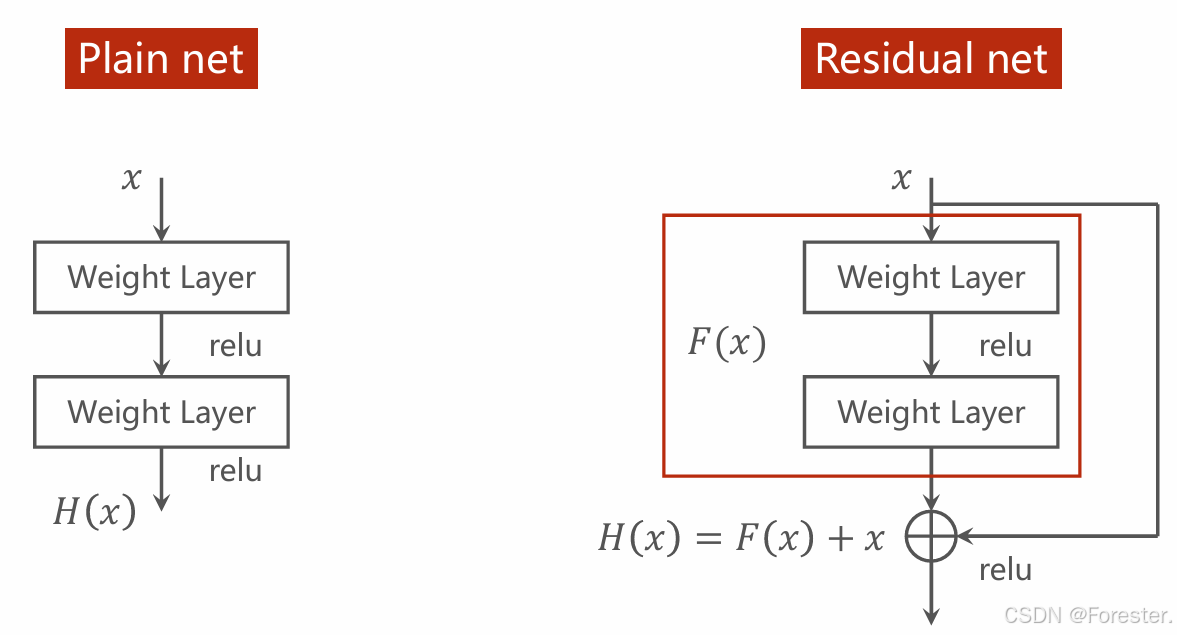
ResNet提出了一种新思想:让网络学习"残差"而不是直接学习映射 。残差定义为:
F ( x ) = H ( x ) − x F(x)=H(x)−x F(x)=H(x)−x
++这里的"残差"不同于损失函数中的残差++,因为它是映射函数输出减去输入而非真实y值,事实上我们也没法减去真实y值,ResNet在中间层而非输出层。
映射函数便为:
H ( x ) = F ( x ) + x H(x)=F(x)+x H(x)=F(x)+x
这样做为什么可以解决梯度消失问题?
很容易理解------ResNet结构中求梯度时绝对值永远大于等于1:
∂ H ( x ) ∂ x = ∂ F ( x ) ∂ x + 1 \frac{\partial H(x)}{\partial x}=\frac{\partial F(x)}{\partial x} +1 ∂x∂H(x)=∂x∂F(x)+1
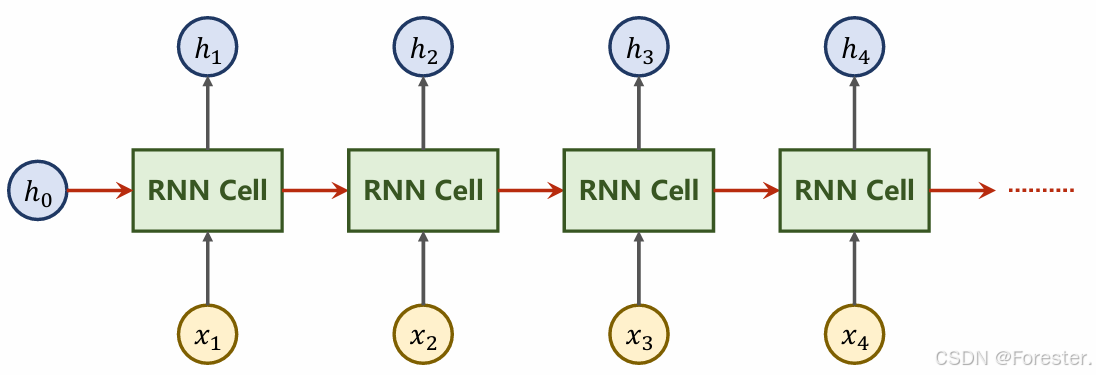
***初步理解:***相对于BP,BPTT中损失对参数的梯度求解时多考虑了"时间"因素。
∂ L ∂ W h h = ∑ t = 1 T ∂ L ∂ h t ⋅ ∂ h t ∂ W h h \frac{\partial L}{\partial W_{hh}} = \sum_{t=1}^{T} \frac{\partial L}{\partial h_t} \cdot \frac{\partial h_t}{\partial W_{hh}} ∂Whh∂L=t=1∑T∂ht∂L⋅∂Whh∂ht
那就需要再加上一个损失函数对W_hh的导数:
∂ L ∂ W h h = ∂ L ∂ h 3 ⋅ ∂ h 3 ∂ h 2 ⋅ ∂ h 2 ∂ h 1 ⋅ ∂ h 1 ∂ W h h \frac{\partial L}{\partial W_{hh}} \; = \frac{\partial L}{\partial h_3} \cdot \frac{\partial h_3}{\partial h_2} \cdot \frac{\partial h_2}{\partial h_1} \cdot \frac{\partial h_1}{\partial W_{hh}} ∂Whh∂L=∂h3∂L⋅∂h2∂h3⋅∂h1∂h2⋅∂Whh∂h1
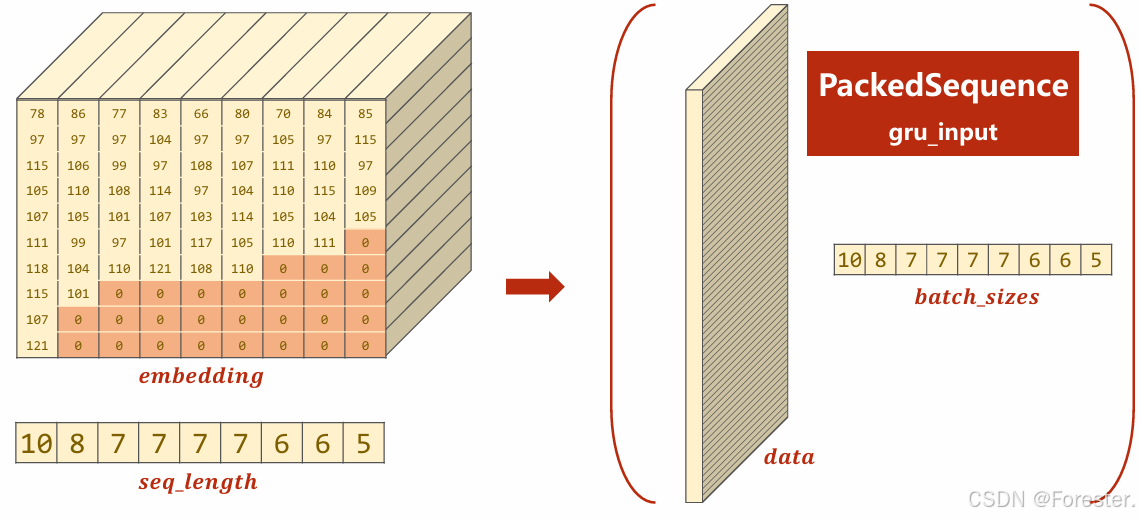
该隐藏层输出为:
h i d d e n = h N f , h N b hidden=h_N\^f,h_N\^b hidden=hNf,hNb
5.3 GRU
5.3.1 GRU的提出
对于RNN,BPTT时很容易导致梯度消失或爆炸,使模型难以记住长序列信息。
Think-Help
++RNN的特殊问题++
我们先回顾一下梯度消失和爆炸两种情况:
在所有神经网络中,反向传播的梯度更新都要用链式法则:
∂ L ∂ W = ∂ L ∂ h n ⋅ ∂ h n ∂ h n − 1 ⋅ ∂ h n − 1 ∂ h n − 2 ⋅ ... ⋅ ∂ h 1 ∂ W \frac{\partial L}{\partial W} = \frac{\partial L}{\partial h_n} \cdot \frac{\partial h_n}{\partial h_{n-1}} \cdot \frac{\partial h_{n-1}}{\partial h_{n-2}} \cdot \ldots \cdot \frac{\partial h_1}{\partial W} ∂W∂L=∂hn∂L⋅∂hn−1∂hn⋅∂hn−2∂hn−1⋅...⋅∂W∂h1
例如一个长度为 100 的序列,RNN 展开后就是 100 层的"共享权重网络":
h t = f ( W h h h t − 1 + W x h x t ) h_t = f(W_{hh}h_{t-1} + W_{xh}x_t) ht=f(Whhht−1+Wxhxt)
反向传播时梯度链路是:
∂ L ∂ W h h ∝ ∏ t = 1 T ∂ h t ∂ h t − 1 \frac{\partial L}{\partial W_{hh}} \propto \prod_{t=1}^{T} \frac{\partial h_t}{\partial h_{t-1}} ∂Whh∂L∝t=1∏T∂ht−1∂ht
于是人们提出了改进版 ------ GRU(门控循环单元)【Gated Recurrent Unit = 有门的循环单元】
首先给定完整公式:
z t = σ ( W z x t + U z h t − 1 ) 更新门 r t = σ ( W r x t + U r h t − 1 ) 重置门 h ~ t = tanh ( W h x t + U h ( r t ⊙ h t − 1 ) ) 候选新状态 h t = ( 1 − z t ) ⊙ h t − 1 + z t ⊙ h ~ t 最终输出 \begin{aligned} z_t &= \sigma(W_z x_t + U_z h_{t-1}) && \text{更新门} \\ r_t &= \sigma(W_r x_t + U_r h_{t-1}) && \text{重置门} \\ \tilde{h}t &= \tanh(W_h x_t + U_h (r_t \odot h{t-1})) && \text{候选新状态} \\ h_t &= (1 - z_t) \odot h_{t-1} + z_t \odot \tilde{h}_t && \text{最终输出} \end{aligned} ztrth~tht=σ(Wzxt+Uzht−1)=σ(Wrxt+Urht−1)=tanh(Whxt+Uh(rt⊙ht−1))=(1−zt)⊙ht−1+zt⊙h~t更新门重置门候选新状态最终输出
 🤸♂️生活座右铭:勤而拂拭,莫染尘埃。 📚学习座右铭:一切烦恼来源于定义不清。 🙌留言:有任何问题欢迎交流学习,直接私信即可,一定会回!👌
🤸♂️生活座右铭:勤而拂拭,莫染尘埃。 📚学习座右铭:一切烦恼来源于定义不清。 🙌留言:有任何问题欢迎交流学习,直接私信即可,一定会回!👌