针对analysis-ik我就不具体介绍了,我个人主要认为它的有点有:
1.java开发,方便修改源码(比如文件内容加密,或者其他特定的分词处理)
2.中文分词效果比较好
3.配置文件响相对于简单
ik下载地址:
https://release.infinilabs.com/analysis-ik/stable/
网上很多让你在服务器上下载或者定位到githup上的我觉得都不太好,不够清晰
上面收录了各个版本es对应的ik分词器版本,特别注意
*******es版本要严格对应ik版本********
比如es为6.3.2那么ik也要下载6.3.2
源码地址
https://github.com/infinilabs/analysis-ik/tree/6.x?tab=readme-ov-file#versions
因为es之前 已经用了一个ik插件修改了一些源码进行了一些加密等等的处理,但是现在想要保持上一个ik插件的特性的情况下,在用一个正常的ik插件,所以需要将第二个ik插件更改名称防止两个插件发生冲突。
1.需要修改源码箭头部分改为自己ik插件的名字:
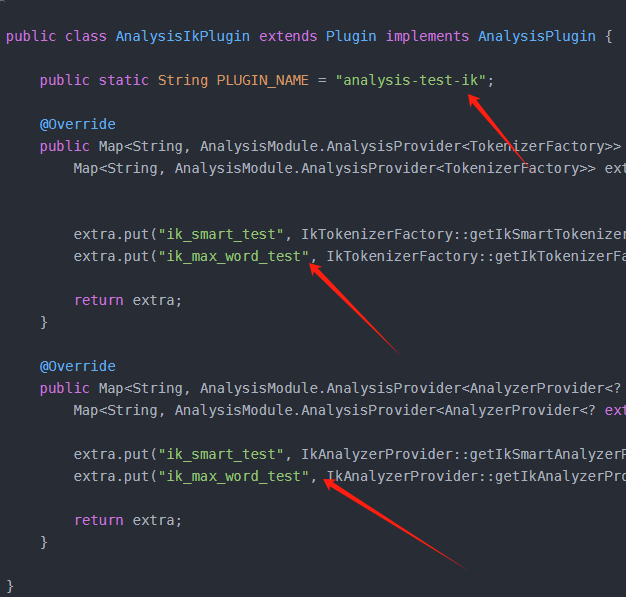
java
public class AnalysisIkPlugin extends Plugin implements AnalysisPlugin {
public static String PLUGIN_NAME = "analysis-test-ik";
@Override
public Map<String, AnalysisModule.AnalysisProvider<TokenizerFactory>> getTokenizers() {
Map<String, AnalysisModule.AnalysisProvider<TokenizerFactory>> extra = new HashMap<>();
extra.put("ik_smart_test", IkTokenizerFactory::getIkSmartTokenizerFactory);
extra.put("ik_max_word_test", IkTokenizerFactory::getIkTokenizerFactory);
return extra;
}
@Override
public Map<String, AnalysisModule.AnalysisProvider<AnalyzerProvider<? extends Analyzer>>> getAnalyzers() {
Map<String, AnalysisModule.AnalysisProvider<AnalyzerProvider<? extends Analyzer>>> extra = new HashMap<>();
extra.put("ik_smart_test", IkAnalyzerProvider::getIkSmartAnalyzerProvider);
extra.put("ik_max_word_test", IkAnalyzerProvider::getIkAnalyzerProvider);
return extra;
}
}2.修改pom文件(改为自己的名称)
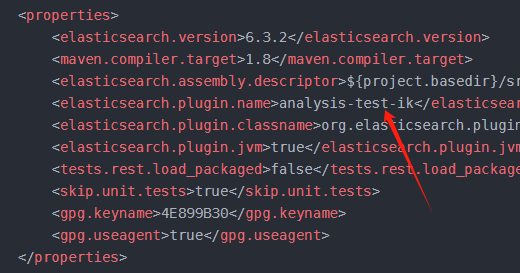
XML
<properties>
<elasticsearch.version>6.3.2</elasticsearch.version>
<maven.compiler.target>1.8</maven.compiler.target>
<elasticsearch.assembly.descriptor>${project.basedir}/src/main/assemblies/plugin.xml</elasticsearch.assembly.descriptor>
<elasticsearch.plugin.name>analysis-test-ik</elasticsearch.plugin.name>
<elasticsearch.plugin.classname>org.elasticsearch.plugin.analysis.ik.AnalysisIkPlugin</elasticsearch.plugin.classname>
<elasticsearch.plugin.jvm>true</elasticsearch.plugin.jvm>
<tests.rest.load_packaged>false</tests.rest.load_packaged>
<skip.unit.tests>true</skip.unit.tests>
<gpg.keyname>4E899B30</gpg.keyname>
<gpg.useagent>true</gpg.useagent>
</properties>然后在es的plugins/按照不同名称把两个ik放在不同名字的目录下,通过不同的分词方法,调用两个不同的ik分词器。