文章目录
一、论文信息
- 论文题目:Run, Don't Walk: Chasing Higher FLOPS for Faster Neural Networks
- 中文题目:奔跑而非行走:追求更高FLOPS以实现更快神经网络
- 论文链接:点击跳转
- 代码链接:点击跳转
- 作者:Jierun Chen (中文名:陈洁润),香港科技大学(HKUST)、Shiu-hong Kao (高诗鸿),香港科技大学(HKUST)、Hao He (何豪),香港科技大学(HKUST)、Weipeng Zhuo (卓伟鹏),香港科技大学(HKUST)\Song Wen (温松),罗格斯大学(Rutgers University)、Chul-Ho Lee (李哲昊),德州州立大学(Texas State University)、S.-H. Gary Chan (陈绍豪),香港科技大学(HKUST)
- 单位: 香港科技大学(HKUST)、罗格斯大学、德克萨斯州立大学
- 核心速览:提出一种新型部分卷积(PConv)和FasterNet架构,在减少FLOPs的同时提升FLOPS,实现更快的推理速度。
二、论文概要
本文指出当前轻量级神经网络虽然FLOPs低,但由于内存访问频繁导致FLOPS(每秒浮点运算次数)不高,实际延迟并未显著降低。作者提出部分卷积(PConv),仅对部分通道进行卷积,减少计算和内存访问,并基于此构建FasterNet,在多个视觉任务上实现速度与精度的最优平衡。
三、实验动机
-
现有轻量网络(如MobileNet、ShuffleNet)虽FLOPs低,但FLOPS也低,导致实际延迟高。
-
深度可分离卷积(DWConv)等操作内存访问频繁,成为速度瓶颈。
-
目标:在减少FLOPs的同时保持高FLOPS,实现真正的高速度。
两个概念:FLOPS和FLOPs(s一个大写一个小写)
FLOPS: FLoating point Operations Per Second的缩写,即每秒浮点运算次数,或表示为计算速度。是一个衡量硬件性能的指标。
FLOPs: FLoating point OPerationS 即 浮点计算次数,包含乘法和加法,只和模型有关,可以用来衡量其复杂度。
总结起来,S大写的是计算速度,小写的是计算量。计算量 / 计算速度 = 计算时间Latency
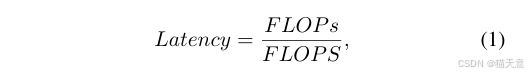
四、创新之处
-
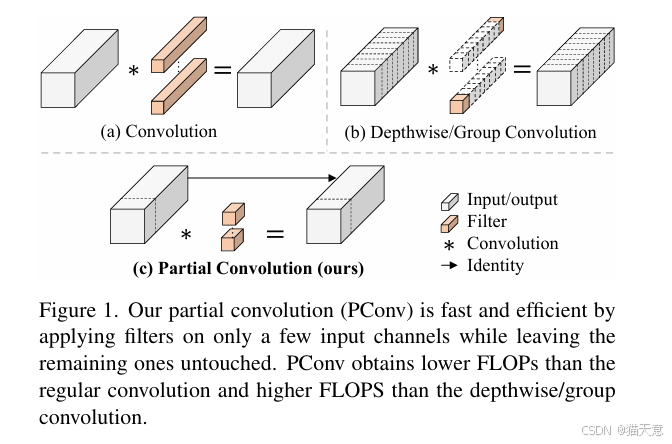
提出PConv:仅对连续的一部分通道进行卷积,其余通道保留,大幅减少计算和内存访问。
-
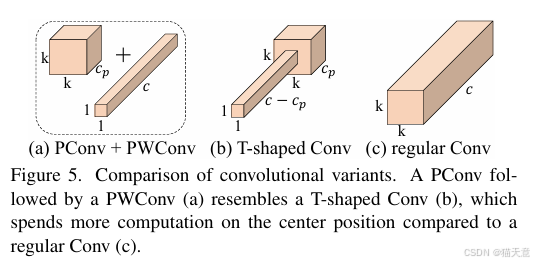
T型感受野:PConv + PWConv 组合形成T型卷积,更关注中心位置,与常规卷积近似。
-
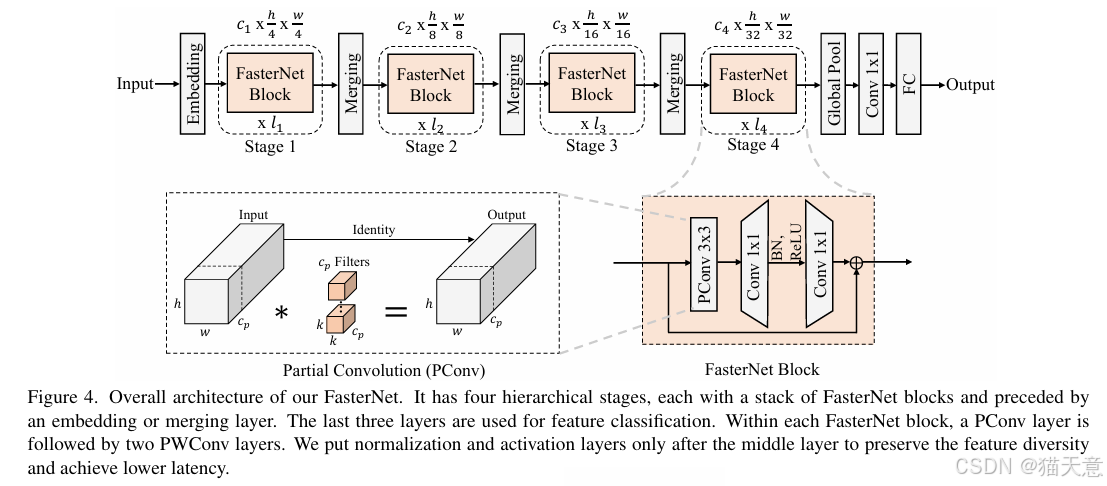
FasterNet架构:基于PConv构建,结构简洁,硬件友好,在多个设备上(GPU/CPU/ARM)均表现优异。

五、实验分析
-
PConv速度对比:在相同FLOPs下,PConv的FLOPS显著高于DWConv和GConv。
-
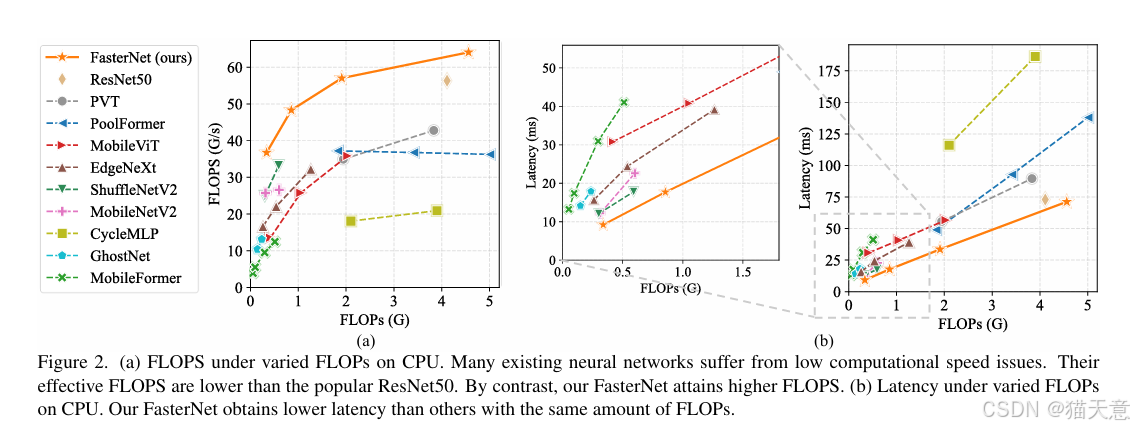
ImageNet分类:FasterNet在相同精度下延迟更低,吞吐量更高。
-
下游任务(检测/分割):在COCO数据集上,FasterNet作为Backbone显著提升检测与分割性能。
-
消融实验:验证了部分比例 r=1/4 最优,BN比LN更高效,不同规模模型适用不同激活函数。
六、核心代码
py
class Partial_conv3(nn.Module):
def __init__(self, dim, n_div, forward):
super().__init__()
self.dim_conv3 = dim // n_div
self.dim_untouched = dim - self.dim_conv3
self.partial_conv3 = nn.Conv2d(self.dim_conv3, self.dim_conv3, 3, 1, 1, bias=False)
if forward == 'slicing':
self.forward = self.forward_slicing
elif forward == 'split_cat':
self.forward = self.forward_split_cat
else:
raise NotImplementedError
def forward_slicing(self, x: Tensor) -> Tensor:
# only for inference
x = x.clone() # !!! Keep the original input intact for the residual connection later
x[:, :self.dim_conv3, :, :] = self.partial_conv3(x[:, :self.dim_conv3, :, :])
return x
def forward_split_cat(self, x: Tensor) -> Tensor:
# for training/inference
x1, x2 = torch.split(x, [self.dim_conv3, self.dim_untouched], dim=1)
x1 = self.partial_conv3(x1)
x = torch.cat((x1, x2), 1)
return x注释版本
py
class Partial_conv3(nn.Module):
def __init__(self, dim, n_div, forward):
super().__init__()
self.dim_conv3 = dim // n_div # 计算要进行3x3卷积的通道数
self.dim_untouched = dim - self.dim_conv3 # 计算保持不变的通道数
self.partial_conv3 = nn.Conv2d(self.dim_conv3, self.dim_conv3, 3, 1, 1, bias=False) # 定义3x3卷积
# 根据forward参数选择前向传播的实现方式 两个函数实质上是等价的操作,只是实现方式不同而已。
if forward == 'slicing':
self.forward = self.forward_slicing
elif forward == 'split_cat':
self.forward = self.forward_split_cat
else:
raise NotImplementedError
def forward_slicing(self, x: Tensor) -> Tensor:
# 仅用于推理的切片方法
x = x.clone() # 克隆输入以保持原始输入不变(为了后续残差连接)
# 只对前dim_conv3个通道进行卷积操作
x[:, :self.dim_conv3, :, :] = self.partial_conv3(x[:, :self.dim_conv3, :, :])
return x
def forward_split_cat(self, x: Tensor) -> Tensor:
# 用于训练/推理的分割-连接方法
# 将输入分割为两部分:要进行卷积的部分和保持不变的部分
x1, x2 = torch.split(x, [self.dim_conv3, self.dim_untouched], dim=1)
x1 = self.partial_conv3(x1) # 对第一部分进行卷积
x = torch.cat((x1, x2), 1) # 将两部分重新连接
return x七、实验总结
-
PConv 在减少FLOPs的同时显著提升FLOPS,是替代DWConv的高效选择。
-
FasterNet 在ImageNet、COCO等任务上实现SOTA速度-精度权衡。
-
方法简洁、通用性强,适用于多种硬件平台。