✨作者主页 :IT毕设梦工厂✨
个人简介:曾从事计算机专业培训教学,擅长Java、Python、PHP、.NET、Node.js、GO、微信小程序、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。
文章目录
一、前言
系统介绍
基于大数据的国家医用消耗选品采集数据可视化分析系统是一套面向医疗器械集中采购领域的智能化分析平台。系统采用Hadoop+Spark大数据处理框架作为核心技术架构,支持海量医用耗材数据的高效存储与实时计算。后端采用Django/Spring Boot技术栈实现,前端基于Vue+ElementUI+Echarts构建响应式可视化界面,能够对国家医用耗材集采数据进行全方位深度挖掘。系统整合了产品特性分析、价格多维度对比、市场竞争格局研判、关键产品领域专题分析等功能模块,通过Spark SQL进行复杂查询处理,结合Pandas和NumPy进行数据清洗与统计分析。平台提供直观的数据可视化大屏展示,支持产品分类构成、注册年份趋势、材质应用分布、企业竞争态势等多维度图表呈现,为医疗机构采购决策、监管部门政策制定、生产企业市场策略提供科学的数据支撑和决策参考。
选题背景
随着医疗卫生事业发展和人口老龄化趋势加剧,医用耗材作为医疗服务的重要组成部分,其需求量持续增长。国家推行医用耗材集中带量采购政策以来,通过建立统一的采购平台,规范市场秩序,降低耗材价格,减轻患者负担。然而,面对种类繁多、规格复杂的医用耗材产品,传统的人工分析方式已难以应对海量数据处理需求。集采过程中涉及的产品信息、价格数据、企业资质、材质特性等多维度信息呈现爆炸式增长,给采购决策、市场监管、政策制定带来挑战。医疗机构在选品时需要综合考虑产品质量、价格水平、供应稳定性等多重因素,而监管部门需要实时掌握市场竞争态势、价格波动情况、产品技术发展趋势。在这样的背景下,运用大数据技术对医用耗材集采数据进行系统化分析,构建智能化的可视化分析系统,已成为提升集采效率、优化资源配置的迫切需要。
选题意义
本研究通过构建医用耗材集采数据可视化分析系统,在实践层面能够为相关机构和人员提供有益的辅助工具。对于医疗机构而言,系统能够帮助采购人员更好地了解不同产品的价格分布、质量特性和供应商情况,在一定程度上辅助采购决策,提高选品的科学性。对于监管部门来说,平台提供的市场竞争格局分析和价格趋势监测功能,有助于及时发现市场异常波动,为政策调整提供参考依据。从技术角度看,本系统尝试将大数据处理技术应用于医用耗材领域,探索了Hadoop、Spark等技术在医疗数据分析中的应用方式,为同类系统开发提供技术参考。在学术价值方面,本研究梳理了医用耗材数据的特点和分析需求,形成了相对完整的分析框架,丰富了医疗信息化领域的研究内容。虽然作为毕业设计项目,系统规模和复杂度有限,但通过完整的设计和实现过程,锻炼了大数据技术综合运用能力,为今后从事相关工作积累了实践经验。
二、开发环境
- 大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
- 开发语言:Python+Java(两个版本都支持)
- 后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
- 前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
- 详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy
- 数据库:MySQL
三、系统界面展示
- 基于大数据的国家医用消耗选品采集数据可视化分析系统界面展示:

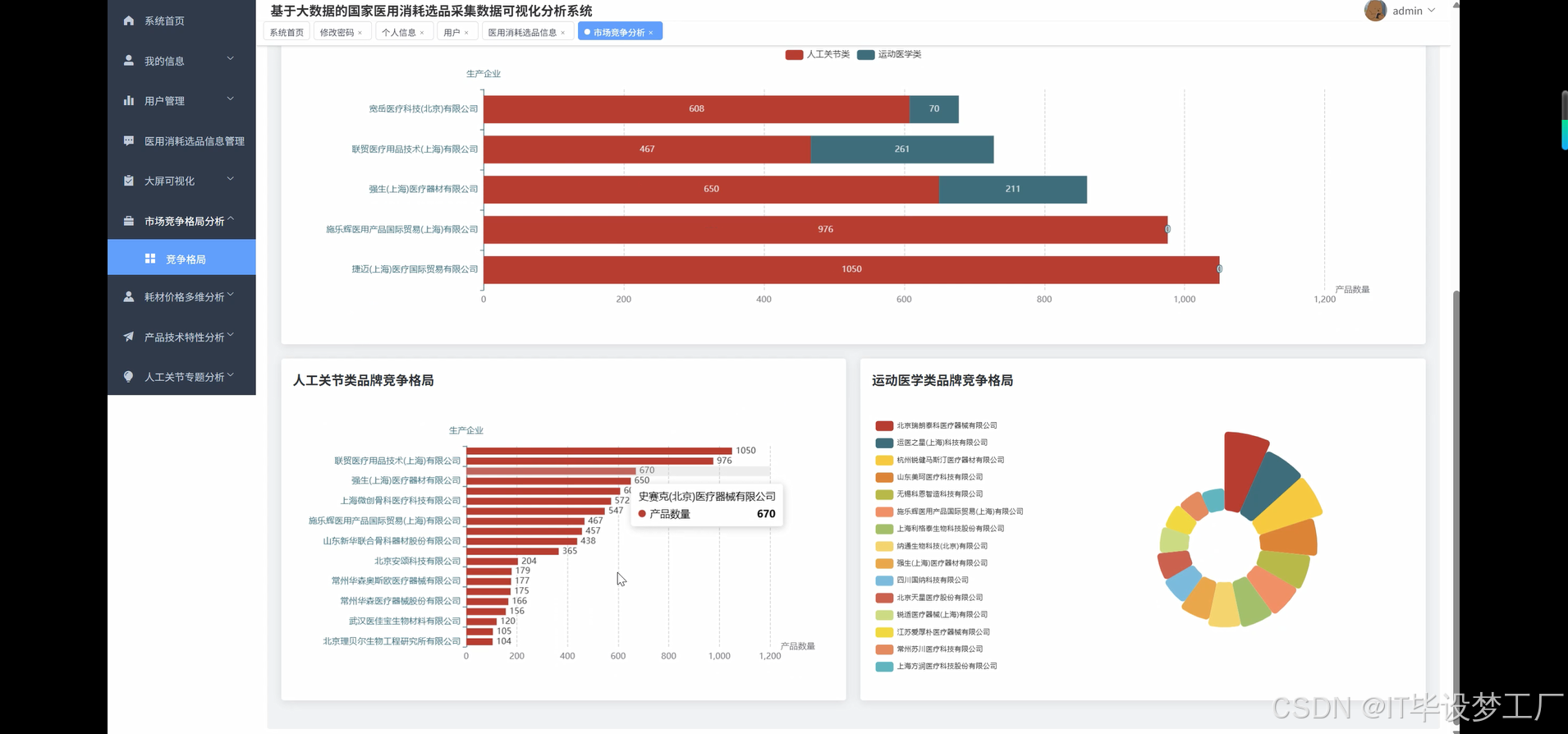
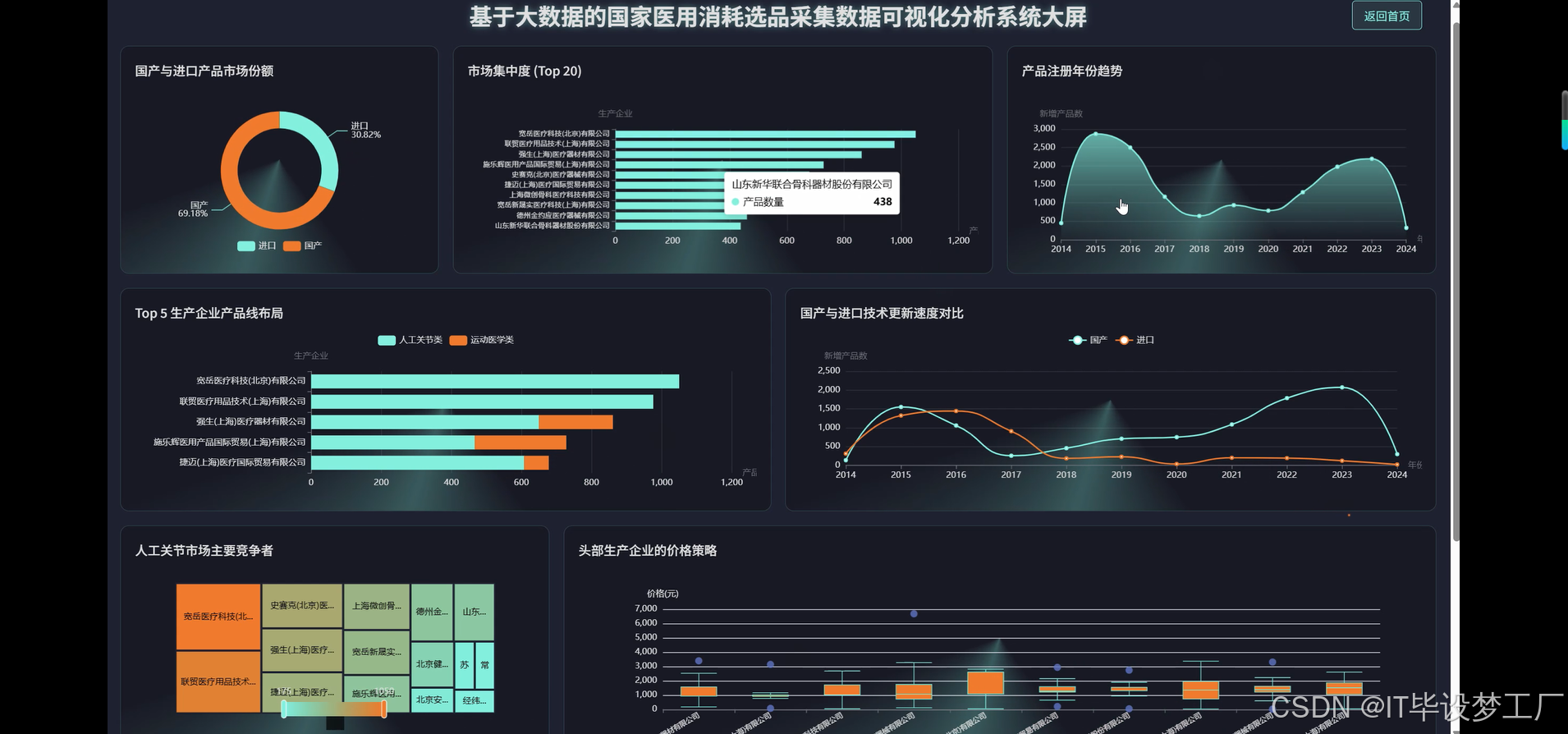
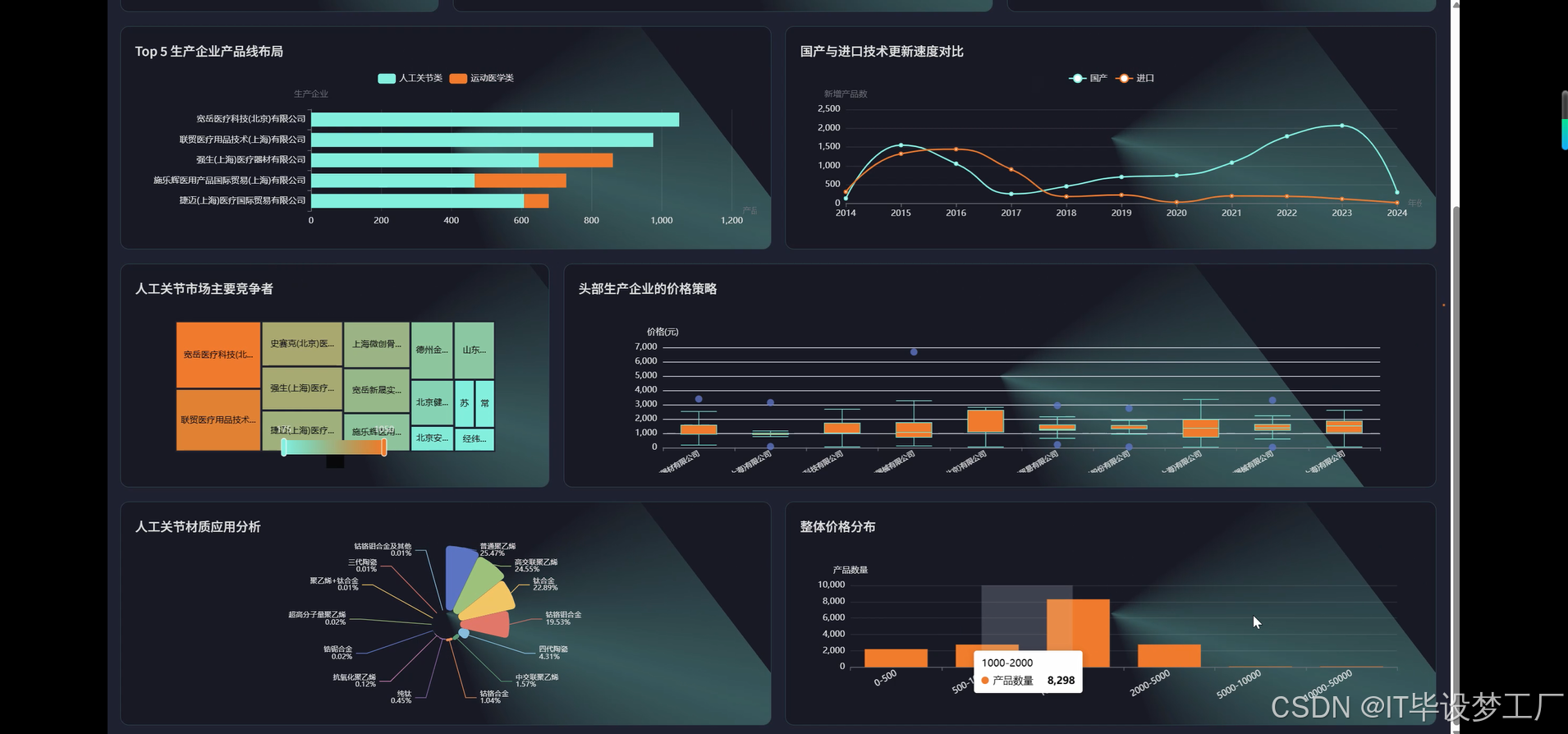
四、部分代码设计
- 项目实战-代码参考:
java(贴上部分代码)
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
import pandas as pd
import numpy as np
spark = SparkSession.builder.appName("MedicalSupplyAnalysis").config("spark.sql.adaptive.enabled", "true").config("spark.sql.adaptive.coalescePartitions.enabled", "true").getOrCreate()
def price_multi_dimension_analysis(data_path):
df = spark.read.option("header", "true").option("inferSchema", "true").csv(data_path)
df = df.filter(col("价格").isNotNull() & (col("价格") > 0))
df = df.withColumn("产品来源", when(col("注册证编号").rlike("^国械注准"), "国产").otherwise("进口"))
df = df.withColumn("注册年份", regexp_extract(col("注册证编号"), r"(\d{4})", 1).cast("int"))
price_ranges = [(0, 500), (500, 1000), (1000, 2000), (2000, 5000), (5000, 10000), (10000, float('inf'))]
range_conditions = [
(col("价格") >= lower) & (col("价格") < upper) if upper != float('inf')
else (col("价格") >= lower) for lower, upper in price_ranges
]
range_labels = [f"{lower}-{upper}" if upper != float('inf') else f"{lower}+" for lower, upper in price_ranges]
price_distribution = df.select("价格")
for i, condition in enumerate(range_conditions):
count = df.filter(condition).count()
price_distribution = price_distribution.withColumn(f"range_{range_labels[i]}", lit(count))
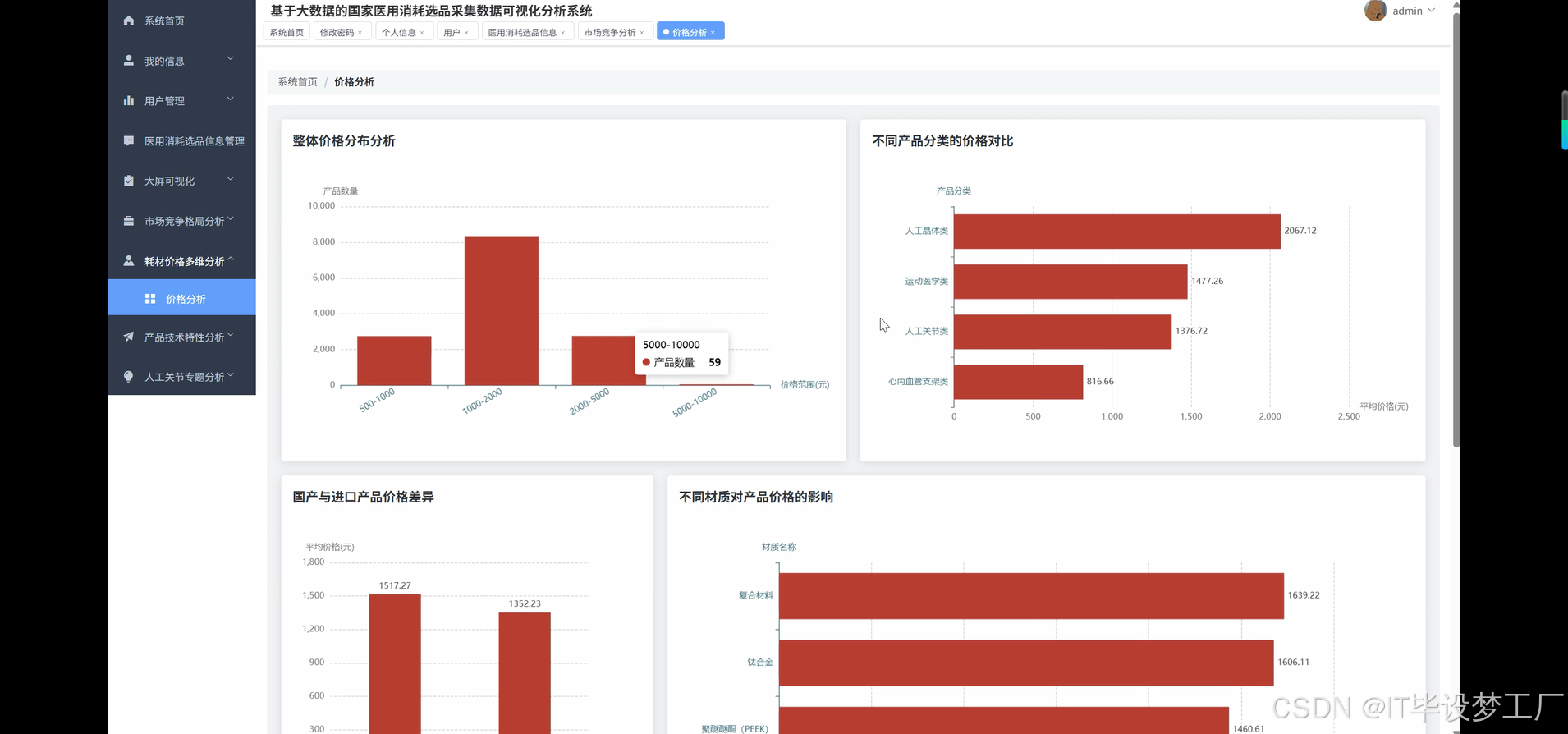
category_price = df.groupBy("产品分类").agg(
avg("价格").alias("平均价格"),
min("价格").alias("最低价格"),
max("价格").alias("最高价格"),
count("*").alias("产品数量")
).orderBy(desc("平均价格"))
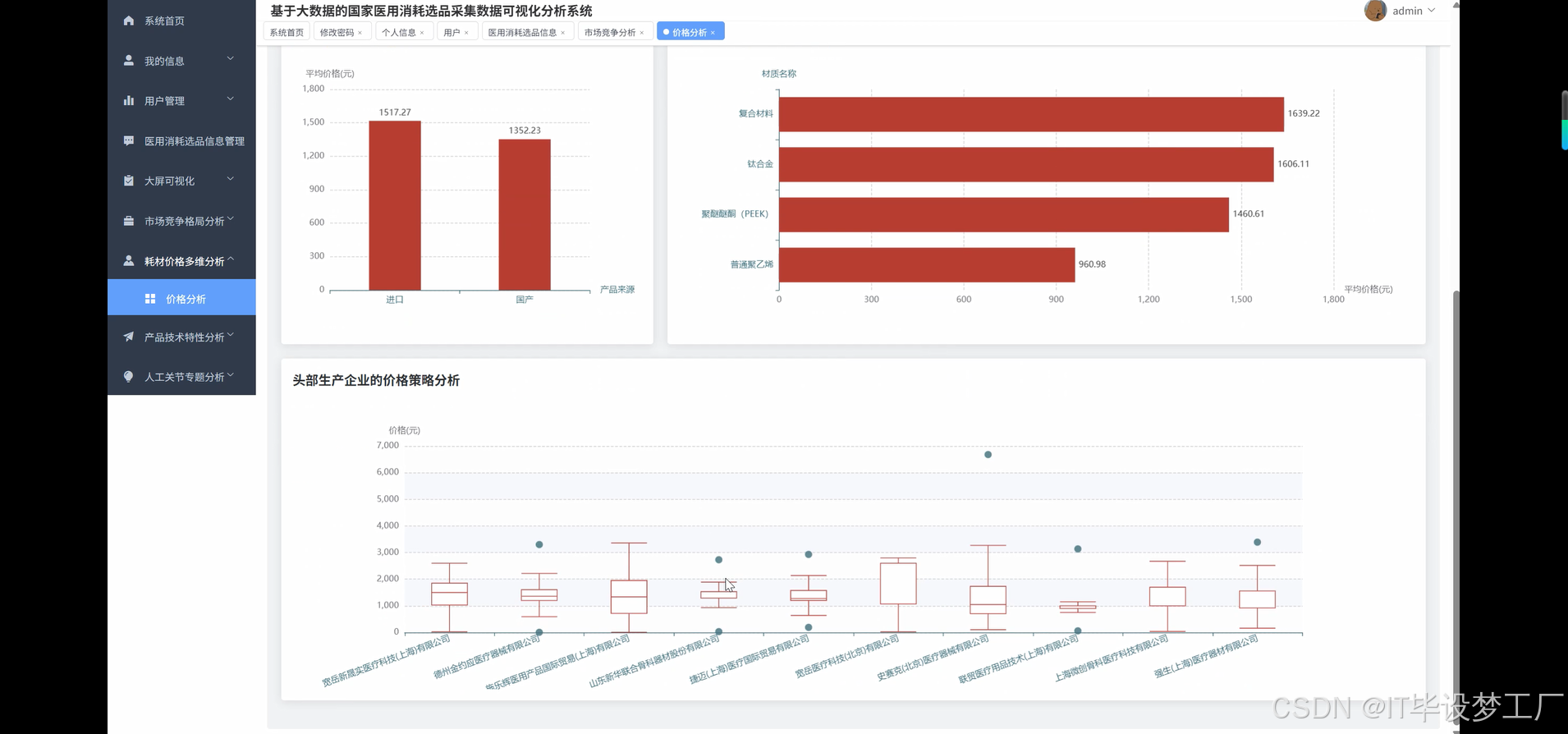
source_price = df.groupBy("产品来源").agg(
avg("价格").alias("平均价格"),
stddev("价格").alias("价格标准差"),
count("*").alias("产品数量")
)
material_price = df.filter(col("材质名称").isNotNull()).groupBy("材质名称").agg(
avg("价格").alias("平均价格"),
count("*").alias("使用数量")
).filter(col("使用数量") >= 5).orderBy(desc("平均价格"))
top_enterprises = df.groupBy("生产企业").agg(count("*").alias("产品数量")).orderBy(desc("产品数量")).limit(10)
enterprise_list = [row["生产企业"] for row in top_enterprises.collect()]
enterprise_prices = df.filter(col("生产企业").isin(enterprise_list)).groupBy("生产企业").agg(
avg("价格").alias("平均价格"),
percentile_approx("价格", 0.25).alias("价格25分位"),
percentile_approx("价格", 0.5).alias("价格中位数"),
percentile_approx("价格", 0.75).alias("价格75分位")
)
return {
"category_price": category_price.toPandas(),
"source_price": source_price.toPandas(),
"material_price": material_price.toPandas(),
"enterprise_prices": enterprise_prices.toPandas()
}
def market_competition_analysis(data_path):
df = spark.read.option("header", "true").option("inferSchema", "true").csv(data_path)
df = df.filter(col("生产企业").isNotNull() & col("产品分类").isNotNull())
df = df.withColumn("产品来源", when(col("注册证编号").rlike("^国械注准"), "国产").otherwise("进口"))
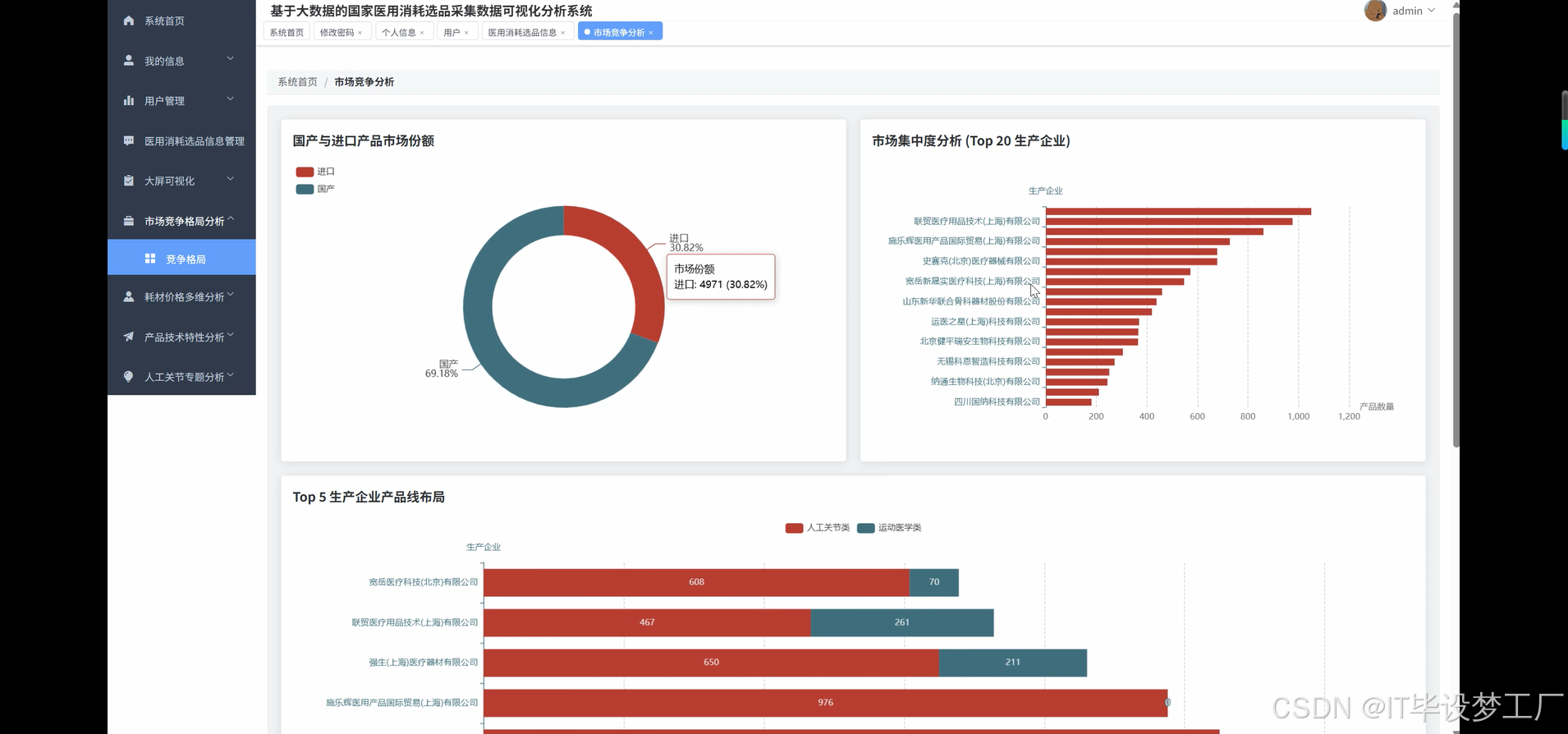
market_concentration = df.groupBy("生产企业").agg(count("*").alias("产品数量")).orderBy(desc("产品数量"))
total_products = df.count()
market_share = market_concentration.withColumn("市场份额", round(col("产品数量") / total_products * 100, 2))
top20_enterprises = market_share.limit(20)
source_distribution = df.groupBy("产品来源").agg(count("*").alias("产品数量"))
total_count = source_distribution.agg(sum("产品数量")).collect()[0][0]
source_ratio = source_distribution.withColumn("占比", round(col("产品数量") / total_count * 100, 2))
top5_enterprises = market_concentration.limit(5)
enterprise_list = [row["生产企业"] for row in top5_enterprises.collect()]
enterprise_category = df.filter(col("生产企业").isin(enterprise_list)).groupBy("生产企业", "产品分类").agg(count("*").alias("产品数量"))
enterprise_layout = enterprise_category.groupBy("生产企业").pivot("产品分类").agg(first("产品数量")).fillna(0)
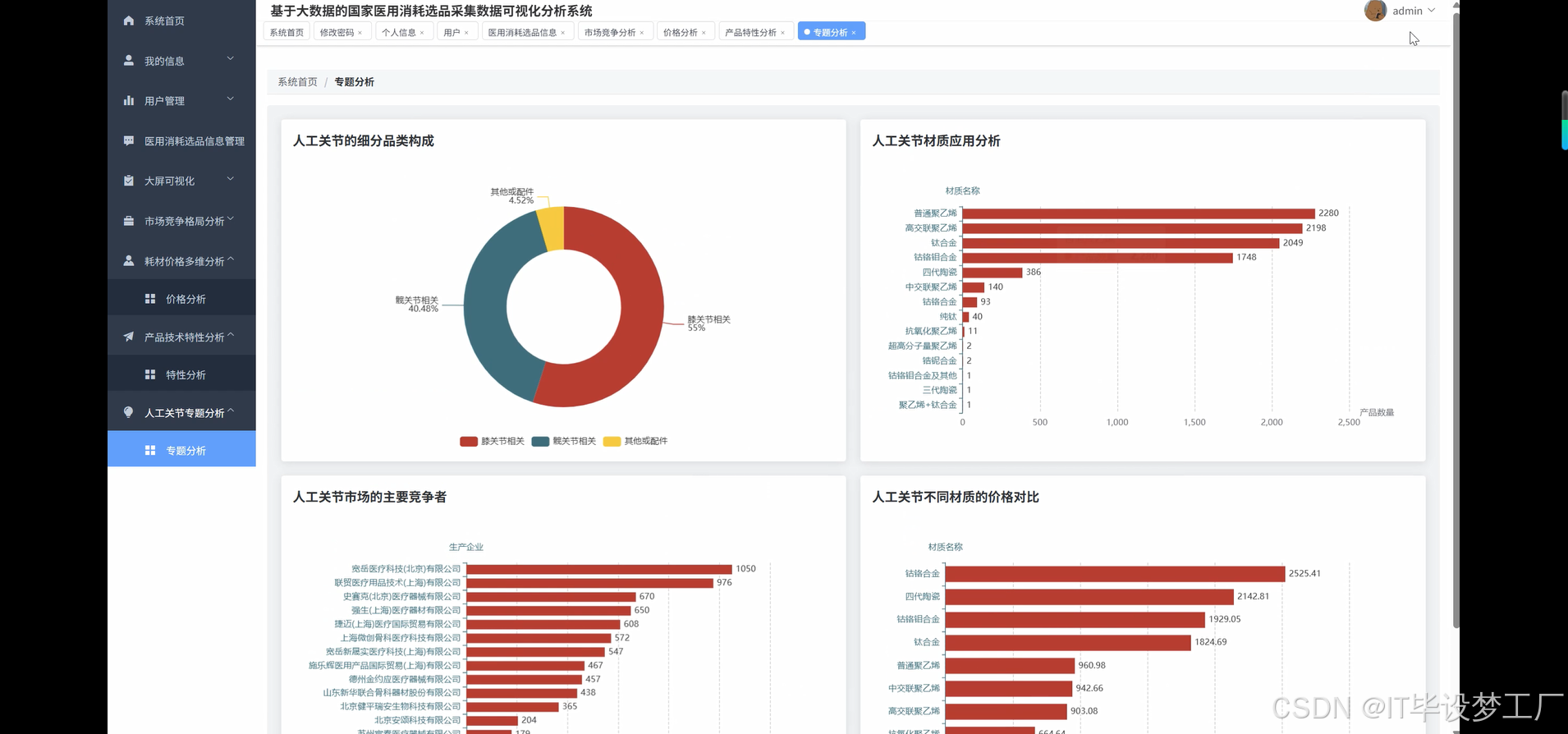
joint_category = df.filter(col("产品分类").like("%人工关节%"))
joint_competition = joint_category.groupBy("生产企业").agg(count("*").alias("产品数量")).orderBy(desc("产品数量"))
joint_total = joint_category.count()
joint_market_share = joint_competition.withColumn("细分市场份额", round(col("产品数量") / joint_total * 100, 2)).limit(15)
hhi_index = market_share.select((pow(col("市场份额"), 2)).alias("squared_share")).agg(sum("squared_share").alias("HHI指数"))
competition_metrics = df.groupBy("产品分类").agg(
countDistinct("生产企业").alias("企业数量"),
count("*").alias("产品总数")
).withColumn("平均企业产品数", round(col("产品总数") / col("企业数量"), 2)).orderBy(desc("企业数量"))
return {
"market_concentration": top20_enterprises.toPandas(),
"source_ratio": source_ratio.toPandas(),
"enterprise_layout": enterprise_layout.toPandas(),
"joint_market_share": joint_market_share.toPandas(),
"competition_metrics": competition_metrics.toPandas()
}
def product_feature_analysis(data_path):
df = spark.read.option("header", "true").option("inferSchema", "true").csv(data_path)
df = df.filter(col("产品分类").isNotNull())
df = df.withColumn("注册年份", regexp_extract(col("注册证编号"), r"(\d{4})", 1).cast("int"))
df = df.filter(col("注册年份").between(2010, 2024))
df = df.withColumn("产品来源", when(col("注册证编号").rlike("^国械注准"), "国产").otherwise("进口"))
category_composition = df.groupBy("产品分类").agg(count("*").alias("产品数量")).orderBy(desc("产品数量"))
total_products = df.count()
category_ratio = category_composition.withColumn("占比", round(col("产品数量") / total_products * 100, 2))
registration_trend = df.groupBy("注册年份").agg(count("*").alias("新注册产品数")).orderBy("注册年份")
yearly_growth = registration_trend.withColumn("同比增长",
round((col("新注册产品数") - lag("新注册产品数").over(Window.orderBy("注册年份"))) /
lag("新注册产品数").over(Window.orderBy("注册年份")) * 100, 2))
material_analysis = df.filter(col("材质名称").isNotNull() & (col("材质名称") != "")).groupBy("材质名称").agg(count("*").alias("使用频次")).orderBy(desc("使用频次"))
material_categories = material_analysis.withColumn("材质类别",
when(col("材质名称").rlike("钛|Ti"), "钛合金类")
.when(col("材质名称").rlike("陶瓷|ceramic"), "陶瓷类")
.when(col("材质名称").rlike("聚乙烯|PE|UHMWPE"), "聚合物类")
.when(col("材质名称").rlike("不锈钢|钢"), "不锈钢类")
.otherwise("其他材质"))
material_category_stats = material_categories.groupBy("材质类别").agg(sum("使用频次").alias("总使用次数")).orderBy(desc("总使用次数"))
source_trend = df.groupBy("注册年份", "产品来源").agg(count("*").alias("注册数量"))
source_pivot = source_trend.groupBy("注册年份").pivot("产品来源").agg(first("注册数量")).fillna(0).orderBy("注册年份")
innovation_index = df.groupBy("注册年份").agg(
countDistinct("生产企业").alias("活跃企业数"),
countDistinct("材质名称").alias("新材质数"),
count("*").alias("新产品数")
).withColumn("创新活跃度", col("活跃企业数") + col("新材质数") + col("新产品数") / 10)
avg_price_trend = df.filter(col("价格").isNotNull() & (col("价格") > 0)).groupBy("注册年份").agg(avg("价格").alias("年度平均价格")).orderBy("注册年份")
return {
"category_ratio": category_ratio.toPandas(),
"registration_trend": registration_trend.toPandas(),
"material_category_stats": material_category_stats.toPandas(),
"source_trend": source_pivot.toPandas(),
"innovation_index": innovation_index.toPandas(),
"price_trend": avg_price_trend.toPandas()
}五、系统视频
- 基于大数据的国家医用消耗选品采集数据可视化分析系统-项目视频:
大数据毕业设计选题推荐-基于大数据的国家医用消耗选品采集数据可视化分析系统-Hadoop-Spark-数据可视化-BigData
结语
大数据毕业设计选题推荐-基于大数据的国家医用消耗选品采集数据可视化分析系统-Hadoop-Spark-数据可视化-BigData
想看其他类型的计算机毕业设计作品也可以和我说~ 谢谢大家!
有技术这一块问题大家可以评论区交流或者私我~
大家可以帮忙点赞、收藏、关注、评论啦~
源码获取:⬇⬇⬇