Transformer实战(18)------微调Transformer语言模型进行回归分析
0. 前言
在自然语言处理领域中,预训练 Transformer 模型不仅能胜任离散类别预测,也可用于连续数值回归任务。本节介绍了如何将 DistilBert 转变为回归模型,为模型赋予预测连续相似度分值的能力。我们以GLUE 基准中的语义文本相似度 (STS-B) 数据集为例,详细介绍配置 DistilBertConfig、加载数据集、分词并构建 TrainingArguments,并定义 Pearson/Spearman 相关系数等回归指标。
1. 回归模型
回归模型通常最后一层只有一个神经元,它不会通过 softmax 逻辑回归处理,而是进行归一化。为了定义模型并在顶部添加一个单神经元的输出层,有两种方法:直接在 BERT.from_pretrained() 方法中使用参数 num_labels=1,或者通过 config 对象传递此信息。首先需要从预训练模型的 config 对象中复制这些信息:
python
from transformers import DistilBertConfig, DistilBertTokenizerFast, DistilBertForSequenceClassification
MODEL_PATH='distilbert-base-uncased'
config = DistilBertConfig.from_pretrained(MODEL_PATH, num_labels=1)
tokenizer = DistilBertTokenizerFast.from_pretrained(MODEL_PATH)
model = DistilBertForSequenceClassification.from_pretrained(MODEL_PATH, config=config)由于我们设置了 num_labels=1 参数,因此预训练模型的输出层包含一个神经元。接下来,准备数据集微调模型进行回归分析。
在本节中,我们将使用语义文本相似度基准 (STS-B) 数据集,它包含从新闻标题等多种内容中提取的句子对。每对句子都有一个从 1 到 5 的相似度评分,我们的任务是微调 DistilBert 模型以预测这些评分,并使用 Pearson/Spearman 相关系数来评估模型。
2. 数据处理
(1) 加载数据。将原始数据分为三部分,但由于测试集没有标签,所以我们可以将验证数据分为两部分:
python
import datasets
from datasets import load_dataset
stsb_train= load_dataset('glue','stsb', split="train")
stsb_validation = load_dataset('glue','stsb', split="validation")
stsb_validation=stsb_validation.shuffle(seed=42)
stsb_val= datasets.Dataset.from_dict(stsb_validation[:750])
stsb_test= datasets.Dataset.from_dict(stsb_validation[750:])(2) 使用 pandas 来整理 stsb_train 训练数据:
python
import pandas as pd
pd.DataFrame(stsb_train)整理后的训练数据样本如下:

(3) 查看三个数据集的形状:
python
stsb_train.shape, stsb_val.shape, stsb_test.shape
# ((5749, 4), (750, 4), (750, 4))(4) 对数据集进行分词处理:
python
enc_train = stsb_train.map(lambda e: tokenizer( e['sentence1'],e['sentence2'], padding=True, truncation=True), batched=True, batch_size=1000)
enc_val = stsb_val.map(lambda e: tokenizer( e['sentence1'],e['sentence2'], padding=True, truncation=True), batched=True, batch_size=1000)
enc_test = stsb_test.map(lambda e: tokenizer( e['sentence1'],e['sentence2'], padding=True, truncation=True), batched=True, batch_size=1000) (5) 分词器将两个句子用 [SEP] 分隔符连接,并为句子对生成 input_ids 和 attention_mask:
python
pd.DataFrame(enc_train)输出结果如下:

3. 模型构建与训练
(1) 在 TrainingArguments 类中定义参数集:
python
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
# The output directory where the model predictions and checkpoints will be written
output_dir='./stsb-model',
do_train=True,
do_eval=True,
# The number of epochs, defaults to 3.0
num_train_epochs=3,
per_device_train_batch_size=32,
per_device_eval_batch_size=64,
# Number of steps used for a linear warmup
warmup_steps=100,
weight_decay=0.01,
# TensorBoard log directory
logging_strategy='steps',
logging_dir='./logs',
logging_steps=50,
# other options : no, steps
evaluation_strategy="epoch",
save_strategy="epoch",
fp16=True,
load_best_model_at_end=True
)(2) 定义 compute_metrics 函数。其中,评估指标基于皮尔逊相关系数 (Pearson correlation coefficient) 和斯皮尔曼等级相关系数 (Spearman's rank correlation) 法,此外,还提供均方误差 (Mean Square Error, MSE)、均方根误差 (Root Mean Square Error, RMSE) 和平均绝对误差 (Mean Absolute Error, MAE) 等常用的回归模型评估指标:
python
from torch import cuda
device = 'cuda' if cuda.is_available() else 'cpu'
import numpy as np
from scipy.stats import pearsonr
from scipy.stats import spearmanr
def compute_metrics(pred):
preds = np.squeeze(pred.predictions)
return {"MSE": ((preds - pred.label_ids) ** 2).mean().item(),
"RMSE": (np.sqrt (( (preds - pred.label_ids) ** 2).mean())).item(),
"MAE": (np.abs(preds - pred.label_ids)).mean().item(),
"Pearson" : pearsonr(preds,pred.label_ids)[0],
"Spearman's Rank" : spearmanr(preds,pred.label_ids)[0]
}(3) 实例化 Trainer 对象:
python
trainer = Trainer(
model=model,
args=training_args,
train_dataset=enc_train,
eval_dataset=enc_val,
compute_metrics=compute_metrics,
tokenizer=tokenizer
)(4) 运行训练过程:
python
train_result = trainer.train()
metrics = train_result.metrics输出结果如下:
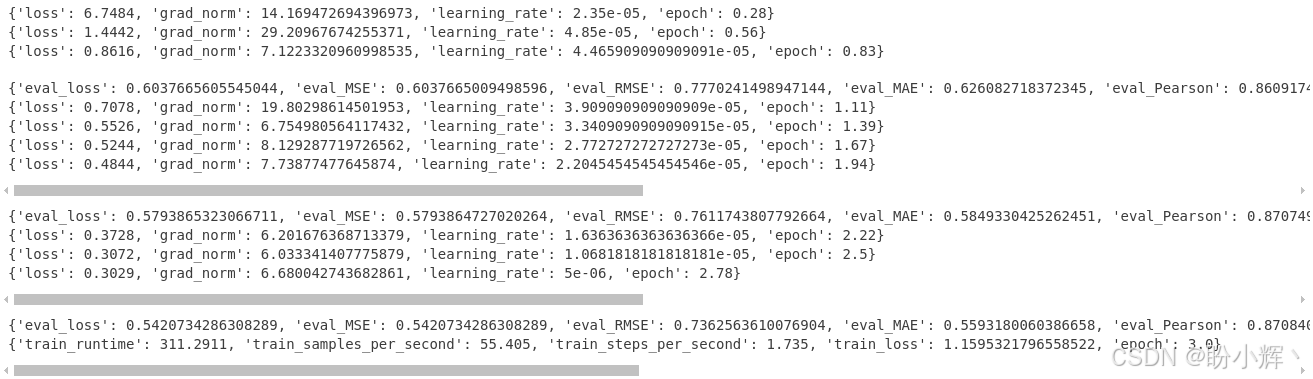
最佳验证损失为 0.542073,评估最佳权重模型:
python
q=[trainer.evaluate(eval_dataset=data) for data in [enc_train, enc_val, enc_test]]
pd.DataFrame(q, index=["train","val","test"]).iloc[:,:6]输出结果如下:

在测试数据集上,Pearson 和 Spearman 相关系数得分分别为 87.69 和 87.64。
4. 模型推理
(1) 运行模型进行推理。以下面两个意义相同的句子为例,将它们输入模型:
python
s1,s2="A plane is taking off.", "An air plane is taking off."
encoding = tokenizer(s1,s2, return_tensors='pt', padding=True, truncation=True, max_length=512)
input_ids = encoding['input_ids'].to(device)
attention_mask = encoding['attention_mask'].to(device)
outputs = model(input_ids, attention_mask=attention_mask)
outputs.logits.item()
# 4.57421875(2) 接下来,将语义不同的句子对输入模型:
python
s1,s2="The men are playing soccer.", "A man is riding a motorcycle."
encoding = tokenizer("hey how are you there","hey how are you", return_tensors='pt', padding=True, truncation=True, max_length=512)
input_ids = encoding['input_ids'].to(device)
attention_mask = encoding['attention_mask'].to(device)
outputs = model(input_ids, attention_mask=attention_mask)
outputs.logits.item()
# 3.1953125(3) 最后,保存模型:
python
model_path = "sentence-pair-regression-model"
trainer.save_model(model_path)
tokenizer.save_pretrained(model_path)小结
本节介绍了如何基于预训练 DistilBert 架构完成语义相似度回归分析。首先,通过修改配置或传参的方式,为模型顶层添加单神经元回归头;随后,借助 STS-B 数据集构建训练、验证与测试集,并应用分词器生成模型输入。接着,使用 Trainer 框架与自定义的 compute_metrics 函数,对模型在 MSE、RMSE、MAE 及 Pearson 和 Spearman 相关性等多维度指标上进行评估,验证了微调方法在回归任务中的有效性。
系列链接
Transformer实战(1)------词嵌入技术详解
Transformer实战(2)------循环神经网络详解
Transformer实战(3)------从词袋模型到Transformer:NLP技术演进
Transformer实战(4)------从零开始构建Transformer
Transformer实战(5)------Hugging Face环境配置与应用详解
Transformer实战(6)------Transformer模型性能评估
Transformer实战(7)------datasets库核心功能解析
Transformer实战(8)------BERT模型详解与实现
Transformer实战(9)------Transformer分词算法详解
Transformer实战(10)------生成式语言模型 (Generative Language Model, GLM)
Transformer实战(11)------从零开始构建GPT模型
Transformer实战(12)------基于Transformer的文本到文本模型
Transformer实战(13)------从零开始训练GPT-2语言模型
Transformer实战(14)------微调Transformer语言模型用于文本分类
Transformer实战(15)------使用PyTorch微调Transformer语言模型
Transformer实战(16)------微调Transformer语言模型用于多类别文本分类
Transformer实战(17)------微调Transformer语言模型进行多标签文本分类