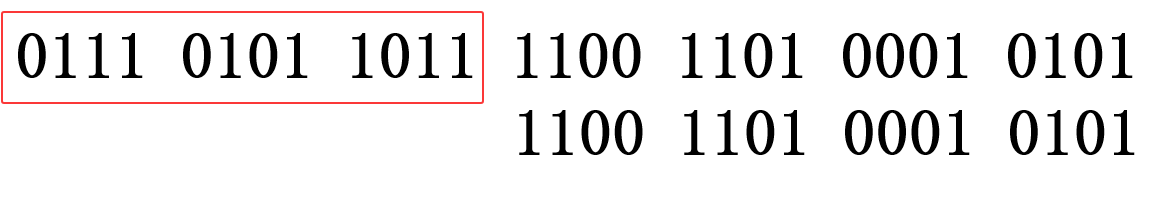免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动!
本次游戏没法给
内容参考于:微尘网络安全
上一个内容:4.UE-探索GetName的加密算法(二)GName(GName在代码中是什么和Blocks字符串存放地)
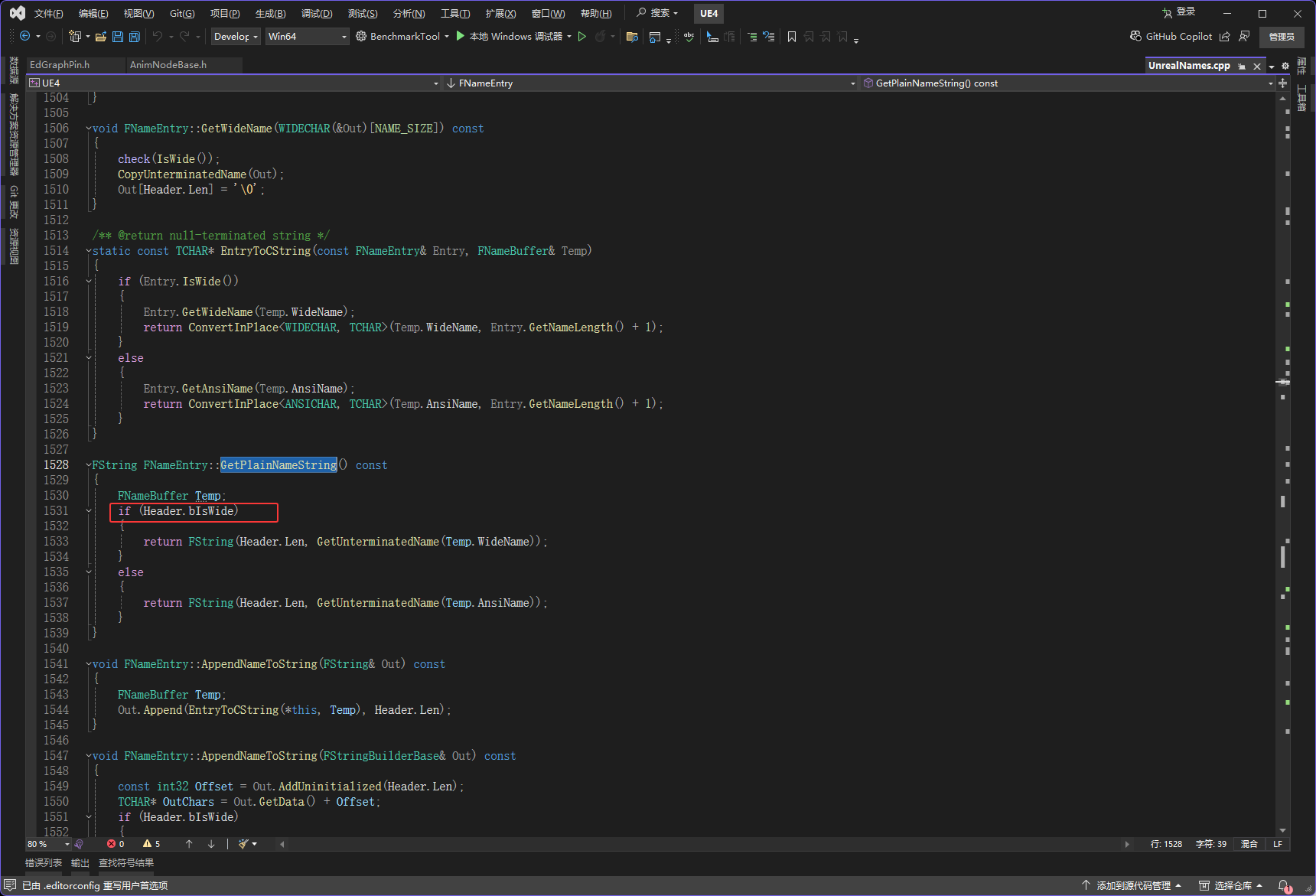
上一个内容里写的Stride是4,这个有点不正确,它只有在开发的时候才会是4
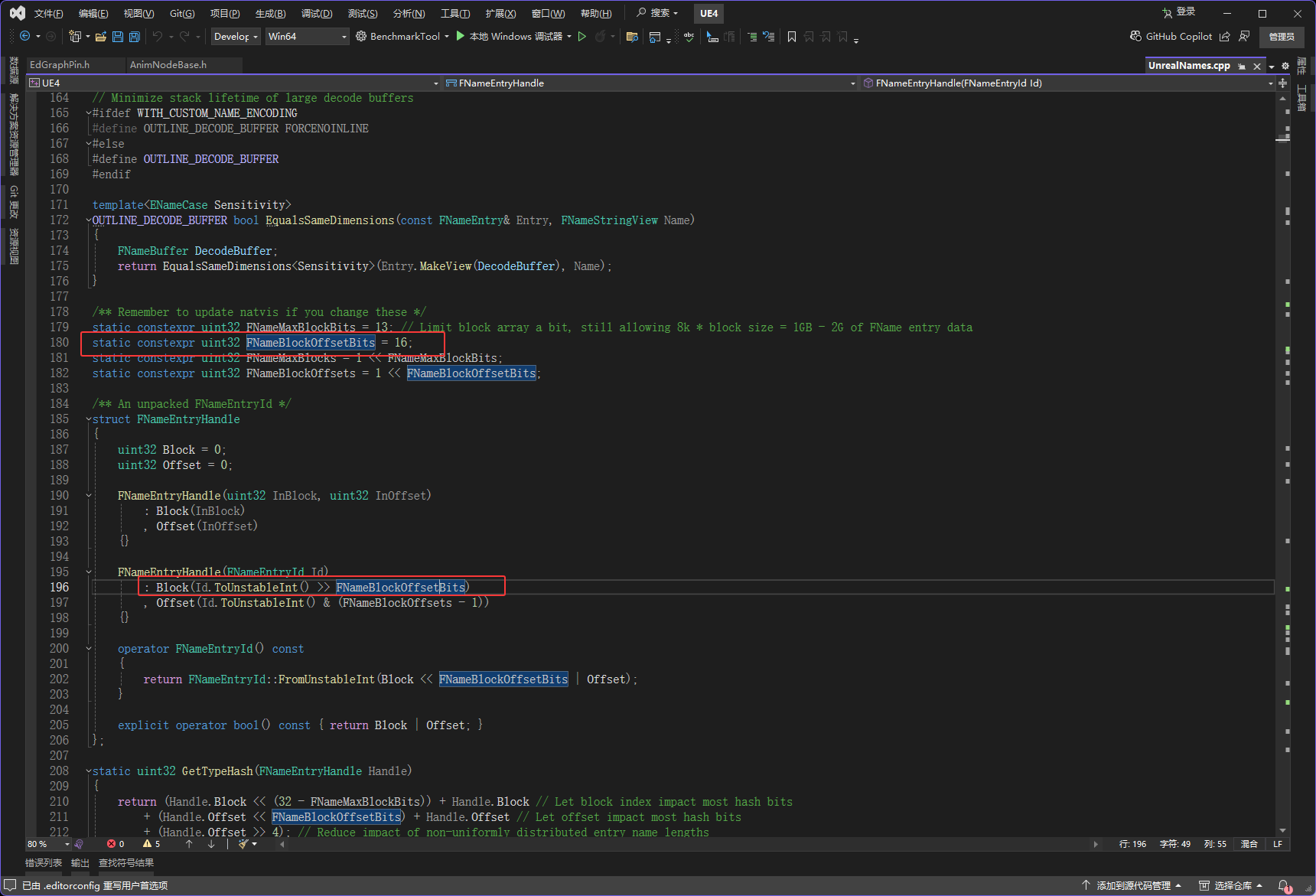
然后下图红框alignof是取FNameEntry类的内存对齐的方式
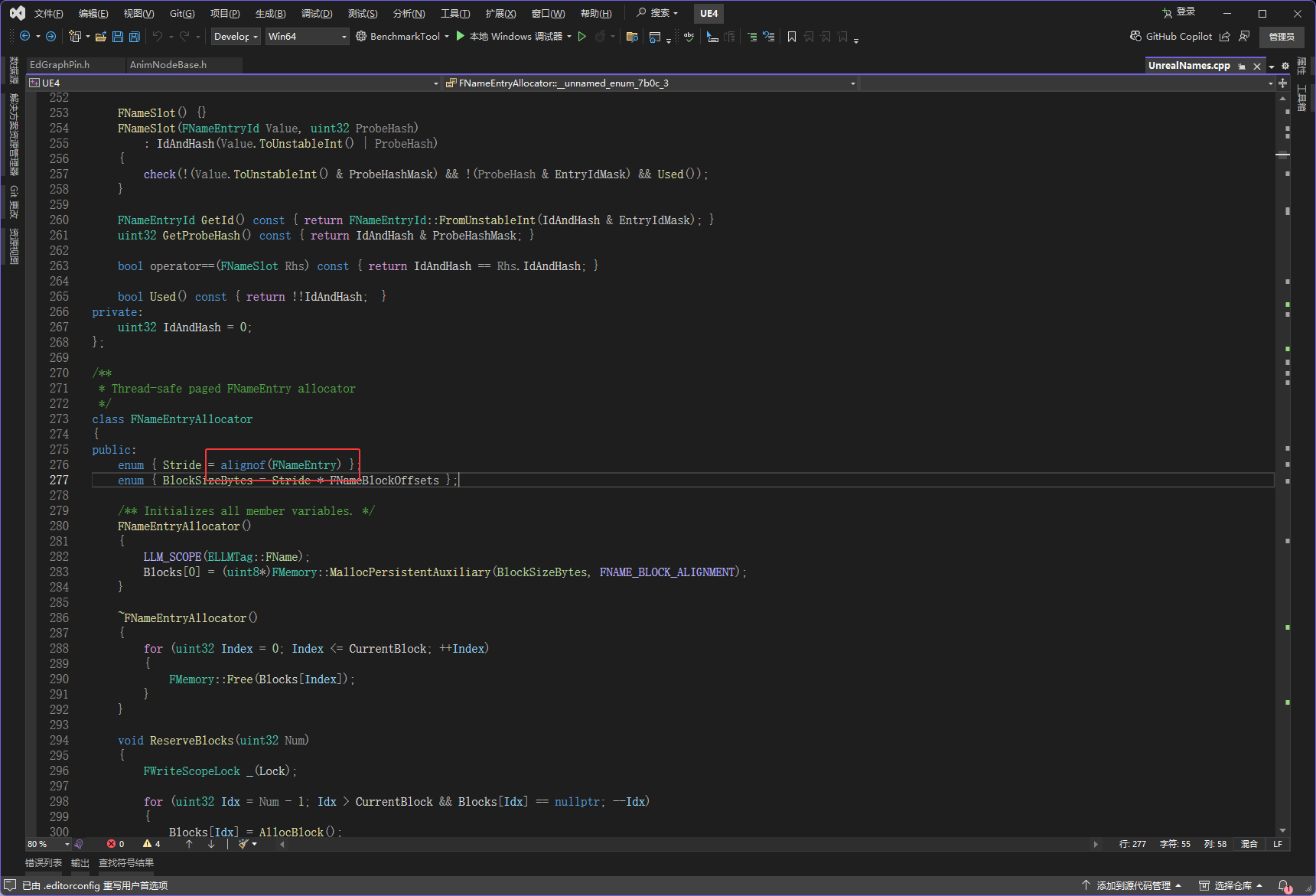
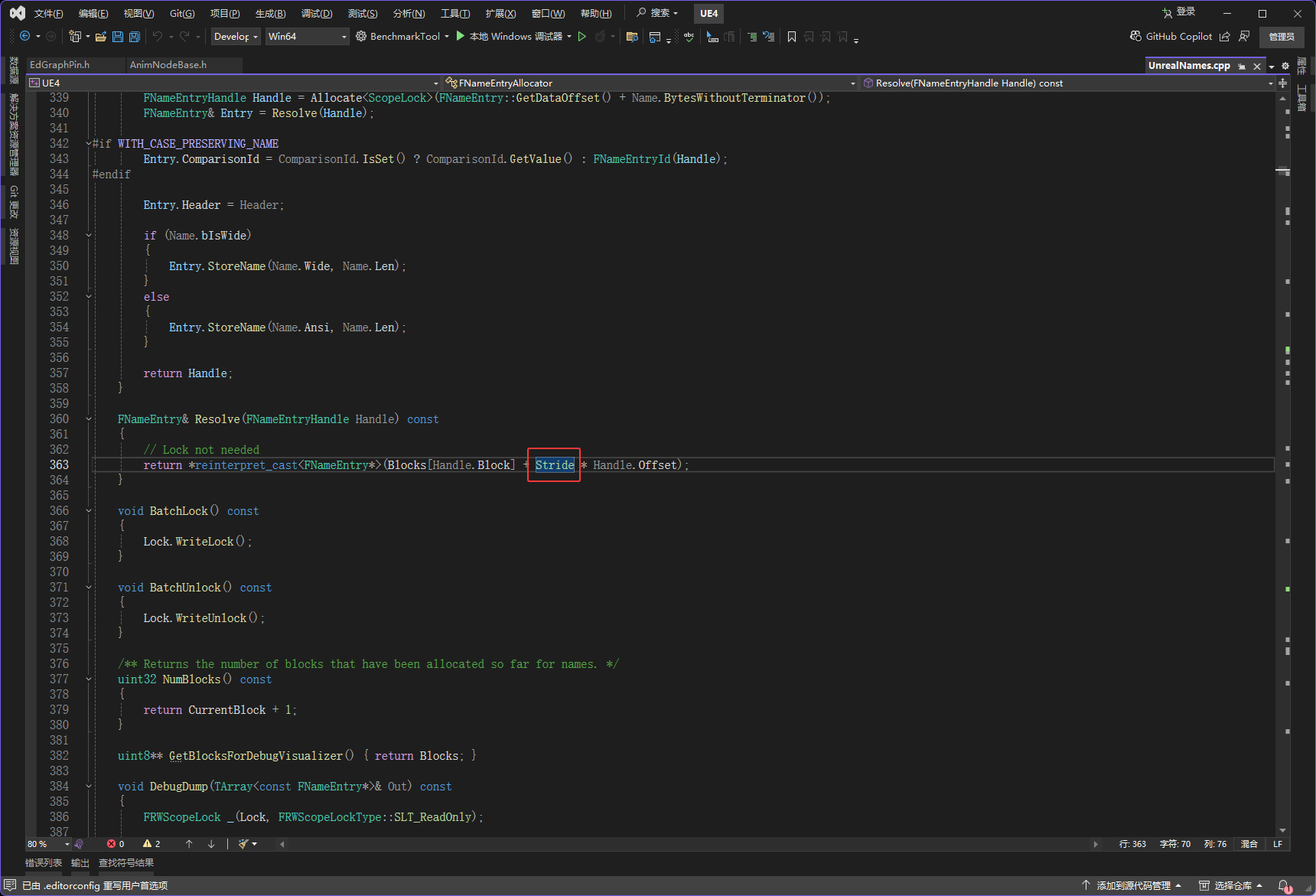
下图红框里有一个WITH_CASE_PRESERVING_NAME,开发的时候它才会存在,它存在也就导致ComparisonId是存在的,ComparisonId是4字节,然后在FNameEntry4字节是最大的,所以会使用4字节对齐
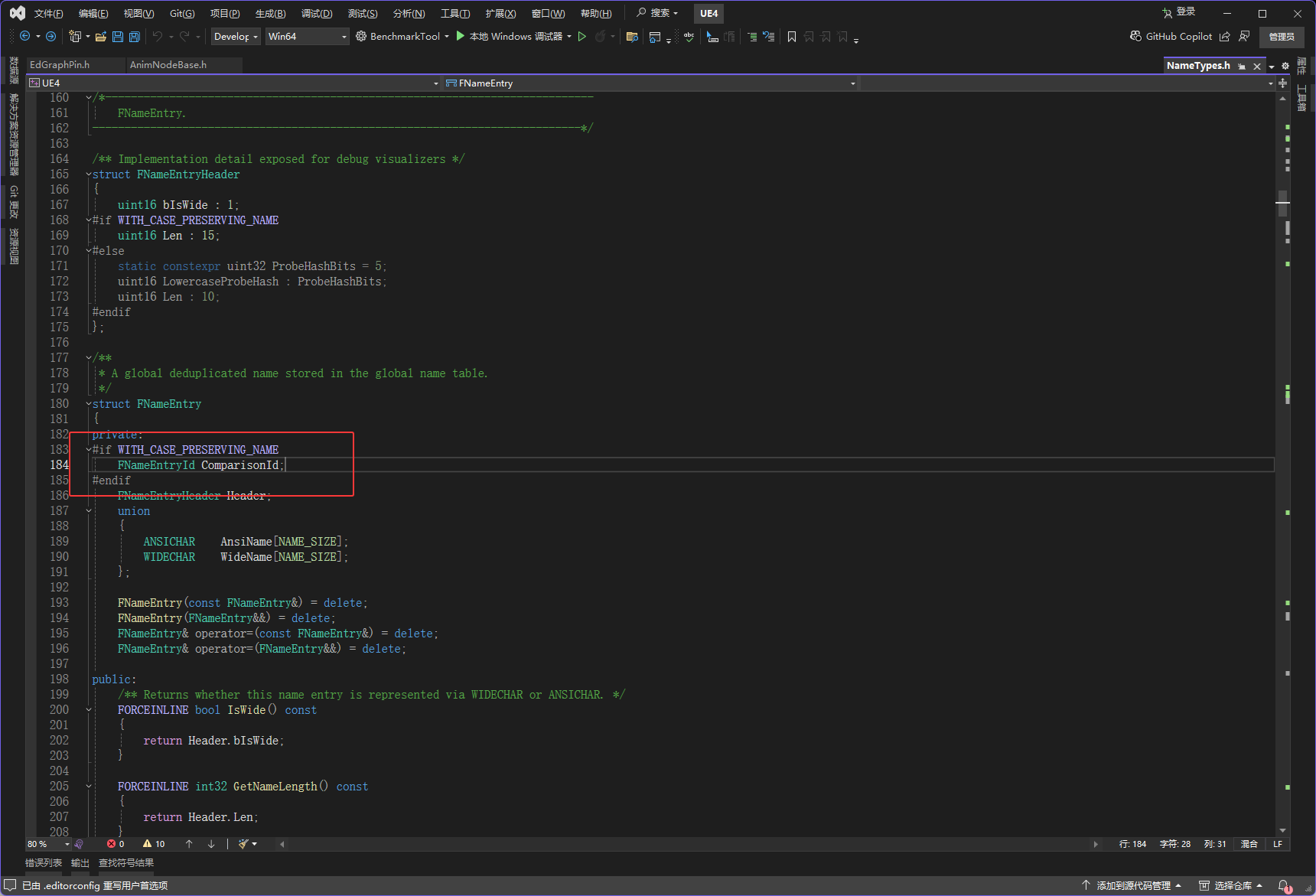
然后FNameEntryHeader的大小,它里面只会有一个int16,int16这个类型是2字节
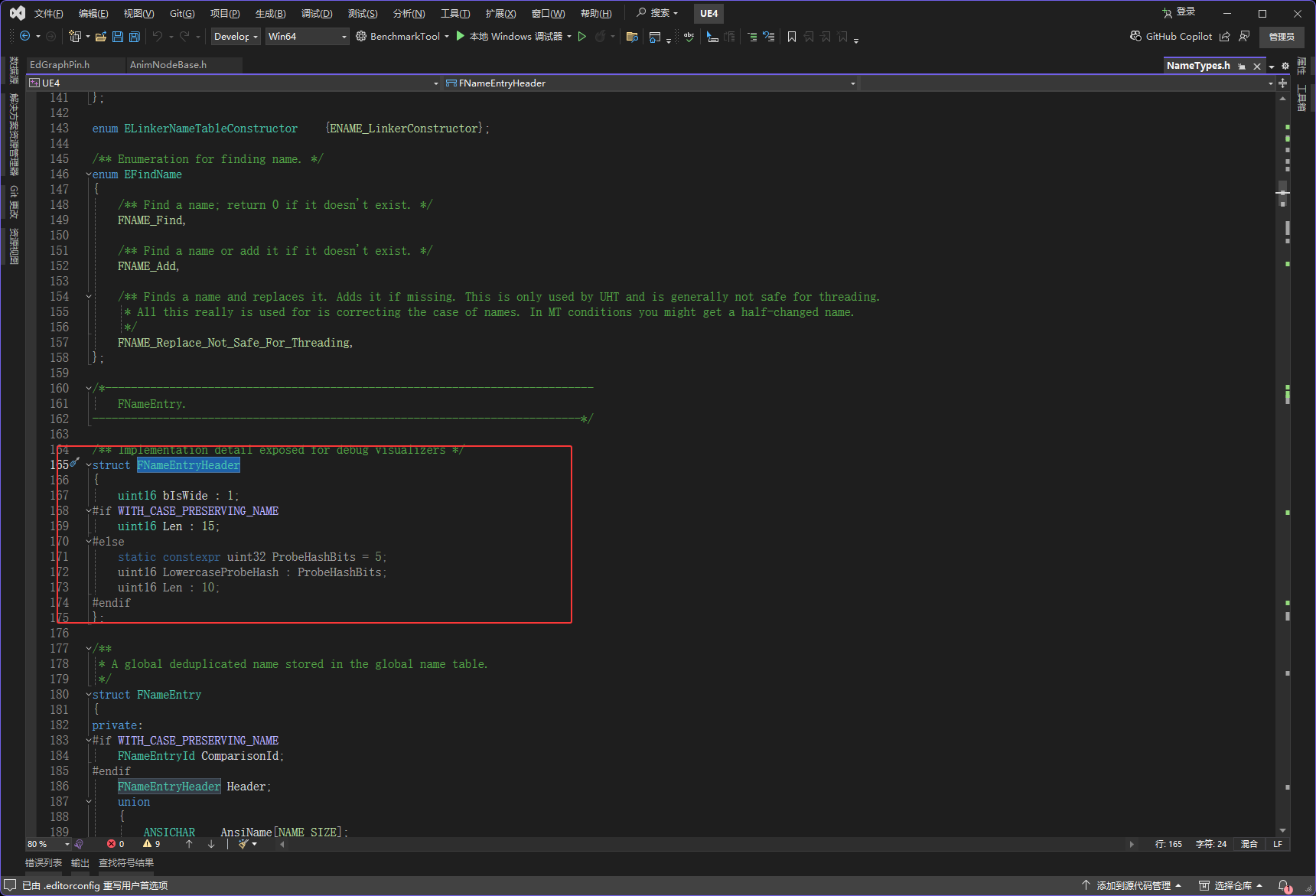
所以如果ComparisonId不存在(非开发),下图红框的两个是最大的,它们都是2字节
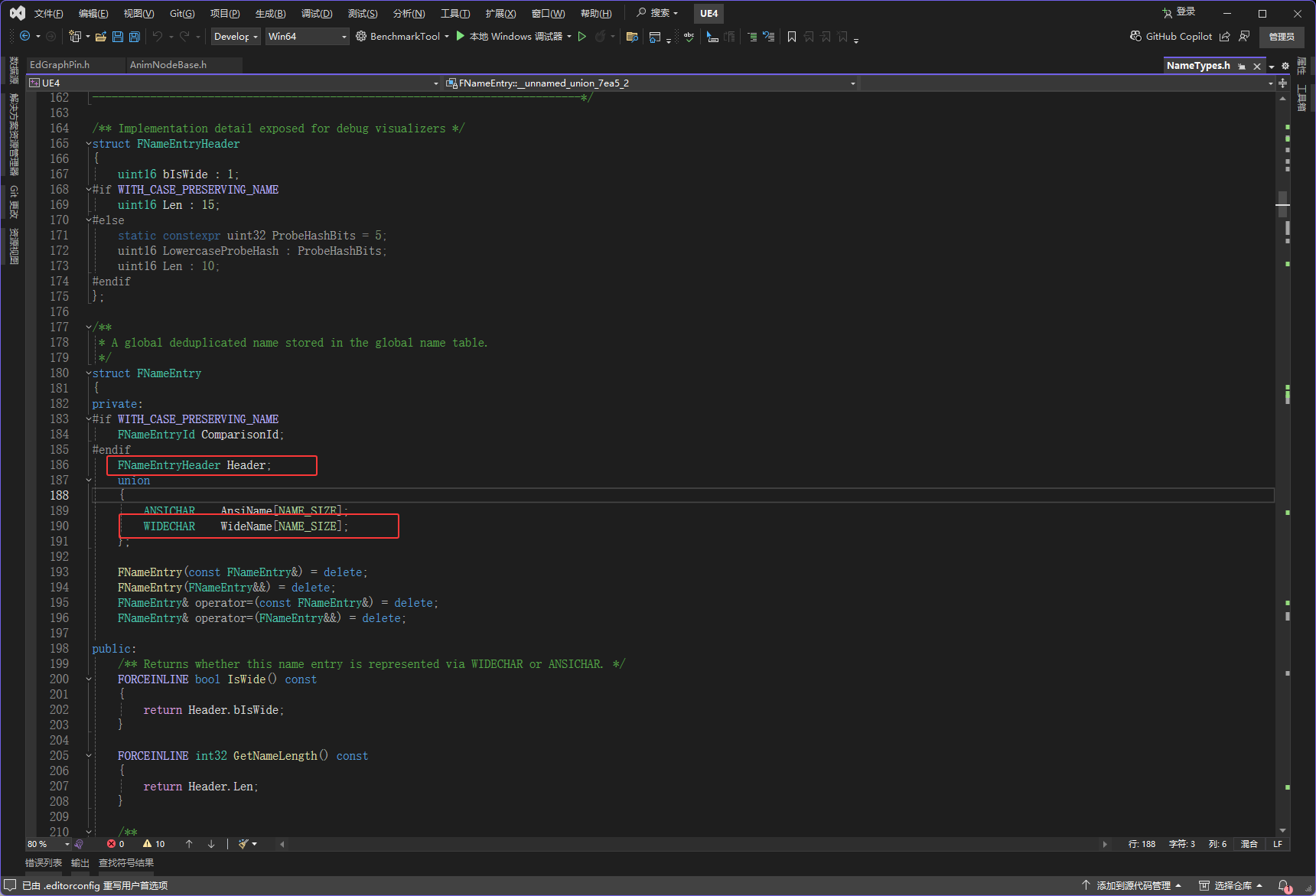
所以现在下图红框的算法是*reinterpret_cast<FNameEntry*>(BlocksHandle.Block + 2 * Handle.Offset)
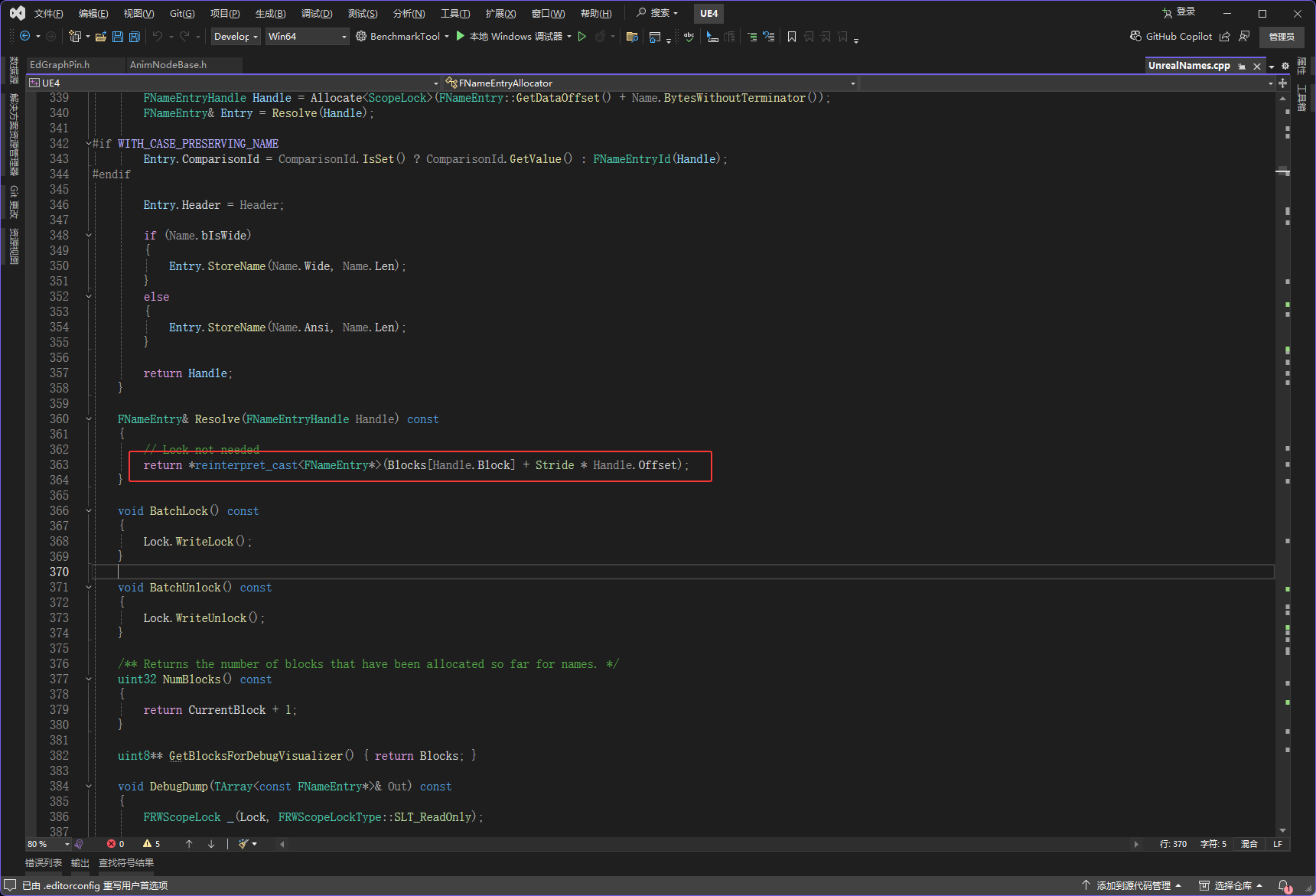
然后到这下图红框的GetDisplayNameEntry函数就分析好了
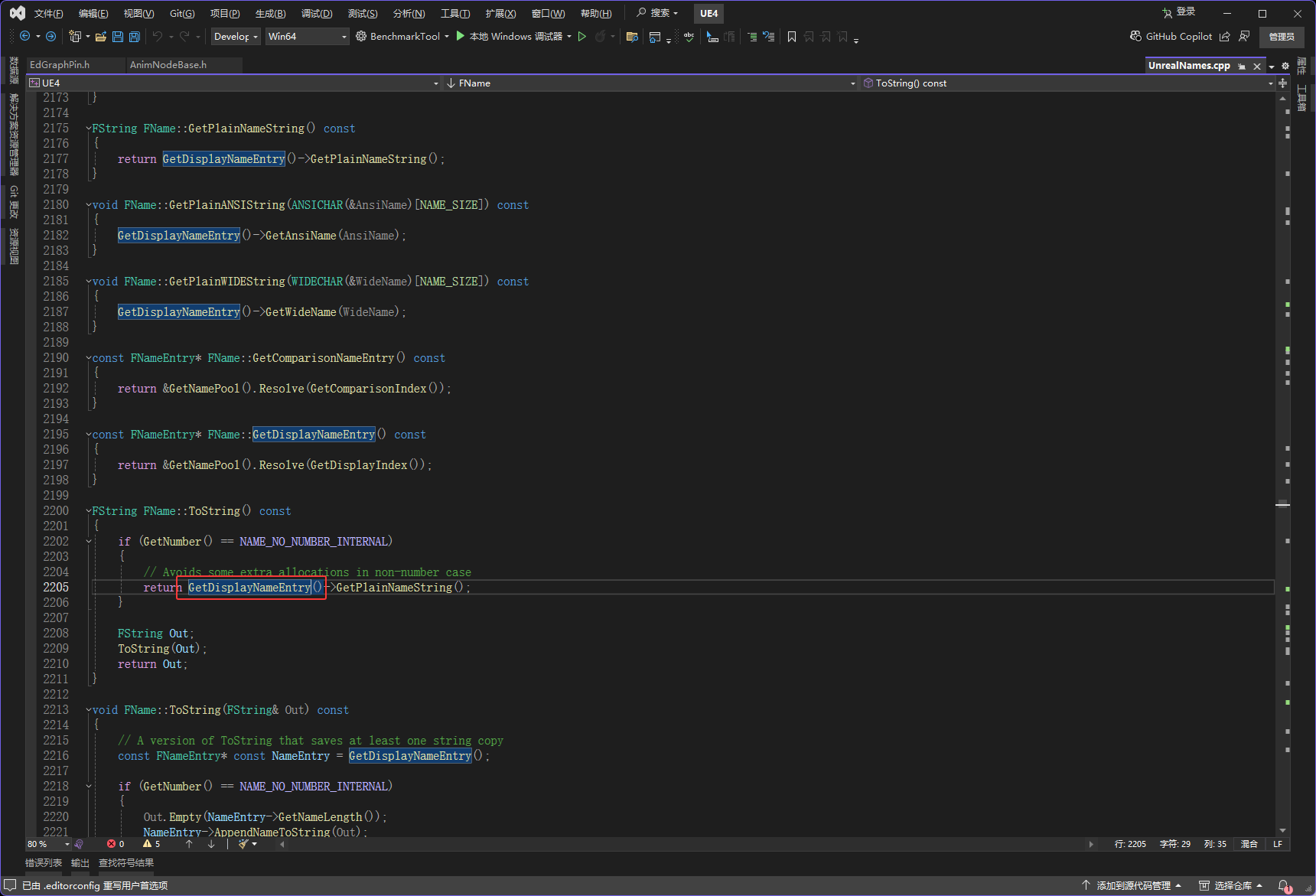
接下来是下图红框的GetPlainNameString函数
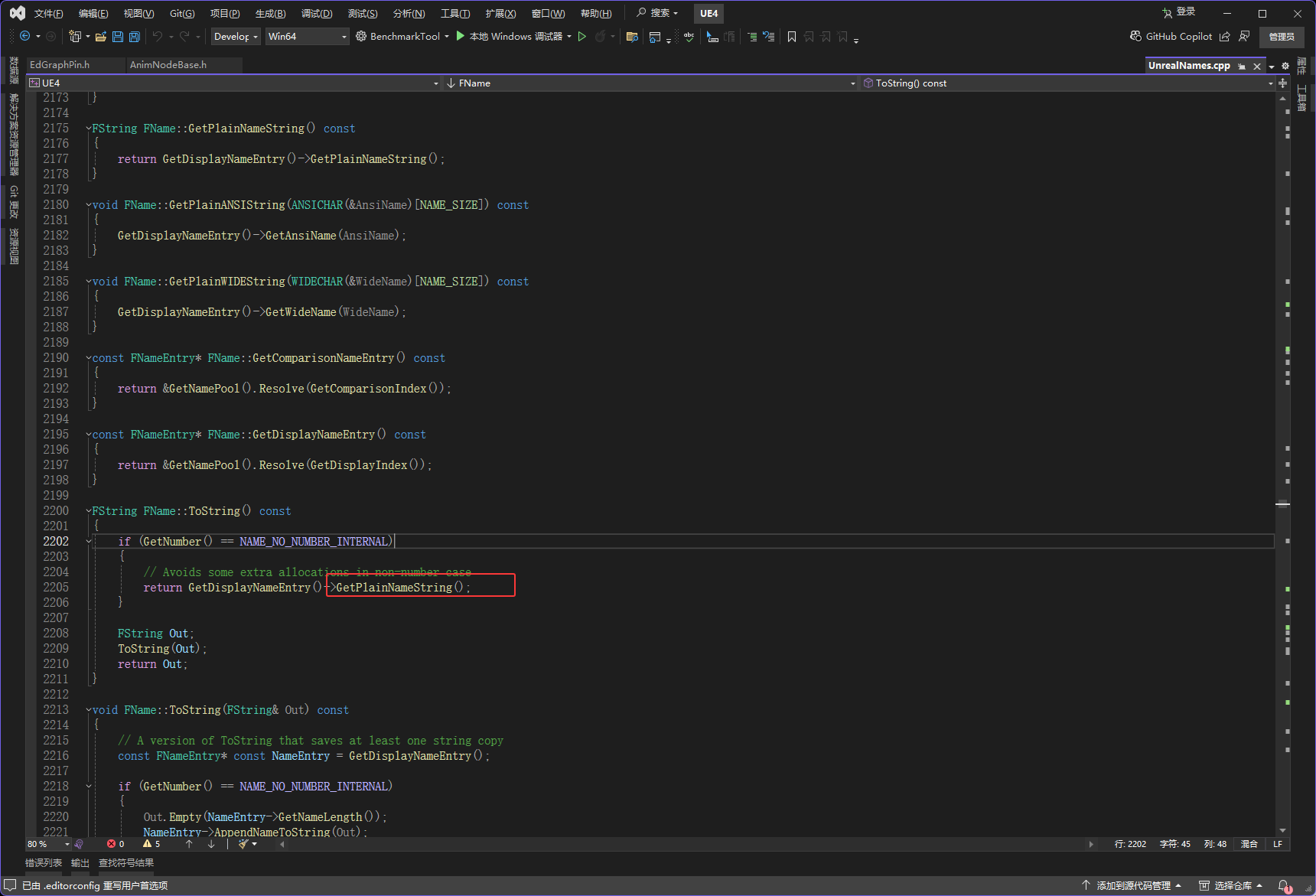
进入GetPlainNameString函数
代码说明
c++
// 函数功能:从当前FNameEntry中取出存储的字符串内容,转换成UE引擎中常用的FString类型并返回
// 简单说:这个函数就是"把FNameEntry里存的字符串取出来,变成可以直接用的字符串类型"
FString FNameEntry::GetPlainNameString() const
{
// 创建一个临时缓冲区(FNameBuffer是UE定义的结构体,里面有两个数组,分别用来临时存ANSI字符和宽字符)
// 作用:就像一个"临时托盘",先把从FNameEntry里取出来的原始字符数据放在这里,方便后续处理
FNameBuffer Temp;
// 检查当前FNameEntry存储的是宽字符(WIDECHAR)还是ANSI字符(ANSICHAR)
// Header是FNameEntry里的"标签结构体",bIsWide是标签里的一个标识位(1表示宽字符,0表示ANSI字符)
if (Header.bIsWide)
{
// 如果是宽字符:
// 1. 调用GetUnterminatedName(Temp.WideName):从当前FNameEntry中取出"没有加结束符的原始宽字符数据",存到临时缓冲区的WideName数组里
// (注:计算机里字符串通常以'\0'作为结束标志,这里"未加结束符"指的是原始存储的字符本身,还没补这个标志)
// 2. 用FString的构造函数:根据字符串长度(Header.Len)和刚才取到的原始宽字符数据,创建一个FString并返回
return FString(Header.Len, GetUnterminatedName(Temp.WideName));
}
else
{
// 如果是ANSI字符:
// 逻辑和宽字符类似,只是取的是ANSI字符数据,存到临时缓冲区的AnsiName数组里
// 最后用这些数据创建FString并返回
return FString(Header.Len, GetUnterminatedName(Temp.AnsiName));
}
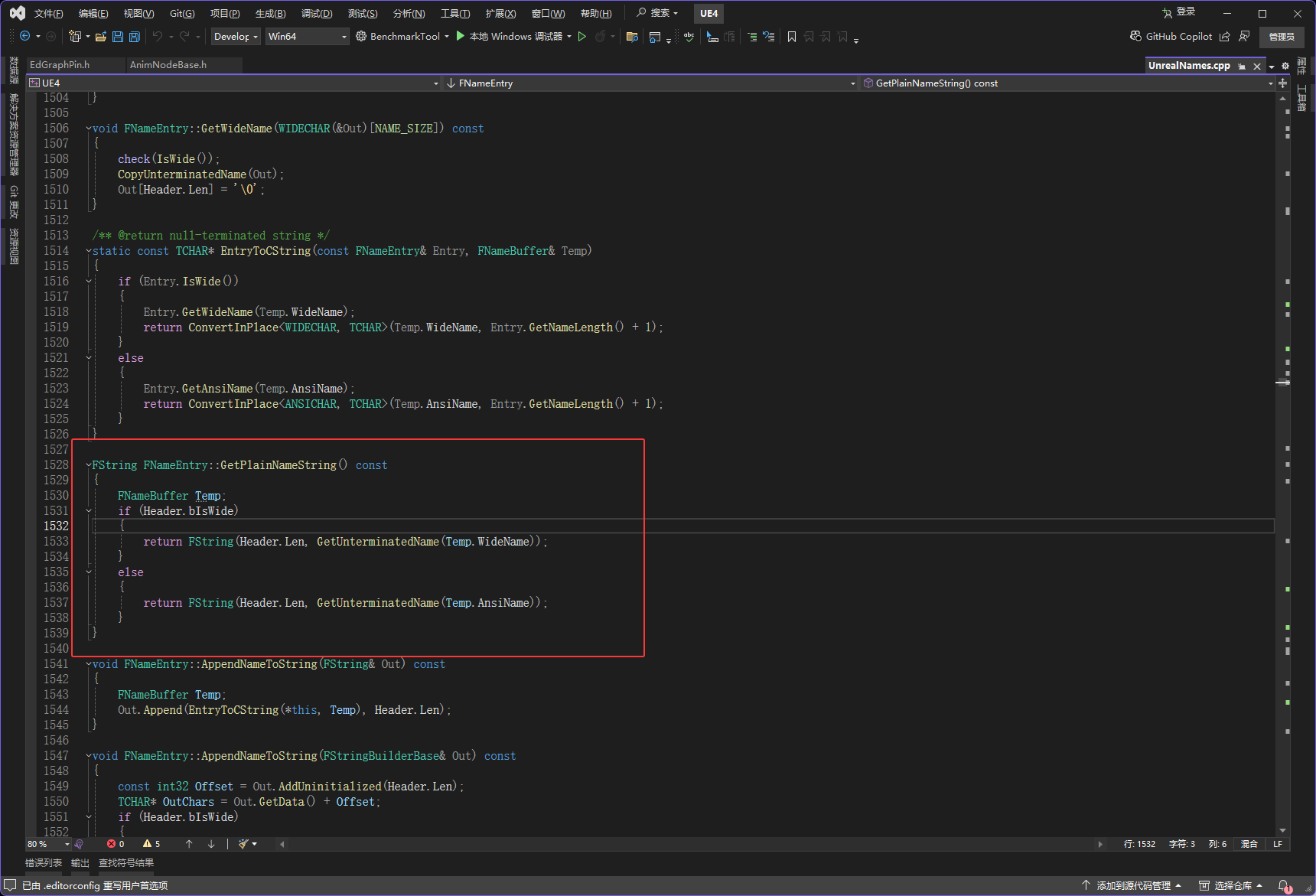
}然后GetPlainNameString函数里主要就是复制内存,然后把创建的内存搞成一个FString类型,复制的操作在下图红框GetUnterminatedName函数中
GetUnterminatedName函数
代码说明
c++
// 函数功能:获取当前FNameEntry中存储的"未加终止符的宽字符字符串"(宽字符即WIDECHAR,通常用于存储中文、日文等多字节字符)
// FORCEINLINE:UE的宏,强制编译器把这个函数的代码"直接嵌入到调用它的地方"(而不是像普通函数那样跳转执行),目的是减少函数调用的开销,让程序运行更快
// 返回值:指向宽字符字符串的指针(const表示不能通过这个指针修改字符串内容)
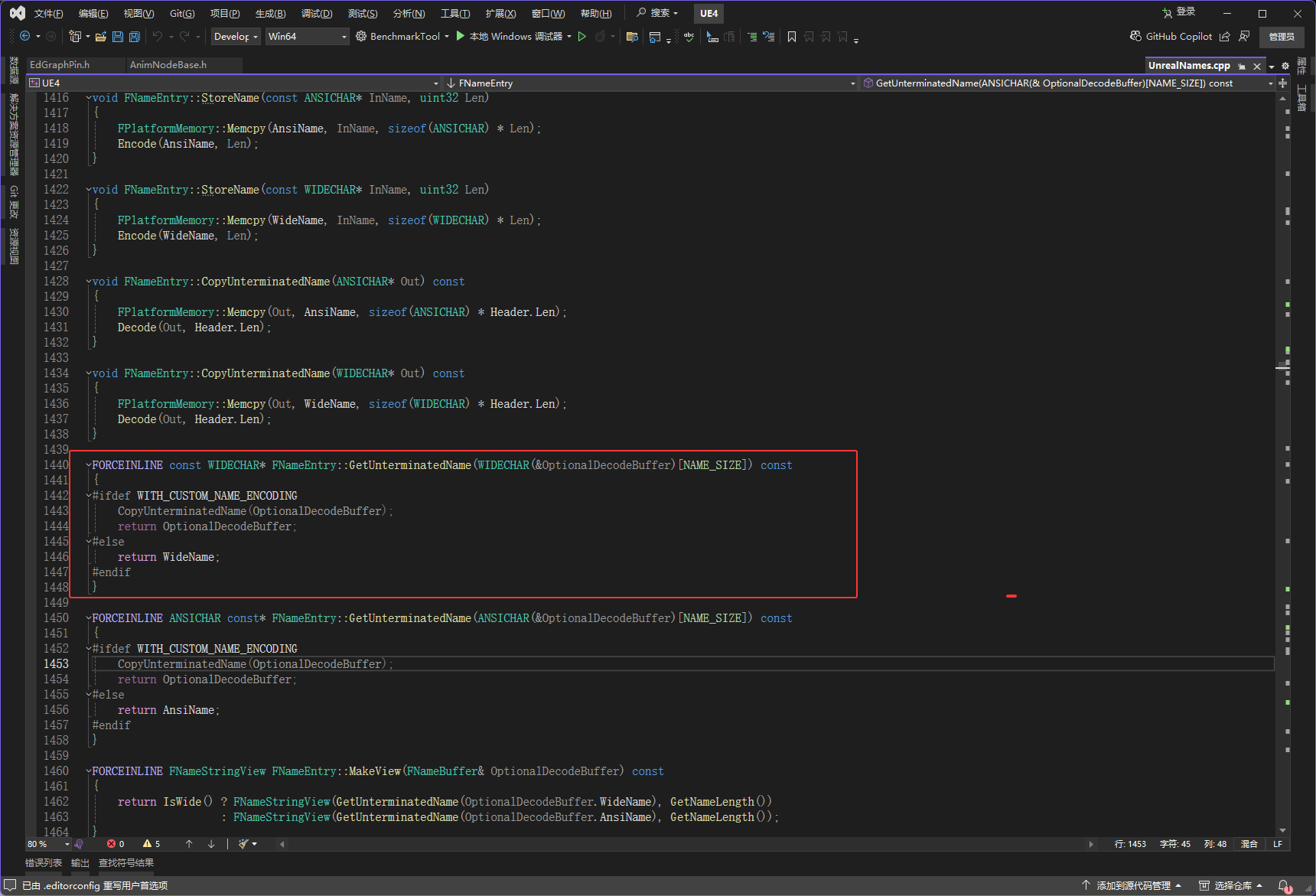
FORCEINLINE const WIDECHAR* FNameEntry::GetUnterminatedName(WIDECHAR(&OptionalDecodeBuffer)[NAME_SIZE]) const
{
// 如果定义了"WITH_CUSTOM_NAME_ENCODING"这个宏(表示项目启用了"自定义名字编码"功能,比如加密或特殊格式存储字符串)
#ifdef WITH_CUSTOM_NAME_ENCODING
// 1. 调用CopyUnterminatedName函数:把FNameEntry里存储的宽字符字符串(可能是加密/特殊编码的)复制到传入的临时缓冲区OptionalDecodeBuffer中,同时完成解码
// 2. OptionalDecodeBuffer:一个宽字符数组(大小为NAME_SIZE),作为"临时容器"接收解码后的字符串
CopyUnterminatedName(OptionalDecodeBuffer);
// 返回这个临时缓冲区的地址,里面就是解码后、未加终止符的宽字符字符串
return OptionalDecodeBuffer;
#else
// 如果没有启用自定义编码(默认情况),直接返回FNameEntry内部存储宽字符的数组WideName
// WideName是FNameEntry里的联合体成员,直接存储原始宽字符数据,没有加密或特殊处理
return WideName;
#endif
}
// 关键概念补充:
// 1. 未加终止符(Unterminated):
// 计算机中字符串通常以'\0'(空字符)作为结束标志(类似句子的句号)
// 这里的"未加终止符"指字符串内容本身没有这个'\0',只包含有效字符
// 原因:FNameEntry为了节省内存,存储时可能省略结束符,使用时通过Header.Len知道长度
// 2. 宽字符(WIDECHAR)与ANSI字符:
// - ANSI字符:1字节/个,只能存英文、数字等(类似"小盒子")
// - WIDECHAR:2字节/个,能存中文、日文等(类似"大盒子",容纳更多字符)
// 3. 缓冲区(OptionalDecodeBuffer)的作用:
// 当字符串有特殊编码时,不能直接返回原始数据(可能是乱码或加密内容)
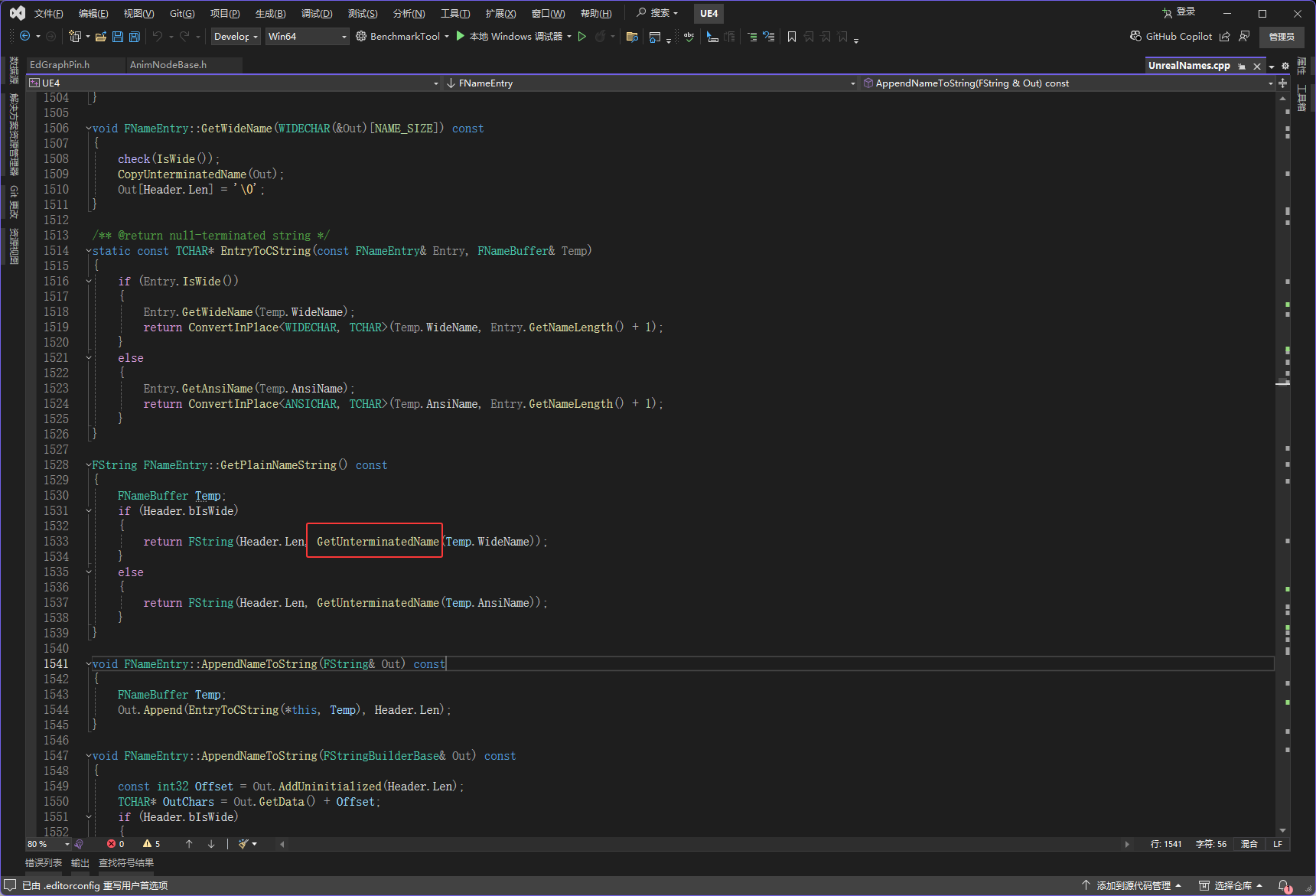
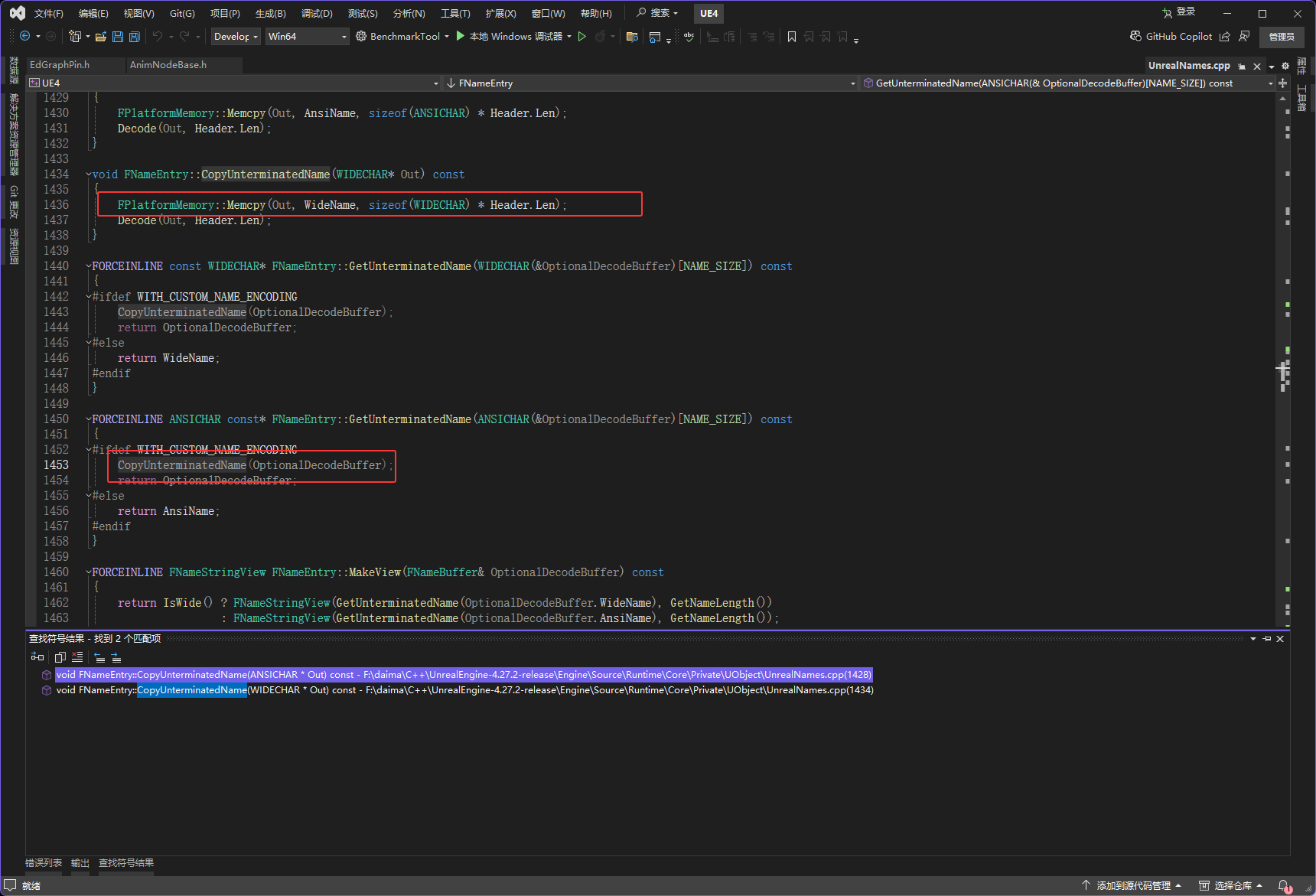
// 因此先解码到临时缓冲区,再返回缓冲区地址,确保调用者拿到的是正确的字符串然后CopyUnterminatedName如下图红框
代码说明
c++
// 函数功能:将当前FNameEntry中存储的宽字符字符串(未加终止符)复制到目标缓冲区,并进行解码(如果有特殊编码的话)
// 简单说:就是把内部的宽字符内容"复制粘贴"到外面的缓冲区,再做必要的解密/还原处理
// 函数声明拆解:
// 1. void:函数没有返回值(只负责"做事",不返回结果)
// 2. FNameEntry::CopyUnterminatedName:属于FNameEntry类的成员函数,函数名意思是"复制未加终止符的名字"
// 3. (WIDECHAR* Out):函数的参数
// - WIDECHAR*:指向宽字符的指针(表示"目标缓冲区的地址",告诉函数要把内容复制到哪里)
// - Out:参数名,意为"输出",即复制的结果会存到这里
// 4. const:函数末尾的const,表示这个函数不会修改FNameEntry自身的数据(只读取内部的宽字符内容)
void FNameEntry::CopyUnterminatedName(WIDECHAR* Out) const
{
// 第一步:把内部存储的宽字符数据复制到目标缓冲区Out中
// FPlatformMemory::Memcpy:UE封装的内存复制函数,作用类似"Ctrl+C再Ctrl+V",直接复制内存中的二进制数据
// 参数说明:
// - 第一个参数Out:目标地址(要粘贴到哪里)
// - 第二个参数WideName:源地址(要复制的内容在哪里,FNameEntry内部存储宽字符的数组)
// - 第三个参数:要复制的字节数 = 每个宽字符的大小 × 字符串长度
// - sizeof(WIDECHAR):每个宽字符占2字节(因为WIDECHAR是2字节类型)
// - Header.Len:字符串的长度(从Header中获取,比如长度为5表示有5个宽字符)
// 举例:如果字符串长度是3,就需要复制 2×3=6字节的数据
FPlatformMemory::Memcpy(Out, WideName, sizeof(WIDECHAR) * Header.Len);
// 第二步:对复制到Out缓冲区的字符串进行解码
// Decode是内部函数,作用是还原特殊编码的字符串(比如如果存储时加密了,这里就解密;如果压缩了,这里就解压)
// 参数:Out(要解码的字符串)、Header.Len(字符串长度,告诉解码函数要处理多少个字符)
Decode(Out, Header.Len);
}
// 关键概念解释:
// 1. 为什么用Memcpy?
// 因为要直接复制原始的宽字符数据(二进制层面的复制),比逐个字符复制更快,尤其适合频繁调用的场景
// 2. 为什么要计算字节数?
// Memcpy需要明确知道要复制多少字节的内容。宽字符每个占2字节,所以"总字节数 = 单个大小 × 字符数量",确保不多复制也不少复制
// 3. 解码(Decode)的意义?
// 如果项目启用了自定义编码(比如WITH_CUSTOM_NAME_ENCODING宏开启),字符串存储时可能被加密或特殊处理(节省空间或保护数据)
// 这里的解码就是把这些处理过的字符串还原成正常可读的内容,让外部调用者能正确使用
// 4. 为什么是"未加终止符"?
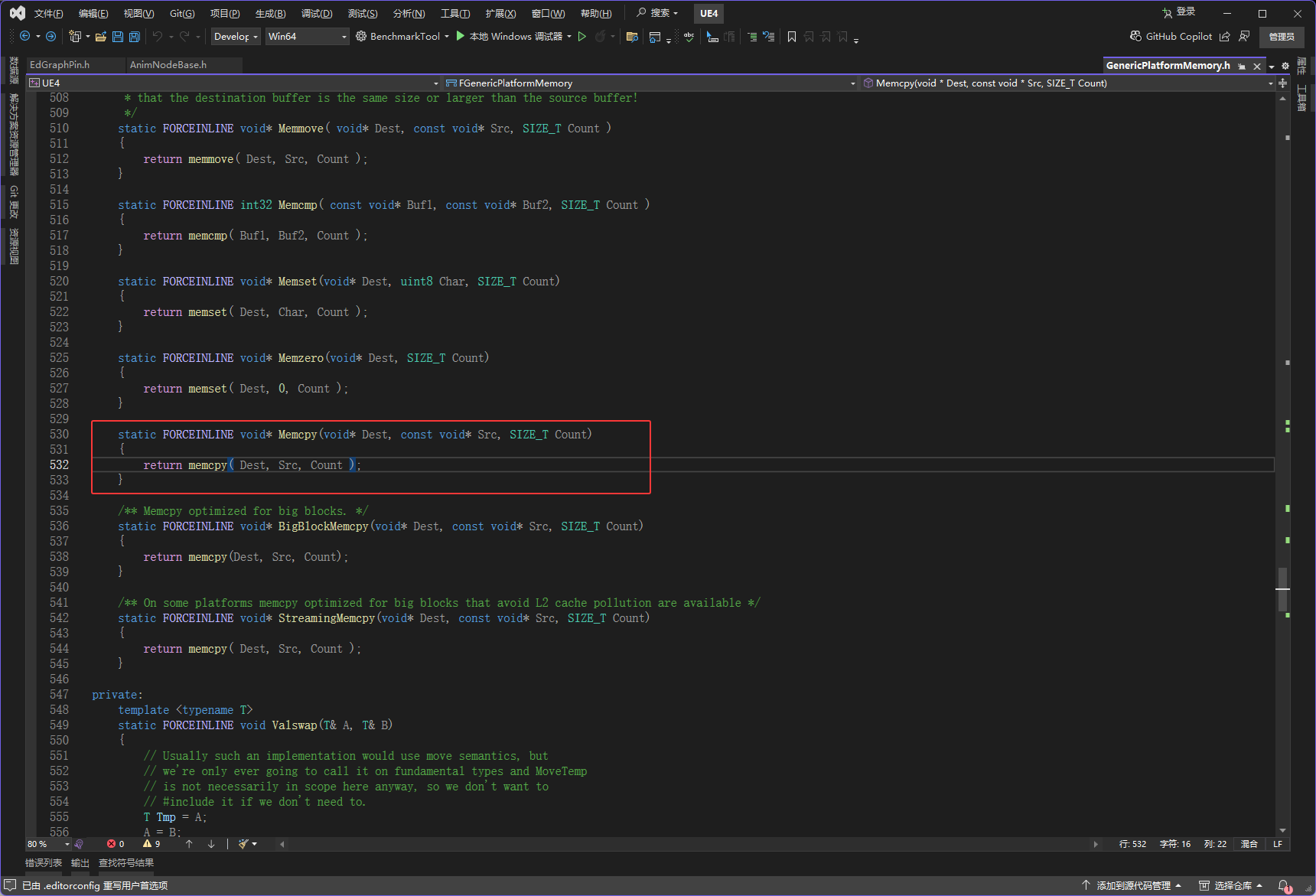
// 复制的字符数量是Header.Len(有效字符数),没有在末尾加'\0'(结束符),因为调用这个函数的地方会根据Header.Len知道字符串长度,不需要结束符然后Memcpy函数
代码说明
c++
// 函数功能:将一块内存中的数据从源地址复制到目标地址,本质是对标准库memcpy函数的封装
// 简单说:就像"文件复制"一样,把一块内存里的内容原封不动地复制到另一块内存,支持复制大块数据
// 函数声明拆解:
// 1. static:静态函数,意味着它属于定义它的类或命名空间,不需要创建对象就能调用(类似"全局工具函数")
// 2. FORCEINLINE:强制内联编译,把函数代码直接嵌入到调用处(减少函数调用的跳转开销,让复制更快)
// 3. void*:返回值类型,是一个"无类型指针"(可以指向任何类型的内存),返回的是目标地址(Dest)
// - 作用:方便链式操作(比如复制后直接用这个地址做其他事)
// 4. BigBlockMemcpy:函数名,意为"大块内存复制"(虽然这里直接调用memcpy,但名字暗示它适合处理大块数据)
// 5. 参数列表:
// - void* Dest:目标内存的起始地址(要复制到哪里,相当于"新文件保存路径")
// - const void* Src:源内存的起始地址(要复制的内容在哪里,相当于"原文件路径")
// - SIZE_T Count:要复制的字节数(要复制多少数据,相当于"文件大小",单位是字节)
// - const修饰Src:表示不会修改源内存的数据(保护原始内容不被意外改动)
static FORCEINLINE void* BigBlockMemcpy(void* Dest, const void* Src, SIZE_T Count)
{
// 直接调用标准库的memcpy函数完成内存复制
// memcpy是C/C++的基础内存复制函数,功能是:从Src地址开始,复制Count个字节的数据到Dest地址
// 这里把memcpy的返回值直接返回(memcpy本身会返回Dest地址)
return memcpy(Dest, Src, Count);
}
// 关键概念解释:
// 1. 为什么叫"BigBlock"?
// 名字暗示它适合复制"大块内存"(比如几百KB、几MB的数据),但实际实现和普通memcpy一样
// 可能是为了代码可读性(让使用者知道这个函数用于处理大块数据),或预留后续优化空间(比如未来针对大块数据做特殊处理)
// 2. void*指针的意义:
// void*是"无类型指针",可以指向任何类型的内存(int、float、字符串等)
// 因为内存复制只关心"字节",不关心数据是哪种类型,所以用void*更通用(能复制任何类型的数据块)
// 3. 和普通复制的区别:
// 普通复制(比如逐个变量赋值)适合小数据,而内存复制(memcpy/BigBlockMemcpy)直接操作内存,速度极快
// 举例:复制一个1000个元素的数组,用循环逐个复制要1000次操作,用这个函数一次就能完成
// 4. 使用注意:
// - 目标地址(Dest)和源地址(Src)的内存空间不能重叠(否则可能复制出错误数据)
// - 目标地址必须有足够的空间(至少能容纳Count个字节,否则会导致内存溢出)到这就是GName的算法,很乱这里总结一下
比如现在的id是123456
它的算法是 *reinterpret_cast<FNameEntry*>(BlocksHandle.Block + 2 * Handle.Offset)
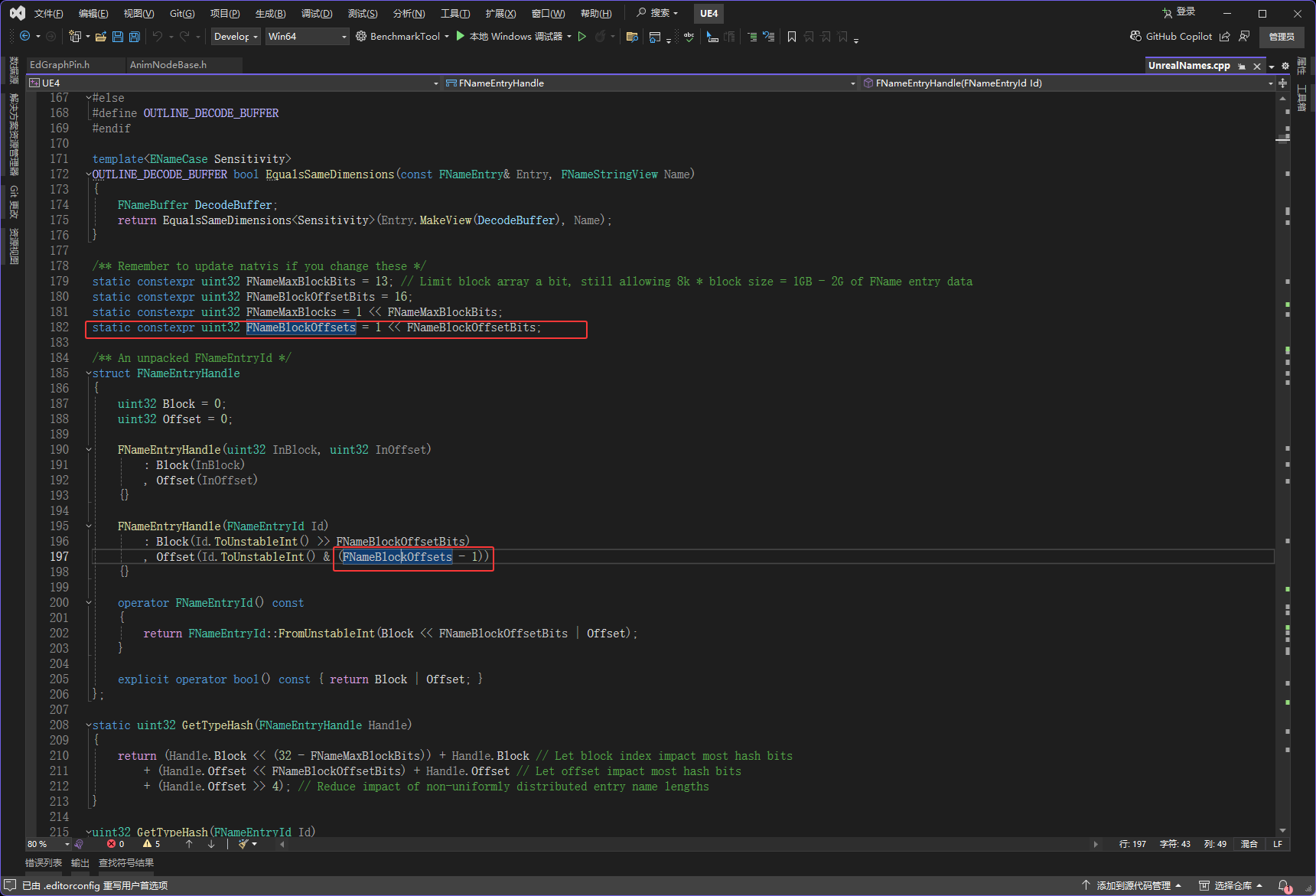
然后Handle.Block的值是id右移16位,也就是下图红框的代码,也就是把右边的2字节删除,然后当做Blocks的索引
Handle.Offset的值是id& (1左移16位的结果-1)也就是下图红框的代码
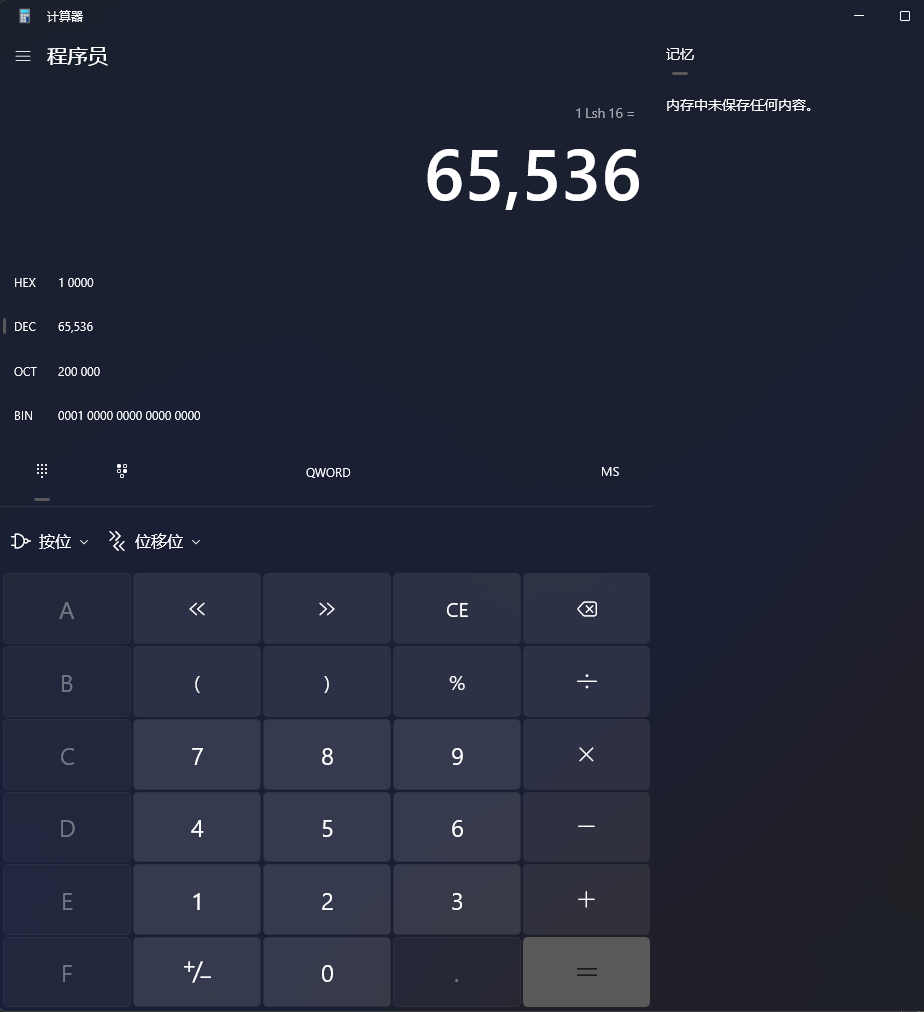
然后1左移16位的结果是65536,然后65536-1=65535
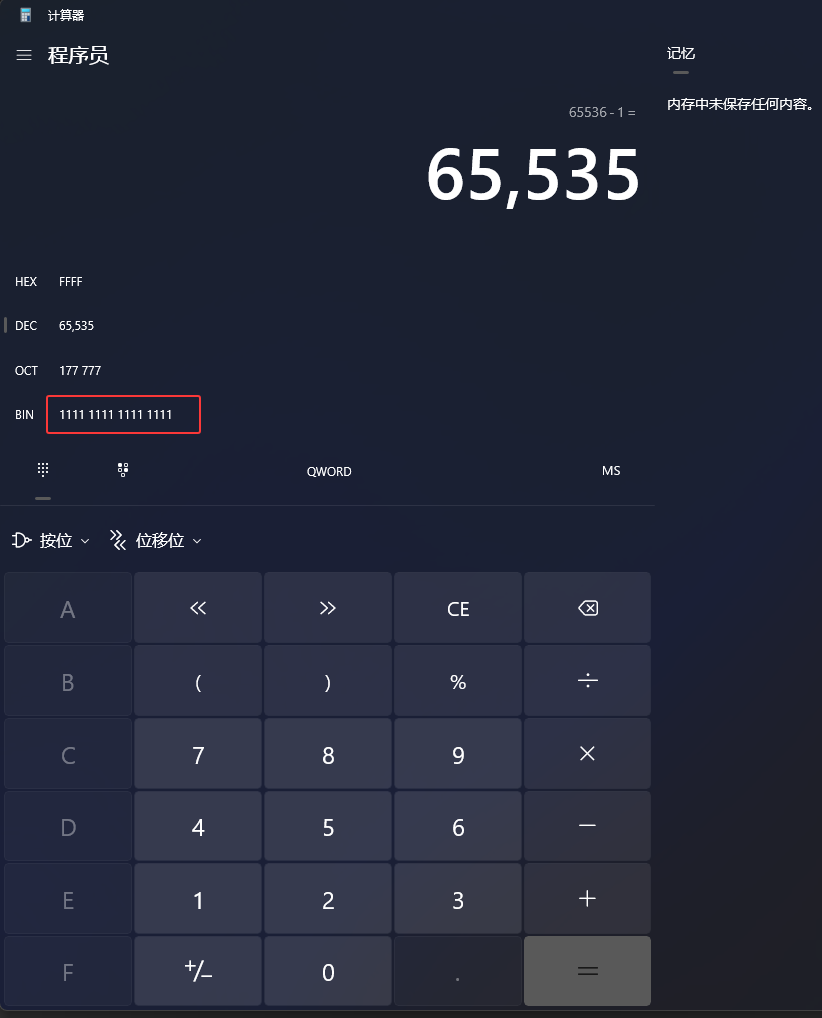
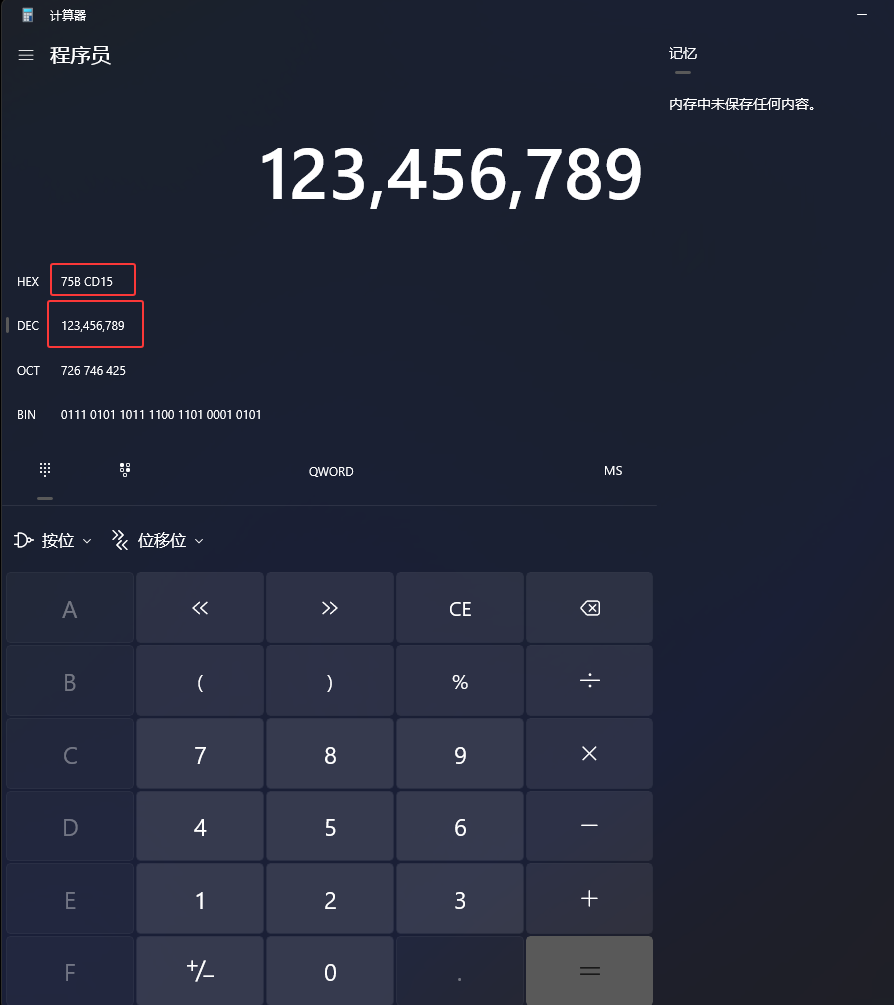
这个65535是2字节内存空间可以表达的最大数,如下图有16个1,8个1表示1字节,65535的十六进制是FFFF,4个F,从下图中可以看到(HEX就表示的是十六进制数)
id&65535的算法,比如现在的id是123456789,它的十六进制是75BCD15
然后进行&运算(也叫and运算)
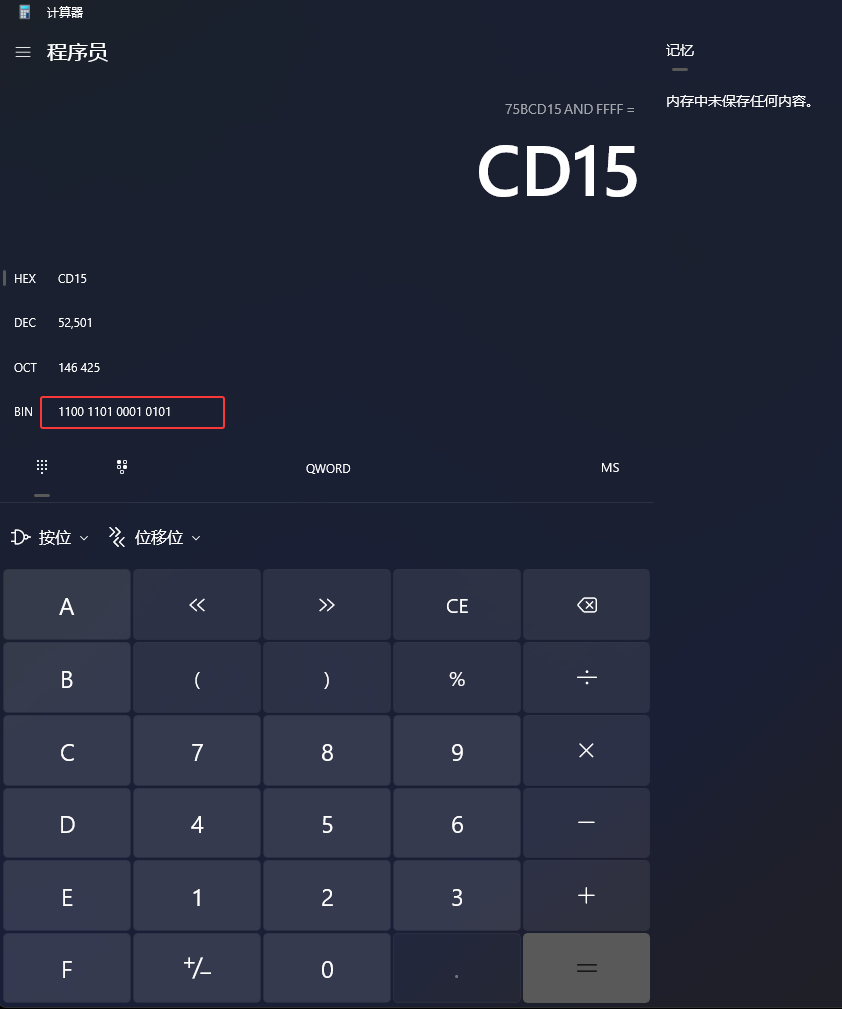
运算后,如下图红框它的二进制,123456789的二进制是0111 0101 1011 1100 1101 0001 0101,进行&运算后变成了1100 1101 0001 0101
&操作是两个二进制数比较都是1才是1,然后FFFF是一个2字节的数,123456789是一个3.5字节的数(二进制有28位,28除以8是3.5,注意这里只是手动计算的实例在计算机中它有内存对齐,它从28会变成32,也就是4字节,不会出现3.5字节这样的东西),也就是把下图红框的数据全部删除了,也就是保留了右边2字节的数据,也就是说Handle.Block保留左边的数据,Handle.Offset保留右边的数据
现在的算法是 *reinterpret_cast<FNameEntry*>(Blocksid\>\>16 + 2 * (id & 65535),然后它Blocksid\>\>16取出来的数据是一个内存地址,然后2 * (id & 65535)的结果是一个偏移,也就是说比如12345678,Blocks是一个大型图书馆,1234是图书馆里面的书架号,然后Blocks1234这个就是找到书架号(内存地址),然后5678乘以2是书在书架中的序号(位置)(内存地址+偏移),然后就能得到文字的数据了,然后再通过下图红框的判断来确定这个文字是什么编码,然后就能得到我们认识的文字了,到这应该就能理解GName的算法了,最开始说的那句话了