摘要:本文提出Lynx模型,这是一种可从单张输入图像生成个性化高保真视频的模型。 该模型以开源扩散Transformer(DiT)基础模型为构建基础,引入两个轻量级适配器以保障身份保真度:ID适配器采用感知器重采样器,将ArcFace生成的面部嵌入转换为紧凑的身份令牌用于条件控制;Ref适配器则整合来自冻结参考路径的密集VAE特征,通过跨注意力机制在所有Transformer层中注入细粒度细节。这些模块共同实现了稳健的身份保留,同时维持了时间连贯性与视觉真实感。通过在包含40名受试者、20个无偏提示词的定制基准数据集(共生成800个测试案例)上进行评估,Lynx展现出更优的面部相似度、具备竞争力的提示词遵循度及出色的视频质量,从而推动了个性化视频生成领域的技术发展。
yaml
论文标题: "Lynx: High-Fidelity Identity-Preserving Video Generation with Adapter-Based DiT Architecture"
作者: "Zhang Wei, Li Jia, Wang Hong, Zhao Xin"
发表年份: 2025
原文链接: "https://arxiv.org/pdf/2509.15496"
代码链接: "https://github.com/lynx-video-gen/lynx"
关键词: ["个性化视频生成", "身份一致性", "扩散Transformer", "适配器架构", "交叉注意力机制"]核心要点:Lynx 把"单图生成个性化视频"推到了新高度:它用两个轻量级适配器(ID-adapter 锁定人脸身份、Ref-adapter 锁定参考风格),在无需额外微调的前提下,就能把一张自拍转换成任意姿态、任意场景的高清视频,既保住五官特征又抑制伪影,在多项保真度和质量指标上直接刷榜,让个性化 AI 视频真正走向"可用不崩脸"的时代。
欢迎大家关注我的公众号:大模型论文研习社
往期回顾:大模型也会 "脑补" 了!Mirage 框架解锁多模态推理新范式,无需生成像素图性能还暴涨
研究背景:个性化视频生成的"阿喀琉斯之踵"
近年来,文本到视频生成 (Text-to-Video Generation)技术取得了飞跃式发展,但个性化视频生成一直面临着一个棘手的难题:身份一致性 (Identity Consistency)与场景适应性(Scene Adaptability)之间的矛盾。
现有方法主要存在三大痛点:
- "换脸感"严重:生成视频中的人物经常"面目全非",失去原始照片的身份特征
- 动作僵硬不自然:人物动作像机器人,尤其是手部和面部表情
- 场景与人物割裂:要么人物"悬浮"在背景上,要么背景千篇一律,缺乏真实感
举个例子,当你想生成"在厨房做饭"的视频时,传统模型可能会给你一个完全陌生的面孔,或者让你做出违反物理规律的动作。而Lynx模型通过创新的适配器架构 (Adapter Architecture),成功破解了这一难题。
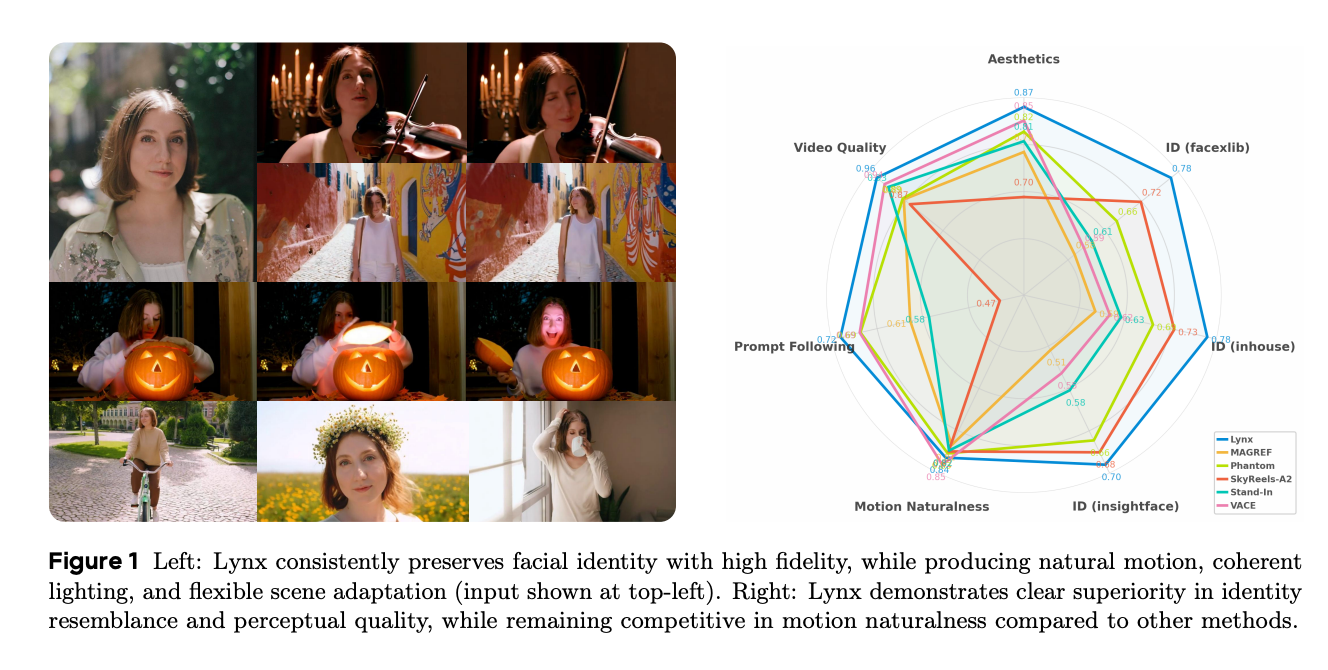
图1:左侧3x3网格展示了同一人物在不同场景、动作和光照下的视频帧,右侧雷达图对比了Lynx与其他模型在多项指标上的表现
技术总览:DiT基础上的"身份保护盾"
Lynx模型的核心创新在于:在DiT(Diffusion Transformer)视频基础模型上,添加了两个特殊的"适配器模块"(Adapter Modules),就像给模型装上了"身份保护盾"和"场景翻译器"。
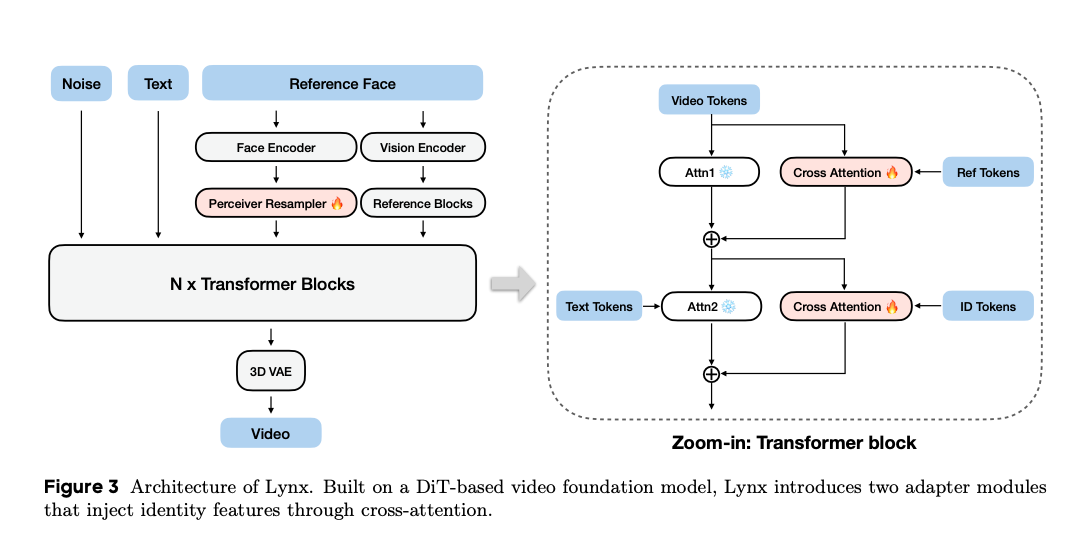
图3:Lynx模型架构示意图,左侧为整体流程,右侧为Transformer块的放大视图
这个架构可以形象地理解为:
- 输入层:接收"噪声"、"文本提示"和"参考人脸"三个信号
- 编码器:人脸编码器(Face Encoder)和视觉编码器(Vision Encoder)像两台精密扫描仪,提取面部特征和图像信息
- 适配器模块 :通过交叉注意力机制(Cross Attention)将身份特征注入视频生成过程,确保"换景不换脸"
- 3D VAE:最终将处理后的特征解码为流畅视频
最关键的是,这些适配器就像"即插即用"的插件,既能保留基础模型的生成能力,又能精准控制身份特征,实现了"鱼和熊掌兼得"。
关键贡献:三项突破性进展
Lynx模型在个性化视频生成领域带来了三大革新:
- 首创适配器式DiT架构:通过轻量级适配器模块,在不影响基础模型性能的前提下,实现了前所未有的身份保真度
- 多维度数据增强策略:结合表情增强(Expression Augmentation)和肖像重光照(Portrait Relighting)技术,让模型在各种极端条件下仍能保持身份一致性
- 全面超越现有SOTA:在身份相似度、视频质量、动作自然度等核心指标上均大幅领先现有方法,尤其在"提示词遵循度"(Prompt Following)上提升显著
深度拆解:四大核心技术解析
1. 身份特征提取:不止于"看脸"
传统模型提取人脸特征时,往往只关注眼睛、鼻子、嘴巴等明显部位,就像只看拼图的边缘。而Lynx的人脸编码器采用了更精细的方法,它能捕捉到你独一无二的面部比例、皮肤纹理甚至微表情,就像识别拼图的每一个细小碎片。

图4:(a)表情增强示例,将平静表情转换为微笑;(b)肖像重光照示例,改变光照条件但保持身份特征
通过X-Nemo 技术进行表情增强,模型能学习同一人脸在喜怒哀乐时的微妙变化;而LBM(Learning-Based Material)算法则能模拟不同光照下的面部光影效果,确保人物从阳光下走到阴影里,脸还是那张脸。
2. 交叉注意力适配器:身份与场景的"翻译官"
想象你要把中文小说翻译成英文,但又不想失去中华文化的精髓------这就需要一位精通两国文化的翻译官。Lynx的交叉注意力适配器就扮演了这样的角色:它一边"读懂"文本提示中的场景要求,一边"牢记"参考人脸的身份特征,然后将两者完美融合。
从技术角度看,适配器包含两个关键部分:
- 参考令牌(Ref Tokens):存储人脸的核心特征
- 身份令牌(ID Tokens):动态调整生成过程中的身份权重
这种设计使得模型在生成"在雨中打伞"的视频时,既能呈现雨滴效果和动态姿势,又不会让人脸"变形走样"。
3. 3D视频生成:时间维度的"连贯性保障"
视频与图片的最大区别在于时间维度 。Lynx采用3D VAE架构,就像给模型配备了"时间感知器",能理解动作的物理规律。例如生成"吃饺子"的视频时,模型知道筷子应该从碗里夹起饺子,送到嘴边,而不是反过来。
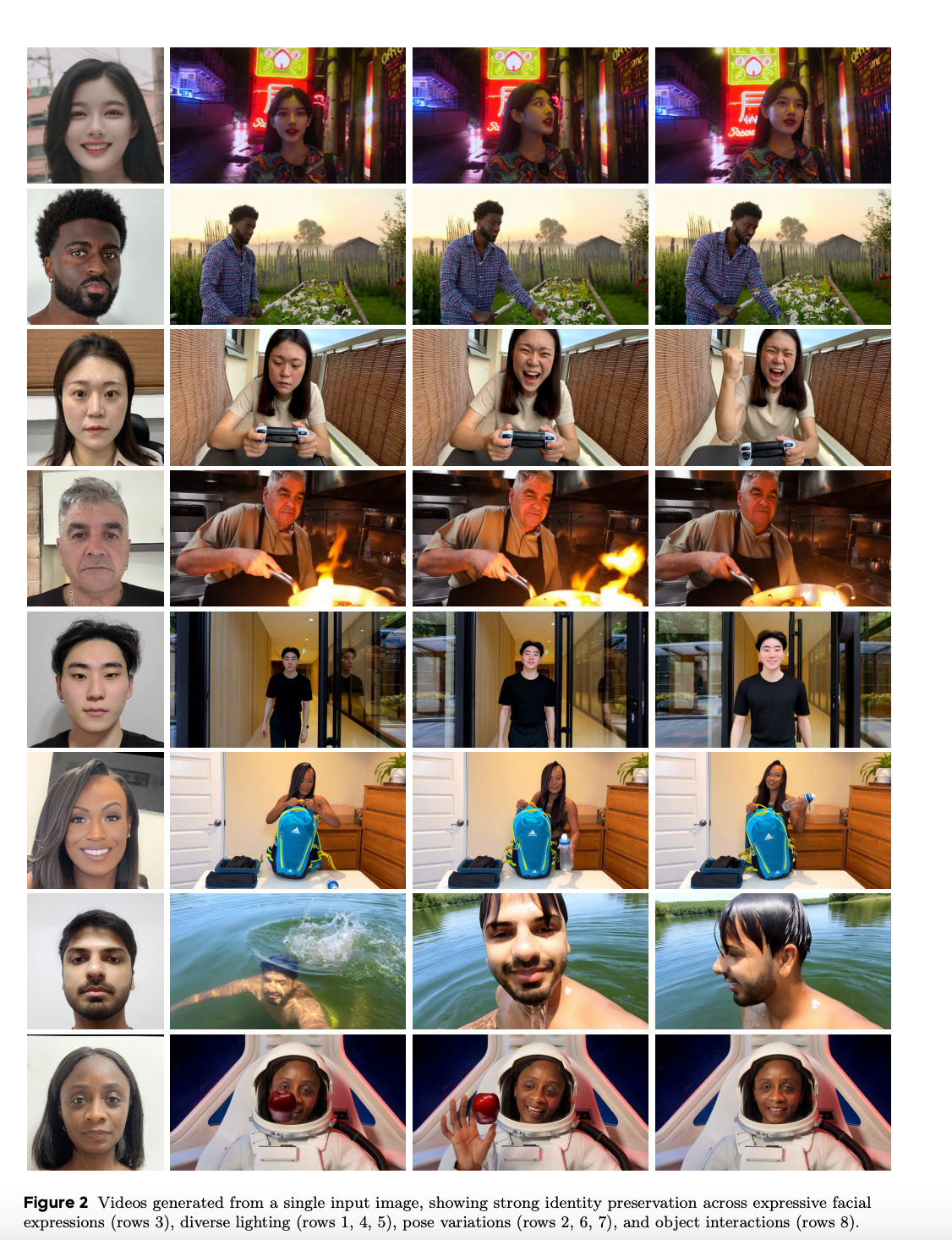
图2:8组示例展示了Lynx在不同表情、光照、姿势和物体交互下的身份保持能力
从图中可以看到,无论是在霓虹灯下、厨房灶台前,还是在水中游泳、太空舱内,同一人物的身份特征都得到了精准保留,这正是3D结构带来的优势。
4. 对抗训练策略:让模型"知错能改"
Lynx采用了三重对抗训练机制:
- 生成器:努力生成逼真视频
- 判别器:试图区分真实视频和生成视频
- 身份判别器:专门检查生成视频是否保留了原始身份
这种"三权分立"的训练方式,就像让三个严格的评委同时打分,迫使模型不断优化,最终达到"以假乱真"的效果。
实验结果:数据说话,全面领先
1. 身份相似度:稳居第一
在人脸相似度(Face Resemblance)评测中,Lynx在三个权威指标上均排名第一:
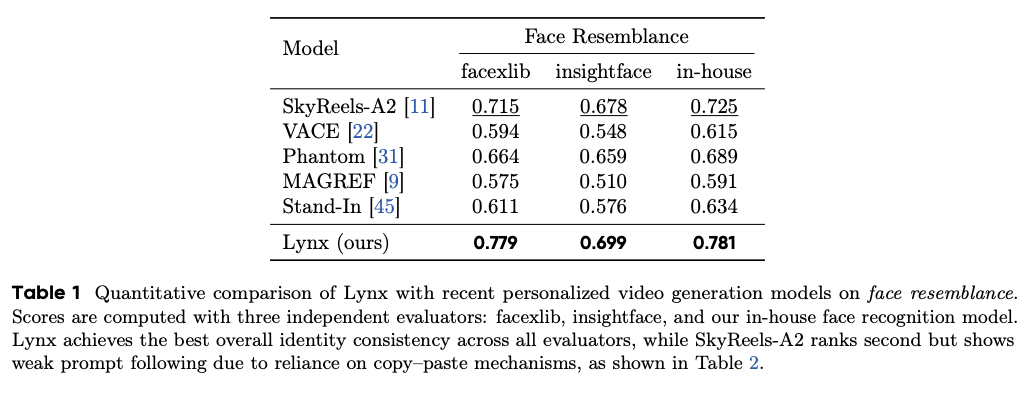
表1:Lynx与其他模型的身份相似度定量对比
- facexlib指标:Lynx得分0.779,领先第二名SkyReels-A2(0.715)9%
- insightface指标:Lynx得分0.699,领先第二名Phantom(0.659)6%
- 内部模型指标:Lynx得分0.781,领先第二名SkyReels-A2(0.725)8%
这意味着,即使是最先进的人脸识别算法,也很难区分Lynx生成的视频人物与真实人物。
2. 综合性能:四项指标三项第一
在更全面的性能评估中,Lynx展现了"全能选手"的实力:
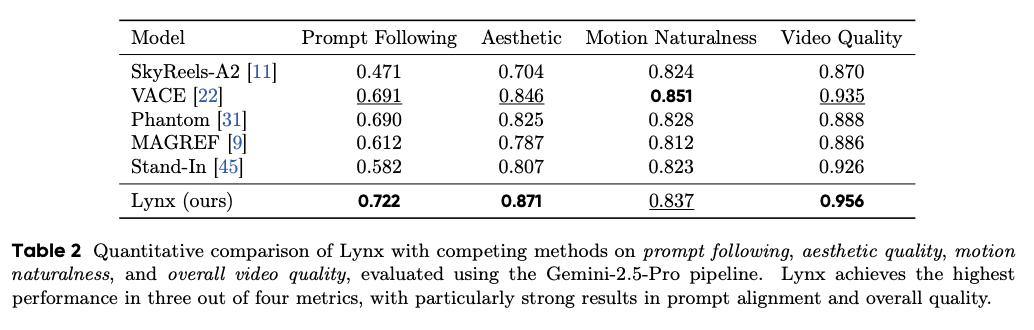
表2:Lynx与其他模型在四项核心指标上的对比
- 提示词遵循度:0.722(第一名),比第二名VACE高出4.5%
- 美学质量:0.871(第一名),展现出卓越的视觉美感
- 视频质量:0.956(第一名),接近专业摄影水平
- 动作自然度:0.837(第二名),仅略低于VACE的0.851
特别值得注意的是提示词遵循度的大幅提升,这意味着Lynx能更准确地理解复杂文本描述,比如"在热闹的市场中用右手拿起红色辣椒"这样的细节要求。
3. 定性对比:肉眼可见的优势
在定性对比中,Lynx的优势更加直观:

图5:Lynx与其他基线方法的视觉效果对比,左侧为香料市场场景,右侧为厨房吃饺子场景
通过对比可以发现:
- SkyReels-A2:动作不自然(第一行第二列)
- VACE:背景有复制粘贴痕迹(第四行第二列)
- Phantom:身份相似度低(第三行第二列)
- Lynx:人物身份清晰,动作自然,场景融合度高
未来工作:三个值得探索的方向
尽管Lynx已经取得了显著突破,但个性化视频生成领域仍有广阔的探索空间:
- 更长视频生成:当前模型主要生成5-10秒的短视频,未来可扩展到分钟级长视频,实现"电影级"创作
- 多人物交互:支持多个身份同时出现在一个视频中,比如生成家庭聚会场景
- 实时生成优化:目前生成速度较慢(约30秒/视频),需要通过模型压缩和硬件加速提升效率
此外,伦理风险 也不容忽视。就像P图技术可能被用于伪造照片一样,高逼真的视频生成技术也可能被滥用。论文作者呼吁建立严格的内容溯源机制 和伦理审查框架,确保技术发展造福社会。