SimpleBEV:改进的激光雷达-摄像头融合架构用于三维目标检测
论文网址: SimpleBEV
摘要
越来越多的研究工作将激光雷达(LiDAR)与摄像头信息进行融合,以提升自动驾驶系统的三维目标检测性能。近期,一种简单而高效的融合框架在三维目标检测上取得了优异的性能,该框架在统一的鸟瞰图(BEV, Bird's-Eye-View)空间中融合了激光雷达与摄像头特征。本文提出了一种名为 SimpleBEV 的激光雷达-摄像头融合框架,用于高精度的三维目标检测。该方法遵循基于 BEV 的融合范式,并分别改进了摄像头与激光雷达的编码器。具体而言,我们通过级联网络进行基于摄像头的深度估计,并利用来自激光雷达点的深度信息对估计结果进行校正。同时,我们引入了一个辅助分支,仅使用基于摄像头 BEV 的特征进行三维目标检测,以便在训练阶段更充分地挖掘摄像头信息。除此之外,我们通过融合多尺度稀疏卷积特征对激光雷达特征提取器进行了改进。实验结果表明,所提出的方法具有显著的有效性。在 nuScenes 数据集上,我们的方法取得了 77.6% 的 NDS 精度,在三维目标检测任务上展现了优越的性能。
引言
三维目标检测在自动驾驶感知系统中发挥着不可或缺的作用,其任务是在三维交通环境中识别和定位目标对象。为了获得充分且准确的感知结果,无人驾驶车辆通常配备多种传感器。在所有车载传感器中,摄像头与激光雷达(LiDAR)传感器受到了广泛研究。激光雷达点云能够提供精确的定位与几何信息,而摄像头则能够提供丰富的语义信息。由于这两类传感器在特性上具有互补性,已有大量研究工作尝试融合激光雷达与摄像头数据,以提升三维目标检测的性能。
近年来,基于鸟瞰图(BEV, Bird's-Eye-View)的感知方法受到了广泛关注,因为它能够以直观的方式表示驾驶场景,并且在多视角摄像头以及不同类型传感器的融合中具有良好的适配性。一系列方法基于 Transformer 架构,通过在激光雷达特征与图像特征之间执行交叉注意力机制来实现 LiDAR 与摄像头信息的融合。与之不同的是,一些工作则基于对齐的 BEV 特征图进行 LiDAR-摄像头融合。尽管结构简单,基于 BEV 的融合框架依然取得了优异的检测性能。在本文中,我们基于 BEVFusion构建了一种 LiDAR-摄像头融合框架,并进一步挖掘摄像头信息,同时改进了激光雷达特征提取器。
为了更好地利用摄像头信息,我们增强了深度估计模块,并引入了一个辅助检测分支。深度估计模块在基于摄像头的三维目标检测中起着至关重要的作用。准确的深度估计结果有助于在融合 LiDAR 与摄像头 BEV 特征图时实现更好的特征对齐。为此,我们提出了一种两阶段级联网络,以提升基于图像的深度估计性能,并利用来自 LiDAR 点的深度信息对估计的深度图进行校正。在融合 LiDAR 与摄像头数据时,LiDAR 模态相较于摄像头模态往往占据主导作用。为了在整个模型的联合训练过程中进一步挖掘摄像头信息,我们引入了一个辅助分支,该分支仅利用摄像头 BEV 特征来执行三维目标检测。
此外,我们通过融合多尺度稀疏卷积特征对 LiDAR 特征提取器进行了改进。为了降低计算量和内存开销,首先将三维体素特征编码到 BEV 空间中。随后,这些多尺度的 LiDAR-BEV 特征图被融合,以生成具有更强表达能力的 BEV 特征图。
实验结果表明,引入的辅助分支以及改进后的摄像头/激光雷达特征提取器能够有效提升三维目标检测的性能。此外,结合模型集成与测试时增强(test-time augmentation)策略,我们的模型在 nuScenes 榜单 上取得了最佳的 NDS 分数。
我们的主要贡献总结如下:
- 我们构建了一个用于三维目标检测的多模态检测模型。该模型遵循 BEVFusion的框架,但在训练阶段引入了一个辅助分支,以更充分地利用摄像头信息。此外,我们改进了基于摄像头的深度估计器和基于 LiDAR 的特征编码器,为多模态融合提供了更有效的特征。
- 我们提出的方法 SimpleBEV 在 nuScenes 数据集 上实现了最先进的三维目标检测性能。
相关工作
基于Camera的3D目标检测 早期的一些工作被提出用于单目三维目标检测。通常,这类方法首先基于图像进行二维目标检测,然后在第二阶段将二维检测结果投影到三维空间。然而,这种直观的检测策略在处理来自环视摄像头的输入时,需要依赖复杂的后处理才能获得稳健的结果。近年来,基于视觉的 BEV 感知方法在工业界和学术界都受到了极大关注。这类方法将来自多张图像的特征转换到一个统一的 BEV 坐标系中。BEV 特征可以直接输入到许多下游任务中,并且更适合进行多模态融合。根据特征转换方式的不同,这些方法大致可以分为两类:"基于几何的转换"和"基于网络的转换"。其中,具有代表性的"基于几何"的方法采用显式的深度估计,并依据物理原理将提取的特征投影到三维空间。有些利用 LiDAR 数据来监督深度预测训练,有些则引入时间线索来提升三维目标检测性能。与此不同,"基于网络"的方法则通过神经网络隐式地将图像特征映射到 BEV 空间。大量工作使用 Transformer 将图像特征转换到 BEV 空间,它们普遍采用 Deformable Transformer 来降低计算和内存开销。
基于LiDAR的3D目标检测 主流的三维目标检测方法可以分为 基于点的方法和 基于体素的方法。基于点的方法直接对不规则的 LiDAR 点进行操作,并利用其空间信息。与之不同,基于体素的方法则首先将无序的 LiDAR 点按照预定义的网格大小转换为体素表示,然后在规则化的体素上应用二维/三维卷积神经网络(2D/3D CNNs)以获得检测结果。近年来,一些方法将三维体素网络与基于点的网络结合起来,以获得更具代表性的特征。
多模态3D目标检测 LiDAR 与摄像头信息具有互补性。LiDAR 点云可以为目标定位提供精确的空间信息,而图像则提供丰富的上下文信息以辅助目标分类。为了为自动驾驶车辆获取准确的周围环境信息,许多研究者致力于有效地融合摄像头和 LiDAR 的信息,以实现高精度的三维目标检测。根据融合操作方式,摄像头--LiDAR 融合方法可分为三类:"早期融合(early-fusion)"、"中间融合(intermediate-fusion)"和"后期融合(late-fusion)"。
"早期融合"方法主要先处理图像信息(如特征 Pointaugmenting、语义标签 Pointpainting 或边界框),然后将结果输入到基于 LiDAR 的分支以获得最终检测结果。这类方法通常需要额外的复杂二维网络,并且在目标 LiDAR 点稀少时检测性能会受影响。
"后期融合"方法 Clocs 则融合来自独立摄像头和 LiDAR 分支的检测结果。尽管这种方法效率较高,但限制了对不同模态丰富且互补信息的充分利用。
"中间融合"方法在工业界和学术界获得了最多关注。早期研究工作一些方法基于 LiDAR 或 LiDAR-摄像头信息生成三维目标候选框,并融合基于候选框提取的 LiDAR 与摄像头特征。近年来,受到视觉 BEV 表示的启发,许多 BEV 相关的融合方法被提出。Bevfusion 使用 LSS 提取摄像头 BEV 特征,并将其与 LiDAR BEV 特征融合。Deepfusion 使用 LiDAR 特征作为查询,将图像与 LiDAR 特征融合。Transfusion 构建了一个两阶段管线:第一阶段生成初始三维边界框,第二阶段将对象查询与图像特征关联并融合,以获得更优的检测结果。一些方法将图像与 LiDAR 特征视为 token,直接使用 Transformer 实现三维目标检测。为了在融合过程中进一步利用摄像头信息,Deepinteraction 引入两个独立分支执行表示交互,并采用顺序模块进行预测交互。我们的方法基于 BEVFusion 架构,并强化了摄像头与 LiDAR 分支,以实现更高性能的三维目标检测。
方法
我们设计了一个基于摄像头和 LiDAR 数据的多模态三维目标检测器 SimpleBEV,其框架如图 1 所示。首先,我们介绍与摄像头相关的分支和 LiDAR 分支。摄像头相关分支包括一个摄像头分支,用于提取图像特征并将其投影到 BEV 空间,以及一个辅助分支,用于在训练阶段更充分地利用摄像头信息。随后,我们介绍 BEV 编码器和用于最终检测任务的检测头。
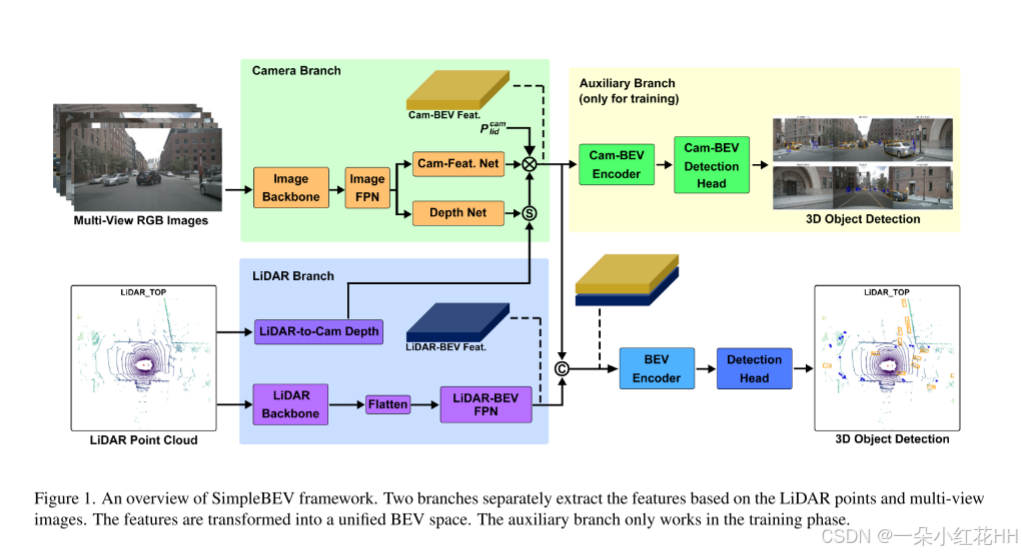
摄像头相关分支
摄像头分支 输入的多视角图像首先通过共享的图像编码器编码为深度特征,该编码器由用于特征提取的图像骨干网络和用于融合多尺度特征的简单 FPN 颈部组成。具体而言,我们采用 ConvXt-Tiny 作为图像骨干网络,以提取具有代表性的图像特征。来自图像骨干网络不同阶段的特征图被送入 FPN 颈部,以充分利用多尺度表示。随后,来自指定层的特征图被用于生成摄像头 BEV 特征图。
给定第 i 张图像的特征图 F cam i ∈ R H × W × C im F^{i}{\text{cam}} \in \mathbb{R}^{H \times W \times C{\text{im}}} Fcami∈RH×W×Cim,我们按照 LSS 中的类似流程将图像特征转换到 BEV 空间。首先,图像特征被用于估计每个像素的深度分布 D cam i ∈ R H × W × D D^{i}{\text{cam}} \in \mathbb{R}^{H \times W \times D} Dcami∈RH×W×D,其中 D D D 表示离散化深度区间的数量。然后,每个图像特征按照不同深度区间的概率加权,并投影到三维坐标中,形成视锥(frustum)特征。来自多摄像头的三维特征都被转换到 LiDAR 坐标系中,并通过体素化(voxelization)以及沿高度方向的求和池化(sum pooling)生成摄像头 BEV 特征图 F cam B ∈ R X × Y × C cam F^{B}{\text{cam}} \in \mathbb{R}^{X \times Y \times C_{\text{cam}}} FcamB∈RX×Y×Ccam。其中, X X X 和 Y Y Y 分别表示 BEV 坐标系中 x 轴和 y 轴方向的网格大小。
在上述特征转换过程中,深度估计在基于摄像头的三维目标检测中起着关键作用。更精确的深度预测有助于摄像头 BEV 特征与 LiDAR BEV 特征的对齐。为了提高深度估计的精度,我们对深度估计网络进行了改进,并引入 LiDAR 数据以生成更精确的深度。该流程如图 2 所示。我们构建了一个两阶段级联结构以获得基于摄像头的深度图 D cam i D^{i}_{\text{cam}} Dcami。第一阶段输出的深度图与第一阶段的特征图进行拼接,融合后的特征图被输入到第二阶段。
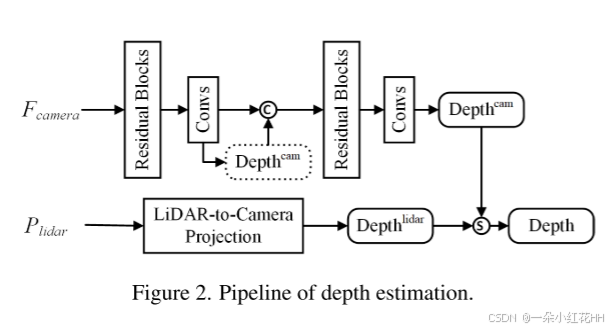
同时,LiDAR 点被转换到第 i 个摄像头坐标系,并投影到图像坐标中,形成 LiDAR 深度图 D lid i ∈ R H × W × D D^{i}{\text{lid}} \in \mathbb{R}^{H \times W \times D} Dlidi∈RH×W×D。考虑到投影到特征图上的点较为稀疏,我们引入了掩码图 M lid i ∈ { 0 , 1 } H × W M^{i}{\text{lid}} \in \{0,1\}^{H \times W} Mlidi∈{0,1}H×W 来表示特征图的像素是否由 LiDAR 点标记(标记为 1)或未标记(标记为 0)。最终深度图中像素 ( u , v ) (u,v) (u,v) 的深度计算公式为:
D i ( u , v ) = D lid i ( u , v ) ⋅ M lid i ( u , v ) + D cam i ( u , v ) ⋅ ( 1 − M lid i ( u , v ) ) D^{i}(u, v) = D^{i}{\text{lid}}(u, v) \cdot M^{i}{\text{lid}}(u, v) + D^{i}{\text{cam}}(u, v) \cdot (1 - M^{i}{\text{lid}}(u, v)) Di(u,v)=Dlidi(u,v)⋅Mlidi(u,v)+Dcami(u,v)⋅(1−Mlidi(u,v))
换句话说,最终深度图是通过用基于图像特征的估计深度图填充稀疏 LiDAR 深度图的空洞生成的。融合后的深度图用于图像特征投影。
辅助分支 为了进一步利用摄像头信息,我们引入了一个辅助分支,该分支在训练阶段被激活。摄像头 BEV 编码器对摄像头分支生成的 BEV 特征进行编码。我们引入了一个基于无锚点(anchor-free)的检测头来实现三维目标检测任务。摄像头 BEV 编码器由多层卷积和多尺度特征融合模块组成。辅助检测头沿用 CenterHead 的结构,仅使用摄像头 BEV 特征执行三维目标检测。
LiDAR分支
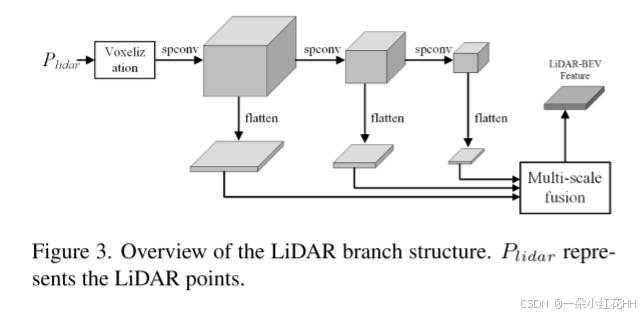
LiDAR 分支遵循与 SECOND 类似的流程来提取三维特征,并融合来自不同阶段的多尺度特征。其框架如图 3 所示。首先,将原始点云转换为体素特征。然后,对这些特征依次应用多个稀疏三维卷积层,以生成多尺度三维特征。为了增强基于 LiDAR 的特征对多尺度目标的捕捉能力,我们引入了多尺度特征融合策略。来自不同阶段的多尺度三维特征首先被转换为多个二维 BEV 特征。我们应用多个三维卷积压缩 z 维度,并沿 z 维拼接特征,将三维特征转换为二维 BEV 特征。随后,利用多次上采样和卷积操作融合多个 BEV 特征图。最终的 LiDAR-BEV 特征 F lid B ∈ R X × Y × C lid F^{B}{\text{lid}} \in \mathbb{R}^{X \times Y \times C{\text{lid}}} FlidB∈RX×Y×Clid 被送入摄像头--LiDAR 特征融合模块。
BEV 编码器与检测头
融合后的 BEV 特征 F fuse B ∈ R X × Y × C fuse F^{B}{\text{fuse}} \in \mathbb{R}^{X \times Y \times C{\text{fuse}}} FfuseB∈RX×Y×Cfuse 通过将摄像头 BEV 特征 F cam B F^{B}{\text{cam}} FcamB 与 LiDAR BEV 特征 F lid B F^{B}{\text{lid}} FlidB 拼接生成。随后,融合特征在 BEV 空间中进一步编码。BEV 编码器通过多层卷积增强 BEV 特征,并融合多尺度特征。
我们分别采用成熟的基于 Transformer 的检测头和中心热图(center heatmap)检测头来执行最终检测任务和辅助检测任务。具体而言,基于 Transformer 的检测头使用融合后的 BEV 特征,而中心热图检测头则利用摄像头 BEV 特征。
训练
模型通过最小化以下损失的和进行训练:
L = L fusion + L aux + L depth L = L_{\text{fusion}} + L_{\text{aux}} + L_{\text{depth}} L=Lfusion+Laux+Ldepth
其中, L fusion L_{\text{fusion}} Lfusion 表示基于融合 BEV 特征的检测损失,我们采用与Transfusion相同的损失函数; L aux L_{\text{aux}} Laux 表示仅使用摄像头 BEV 特征的辅助分支检测损失; L depth L_{\text{depth}} Ldepth 是用于训练摄像头分支深度网络的深度损失。深度的真实值来自 LiDAR 数据。
实验
结论
在本文中,我们提出了一种高效的多模态融合框架 SimpleBEV,用于在自动驾驶环境中进行三维目标检测。该方法沿用了基于 BEV 的融合架构,将 LiDAR 与摄像头特征融合到统一的 BEV 空间中。实验结果验证了我们方法的有效性。改进后的摄像头深度估计模块和多尺度 LiDAR-BEV 融合模块能够显著提升检测性能。此外,引入的辅助分支在训练阶段有助于充分利用摄像头信息。未来,我们计划将更多传感器集成到该框架中,并探索基于融合特征的更多下游应用。