文章目录
- [电商项目机器学习:基于 Python 电商爬虫可视化分析预测系统](#电商项目机器学习:基于 Python 电商爬虫可视化分析预测系统)
-
- 一、项目概述
- 二、项目说明
- 三、研究意义
- 四、系统总体架构设计
- 五、需求分析
- 六、系统设计
- 七、系统技术架构分析
- [八、 线性回归算法](#八、 线性回归算法)
- 九、核心功能模块实现
- 数据可视化模块功能实现
- 十、项目部分截图
- 八、总结
- 八、项目结语(源码文档等资料)
电商项目机器学习:基于 Python 电商爬虫可视化分析预测系统
一、项目概述
在电子商务蓬勃发展的数字化时代,电商平台积累了海量商品与用户行为数据,但传统营销策略难以满足消费者个性化需求。本项目设计实现了一套基于 Python 的电商爬虫可视化分析预测系统,通过Django+Vue 前后端分离架构,整合数据采集、可视化分析、机器学习预测及数据管理等核心能力。系统依托淘宝爬虫获取实时商品数据,借助 Echarts 等工具实现数据直观呈现,通过线性回归算法预测用户购买行为,最终为电商企业提供精准营销决策支持与个性化服务方案,助力提升用户体验与销售增长。
二、项目说明
系统覆盖从数据获取到决策支撑的全流程,核心模块功能如下:
在项目的数据采集模块,基于 Python 爬虫技术,定向抓取淘宝平台商品数据(含商品类型、名称、价格、销量、店铺信息、包邮状态等),通过数据清洗后存储至 MySQL 数据库,为后续分析提供基础数据源。在项目的数据可视化分析模块,现多维度图表展示,包括商品类型占比饼图、销量趋势折线图、价格分布柱状图及评论关键词云图等,直观呈现数据特征与市场趋势。在项目的机器学习模块,价格、类型、地域、包邮状态等特征训练模型,预测用户购买数量,为个性化推荐与库存优化提供数据支撑。在用户管理,模块实现用户注册、登录及权限控制功能,保障系统数据安全与个性化使用体验。在数据管理模块方面,提供商品数据、用户数据的增删改查操作,支持数据批量导入导出,满足运营者数据维护需求。系统通过模块化设计实现高内聚低耦合,前端界面简洁易用,后端数据处理高效稳定,可适配电商企业精准运营的实际需求。
三、研究意义
该系统具备显著的理论与实践价值,通过爬虫技术实现商品数据实时采集,解决电商数据分散问题;线性回归预测模型提升购买行为预判准确性,助力精准营销与库存优化;可视化分析降低数据解读门槛,为运营决策提供直观依据,最终帮助企业提升转化率与用户忠诚度。通过整合 Django+Vue 前后端分离、爬虫、机器学习、数据可视化等多领域技术,形成完整的电商数据处理链路,为同类系统开发提供可复用的技术方案。在行业价值领域,粗放式营销" 向 "数据驱动型运营" 转型,通过个性化服务设计提升行业整体服务水平,助力数字经济下电商行业的创新发展。
四、系统总体架构设计
总体框架
系统采用分层设计思想,自上而下分为前端展示层、后端服务层、数据处理层、数据存储层四层架构:
- 前端展示层:基于 Vue 框架构建,包含可视化大屏、预测界面、用户中心、数据管理界面等,通过 Echarts 实现图表渲染与交互。
- 后端服务层:以 Django 为核心,提供 API 接口服务,负责请求处理、业务逻辑实现(如爬虫调度、模型调用、权限校验)。
- 数据处理层:涵盖数据清洗(缺失值填充、异常值处理)、特征工程、线性回归模型训练与预测、可视化数据加工等功能。
- 数据存储层:采用 MySQL 数据库存储商品数据、用户数据及系统配置信息,通过 CSV 文件实现临时数据流转。
技术架构
| 技术层级 | 核心技术 / 工具 | 功能作用 |
|---|---|---|
| 前端技术 | Vue、Echarts、Bootstrap | 界面构建、数据可视化渲染、响应式布局 |
| 后端技术 | Python、Django | 后端服务开发、API 接口设计、业务逻辑处理 |
| 数据采集 | Requests 库、Selenium | 模拟浏览器请求、淘宝商品数据抓取 |
| 数据存储 | MySQL、Navicat Premium 15 | 数据持久化存储、数据库可视化管理 |
| 数据分析 | Pandas、NumPy | 数据清洗、特征处理、统计分析 |
| 机器学习 | Scikit-learn | 线性回归模型训练、预测与评估 |
| 开发工具 | PyCharm | Python 项目开发、调试与管理 |
五、需求分析
在设计系统时,除了满足功能性需求外,还必须考虑到用户体验、性能、安全性等非功能性方面的需求。系统的用户界面应当简洁明了、易于操作,以提升用户体验,因此对于前端设计需要注重响应式布局、友好的交互设计,并兼容不同终端设备。系统应具备良好的性能,能够高效处理大规模数据,并在数据采集、分析和预测过程中保持稳定性和可靠性,因此需要优化数据库设计、请求处理和算法性能。系统的安全性也是不容忽视的,必须采取有效措施保护用户隐私和数据安全,例如加密存储、访问控制等,同时防范常见的网络攻击和数据泄露风险。最后,在可视化分析方面,系统应当支持多种图表展示和数据可视化技术,如echarts、matplotlib等,以便用户直观地理解数据,并且可以生成各种形式的报告和可视化结果。通过对非功能性需求的充分分析和考量,可以有效地提升电商商品数据分析可视化预测系统的整体质量和用户满意度。
六、系统设计
经过系统需求分析,系统总体结构设计如图所示。
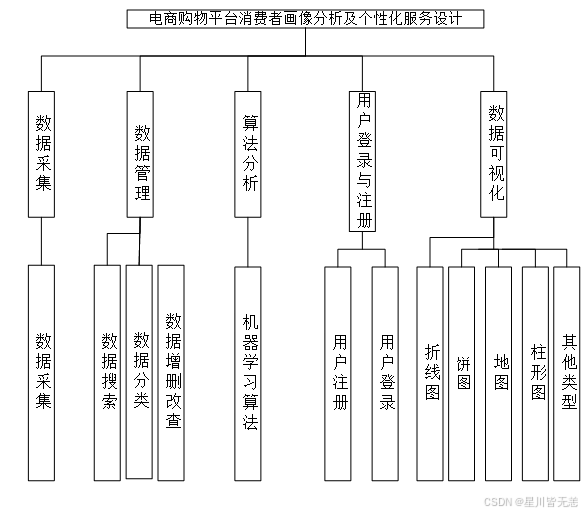
七、系统技术架构分析
系统总体架构示意图如下所示。
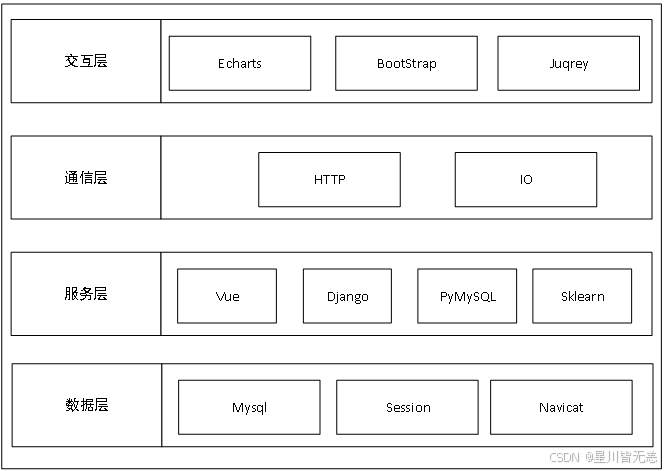
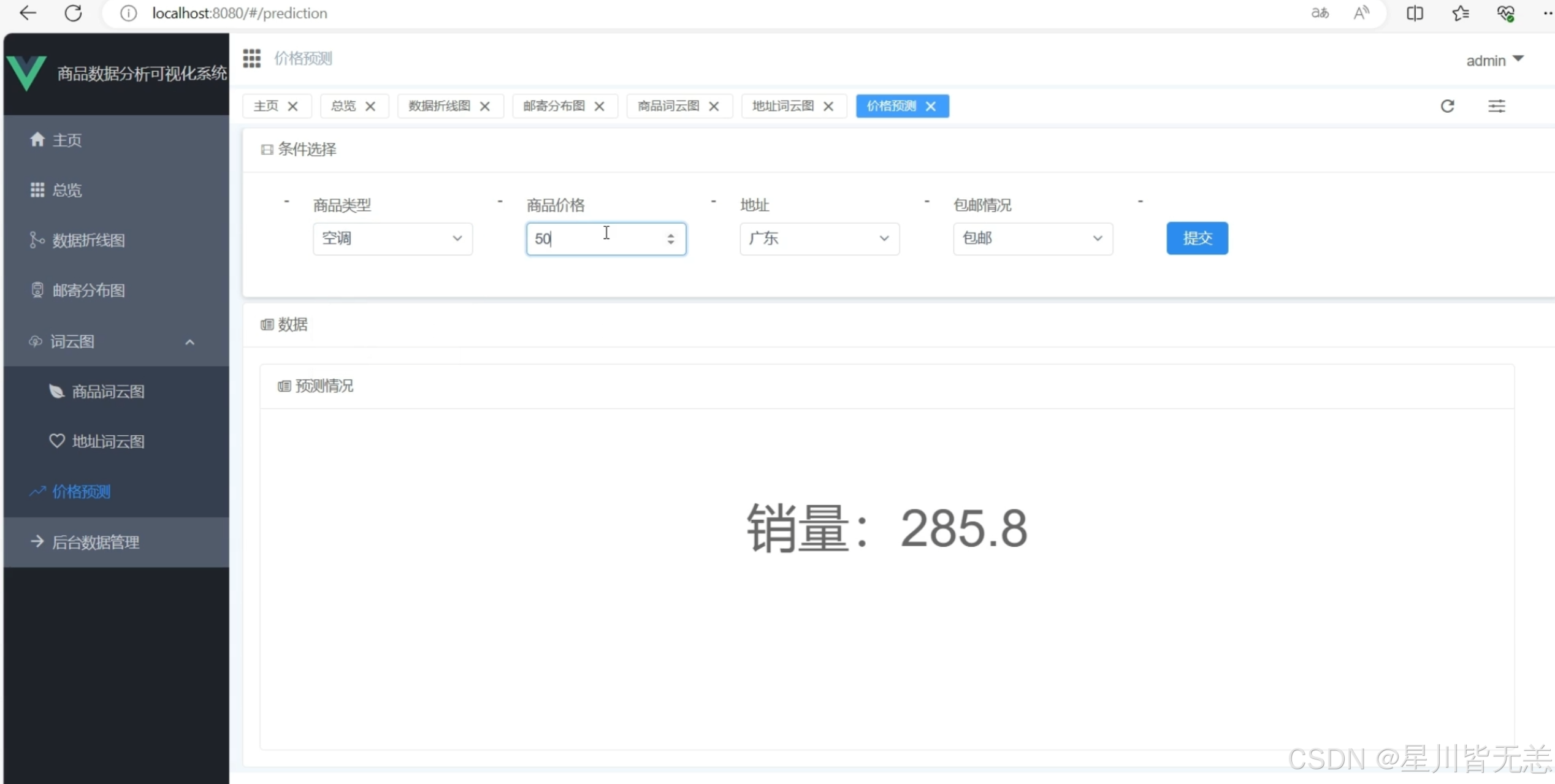
八、 线性回归算法
线性回归算法是系统预测功能的核心,通过建立商品特征与用户购买数量的线性关系模型,实现购买行为精准预判,具体实现流程如下:
算法原理与流程
- 数据预处理:从 MySQL 数据库提取商品数据,通过 Pandas 填充缺失值(如 "暂无" 替代空值),筛选核心特征(商品类型、价格、地址、包邮状态)并转换为数值型向量。
- 特征工程:对分类特征(如商品类型、地址)进行编码,对连续特征(如价格)进行标准化,构建模型输入数据集。
- 模型训练:划分训练集(80%)与测试集(20%),采用普通最小二乘法最小化残差平方和,训练线性回归模型。
- 模型评估:通过均方误差(MSE)、均方根误差(RMSE)评估模型性能,迭代优化参数。
- 预测应用:接收用户输入的商品特征,调用训练好的模型输出购买数量预测结果,支撑个性化推荐场景。
部分核心代码
python
# 2. 特征处理(分类特征编码)
le_type = LabelEncoder()
le_address = LabelEncoder()
le_delivery = LabelEncoder()
df['type_encoded'] = le_type.fit_transform(df['type'])
df['address_encoded'] = le_address.fit_transform(df['address'])
df['delivery_encoded'] = le_delivery.fit_transform(df['isFreeDelivery'])
# 3. 特征与目标变量划分
X = df[['type_encoded', 'price', 'address_encoded', 'delivery_encoded']]
y = df['buy_len'] # 目标变量:购买数量
# 4. 数据集拆分与模型训练
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
lr_model = LinearRegression()
lr_model.fit(X_train, y_train)
# 5. 模型评估
y_pred = lr_model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print(f"模型均方误差(MSE):{mse:.2f}")九、核心功能模块实现
1. 数据采集模块
功能说明
基于 Requests 与 Selenium 实现淘宝商品数据爬取,支持按关键词搜索,遍历多页结果,提取商品类型、名称、价格、销量、店铺名、地址、包邮状态等信息,通过 CSV 临时存储后导入 MySQL 数据库。爬取过程设置延时避免被反爬,实现数据去重与格式统一。
部分核心代码片段
python
# 提取商品列表
items = driver.find_elements(By.XPATH, '//div[@class="items"]/div[@class="item J_MouserOnverReq "]')
for item in items:
try:
title = item.find_element(By.XPATH, './/div[@class="title"]/a').text
price = item.find_element(By.XPATH, './/div[@class="price g_price g_price-highlight"]/strong').text
buy_len = item.find_element(By.XPATH, './/div[@class="deal-cnt"]').text.replace('人付款', '')
name = item.find_element(By.XPATH, './/div[@class="shop"]/a/span[2]').text
address = item.find_element(By.XPATH, './/div[@class="location"]').text
isFreeDelivery = '包邮' if '包邮' in title else '不包邮'
# 保存到CSV
save_to_csv('电脑', title, price, buy_len, '', name, address, isFreeDelivery, '', '')
count += 1
if count % 10 == 0:
print(f'已爬取{count}条数据')
except Exception as e:
print(f'爬取异常:{e}')
continue
# 翻页处理
try:
driver.find_element(By.XPATH, '//button[@class="next-btn next-medium next-btn-normal next-pagination-item next-next"]').click()
time.sleep(10)
get_product(count, page + 1)
except:
print('爬取完毕')
driver.quit()
# 保存到CSV
def save_to_csv(type, title, price, buy_len, img_src, name, address, isFreeDelivery, href, nameHref):
with open('./data.csv', 'a', encoding='utf-8', newline='') as f:
myWriter = csv.writer(f, dialect='excel')
myWriter.writerow([type, title, price, buy_len, img_src, name, address, isFreeDelivery, href, nameHref])
# 导入数据库
def save_to_sql():
products = pd.read_csv('./data.csv')
df = pd.DataFrame(products)
conn = create_engine('mysql+pymysql://root:123456@localhost:3306/goodsdata?charset=utf8')
df.to_sql('products', con=conn, index=False, if_exists='append')
print('导入数据库成功')2. 数据可视化模块
数据可视化模块功能实现
在系统中可视化模块是一个重要的功能模块,通过前端页面向后台发送请求,获取相关数据并对其进行解析和可视化展示。用户在系统首页访问页面时,页面会调用前端JavaScript脚本发送异步请求,访问后端提供的数据接口。Django框架作为后端的服务端框架,接受到前端请求后,会调用相关Python代码库对数据库进行操作,获取需要的数据。获取到数据后,Django会对数据进行处理,将数据处理成系统所需的数据格式,然后将数据响应给前端页面。前端页面拿到响应的数据后,将数据渲染成可视化的图表或者表格,以美观的形式呈现给用户。
img
部分核心代码:
javascript
// 前端Vue组件中绘制商品类型占比饼图
drawProductTypePie() {
var myChart = this.$echarts.init(this.$refs.typePie);
// 向后端请求商品类型数据
this.$axios.get('/api/product/type-count').then(res => {
const data = res.data;
const option = {
title: {
text: "各类型商品占比",
left: "center",
textStyle: { color: "#C0C0C0" }
},
tooltip: { trigger: "item" },
legend: {
orient: "vertical",
left: "left",
textStyle: { color: "#C0C0C0" }
},
series: [
{
name: "商品数量",
type: "pie",
radius: ["40%", "70%"],
data: data.map(item => ({ name: item.type, value: item.count })),
label: { color: "#fff" }
}
]
};
myChart.setOption(option);
});
}
// 后端Django视图函数(数据接口)
from django.http import JsonResponse
from myapp.models import Product
from collections import Counter
def get_product_type_count(request):
# 从数据库查询商品类型并统计数量
types = Product.objects.values_list('type', flat=True)
type_count = Counter(types)
# 转换为前端所需格式
result = [{'type': k, 'count': v} for k, v in type_count.items()]
return JsonResponse(result, safe=False)3. 用户登录与注册模块
功能说明
基于 Django 后端与 Vue 前端实现用户身份认证:
- 注册:校验用户名唯一性,加密存储密码;
- 登录:通过 Ajax 异步请求验证账号密码,返回登录状态;
- 权限控制:区分普通用户与管理员权限,限制数据管理操作。
部分核心代码片段
python
from django.http import JsonResponse
from django.views.decorators.csrf import csrf_exempt
from myapp.models import User
@csrf_exempt
def login(request):
if request.method == 'POST':
uname = request.POST.get('username')
pwd = request.POST.get('password') # 实际项目需加密校验
try:
# 查询用户
user = User.objects.get(username=uname, password=pwd)
# 生成会话(实际项目需用JWT令牌)
request.session['user_id'] = user.id
return JsonResponse({
'username': uname,
'message': '登录成功',
'is_admin': user.is_admin
})
except User.DoesNotExist:
return JsonResponse({'message': '用户名或密码错误'}, status=400)
@csrf_exempt
def register(request):
if request.method == 'POST':
uname = request.POST.get('username')
pwd = request.POST.get('password')
# 校验用户名是否已存在
if User.objects.filter(username=uname).exists():
return JsonResponse({'message': '用户名已存在'}, status=400)
# 创建用户(实际项目需对密码加密)
User.objects.create(username=uname, password=pwd, is_admin=False)
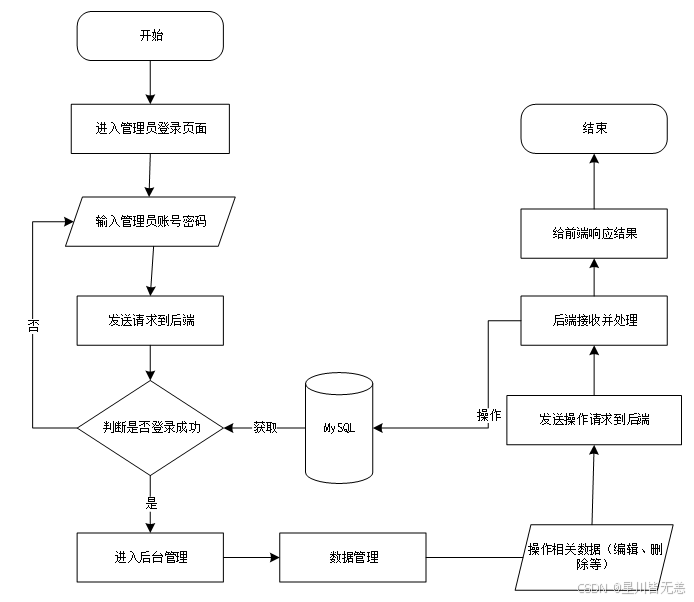
return JsonResponse({'message': '注册成功'})4. 数据管理模块
功能说明
为管理员提供商品数据与用户数据的全生命周期管理:
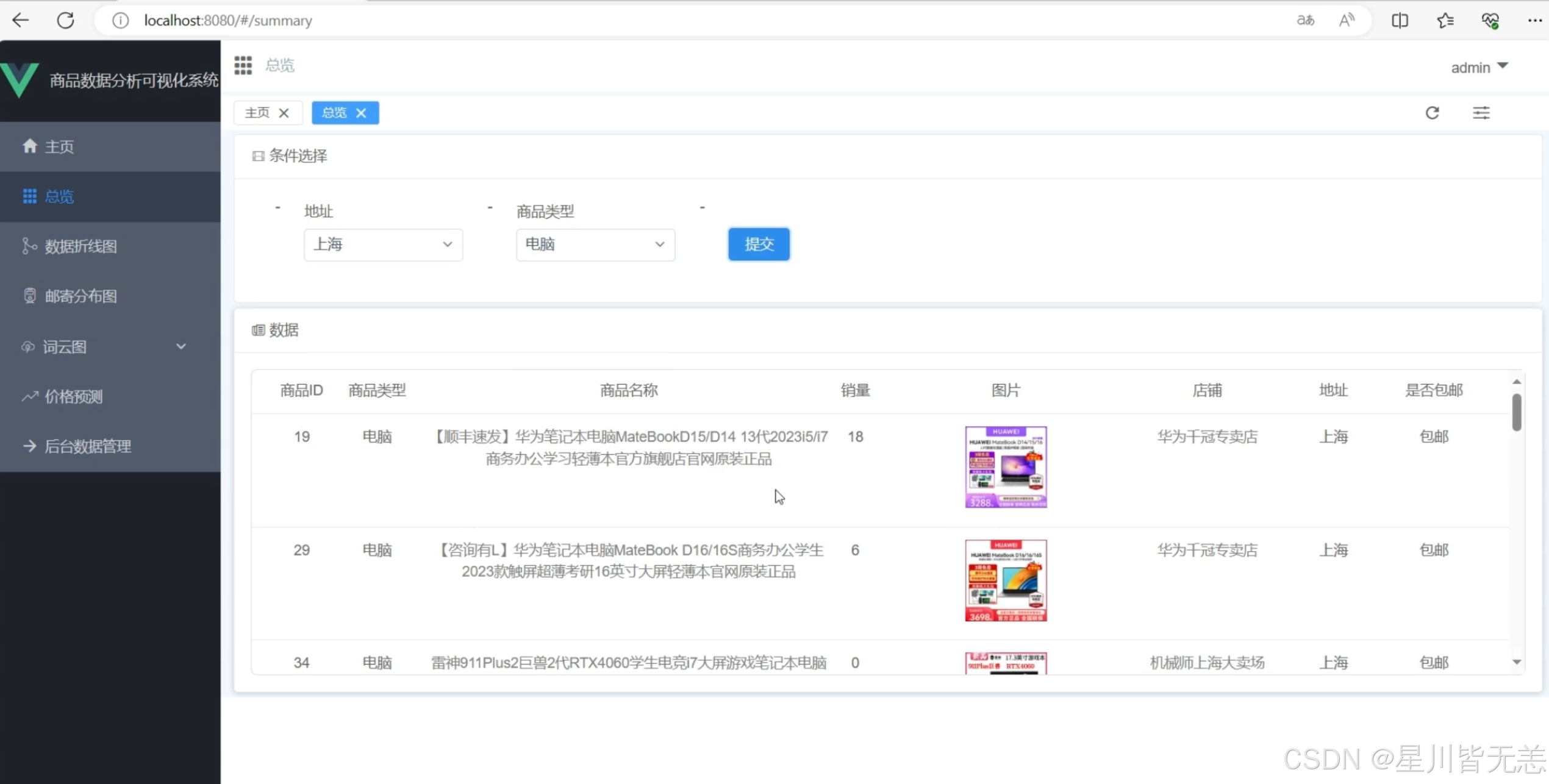
- 数据查询:支持按商品类型、价格区间、销量筛选;
- 数据操作:实现商品信息的新增、编辑、删除;
- 数据导出:支持将筛选后的数据导出为 Excel 格式;
- 日志记录:跟踪数据操作历史,保障数据安全。
5.数据管理模块
在系统中,数据管理模块负责实现数据的获取、存储和处理。通过requests爬虫模块,系统能够从各大电商商品网站获取数据,并将其转化为结构化格式。获取到的数据随后通过MySQL数据库进行持久化存储,确保数据的可靠性和持久性。数据管理模块还包括对数据的清洗和预处理功能,以确保数据的准确性和完整性。在数据处理方面,系统能够进行基本的统计分析,分析用户的偏好等,并将分析结果存储到数据库中供其他模块使用。同时,该模块还利用echarts、matplotlib等可视化工具对数据进行可视化分析,生成各种图表和词云,为用户提供直观的数据展示。通过数据管理模块的功能实现,系统能够高效地管理大量电商商品数据,并为后续的预测算法和用户交互提供有力支持。
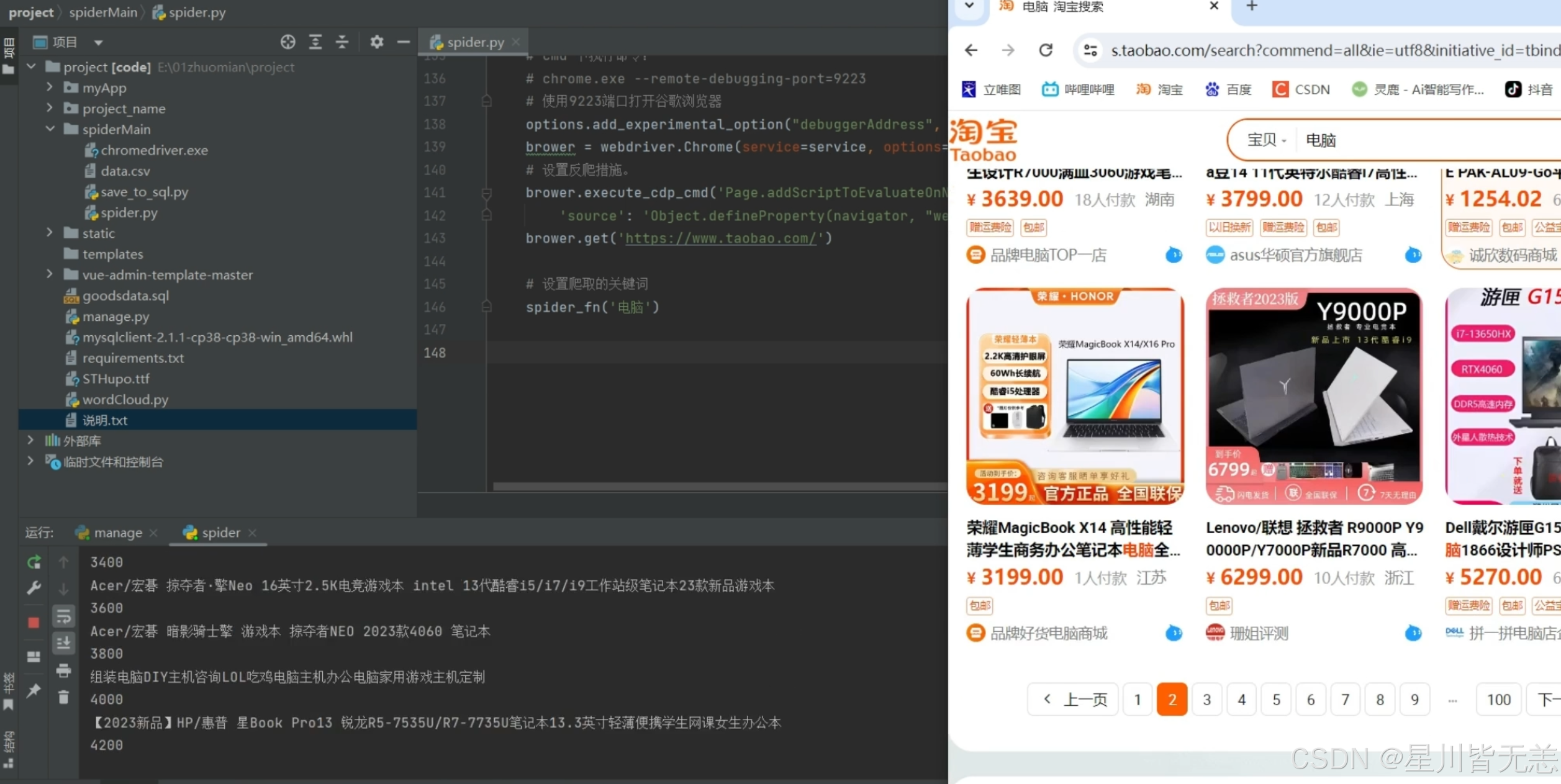
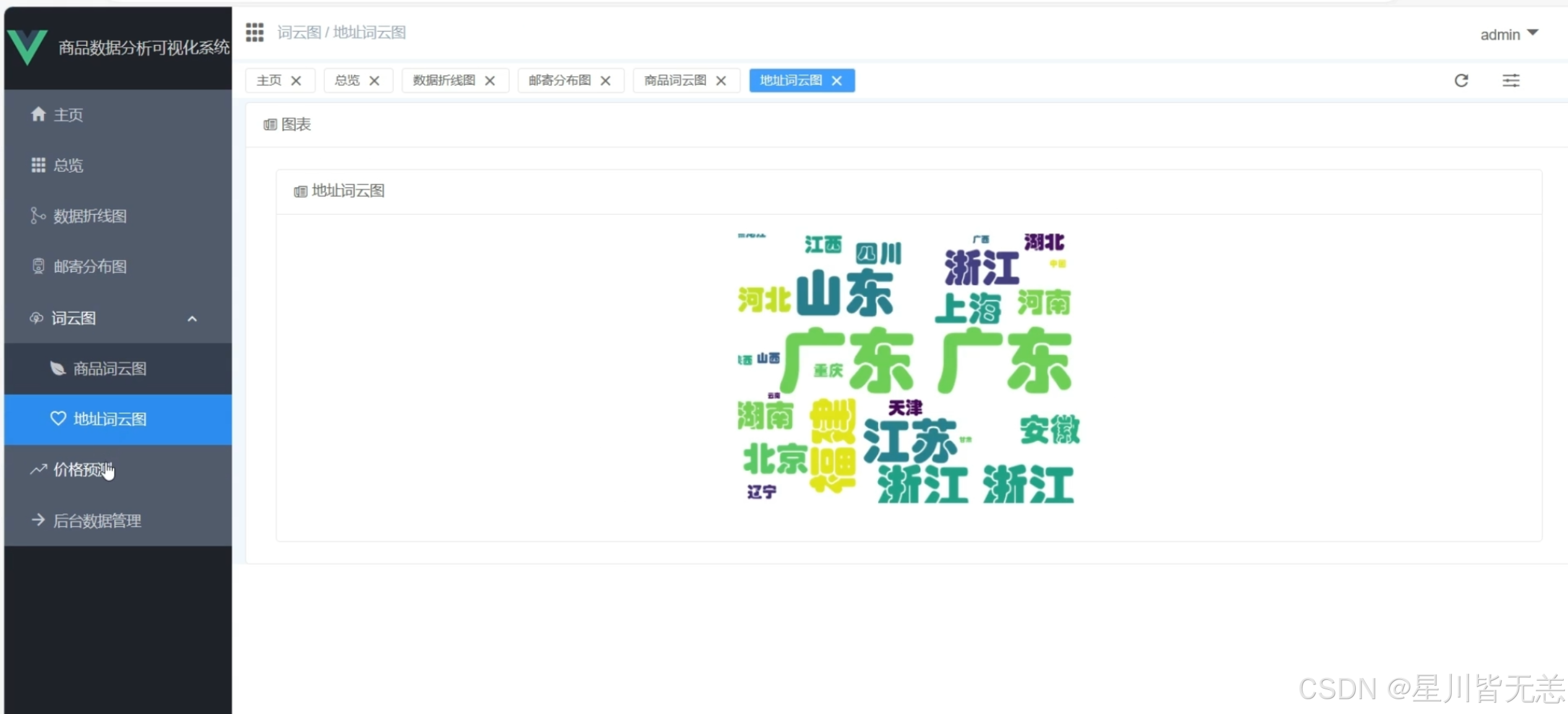
十、项目部分截图
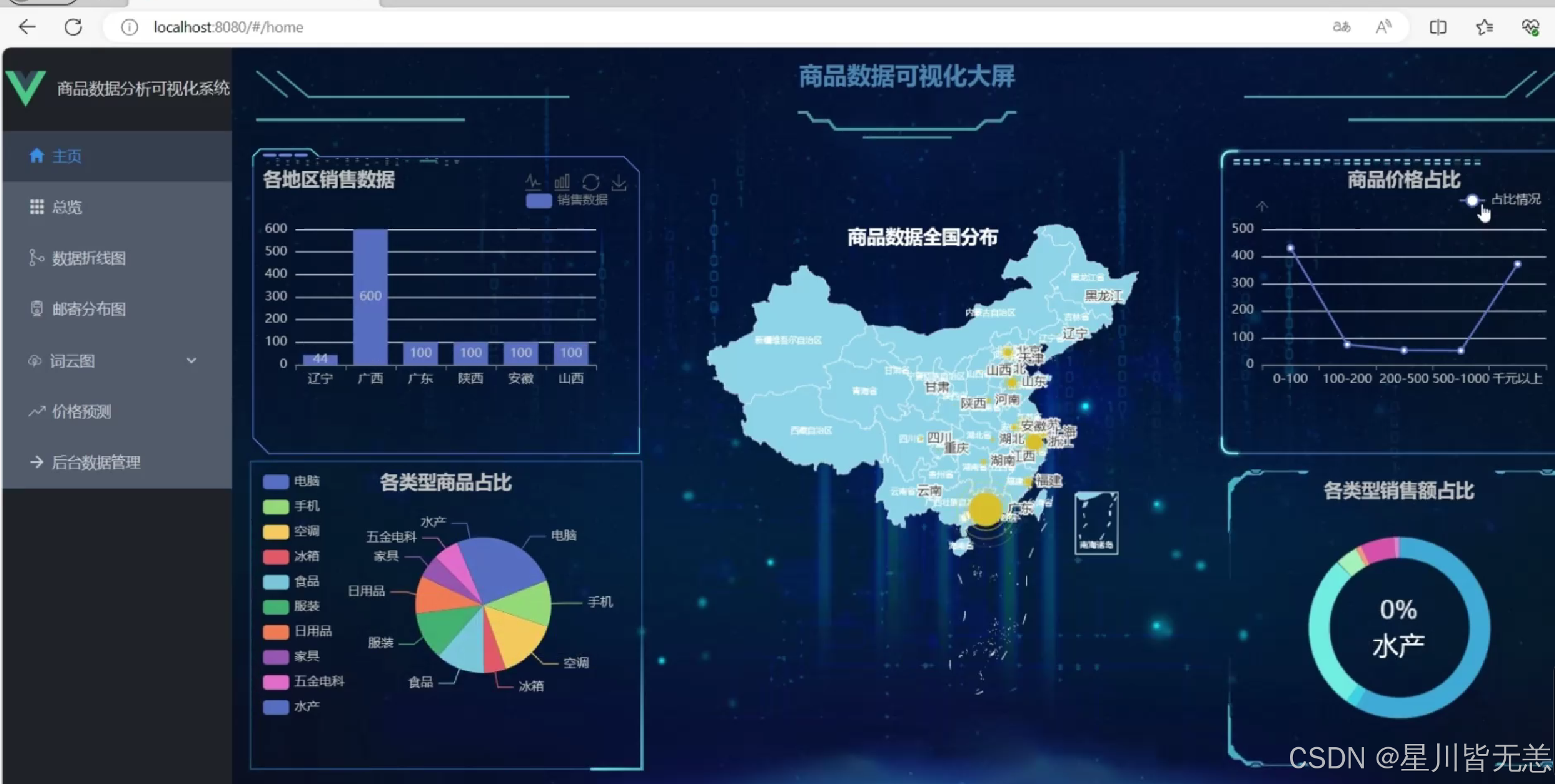
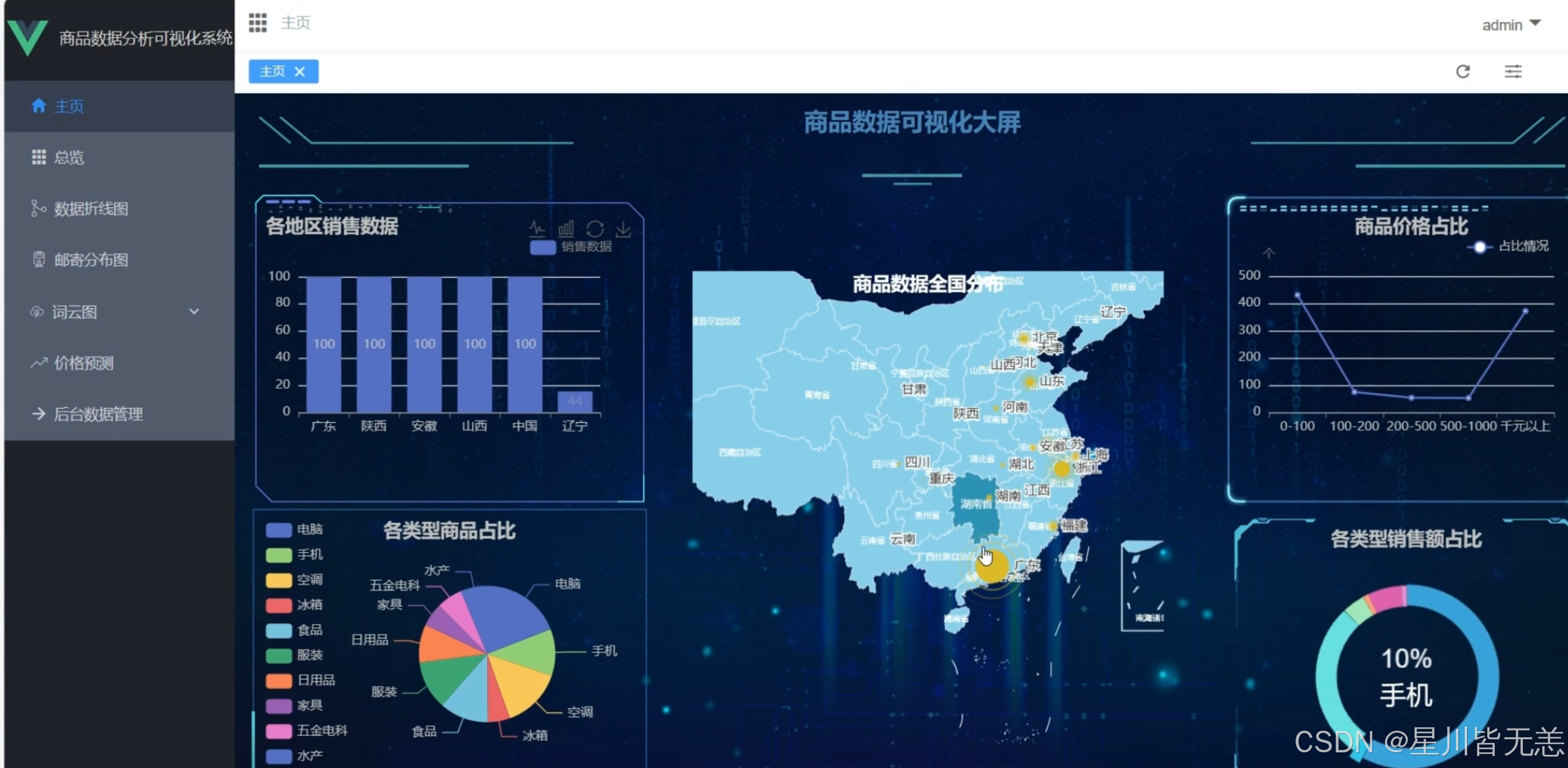
(1)系统首页 - 数据概况
展示核心指标(总商品数、总销量、热门品类),整合可视化图表入口与预测功能入口,左侧为功能导航栏。
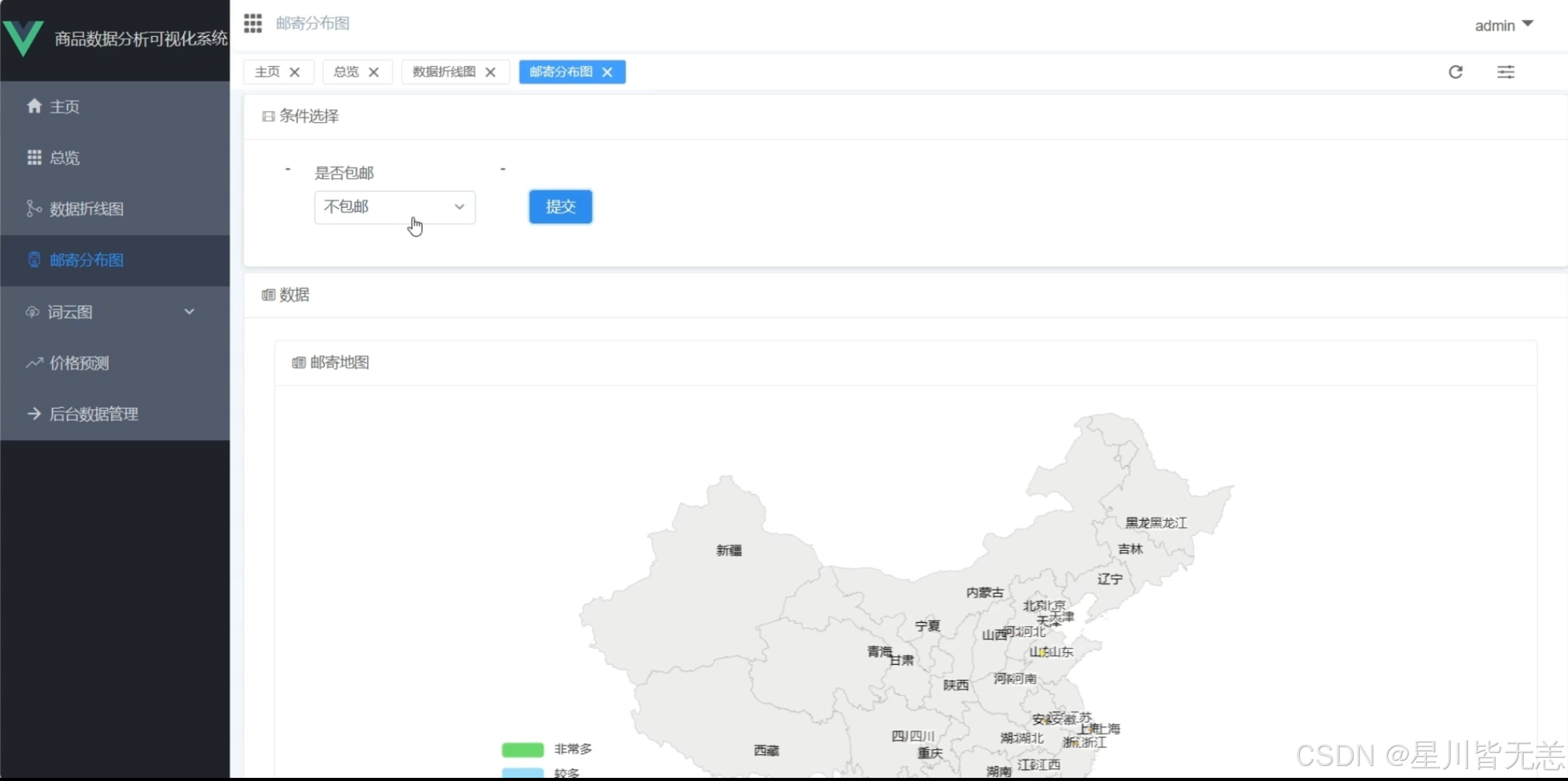
通过饼图直观呈现各品类商品数量分布,支持点击图例筛选数据,鼠标悬浮显示具体数值。
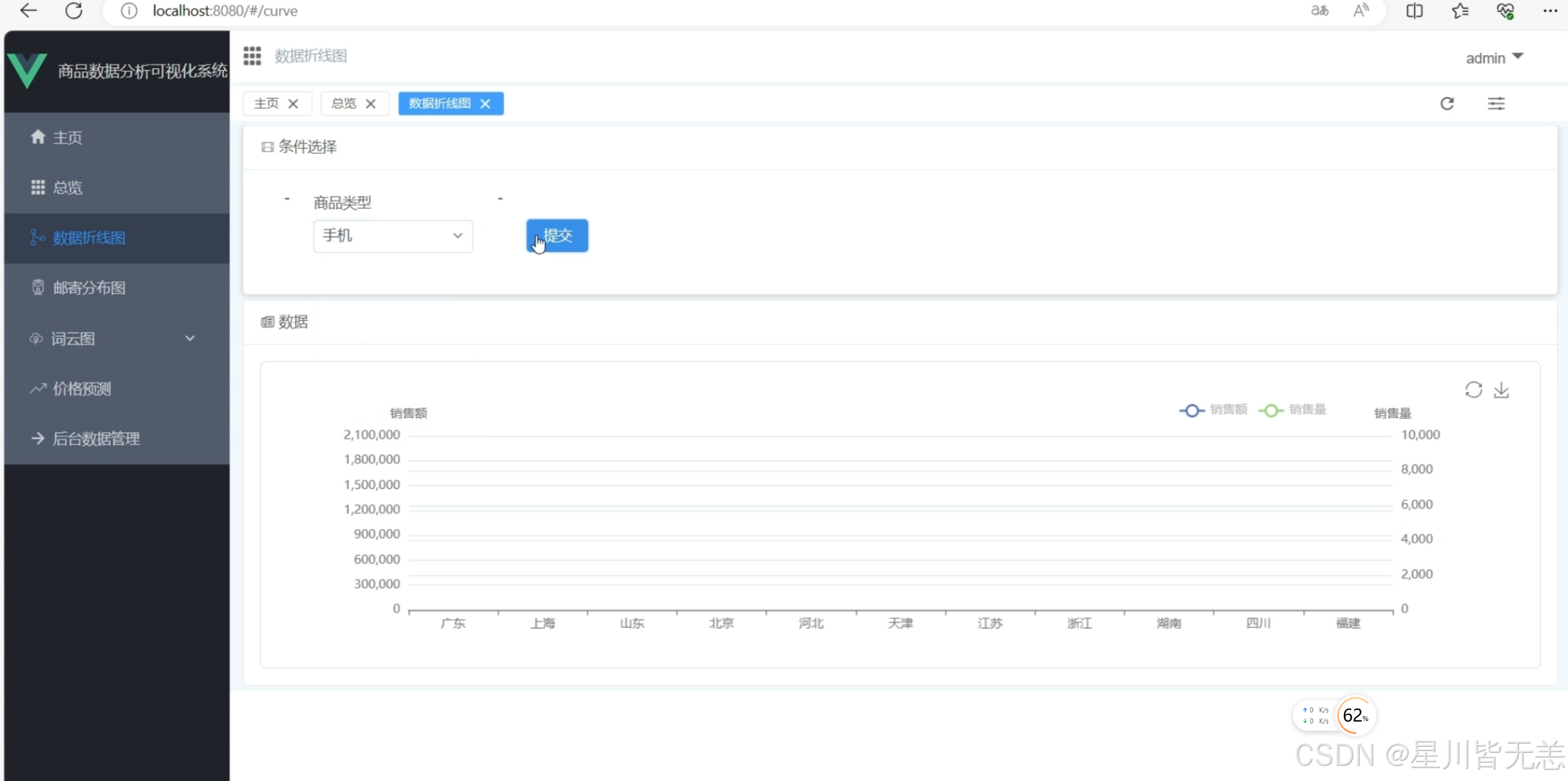
折线图展示不同价格区间商品的销量变化,可切换时间维度(日 / 周 / 月),辅助定价策略制定。
在这里插入图片描述
八、总结
在本研究中,我们以基于python电商爬虫可视化分析预测系统为主题,采用了Django+Vue前后端分离技术,开发了一个综合性的系统。该系统包括商品数据分析大屏、数据分析折线图、邮寄分布图、机器学习算法预测、后台数据管理以及大数据淘宝爬虫及数据分析词云图等功能模块。在商品数据分析大屏模块中,我们通过可视化展示了关键的商品数据指标,如销售额、库存量等,为平台决策者提供了直观的数据分析工具。数据分析折线图模块以及邮寄分布图模块,通过折线图和地图展示了不同时间段内的销售趋势以及订单邮寄分布情况,帮助平台了解用户行为和订单特征,为运营策略提供了参考依据。机器学习算法预测模块运用了线性回归算法,根据用户提供的商品特征,预测了用户的购买数量,为个性化推荐和定价优化提供了数据支持。在后台数据管理模块中,我们设计了一个用户友好的管理界面,实现了对商品数据、用户数据等的管理和统计分析,为平台运营者提供了便捷的数据管理工具。此外,大数据淘宝爬虫及数据分析词云图模块,通过爬取淘宝商品信息,并生成词云图展示了用户的搜索偏好和热门商品标签,为平台推荐系统提供了数据支持。
八、项目结语(源码文档等资料)
本系统整合爬虫、数据分析、机器学习与可视化技术,为电商企业提供了从数据采集到决策支撑的一体化解决方案。
需项目源码、完整设计文档或交流探讨,可联系下方名片获取相关资料,感谢您的关注与支持!