1. 全连接神经网络
全连接神经网络(Fully Connected Neural Network),中每个节点 与下一层 所有节点相连,通过调整节点连接关系处理信息,工程和学术界常简称其为 "神经网络",如下图所示。
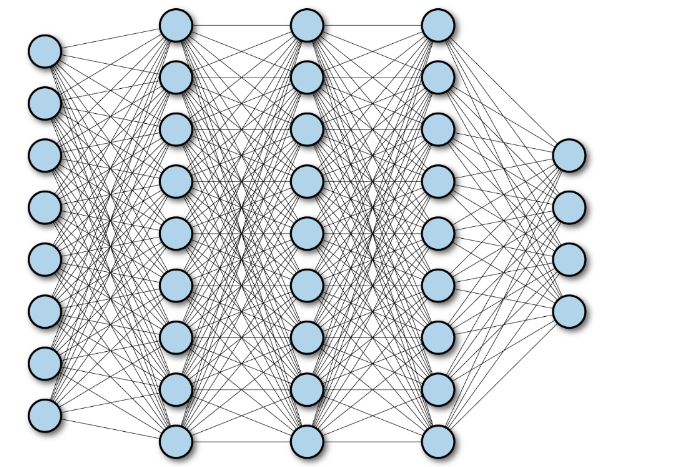
全连接神经网络通常包括输入层 、隐藏层 、输出层 三层核心结构,每层由若干节点(神经元)组成,且层间节点全连接。如下图所示
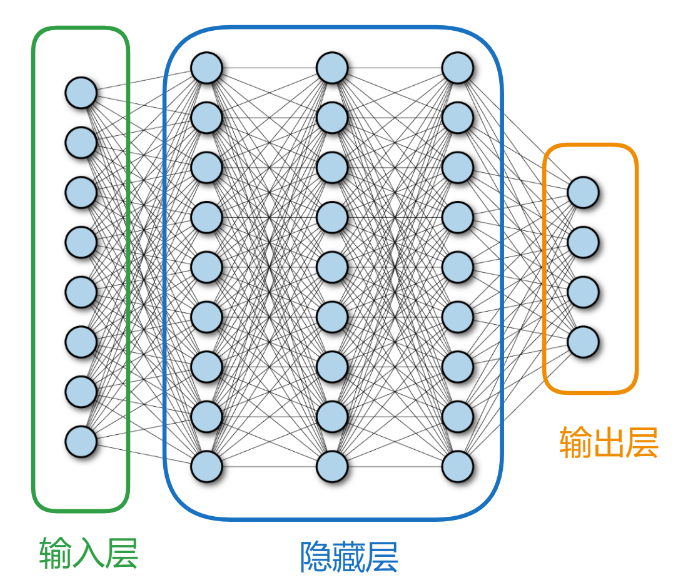
输入层
深度学习神经网络输入类型多样(数值、文字、图像、音频等),但对网络而言仅接收 n 维数据。输入层神经元数量增减需结合任务,须采用对逻辑回归或分类有实际意义的数据,训练才更有效。除数据有意义外,数据效率亦关键,对样本进行算法加工(如图像灰度化)可助力网络训练。
隐藏层
全连接隐藏层是全连接神经网络的核心组成部分,位于输入层和输出层之间,负责对数据进行非线性特征提取与抽象。
输出层
全连接神经网络输出层神经元个数需根据任务类型灵活设置,如回归问题、分类问题等场景均需适配实际需求。
2.1 散点输入
假如现在调查某人对衣服的尺码的接受程度,当衣服的尺码过大或者过小时,都穿不上。采集了某人对衣服尺码(横坐标)的接受程度(纵坐标),并且将它们绘制在一个二维坐标中,其分布如下图所示:
其坐标分别为:0.8, 0,1.1, 0,1.7, 0,1.9, 0,2.7, 1,3.2, 1,3.7, 1,4.0, 1,5.0, 0,5.5, 0,6.0, 0,6.3, 0,纵坐标1代表能穿上,0代表穿不上。
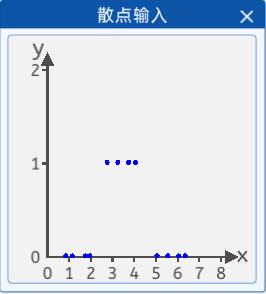
那么就可以搭建一个神经网络,将散点数据带入网络中进行训练,从而拟合出一条曲线,使该曲线能够尽可能准确的描述衣服尺码与被接受程度的关系,那样就可以预测某件衣服的不同尺码的被接受程度。
2.2 前向计算
神经网络,也称为人工神经网络(ANN)或模拟神经网络(SNN),是机器学习的子集,并且是深度学习算法的核心。其名称和结构是受人类大脑的启发,模仿了生物神经元信号相互传递的方式,但实际上并不十分相通。一般分为3个层次:输入层,输出层,隐藏层,下图就是一个最简单的神经网络结构。
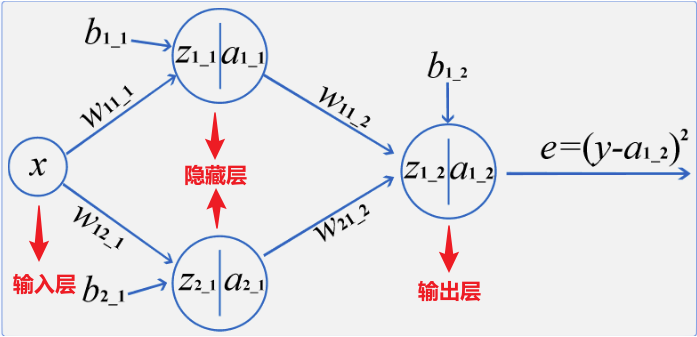
在上图中,所有的"圆圈"有一个共同的名字,叫做神经节点。一个神经网络是由很多个节点来构成的,不同层的节点会有不同的作用。
比如节点"x"所在的层叫做输入层。每一个神经网络都只有一个输入层,但输入层可以有很多个"输入"节点,所有的特征都从该层进行输入。比如上面的神经网络中输入层只有"x"一个节点,也就意味着该神经网络只有一个输入特征,例如根据用水量判断水费,"x"就是用水量。
节点"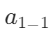 "和节点"
"和节点"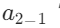 "所在的层叫做隐藏层,一个神经网络可以有很多个隐藏层,每一个隐藏层中也可以有很多个节点。
"所在的层叫做隐藏层,一个神经网络可以有很多个隐藏层,每一个隐藏层中也可以有很多个节点。
隐藏层是用来对输入的特征进行计算的结果,层数越多,模型越复杂。
上面的神经网络中有一层隐藏层,该隐藏层中有两个节点,其中"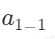 "节点下角标的第一个"1"表示该节点是本层的第一个节点,第二个"1"表示是神经网络的第1层(第一个隐藏层是第一层)。
"节点下角标的第一个"1"表示该节点是本层的第一个节点,第二个"1"表示是神经网络的第1层(第一个隐藏层是第一层)。
由此,"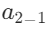 "节点的下角标代表本节点是该网络第一层隐藏层中的第二个节点。
"节点的下角标代表本节点是该网络第一层隐藏层中的第二个节点。

由此,表示该参数是第一层的参数,其计算对象是上一层的第一个节点,计算后的结果(需要激活)是本层的第二个节点,表示该参数是第二层的参数,其计算对象是上一层的第一个节点,计算后的结果(需要激活)是本层的第一个节点;表示该参数是第一层的参数,计算结果(需要激活)是本层的第一个节点,表示该参数是第一层的参数,计算结果(需要激活)是本层的第二个节点。
从隐藏层开始,每个节点都是有计算公式的,包括输出层。计算公式为:
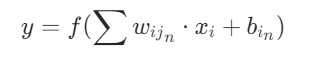
其中y 就是经过计算并激活的结果,对应上面的 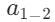 、
、 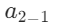 等节点;
等节点;
f是激活函数,用于带入非线性因素,本实验中用的激活函数是 sigmiod()。
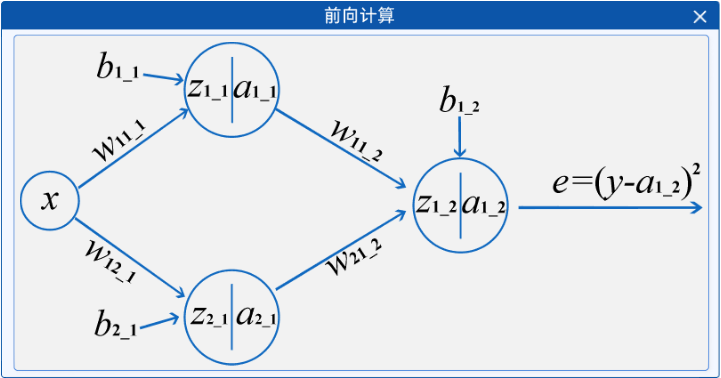
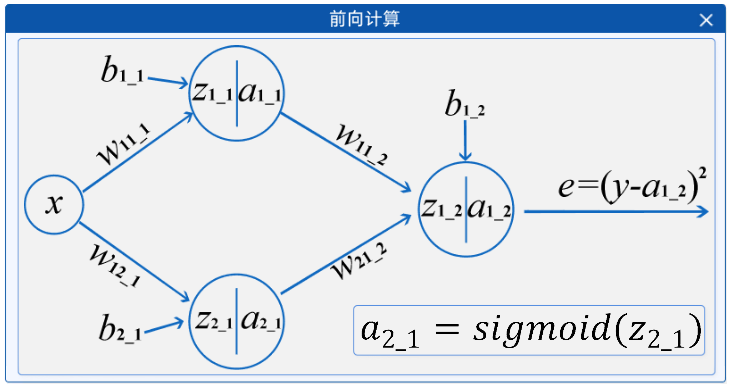
最后根据输出结果得到损失函数: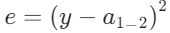 这就是全连接神经网络中的前向计算的过程。
这就是全连接神经网络中的前向计算的过程。
在"前向计算"组件中,将鼠标移动到节点上时,会在右下角显示其计算公式,如下图所示:
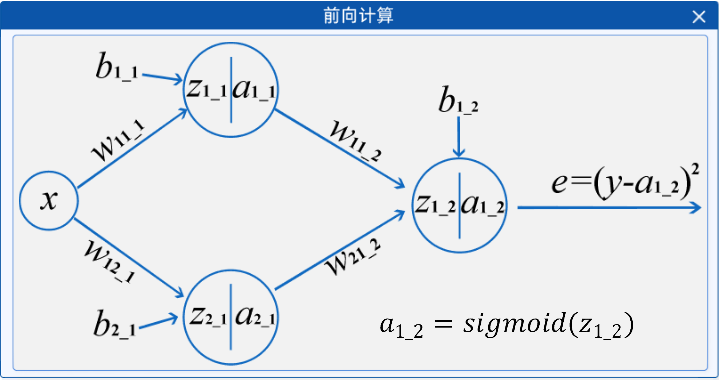
2.3 参数初始化
了解了全连接神经网络中的前向计算过程后,就可以进行前向计算了。首先要进行的就是参数初始化,在"参数初始化"组件中,可以修改神经网络计算过程中所涉及到的参数以及后续反向传播更新参数用到的学习率,并且随着参数的修改,原本的直线会随着参数的修改而改变形状。如下图所示:
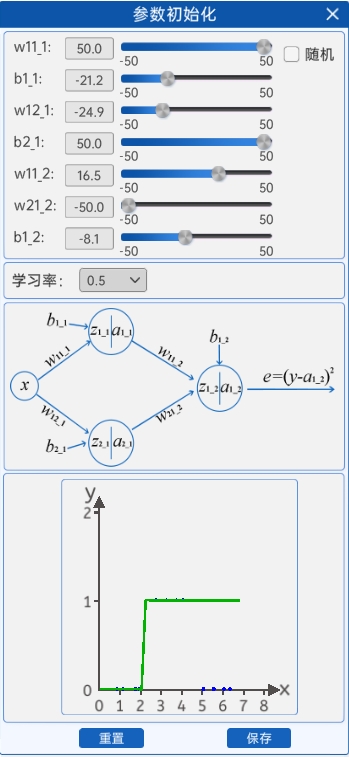
2.4 损失函数
由于本实验的最终目标是拟合一条曲线,所以损失函数使用的还是MSE(均方误差损失函数)。
2.5 开始迭代
与机器学习一样,神经网络也是通过不断的迭代更新来训练参数的,不同的是,神经网络的模型结构会比机器学习复杂的多,其中所涉及到的参数量也远远大于机器学习,因此,神经网络的迭代次数一般都很大,同时,由于本实验的拟合线较复杂但是网络偏简单,所以并不是很好拟合。本实验中,"开始迭代"组件中默认选择的迭代次数是5000次。
2.6 反向传播
与机器学习一样,神经网络中的反向传播的过程也是对参数进行求导,不同的是,由于深度学习结构的复杂,其求导过程也会相对复杂。

这个过程就用到了链式求导法则,链式求导法是指当有两个可导的函数组成一个复合函数时,对复合函数求导时需要遵循一环一环逐次求导的原则,即首先对内层函数求导,然后再将内层函数的导数乘以外层函数的导数。
例如,如果有两个可导的函数f(x)和g(x),将它们组成一个复合函数h(x) = f(g(x)),则对h(x)求导时需要按照如下顺序进行:首先对g(x)求导,然后将其结果与f'(x)相乘。


这个公式表达了 z 对 x 的偏导数,其中每一项表示 z 相对于中间变量 u 和 v 的变化率,乘以 u 和 v 相对于 x 的变化率。
通过链式求导法则,就可以求得损失 对所有参数的导数并更新。在"反向传播"组件中,把鼠标放在箭头上时,就可以看到其求导的公式了,如下图所示:
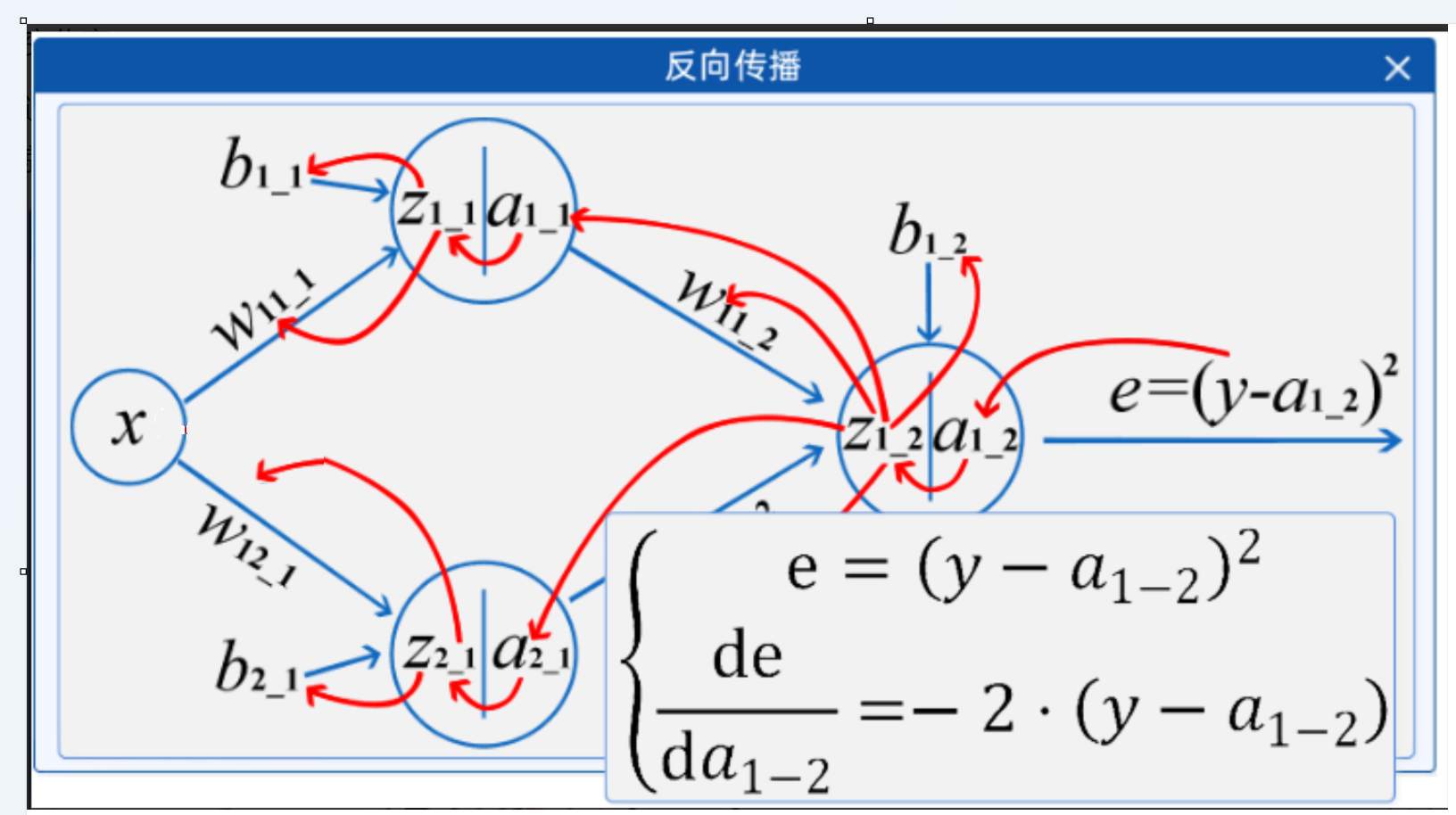
链式法则在计算神经网络中的梯度(反向传播)时非常重要,因为神经网络中的层与层之间通常是复合函数关系。通过链式法则,可以有效地计算损失函数对网络参数的梯度,从而进行梯度下降优化。
2.7 显示频率设置
求导完成之后,使用梯度下降的方法来更新w和b的值。为了更好的在实验中看现象,通过"显示频率设置"组件来绘制当前参数的拟合线及损失函数的大小。
2.8 梯度下降显示
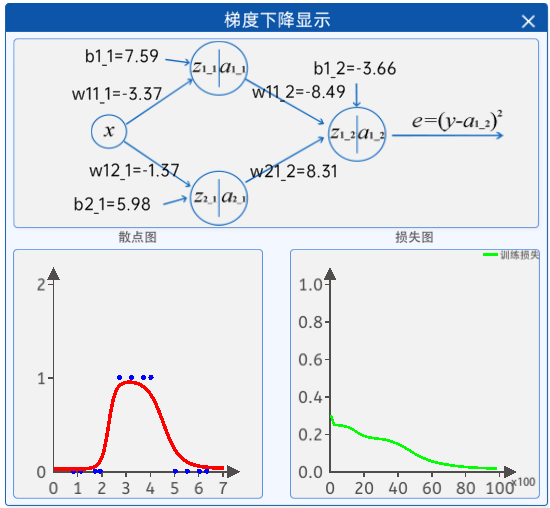
其中,每个参数的值都是随着神经网络的迭代而实时更新的。
而左边的图则是根据上面的参数值而实时绘制的图形,右边的图则是当前参数值下的损失值,随着迭代次数的不断增长,参数值在不断的更新,损失值也在不断的更新。
注意:随机参数由于网络比较简单但特征相对复杂导致可能会不拟合,建议在"参数初始化"组件中的初始化值使用上图中的参数。使用该参数过程类似于迁移学习,可得到一个较好的拟合结果。
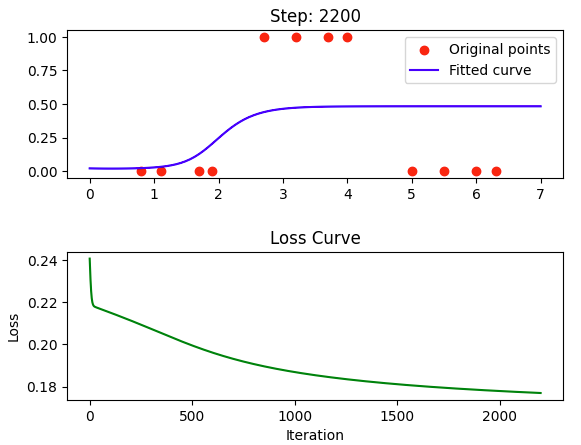
实验现象
实验结果为:
5.代码实现:
无图代码展示:
python
#导入相关库
import numpy as np
import matplotlib.pyplot as plt
#1.散点输入
points = np.array([[0.8, 0],
[1.1, 0],
[1.7, 0],
[1.9, 0],
[2.7, 1],
[3.2, 1],
[3.7, 1],
[4.0, 1], [5.0, 0],
[5.5, 0], [6.0, 0],
[6.3, 0]])
#将输入样本的特征和标签分开
X=points[:,0] #将所有数据的第一维放到X中
Y=points[:,1] #将所有数据的第二维放到Y中
#2.前向计算
#sigmoid 函数
def sigmoid(x):
return 1/(1+np.exp(-x))
def forward(w11_1,b1_1,w12_1,b2_1,w11_2,w21_2,b1_2,x):
z1_1=w11_1*x+b1_1
a1_1=sigmoid(z1_1)
z2_1=w12_1*x+b2_1
a2_1=sigmoid(z2_1)
z1_2 = a1_1 * w11_2 + a2_1*w21_2+b1_2
a1_2 = sigmoid(z1_2)
return a1_1,a2_1,a1_2
#3.参数初始化
w11_1,b1_1,w12_1,b2_1,w11_2,w21_2,b1_2=0.1,0.6,0.9,-1.5,0.1,0.9,0.2
lr=0.5
#4.损失函数
def loss_func(y,y_hat):
loss=np.mean((y-y_hat)**2)
return loss
#5.迭代
#设置迭代次数
epoches=500
for epoch in range(1,epoches+1):
#计算损失函数
a1_1,a2_1,a1_2=forward(w11_1, b1_1, w12_1, b2_1, w11_2, w21_2, b1_2, X)
loss=loss_func(Y,a1_2)
print(loss)
#反向传播
deda1_2=-2*(Y-a1_2)
dedz1_2=deda1_2*a1_2*(1-a1_2)
dedw11_2=np.mean(dedz1_2*a1_1)
dedw21_2=np.mean(dedz1_2*a2_1)
dedb1_2=np.mean(dedz1_2)
deda1_1=dedz1_2*w11_2
dedz1_1=deda1_1*(a1_1*(1-a1_1))
#求平均
dedw11_1=np.mean(dedz1_1*X)
dedb1_1 = np.mean(dedz1_1)
deda2_1=dedz1_2*w21_2
dedz2_1=deda2_1*a2_1*(1-a2_1)
dedw12_1=np.mean(dedz2_1*X)
dedb2_1=np.mean(dedz2_1)
#梯度更新
w11_2=w11_2-lr*dedw11_2
w21_2=w21_2-lr*dedw21_2
b1_2=b1_2-lr*dedb1_2
w11_1=w11_1-lr*dedw11_1
b1_1=b1_1-lr*dedb1_1
w12_1=w12_1-lr*dedw12_1
b2_1=b2_1-lr*dedb2_1有图:
python
#导入相关库
import numpy as np
import matplotlib.pyplot as plt
#1.散点输入
points = np.array([[0.8, 0],
[1.1, 0],
[1.7, 0],
[1.9, 0],
[2.7, 1],
[3.2, 1],
[3.7, 1],
[4.0, 1], [5.0, 0],
[5.5, 0], [6.0, 0],
[6.3, 0]])
#将输入样本的特征和标签分开
X=points[:,0] #将所有数据的第一维放到X中
Y=points[:,1] #将所有数据的第二维放到Y中
#2.前向计算
#sigmoid 函数
def sigmoid(x):
return 1/(1+np.exp(-x))
def forward(w11_1,b1_1,w12_1,b2_1,w11_2,w21_2,b1_2,x):
z1_1=w11_1*x+b1_1
a1_1=sigmoid(z1_1)
z2_1=w12_1*x+b2_1
a2_1=sigmoid(z2_1)
z1_2 = a1_1 * w11_2 + a2_1*w21_2+b1_2
a1_2 = sigmoid(z1_2)
return a1_1,a2_1,a1_2
#3.参数初始化
w11_1,b1_1,w12_1,b2_1,w11_2,w21_2,b1_2=0.1,0.6,0.9,-1.5,0.1,0.9,0.2
lr=0.5
#4.损失函数
def loss_func(y,y_hat):
loss=np.mean((y-y_hat)**2)
return loss
#5.迭代
#画图用
x_values=np.linspace(0,7,100)
loss_list=[]
epoches_list=[]
#设置迭代次数
epoches=5000
for epoch in range(1,epoches+1):
#计算损失函数
a1_1,a2_1,a1_2=forward(w11_1, b1_1, w12_1, b2_1, w11_2, w21_2, b1_2, X)
loss=loss_func(Y,a1_2)
loss_list.append(loss)
epoches_list.append(epoch)
print(loss)
#反向传播
deda1_2=-2*(Y-a1_2)
dedz1_2=deda1_2*a1_2*(1-a1_2)
dedw11_2=np.mean(dedz1_2*a1_1)
dedw21_2=np.mean(dedz1_2*a2_1)
dedb1_2=np.mean(dedz1_2)
deda1_1=dedz1_2*w11_2
dedz1_1=deda1_1*(a1_1*(1-a1_1))
#求平均
dedw11_1=np.mean(dedz1_1*X)
dedb1_1 = np.mean(dedz1_1)
deda2_1=dedz1_2*w21_2
dedz2_1=deda2_1*a2_1*(1-a2_1)
dedw12_1=np.mean(dedz2_1*X)
dedb2_1=np.mean(dedz2_1)
#梯度更新
w11_2=w11_2-lr*dedw11_2
w21_2=w21_2-lr*dedw21_2
b1_2=b1_2-lr*dedb1_2
w11_1=w11_1-lr*dedw11_1
b1_1=b1_1-lr*dedb1_1
w12_1=w12_1-lr*dedw12_1
b2_1=b2_1-lr*dedb2_1
# 7.显示频率设置
if epoch == 1 or epoch % 100 == 0:
print(f"epoch:{epoch},loss:{loss}")
# 画图 散点图及预测曲线
# 清除当前图形
plt.clf()
plt.subplot(2, 1, 1)
# 画Y的散点和拟合线
a1_1, a2_1, a1_2 = forward(w11_1, b1_1, w12_1, b2_1, w11_2, w21_2, b1_2, x_values)
plt.plot(x_values, a1_2)
# 画散点
plt.scatter(X, Y)
# 画损失值
plt.subplot(2, 1, 2)
plt.plot(epoches_list, loss_list)
plt.pause(1)
# 8.梯度下降显示
plt.show()