目标检测 是计算机视觉的基石。与上一讲复杂的两阶段 范式(如R-CNN)不同,单阶段 方法开启了"一眼检测"的新思路。它摒弃了独立的区域提议步骤 ,将任务简化为单次网络前向传播 ,在速度上取得压倒性优势。
我们将从开创者YOLOv1 出发,剖析其统一的回归思想与设计局限;随后探索SSD如何通过多尺度与默认框 机制实现精度飞跃;最后追踪YOLOv2/v3的自我进化之路,看它们如何吸收业界精华,通过骨干网络升级、多尺度预测等技术,最终成为实时检测领域的标杆。
目录
[上一讲 两阶段(R-CNN)与这一讲 单阶段区别](#上一讲 两阶段(R-CNN)与这一讲 单阶段区别)
[1. 架构](#1. 架构)
[2. 损失函数设计:](#2. 损失函数设计:)
[3. 局限性](#3. 局限性)
上一讲 两阶段(R-CNN)与这一讲 单阶段区别
-
两阶段(R-CNN, Fast R-CNN, Faster R-CNN): 将"目标检测"这个任务明确地拆分成两个子任务,并分步执行。
-
阶段一:区域提议(Region Proposal) - 找出图片中"可能"包含物体的所有区域框(例如,1,000~2,000个)。
- 方法: 使用单独的算法(如Selective Search或RPN网络)来生成这些候选框。
-
阶段二:分类与精修 - 对每一个候选区域框进行精细处理。
- 步骤: 将每个候选框输入到一个卷积神经网络中进行特征提取 ,然后使用分类器判断框内物体的类别 ,同时使用回归器对框的位置和大小进行微调。
打个比方: 两阶段方法就像先用人眼快速扫描一张图片,找出所有"可能是物体"的模糊区域 (阶段一),然后再把每个模糊区域拿起来,凑近了仔细看,确认它到底是什么 ,并且把它的边界划精确 (阶段二)。这个过程是顺序的 ,比较慢但通常更精确。
-
-
单阶段(YOLO, SSD, RetinaNet): 将"目标检测"视为一个单一的回归问题。
-
核心思想: 只看图片一次 ,直接在网络的一次前向传播过程中,同时 预测出所有目标的位置和类别。
-
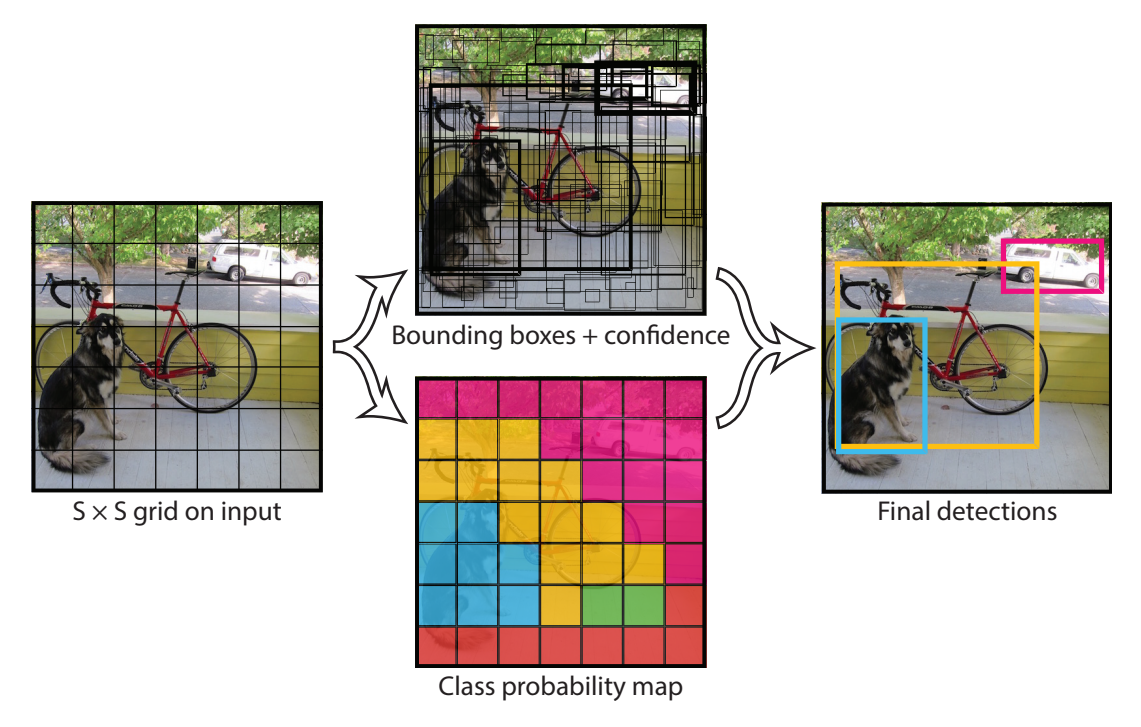
方法: 将输入图像均匀地划分成一个 S x S 的网格(Grid Cell)。每个网格负责预测固定数量的边界框 (Bounding Box)以及这些框的**"物体置信度"和"类别概率"**。
打个比方: 单阶段方法就像你一眼看过去整张图片,大脑瞬间就完成了所有物体的定位和识别 。你不需要先找"可能是物体的区域",而是直接输出了"哪里有什么"。这个过程是并行的,速度快。
-
YOLO-v1
1. 架构
-
划分网格(Grid Division):
- 将输入图像 resize 到一个固定尺寸(如 448x448),并将其划分为一个 S x S 的网格(例如 7x7)。
-
每个网格负责预测边界框:
-
每个网格会预测 B 个边界框(例如 B=2)。对于每个边界框,网络需要预测5个值:
-
(x, y, w, h):边界框的中心点坐标(相对于该网格的偏移)以及框的宽和高(相对于整个图片的比例)。 -
confidence(置信度):表示这个框内"包含一个物体"的把握有多大。计算公式为:Pr(Object) * IOU^(truth_pred)。如果网格里没有物体 ,置信度应该为0 ;如果有,置信度等于预测框与真实框的IOU(交并比)。
-
-
-
每个网格同时预测类别概率:
- 此外,每个网格 (而不是每个边界框)还会预测一组 C 个"条件类别概率"(Conditional Class Probabilities),即
Pr(Class_i | Object)。意思是"如果这个网格里有物体 ,那么这个物体是第 i 类的概率是多少"。
- 此外,每个网格 (而不是每个边界框)还会预测一组 C 个"条件类别概率"(Conditional Class Probabilities),即
-
整合输出(Final Output):
-
将上述信息组合起来,网络的最终输出张量形状就是 S x S x (B * 5 + C)
-
在推理时,将每个边界框的"置信度" 与每个类别的"条件概率" 相乘,就得到了每个框对于每个类别的**"类别置信度分数"** (Class-specific Confidence Score) Pr(Class_i | Object) * Pr(Object) * IOU = Pr(Class_i) * IOU 这个分数同时编码了 "框内物体属于某类的概率 " 和 "预测框的位置准不准" 两方面信息。
-
-
inference 推理输出时 非极大值抑制(Non-Maximum Suppression, NMS):
-
经过上述步骤,会得到 S x S x B 个预测框。很多框是重复的或者置信度很低的。
-
一些大型物体 或跨越多个网格单元边界 的物体,可能会被多个网格单元较好地定位。
-
NMS 用于过滤这些冗余的框,只保留最好的一个。它根据类别置信度分数,抑制掉那些与最高分框重叠度(IOU)过高的其他框。
-
2. 损失函数设计:
-
损失函数 = 坐标损失(中心点+宽高) + 置信度(有没有物体)损失 + 分类损失
-
挑战1:分类错误比定位错误更严重
-
挑战2:图像中"背景"远多于"物体",大量背景网格产生的"置信度误差"会占据总损失的绝大部分 。模型为了快速降低总损失,会倾向于把所有网格的置信度都预测成0("躺平")
-
挑战3:大框大物体的10个像素差异和小物体的10个像素
| 部分 | 目标 | 关键设计 | 解决的问题 |
|---|---|---|---|
| 1. 中心点损失 | 精准定位物体中心 | 𝕀_{ij}^{obj} 和 λ_coord=5 |
只优化主预测框,加强定位重要性 |
| 2. 宽高损失 | 精准框出物体大小 | 预测宽高平方根 | 均衡大小框的误差敏感性,改善 小物体检测 |
| 3. 有物体置信度 | 提高真阳性框的置信度 | 𝕀_{ij}^{obj} |
让模型对正确预测的框更有把握 |
| 4. 无物体置信度 | 降低假阳性(背景误判) | 𝕀_{ij}^{noobj} 和 λ_noobj=0.5 |
解决背景淹没问题,这是稳定训练的关键 |
| 5. 类别损失 | 正确识别物体类别 | 𝕀_{i}^{obj} |
只在有物体的网格上进行分类学习 |
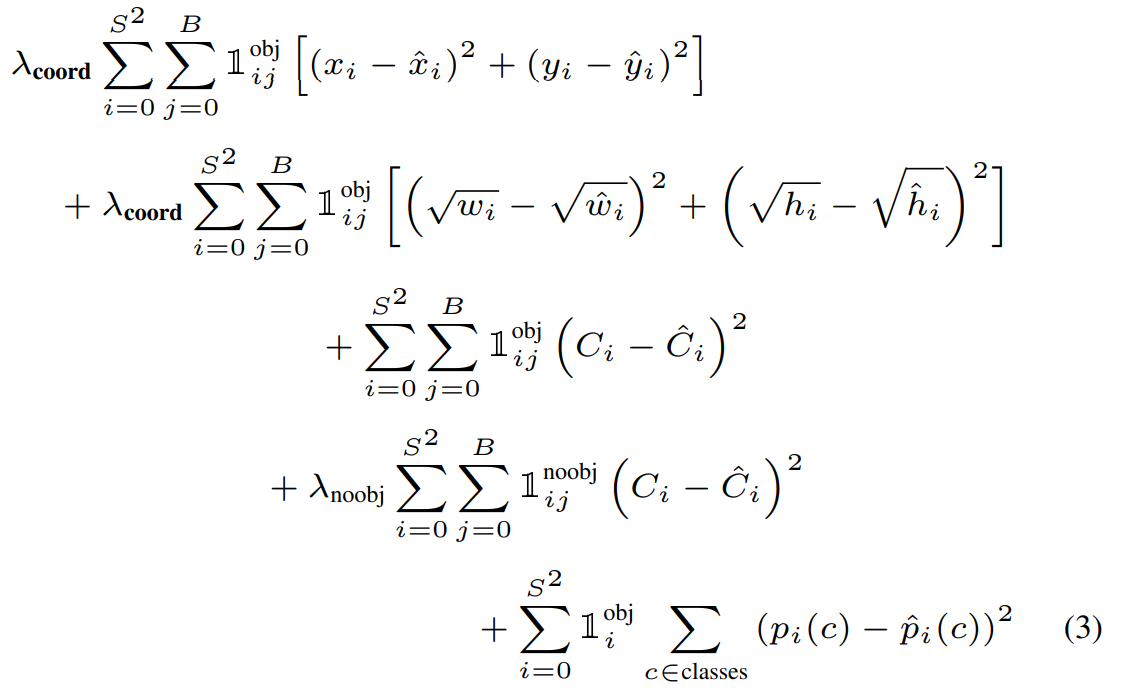
3. 局限性
-
空间约束强,对成群小物体检测差:
- 根源: 每个
S x S的网格最多只能预测B个物体(B=2)。这意味着,如果两个同类小物体的中心点落入同一个网格单元 ,YOLOv1只能检测出其中一个。对于密集的小物体(如鸟群、人群),这是致命的。
- 根源: 每个
-
泛化能力到新形状物体较弱:
- 根源: 模型的边界框预测能力 是从训练数据中学来的。如果测试数据中出现了一种训练集中从未见过的、非常奇特的长宽比或物体姿态,模型会难以预测出准确的框。因为它的"想象力"受限于训练数据。
-
特征相对粗糙,定位精度是主要误差来源:
-
根源: 网络为了获得大的感受野和更高级的语义特征,进行了多次下采样 (如从448x448下采样到7x7)。这导致用于预测边界框的特征图分辨率很低(7x7) ,包含的细粒度几何信息不足 。因此, bounding box 的坐标回归不够精准。
-
后续版本的改进: 这也是为什么YOLOv2/v3开始使用多尺度特征图 (例如,不仅在深层粗特征图上预测,也在浅层细特征图上预测)和锚点框 来提升定位精度,尤其是小物体检测能力。
-
-
损失函数对大小框误差处理仍不完美:
-
回顾: 虽然损失函数通过预测宽高的平方根 来部分缓解了大小框误差权重不均的问题。
-
遗留问题: 但平方根变换只是一个近似解决方案,并未根本解决IOU损失与坐标直接回归之间的不对齐问题 。定位误差(尤其是小物体的定位误差)是YOLOv1最主要的错误类型。这催生了后续研究中各种基于IOU的损失函数(如GIOU, DIOU, CIOU)。
-
SSD
SSD: Single Shot MultiBox Detector
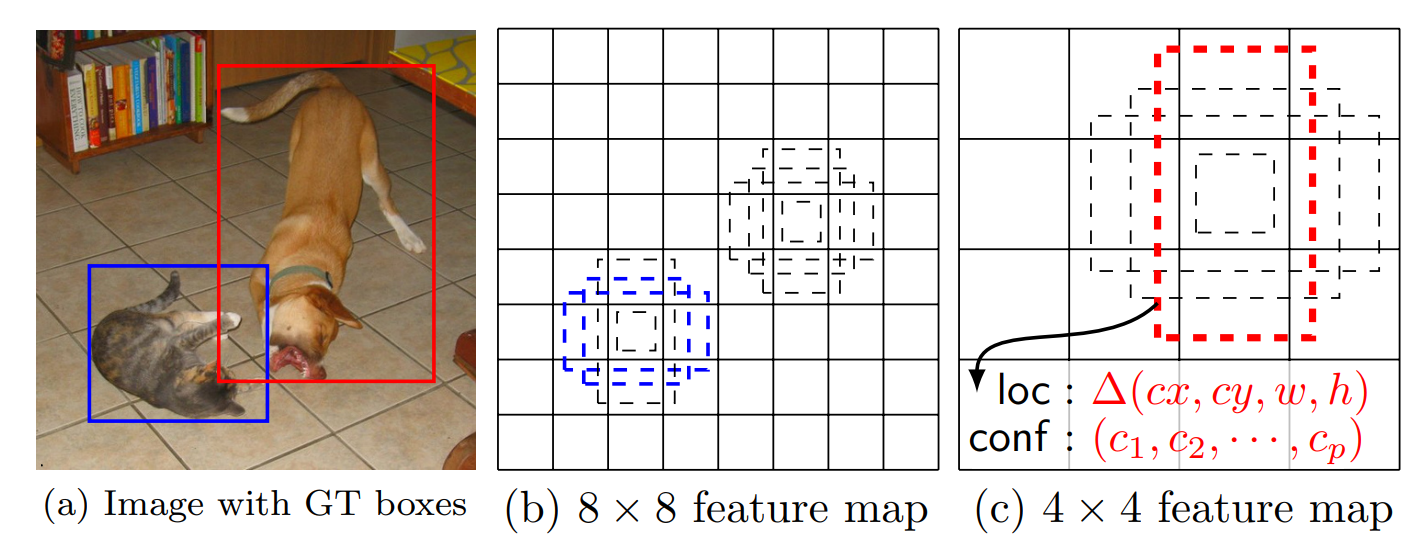
SSD的核心贡献在于将"多尺度特征图预测"和"默认框(锚点)"机制成功结合 ,在一个统一的单阶段框架内,同时实现了高速度 、高精度 (尤其是对小物体)和对物体形状的良好适应性。
在不同尺度(实现不同大小) 的特征图上,为每个位置生成多个默认框(实现不同形状)
然后预测偏移量和类别分数,最后通过匹配和损失计算进行训练。
三大关键设计
1. 多尺度特征图检测
-
YOLOv1的局限: 只在最后一层 (7x7的粗粒度特征图)进行预测。这导致小物体检测能力很差 ,因为经过多次下采样后,小物体的信息几乎丢失了。
-
SSD的创新: 使用多个不同尺度的特征图进行预测(例如,38x38, 19x19, 10x10, 5x5, 3x3, 1x1)。
-
浅层特征图(如38x38): 分辨率高,感受野小,包含丰富的细节信息 ,非常适合检测小物体。
-
深层特征图(如1x1): 分辨率低,感受野大,包含高级的语义信息 ,非常适合检测大物体。
-
结果: SSD能自然地处理各种尺寸的物体 ,大大改善了小物体检测性能。
-
2. 默认框(Default Boxes)------ 预定义的锚点
-
YOLOv1的局限: 每个网格单元预测两个边界框,但它们的形状是模型自由学习 的,在训练初期很不稳定,且难以适应各种形状的物体。
-
SSD的创新: 在每个特征图的每个位置,预先定义一组不同大小和宽高比的"默认框" 。可以理解为预先铺好各种形状的**"锚点"**。
-
网络的任务不再是直接回归框的绝对坐标,而是预测每个默认框的偏移量 和类别置信度。
-
好处:
-
训练更稳定 :学习目标是偏移量 ,而不是凭空创造坐标,任务更简单。
-
应对多种形状:通过设置不同宽高比的默认框(如1:1, 1:2, 2:1),模型更容易匹配各种形状的物体(如瘦高的人、扁平的汽车)。
-
-
3. 卷积预测
-
YOLOv1的局限: 使用全连接层进行预测,这会破坏特征图的空间结构,并且参数量大。
-
SSD的创新: 使用小卷积核 (如3x3)在特征图上进行滑动窗口式的预测。
-
对于每个特征图上的每个点,应用卷积核直接输出(类别数+4个坐标偏移)* 该点的默认框数量。
-
好处:
-
保持了空间信息:更适合检测任务。
-
更高效:参数更少,速度更快。
-
可以灵活应用于任何尺寸的特征图:这是实现多尺度预测的基础。
-
-
技巧设计
1. 匹配策略: 确定哪些默认框需要负责学习预测哪个真实物体。
-
SSD的创新(两步匹配):
-
最佳匹配: 为每个真实物体找到与其IOU最大的默认框。确保每个物体都至少有一个"负责人"。
-
阈值匹配: 再将所有与任意真实物体IOU超过0.5的默认框都设为正样本。
-
-
为什么这样设计?
- 简化学习: 一个物体可能被多个形状相近 的默认框较好地覆盖。让网络为所有这些"还不错"的框都学习预测 该物体,比强迫它必须只挑出最好的那一个要更容易。这增加了正样本数量,缓解了正负样本不平衡。
2. 难例挖掘:解决正负样本极端不平衡的关键
-
问题: 一张图可能只有几个物体,但会产生数千个默认框 ,其中绝大部分都是容易分类的背景(负样本)。如果全部用于训练,简单背景的梯度会"淹没"物体和难分背景的梯度。
-
SSD的解决方案: 不是全部使用,而是主动挑选那些"最难"的负样本(即模型最容易搞错、信心满满地认为是物体的背景块)。
3. 损失函数:Smooth L1 + Softmax
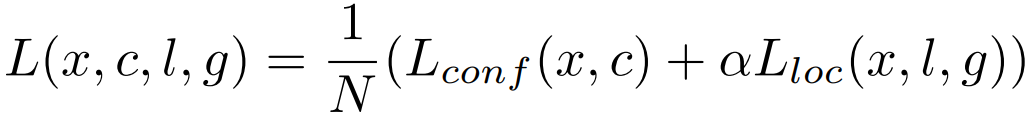
-
L_conf(x, c): 置信度损失 ,负责学习"框里有什么? "或者"框里是不是背景?" -
softmax 正样本和类别p ;背景和类别0
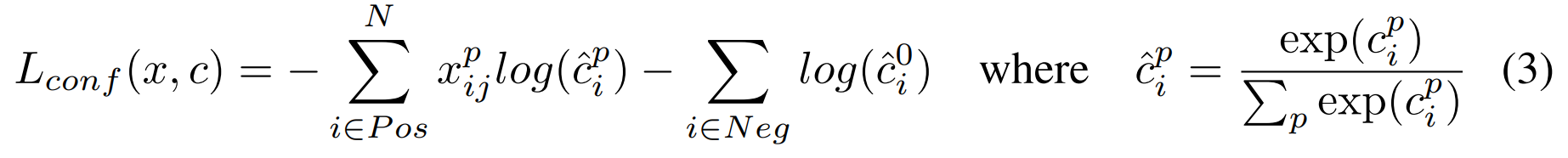
L_loc(x, l, g): 定位损失 ,偏移量ĝ负责学习"框的位置和大小准不准?"
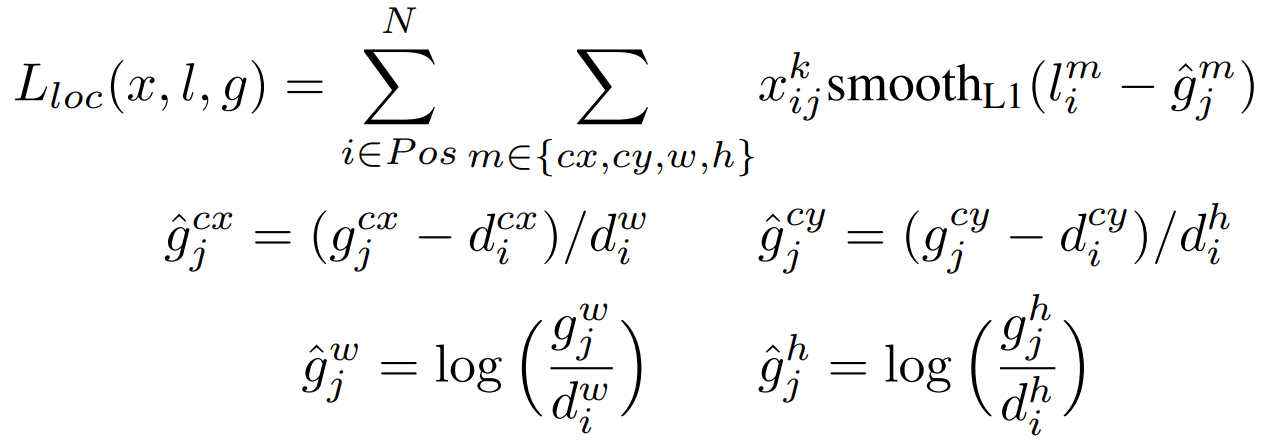
YOLO-v2
https://arxiv.org/pdf/1612.08242
-
通过 BN、锚点框、维度聚类、直接位置预测 提升了定位精度和召回率。
-
通过 Darknet-19 和全卷积设计 保证了速度。
-
通过 多尺度训练 增强了模型鲁棒性 和灵活性。
-
通过 细粒度特征 改善了小物体检测。
-
通过 联合训练 实现了类别数量的巨大突破。
| 改进点 | 描述 | 解决的问题 |
|---|---|---|
| 批归一化 | 在所有卷积层后添加批量归一化(Batch Normalization)。 | 稳定训练,加速收敛,减少对其他正则化方法(如Dropout)的依赖,提升mAP约2%。 |
| 高分辨率分类器 | 先在ImageNet上以448x448的高分辨率(而不仅是224x224)微调分类模型,然后再用于检测。 | 让网络在转向检测任务前就适应更高的分辨率,使其能够更好地处理高分辨率细节。 |
| 卷积化与锚点框 | 移除YOLOv1中的全连接层 ,改用全卷积网络 。引入锚点框(类似Faster R-CNN和SSD的默认框)。 | 全卷积化 使模型能适应不同尺寸 的输入。锚点框 将预测目标从"直接回归坐标"变为"回归相对于锚点框的偏移量",使网络更容易学习,显著提升召回率(Recall)。 |
| 维度聚类 | 对训练集边界框的宽高进行k-means聚类 ,自动选出最具有代表性的锚点框尺寸,而不是手动选择。 | 使得初始的锚点框尺寸更符合数据集的物体形状,为回归提供一个更好的起点,加速模型收敛。 |
| 直接位置预测 | 对基于锚点框的偏移量预测施加约束 ,使用sigmoid函数将预测的中心点坐标限制在其所属的网格单元内。 | 防止模型在训练初期预测不稳定的边界框位置,使训练更稳定。 |
| 细粒度特征 | 引入直通层 ,将浅层高分辨率 特征图(26x26)连接到深层特征图,类似于残差连接或特征金字塔。 | 将浅层的细粒度特征 与深层的高级语义特征 结合,极大改善了小物体检测能力。 |
| 多尺度训练 | 在训练过程中,每经过一定批次(如10个batch),就随机选择一个新的输入图像尺寸(如{320, 352, ..., 608})进行训练。 | 迫使网络学会在不同输入尺度下都能良好预测,从而增强了模型的鲁棒性。同一个模型可以灵活地在速度和精度之间切换(小尺寸快,大尺寸准)。 |