Title
题目
EndoChat: Grounded multimodal large language model for endoscopicsurgery
EndoChat:面向内镜手术的基于事实依据的多模态大型语言模型
01
文献速递介绍
机器人辅助手术与EndoChat模型相关研究内容翻译 机器人辅助手术(RAS)为提升手术精度、减少患者创伤及缩短术后恢复时间提供了前所未有的可能(Nwoye 等,2023)。然而,该技术的有效应用对 surgeons(外科医生)的技能提出了极高要求,尤其是在手术过程中掌握机器人系统操作方面(Alabi 等,2025;Wagner 等,2023)。为确保手术安全与效果,外科医生必须接受严格培训,以掌握机器人操作所需的核心技能(Chen 等,2020;Aziz 等,2021)。 为提高培训效率,研究人员开发了多种基于模拟器的手术培训平台(Mariani 等,2020)。但在培训过程中,学员遇到问题时,往往需要专业外科医生即时提供反馈与指导,以解决疑惑或纠正错误。遗憾的是,专业外科医生因临床、教学与科研工作繁重,时间十分紧张(Sharma 等,2021;Seenivasan 等,2022),难以在培训期间提供持续、实时的支持。因此,目前迫切需要能在手术培训中提供灵活、实时且高效支持的技术方案。 近年来,具备结构化视觉问答(VQA)功能的人工智能(AI)对话系统已被引入手术培训领域(Seenivasan 等,2022;Bai 等,2023b)。这类系统通过分析手术场景的视觉数据来解答学员的问题。但它们依赖简单的、基于目标存在性的结构化VQA数据集,且通常为特定任务训练,难以灵活应对学员提出的各类问题(Lin 等,2023b)。此外,多数此类方法基于编码器-解码器架构,需要明确定义输入/输出格式。这种刚性使其在处理高度开放式生成任务时灵活性不足,且可扩展性受限。当应用场景超出设计范围时,这些模型的性能会大幅下降,无法适配复杂多样的手术场景(Gozalo-Brizuela 与 Garrido-Merchan,2023)。面对学员的开放式问题,现有VQA系统缺乏必要的灵活性与语境理解能力,难以处理开放式问题或复杂的多轮对话,极大限制了其在手术培训中的实用价值。 当前,医疗领域的多模态大型语言模型(MLLMs)正成为极具潜力的解决方案。通过大规模预训练,它们具备跨任务完成复杂推理与理解的能力,前景广阔(Li 等,2024b;Chen 等,2024b;Ye 等,2024;Liu 等,2023)。具体而言,多模态大型语言模型能够从手术场景的多模态数据中提取信息,并进行高级推理。与结构化问答系统不同,它们可处理非结构化且复杂的语境信息。例如,学员可用自然语言提出开放式问题,多模态大型语言模型借助预训练知识与多模态推理能力生成针对性回答。强大的自然语言处理能力使其能够处理多轮对话,并根据语境动态调整回答内容。这种交互模式类似于获得专业外科医生的指导,可显著提升培训体验。总体而言,多模态大型语言模型有望通过模拟专业外科医生的知识与决策能力,部分替代其指导工作。这不仅能解决现有培训方案的局限性,还能减轻临床日程紧张的外科医生的负担,最终提升手术培训的效率与质量(Chen 等,2024b;Dou 等,2023)。 手术领域的多模态大型语言模型已引起研究人员的广泛关注(Li 等,2024a;Jin 与 Jeong,2024;Wang 等,2025)。但现有手术多模态大型语言模型主要聚焦于以下三种思路之一:利用多模态大型语言模型的强大能力提升问答性能(Hou 等,2024);通过指令微调扩展模型以适配特定预定义任务(Wang 等,2025);利用网络来源数据构建通用描述性与对话性数据集(Li 等,2024a)。这些方法面临两大挑战:(1)在实际场景中,学员的提问极具多样性,仅依赖预定义的提问格式或通用描述,无法应对实际场景中学员的各类问题;(2)目前许多多模态大型语言模型应用依赖预训练视觉编码器提取视觉特征(Li 等,2024a;Liu 等,2024b),但由于领域差异,通用视觉场景的语义信息无法直接应用于手术场景,导致模型对视觉信息的理解不足,且出现推理幻觉(即生成与实际不符的内容)。 为解决这些挑战,我们从两方面入手:构建开放式、知识密集型的手术视觉-语言数据集,以及开发针对手术场景定制的视觉增强型多模态大型语言模型。首先,我们开发了Surg-396K数据集------一款专为手术场景设计的手术多模态指令数据集。我们从三个公开数据集中系统性提取手术属性信息,并利用多种对话模板生成指令微调数据。为更好地模拟实际场景(如表1所示),我们提出五种不同的对话范式,以覆盖大多数自然语言对话场景,并定义七项与手术属性相关的下游任务,确保全面涵盖手术场景理解需求。因此,基于Surg-396K训练的多模态大型语言模型能更好地实现"外科医生-系统"交互,在手术场景中高效响应,为手术培训与教学提供实用、可靠的支持。 其次,在多模态大型语言模型的架构设计中,我们研发了混合视觉令牌引擎(MVTE),通过多尺度提取视觉信息,实现手术场景下更优的视觉-语言对齐。与传统框架直接采用预训练视觉Transformer(ViTs)提取视觉令牌不同,MVTE利用多个视觉塔进行视觉令牌的提取、交互与融合,在与文本对齐前优化视觉信息提取效果。此外,为减少模型幻觉,我们提出一种基于视觉对比的方法:对比原始视觉输入与失真视觉输入生成的输出结果。该方法通过施加自适应合理性约束,优化令牌选择过程,确保在内镜手术场景中视觉输入与语言输出的一致性。 基于上述工作,我们提出EndoChat模型(如图1所示),以支持内镜手术场景中的多种对话范式。这一灵活框架能有效满足多样化的交互需求,支持各类手术任务,可灵活适配学员在不同场景下可能提出的各类问题。 为验证EndoChat的有效性,我们首先在不同对话范式下,将其与商用及开源多模态大型语言模型进行严格对比。结果表明,无论是手术理解准确性还是对话能力,我们的方法均优于现有通用型与医疗专用型多模态大型语言模型。此外,在手术场景理解的各类属性相关子任务中,我们的模型均实现了当前最优(state-of-the-art)性能。消融实验进一步证实了多模态大型语言模型框架中创新架构设计的有效性。同时,我们邀请经验丰富的执业外科医生独立评估:该辅助工具是否有助于推进手术培训流程,以及他们是否愿意采用。评估结果显示,外科医生对EndoChat持积极态度,这进一步证明EndoChat是适用于各类手术培训与教学场景的合格辅助工具。综上,EndoChat标志着多模态大型语言模型在手术培训应用中的重要突破,能为学员提供智能、语境感知的辅助支持。 本研究的核心贡献总结如下: 1. 提出EndoChat------一款新型基于事实依据的多模态大型语言模型,支持内镜手术场景中的五种对话范式与七项属性相关手术子任务,满足手术培训与指导中对高效对话系统的需求。 2. 开发Surg-396K数据集:通过多对话构建流程,系统性提取手术信息并生成结构化标注,构建包含39.6万组图像-指令对的综合型手术多模态数据集。 3. EndoChat集成混合视觉令牌引擎,增强多尺度视觉信息的提取与融合;同时融入基于视觉对比的方法,解决多模态大型语言模型中的目标幻觉问题。 4. 在提出的数据集上开展大量实验,结果表明:在各类对话范式与手术场景理解子任务中,EndoChat均优于现有通用型与医疗专用型多模态大型语言模型。此外,通过经验丰富的内镜医师进行专家评估,验证了EndoChat的实际效用,证实其有望成为提升手术培训与教学质量的有效工具。
Aastract
摘要
Recently, Multimodal Large Language Models (MLLMs) have demonstrated their immense potential incomputer-aided diagnosis and decision-making. In the context of robotic-assisted surgery, MLLMs can serveas effective tools for surgical training and guidance. However, there is still a deficiency of MLLMs specializedfor surgical scene understanding in endoscopic procedures. To this end, we present EndoChat, an MLLMtailored to address various dialogue paradigms and subtasks in understanding endoscopic procedures. Totrain our EndoChat, we construct the Surg-396K dataset through a novel pipeline that systematically extractssurgical information and generates structured annotations based on large-scale endoscopic surgery datasets.Furthermore, we introduce a multi-scale visual token interaction mechanism and a visual contrast-basedreasoning mechanism to enhance the model's representation learning and reasoning capabilities. Our modelachieves state-of-the-art performance across five dialogue paradigms and seven surgical scene understandingtasks. Additionally, we conduct evaluations with professional surgeons, who provide positive feedback onthe majority of conversation cases generated by EndoChat. Overall, these results demonstrate that EndoChathas the potential to advance training and automation in robotic-assisted surgery.
EndoChat相关研究内容翻译 近年来,多模态大型语言模型(MLLMs)在计算机辅助诊断与决策领域展现出巨大潜力。在机器人辅助手术场景中,多模态大型语言模型可作为手术培训与指导的有效工具。然而,目前仍缺乏专门针对内镜手术中手术场景理解的多模态大型语言模型。为此,我们提出了EndoChat------一款专为解决内镜手术理解中的各类对话范式及子任务而定制的多模态大型语言模型。 为训练EndoChat,我们通过一种新颖的流程构建了Surg-396K数据集:该流程基于大规模内镜手术数据集,系统性地提取手术信息并生成结构化标注。此外,我们引入多尺度视觉令牌交互机制与基于视觉对比的推理机制,以增强模型的表征学习能力与推理能力。 实验结果表明,我们的模型在5种对话范式及7项手术场景理解任务中均取得了当前最优(state-of-the-art)性能。同时,我们还邀请专业外科医生进行评估,医生们对EndoChat生成的大部分对话案例给予了积极反馈。总体而言,这些结果证明EndoChat有望推动机器人辅助手术在培训与自动化领域的发展。
Method
方法
3.1. Surgical multimodal instruction dataset: Surg-396KThe AI-assisted surgery field has experienced a notable expansion inthe availability of public multimodal datasets, particularly VQA pairs,as evidenced by works ranging from Seenivasan et al. (2022) to Yuanet al. (2024). However, the availability of multimodal instruction dataremains limited, primarily due to the time-intensive and less standardized processes involved in human crowd-sourcing. To promote thedevelopment of MLLMs tailored for surgical understanding, we proposeSurg-396K, a surgical multimodal instruction dataset incorporating41K images and 396K instruction-following annotations for endoscopicsurgery. Following the data generation process shown in Fig. 2, wedefine five conversational paradigms and seven attribute-related subtasks to capture the majority of natural language dialogues whileensuring comprehensive coverage of surgical scene understanding. Thestyle of these conversation types and sub-tasks is shown in Table 1.
3.1 手术多模态指令数据集:Surg-396K 在人工智能辅助手术领域,公开多模态数据集(尤其是视觉问答(VQA)对)的可获取性显著提升,从Seenivasan等人(2022)到Yuan等人(2024)的相关研究均体现了这一点。然而,多模态指令数据的可获取性仍十分有限,这主要是因为人工众包过程耗时且标准化程度较低。 为推动面向手术场景理解的多模态大型语言模型(MLLMs)发展,我们提出了Surg-396K数据集------这是一个针对内镜手术的手术多模态指令数据集,包含4.1万幅图像与39.6万条指令遵循型标注。 参照图2所示的数据生成流程,我们定义了五种对话范式与七项属性相关子任务:一方面覆盖大多数自然语言对话场景,另一方面确保全面涵盖手术场景理解需求。这些对话类型与子任务的具体形式如表1所示。
Conclusion
结论
In this paper, we introduce Surg-396K, a comprehensive surgicalmultimodal dataset that includes 396K image-instruction pairs acrossmultiple conversation paradigms. Based on Surg-396K, we present aflexible surgical understanding MLLM, EndoChat, designed to integratevarious downstream tasks in surgical scene understanding and supportdifferent dialogue paradigms that may occur between surgeons andchatbots. Endochat integrates the Mixed Visual Token Engine (MVTE)and the visual contrast-based hallucination mitigation strategy, allowing it to effectively capture high-quality visual features and reduce inaccuracies in generated responses. Extensive experiments demonstratedthe effectiveness of our approach, providing a more generalizable solution for understanding the surgical scene. Furthermore, the positivefeedback from expert evaluations underscores the model's practicalapplicability in real-world surgical environments.Moving forward, we will open-source our model weights, trainingcode, and data to promote the development of multimodal AI systemsin the surgical domain. In the future, we will collaborate with surgeonsand clinical systems to conduct more rigorous and extensive validationsto ensure the safety, reliability, and usability of the dialogue model.We aim to integrate EndoChat into surgical training or endoscopicsurgery systems. By using monitors and voice-based dialogue systems,EndoChat could provide direct assistance to surgeons or trainees.
论文核心内容与未来展望 在本文中,我们提出了Surg-396K------一个全面的手术多模态数据集,该数据集包含跨越多种对话范式的39.6万组图像-指令对。基于Surg-396K数据集,我们设计了一款具备灵活手术场景理解能力的多模态大型语言模型(MLLM)EndoChat,其旨在整合手术场景理解中的各类下游任务,并支持外科医生与聊天机器人之间可能出现的不同对话范式。 EndoChat集成了混合视觉令牌引擎(Mixed Visual Token Engine, MVTE)与基于视觉对比的幻觉缓解策略,能够有效捕捉高质量视觉特征,并降低生成响应中的不准确内容。大量实验验证了我们所提方法的有效性,为手术场景理解提供了更具泛化性的解决方案。此外,专家评估给出的积极反馈,也凸显了该模型在真实手术环境中的实际应用价值。 展望未来,我们将开源模型权重、训练代码及数据,以推动手术领域多模态人工智能系统的发展。后续,我们将与外科医生及临床系统展开合作,进行更严格、更广泛的验证,确保该对话模型的安全性、可靠性与可用性。我们的目标是将EndoChat整合到手术培训或内镜手术系统中:通过显示器与基于语音的对话系统,EndoChat可直接为外科医生或实习医生提供辅助支持。
Results
结果
4.1. Implementation details
We conduct comparative experiments against multiple MLLMs,including BiomedGPT (Zhang et al., 2024b), LLAVA-Med (Li et al.,2024b), Qwen2.5-VL-7B (Bai et al., 2025a), LLaMA-3.2-11B (Grattafioriet al., 2024), Gemma-3-12B (Team et al., 2025), Qwen2-VL-7B (Wanget al., 2024a), GLM-4V-9B (GLM et al., 2024), MiniGPTv2 (Chen et al.,2023), LLAVA-1.5-13B (Liu et al., 2024a), and SPHINX (Lin et al.,2023a). These benchmarks cover the current state-of-the-art withinopen-source, general-purpose models of comparable parameter scaleto our EndoChat. Additionally, we benchmark our method againsta range of specialized models, namely VisualBert (Li et al., 2019),VisualBert ResMLP (Seenivasan et al., 2022), MCAN (Ben-Younes et al.,2017), VQA-DeiT (Touvron et al., 2021), MUTAN (Ben-Younes et al.,2017), MFH (Yu et al., 2018), BlockTucker (Ben-Younes et al., 2019),CAT-ViL DeiT (Bai et al., 2023a), GVLE-LViT (Bai et al., 2023b),and Surgical-LVLM (Wang et al., 2025). All evaluation metrics in theresults are presented in percentage form, except for CIDEr. To trainthe LLM and the Mixed Visual Token Engine, we utilize an inputresolution of 1024 × 1024. We conduct the training on the Surg-396Kdataset for a single epoch, employing four NVIDIA A800 GPUs. Weutilize AdamW (Loshchilov and Hutter, 2019) optimizer with an initiallearning rate of 2e-5, following a cosine decay schedule and a linearwarm-up phase. The training process employs a batch size of 16 and iscompleted in approximately 20 hours.We conduct four types of MLLM comparison experiments: zero-shotcomparison (Tables 3--7), fine-tuning comparison (Table 8), generalization comparison (Table 9) and ablation study (Table 10). Apart fromthe MLLM comparison, in Tables 4 and 5, we also introduce specializedmodels (e.g., VisualBERT, MCAN) that are trained on the training set ofthe comparison dataset before testing. For generalization comparison,all MLLMs are trained on the Surg-396K dataset before evaluating onthe out-of-distribution datasets PSI-AVA-VQA (Seenivasan et al., 2023)and EndoVis-17-VQLA-Extend (Bai et al., 2025b).For training and evaluation on the Surg-396K dataset, three constituent datasets all follow the data splitting scheme of their sourcedataset (Bai et al., 2023b; Wang et al., 2024c; Seenivasan et al.,2022). Consequently, Surg-396K comprises 34,277 training imageswith 339,098 QA pairs, and 7097 test images with 57,494 QA pairs.
4.1 实现细节 我们与多个多模态大型语言模型(MLLM)开展对比实验,包括BiomedGPT(Zhang 等,2024b)、LLAVA-Med(Li 等,2024b)、Qwen2.5-VL-7B(Bai 等,2025a)、LLaMA-3.2-11B(Grattafiori 等,2024)、Gemma-3-12B(Team 等,2025)、Qwen2-VL-7B(Wang 等,2024a)、GLM-4V-9B(GLM 等,2024)、MiniGPTv2(Chen 等,2023)、LLAVA-1.5-13B(Liu 等,2024a)以及SPHINX(Lin 等,2023a)。这些基准模型涵盖了当前开源领域内与我们的EndoChat参数规模相当的通用型最优模型。此外,我们还将所提方法与一系列专用模型进行基准测试对比,即VisualBert(Li 等,2019)、VisualBert ResMLP(Seenivasan 等,2022)、MCAN(Ben-Younes 等,2017)、VQA-DeiT(Touvron 等,2021)、MUTAN(Ben-Younes 等,2017)、MFH(Yu 等,2018)、BlockTucker(Ben-Younes 等,2019)、CAT-ViL DeiT(Bai 等,2023a)、GVLE-LViT(Bai 等,2023b)以及Surgical-LVLM(Wang 等,2025)。结果中的所有评估指标均以百分比形式呈现,CIDEr指标除外。 在训练大型语言模型(LLM)与混合视觉令牌引擎(Mixed Visual Token Engine)时,我们采用1024×1024的输入分辨率。训练在Surg-396K数据集上进行,仅训练一个轮次(epoch),使用4块NVIDIA A800 GPU。优化器采用AdamW(Loshchilov 和 Hutter,2019),初始学习率设为2e-5,学习率调度策略采用余弦衰减(cosine decay),并包含线性预热阶段(linear warm-up)。训练过程中批次大小(batch size)设为16,训练时长约20小时。 我们开展了四类多模态大型语言模型对比实验:零样本对比(表3-表7)、微调对比(表8)、泛化能力对比(表9)以及消融实验(表10)。除多模态大型语言模型对比外,在表4和表5中,我们还引入了专用模型(如VisualBERT、MCAN),这些模型在测试前均在对比数据集的训练集上完成训练。在泛化能力对比实验中,所有多模态大型语言模型均先在Surg-396K数据集上训练,随后在分布外数据集PSI-AVA-VQA(Seenivasan 等,2023)与EndoVis-17-VQLA-Extend(Bai 等,2025b)上进行评估。 在Surg-396K数据集上进行训练与评估时,其包含的三个子数据集均遵循各自源数据集(Bai 等,2023b;Wang 等,2024c;Seenivasan 等,2022)的数据划分方案。最终,Surg-396K数据集包含34277张训练图像(含339098组问答对)与7097张测试图像(含57494组问答对)。
Figure
图
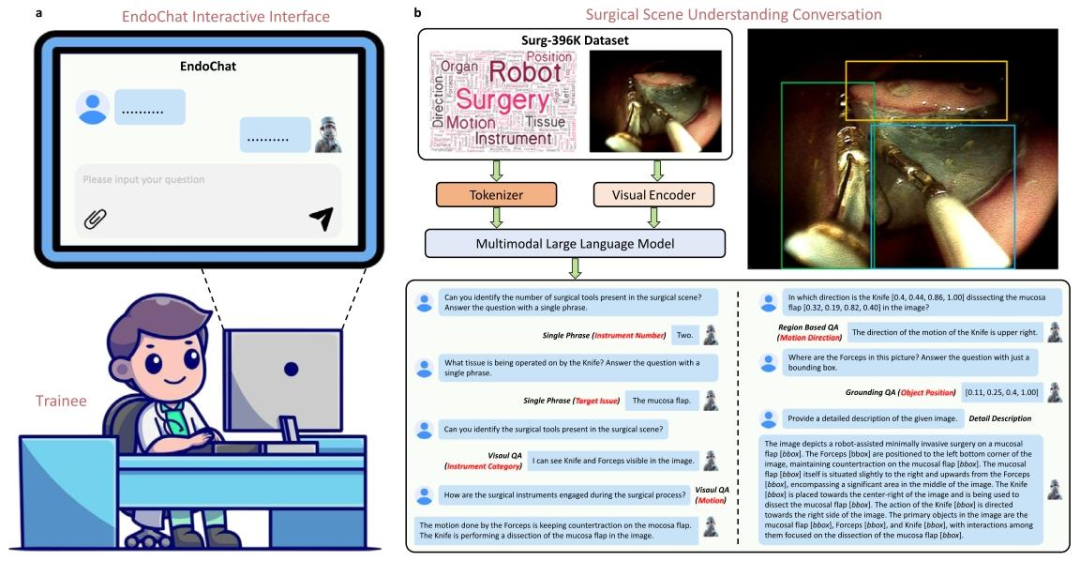
Fig. 1. Overview of the EndoChat. a EndoChat is an interactive multimodal large language model designed for surgical education and training. Users can interactwith EndoChat by uploading images and formulating questions, enabling a comprehensive surgical scene understanding. b EndoChat is trained on Surg-396K, alarge-scale multimodal instruction dataset. Surg-396K includes five conversation paradigms, enabling EndoChat to effectively perform natural language and visualgrounding conversations with trainees. On the bottom is an example of the multi-turn conversation.
图1 EndoChat模型概述 a EndoChat是专为手术教学与培训设计的交互式多模态大型语言模型。用户可通过上传图像并提出问题与EndoChat交互,实现对手术场景的全面理解。 b EndoChat基于大规模多模态指令数据集Surg-396K训练。Surg-396K涵盖五种对话范式,使EndoChat能与学员有效开展自然语言及视觉关联对话。图下方展示了一个多轮对话示例。
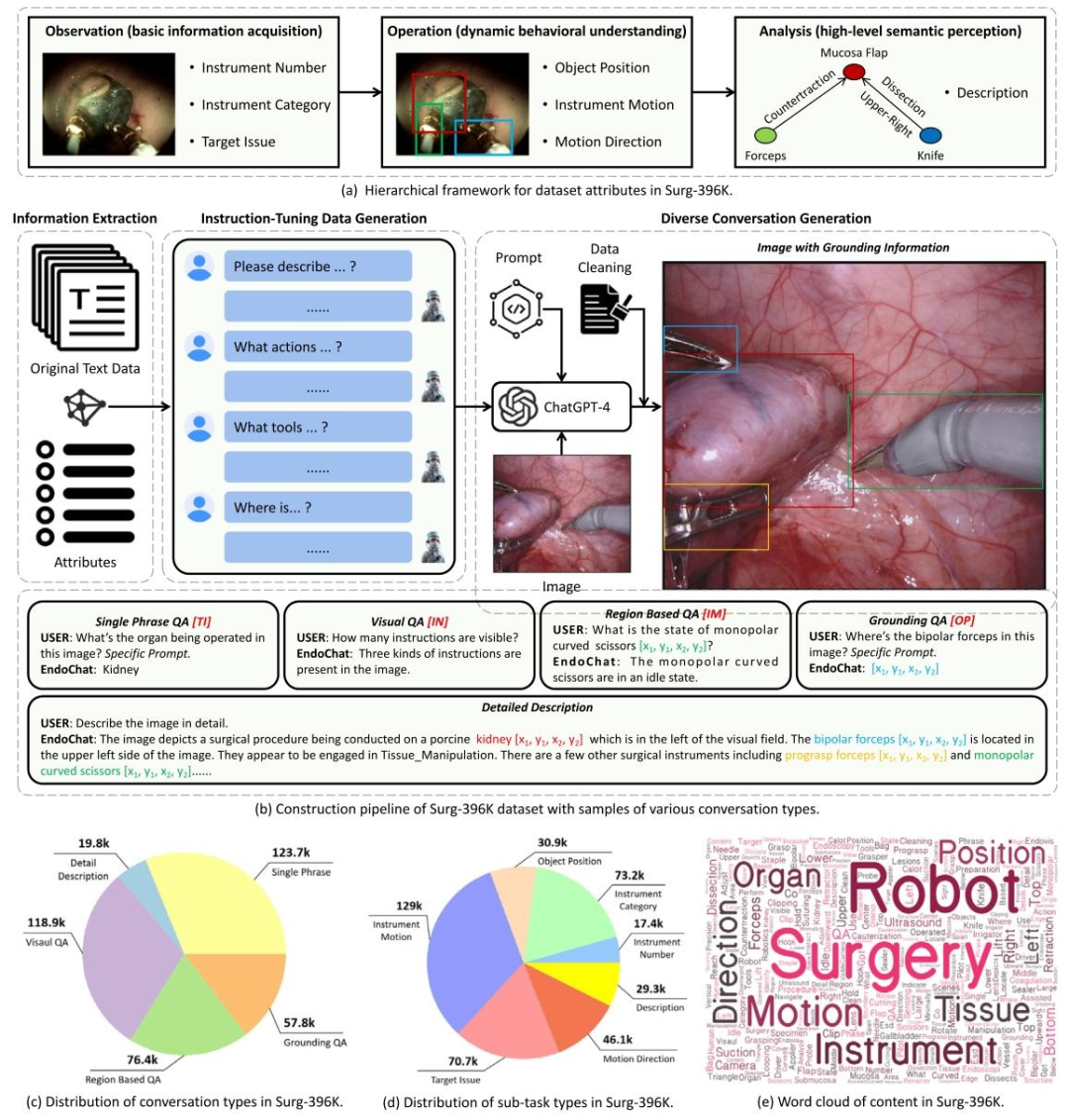
Fig. 2. Overview of the construction pipeline and distribution statistics for our Surg-396K dataset. The pipeline involves five key steps: annotation attributeanalysis, information extraction, instruction-tuning data generation, diverse conversation generation, and data validation.
图2 Surg-396K数据集的构建流程与分布统计概述 该数据集构建流程包含五个关键步骤,依次为:标注属性分析、信息提取、指令微调数据生成、多样化对话生成、数据验证。
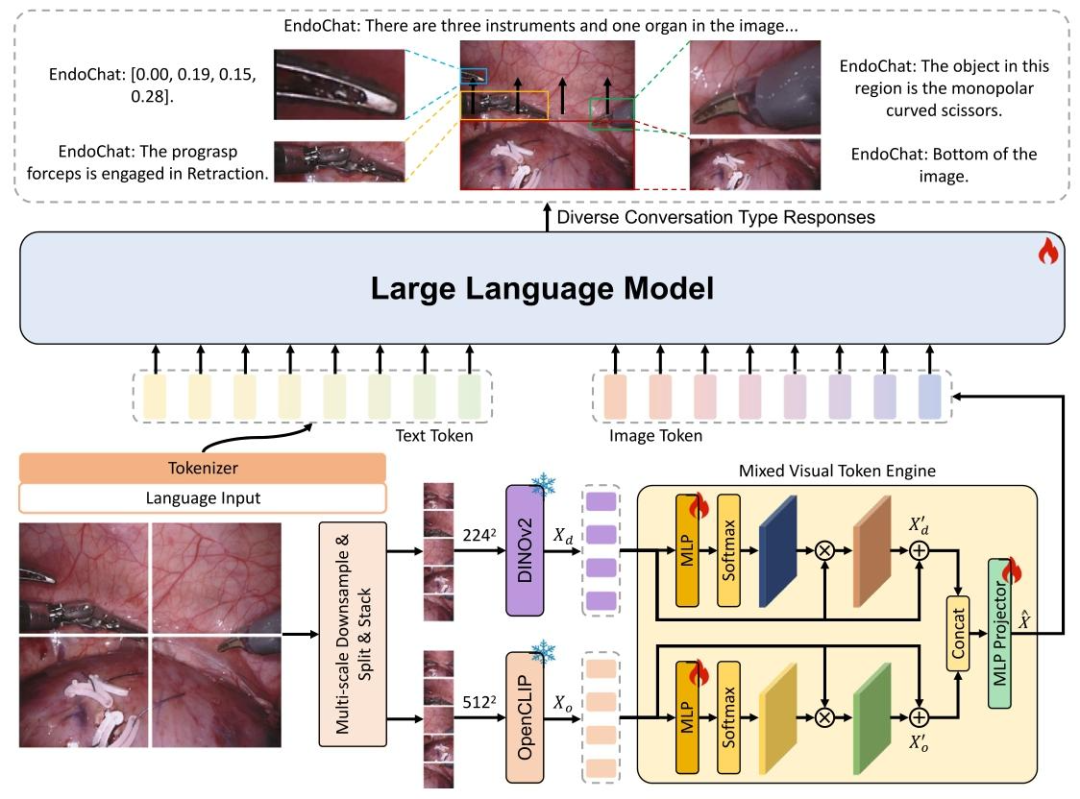
Fig. 3. The overview of the proposed EndoChat. For each input image, we use a multi-scale downsampling strategy to generate different scales and sub-images.2242 and 5122 indicate concatenated features with the shapes 5 × 224×224 × 3 and 5 × 512×512 × 3, respectively. These features are subsequently encodedusing a mixed visual backbone, followed by the Mixed Visual Token Engine. The resulting vision tokens are then transformed into language space, suitable forinput to the Large Language Model. In addition to visual inputs, region coordinates can be auxiliary inputs, along with specific prompts to guide user-definedtasks. This enables the LLM to generate language responses for related object regions.
图3 所提EndoChat模型概述 对于每张输入图像,我们采用多尺度下采样策略生成不同尺度的子图像。其中,224²和512²分别代表形状为5×224×224×3和5×512×512×3的拼接特征。这些特征随后通过混合视觉骨干网络进行编码,接着输入至混合视觉令牌引擎(Mixed Visual Token Engine)。生成的视觉令牌会被转换到语言空间,以适配大型语言模型(Large Language Model, LLM)的输入格式。 除视觉输入外,区域坐标可作为辅助输入,结合特定提示词(prompts)指导用户定义的任务。这一设计使大型语言模型能够针对相关目标区域生成语言响应。
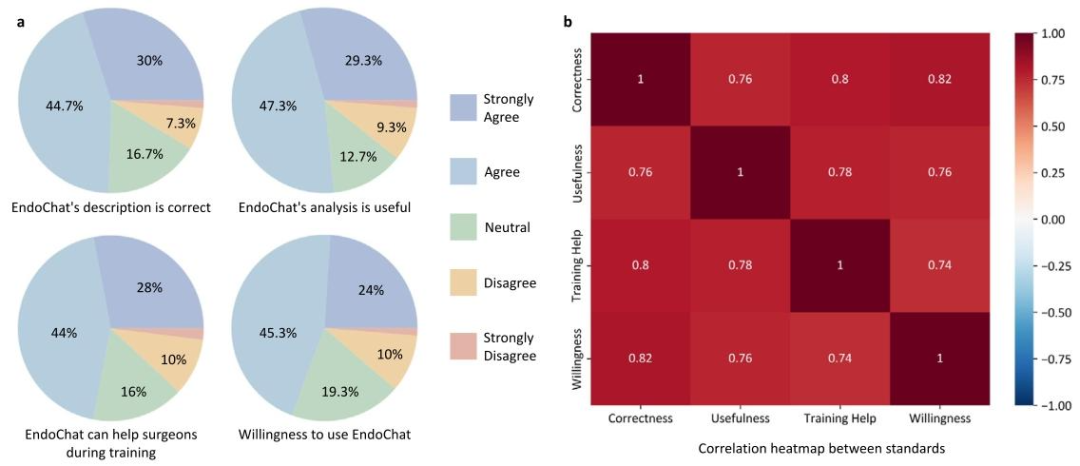
Fig. 4. Endoscopist evaluation of EndoChat in 150 cases. a Questionnaire-based evaluation of EndoChat conducted by endoscopists. The pie charts illustratethe distribution of cases in which endoscopists express varying levels of agreement. b Correlation analysis of four evaluation standards.
图4 内镜医师对EndoChat在150个案例中的评估结果 a 由内镜医师开展的基于问卷的EndoChat评估。饼图展示了内镜医师对不同同意程度案例的分布情况。 b 四项评估标准的相关性分析。
Table
表
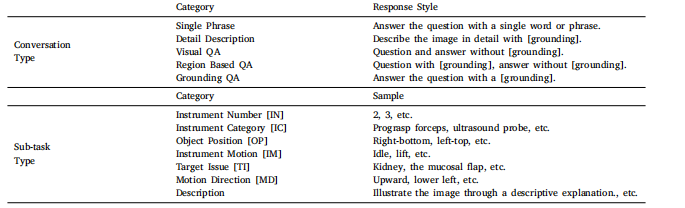
Table 1List of attributes (with abbreviations) and conversation types designed for Surg-396K
表1 为Surg-396K数据集设计的属性(含缩写)及对话类型清单

Table 2The comparison of Surg-396K with existing surgical scene understanding benchmarks. In the ''Surgery Type'' column, ''LC'' indicates LaparoscopicCholecystectomy, ''Ne'' indicates Nephrectomny. ''Pr'' indicates Prostatectomy. ''SD'' indicates Submucosal Dissection.
表2 Surg-396K数据集与现有手术场景理解基准数据集的对比 在"手术类型"列中,"LC"代表腹腔镜胆囊切除术,"Ne"代表肾切除术,"Pr"代表前列腺切除术,"SD"代表黏膜下剥离术。
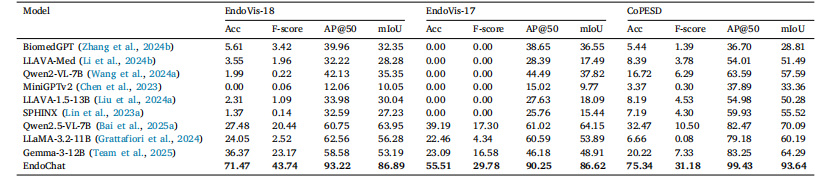
Table 3Comparison experiments with zero-shot MLLMs in Single Phrase QA and Grounding QA on three parts of the Surg-396K dataset
表3 在Surg-396K数据集的三个子数据集上,与零样本多模态大型语言模型(MLLMs)在"单句问答(Single Phrase QA)"和"关联问答(Grounding QA)"任务中的对比实验
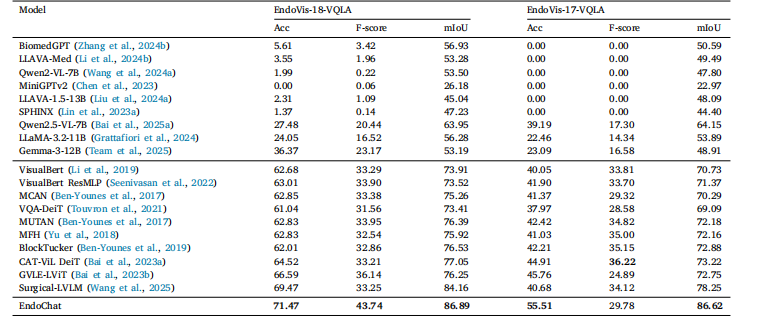
Table 4 Comparison experiments with zero-shot MLLMs (top) and specialized models (middle) in Single Phrase QA and Grounding QA on EndoVis-VQLA(Bai et al., 2023b) dataset
表4 在EndoVis-VQLA数据集(Bai 等,2023b)的"单句问答(Single Phrase QA)"与"关联问答(Grounding QA)"任务中,与零样本多模态大型语言模型(MLLMs,表上半部分)及专用模型(表中间部分)的对比实验
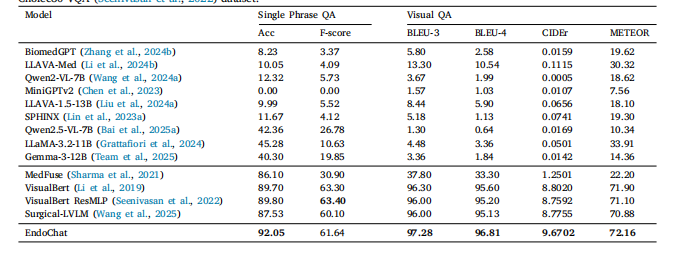
Table 5Comparison experiments with zero-shot MLLMs (top) and specialized models (middle) in Single Phrase QA and Visual QA onCholec80-VQA (Seenivasan et al., 2022) dataset.
表5 在Cholec80-VQA数据集(Seenivasan 等,2022)的"单句问答(Single Phrase QA)"与"视觉问答(Visual QA)"任务中,与零样本多模态大型语言模型(MLLMs,表上半部分)及专用模型(表中间部分)的对比实验
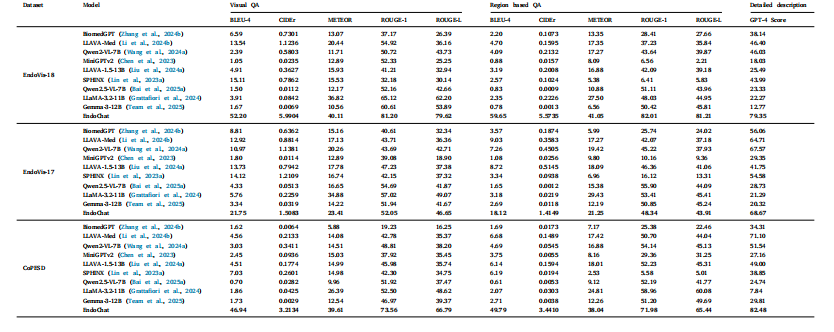
Table 6Comparison experiments with zero-shot MLLMs in Visual QA, Region based QA, and detailed description on Surg-396K dataset.
表6 在Surg-396K数据集上,与零样本多模态大型语言模型(MLLMs)在视觉问答(Visual QA)、基于区域的问答(Region based QA)及详细描述任务中的对比实验
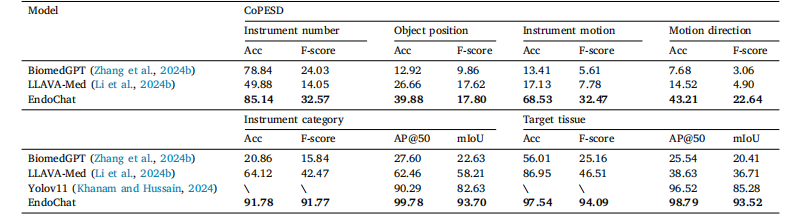
Table 7Comparison experiments with zero-shot medical-specialized MLLMs in various surgical scene understanding tasks (excluding the Description task, whichhas been shown in Table 6) on the CoPESD part of Surg-396K dataset. Six types of tasks include: the number of instruments, the object location inthe surgical scene (textual form), the current motion of the instrument, the direction of instruction motion, the identification of instruments, instrumentdetection, the recognition of issues and issue detection
表7 在Surg-396K数据集的CoPESD子数据集上,与零样本医疗专用多模态大型语言模型(MLLMs)在各类手术场景理解任务(不含"描述任务",该任务结果已见于表6)中的对比实验。 六种任务包括:器械数量统计、手术场景中目标位置(文本形式)、器械当前动作、指示动作方向、器械识别、器械检测、问题识别与问题检测。
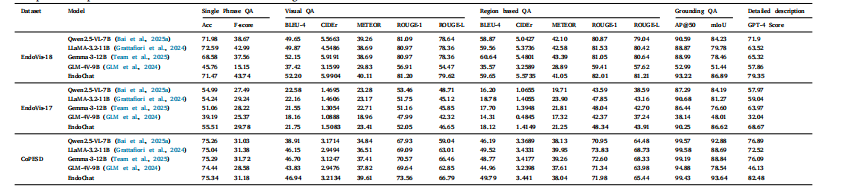
Table 8Comparison experiments with fine-tuned MLLMs on Surg-396K dataset.
表8 在Surg-396K数据集上,与经过微调的多模态大型语言模型(MLLMs)的对比实验

Table 9Generalization experiments with fine-tuned MLLMs on PSI-AVA-VQA and EndoVis-17-VQLA-Extend dataset
表9 在PSI-AVA-VQA与EndoVis-17-VQLA-Extend数据集上,与经过微调的多模态大型语言模型(MLLMs)的泛化能力实验
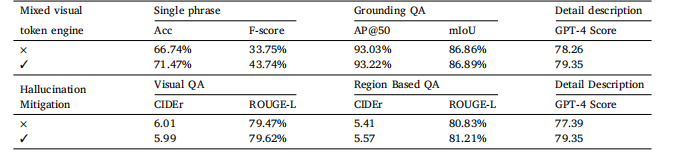
Table 10Ablation study with zero-shot medical-specialized MLLMs on EndoVis-18 part of Surg-396K dataset.Mixed visual Single phrase Grounding QA D
表10 在Surg-396K数据集的EndoVis-18子数据集上,与零样本医疗专用多模态大型语言模型(MLLMs)的消融实验