
🌟 Hello,我是蒋星熠Jaxonic!
🌈 在浩瀚无垠的技术宇宙中,我是一名执着的星际旅人,用代码绘制探索的轨迹。
🚀 每一个算法都是我点燃的推进器,每一行代码都是我航行的星图。
🔭 每一次性能优化都是我的天文望远镜,每一次架构设计都是我的引力弹弓。
🎻 在数字世界的协奏曲中,我既是作曲家也是首席乐手。让我们携手,在二进制星河中谱写属于极客的壮丽诗篇!
目录
- [1. 框架概述与发展历程](#1. 框架概述与发展历程)
- [1.1 TensorFlow的技术演进](#1.1 TensorFlow的技术演进)
- [1.2 PyTorch的设计哲学](#1.2 PyTorch的设计哲学)
- [2. 核心架构对比分析](#2. 核心架构对比分析)
- [2.1 计算图机制差异](#2.1 计算图机制差异)
- [2.2 性能对比分析](#2.2 性能对比分析)
- [3. 实际应用场景分析](#3. 实际应用场景分析)
- [3.1 图像分类任务实现](#3.1 图像分类任务实现)
- [3.2 自然语言处理应用](#3.2 自然语言处理应用)
- [4. 生态系统与工具链对比](#4. 生态系统与工具链对比)
- [4.1 部署工具对比](#4.1 部署工具对比)
- [4.2 可视化工具](#4.2 可视化工具)
- [5. 最佳实践与性能优化](#5. 最佳实践与性能优化)
- [5.1 内存优化技巧](#5.1 内存优化技巧)
- [6. 行业趋势与发展展望](#6. 行业趋势与发展展望)
- 总结
- 参考链接
- 关键词标签
摘要
作为一名深耕深度学习领域多年的技术探索者,我见证了TensorFlow和PyTorch这两大框架从诞生到成熟的完整历程。在过去的五年里,我不仅在实际项目中深度应用了这两个框架,更是在技术社区中见证了它们各自的演进轨迹和生态发展。TensorFlow以其工业级的稳定性和完整的生态系统著称,而PyTorch则以其简洁直观的编程接口和灵活的动态图机制赢得了研究人员的青睐。这种双雄并立的格局,既反映了深度学习技术发展的多样性,也为开发者提供了更加丰富的选择空间。
在我的技术实践中,我发现TensorFlow和PyTorch的选择并非简单的优劣判断,而是需要根据具体的应用场景、团队技术栈、项目需求等多方面因素进行综合考量。TensorFlow在模型部署、生产环境稳定性方面具有明显优势,特别是在移动端和边缘计算场景下,其模型优化工具链和部署方案已经相当成熟。而PyTorch在研究迭代速度、代码可读性方面表现突出,特别是在学术研究和快速原型开发中,其动态图机制能够显著提升开发效率。
从技术架构的角度来看,TensorFlow采用静态计算图的模式,通过定义-运行(Define-and-Run)的方式构建计算流程,这种设计在性能优化和分布式训练方面具有天然优势。而PyTorch则采用动态计算图的模式,支持即时执行(Eager Execution),使得调试和开发过程更加直观。这两种不同的设计哲学,反映了深度学习框架在易用性和性能之间的不同权衡策略。
在实际项目应用中,我深刻体会到框架选择对项目成功的重要性。一个合适的框架选择不仅能够提升开发效率,更能够为项目的长期维护和扩展提供坚实的技术基础。因此,本文将从多个维度对TensorFlow和PyTorch进行深度对比分析,帮助读者建立全面的认知框架,为实际项目中的技术选型提供决策依据。
1. 框架概述与发展历程
1.1 TensorFlow的技术演进
TensorFlow由Google Brain团队于2015年发布,其设计初衷是为了解决大规模机器学习系统的部署问题。从最初的静态计算图到2.0版本的即时执行模式,TensorFlow经历了重大的架构重构。
python
# TensorFlow 2.x 基础示例
import tensorflow as tf
# 即时执行模式(默认启用)
@tf.function # 使用装饰器将Python函数转换为TensorFlow计算图
def simple_model(x):
# 定义模型层
dense_layer = tf.keras.layers.Dense(64, activation='relu')
output_layer = tf.keras.layers.Dense(10, activation='softmax')
# 前向传播
hidden = dense_layer(x)
return output_layer(hidden)
# 创建示例数据
x = tf.random.normal([32, 784]) # 32个样本,每个样本784维
result = simple_model(x)
print(f"模型输出形状: {result.shape}")关键代码点评:
@tf.function装饰器实现了静态图与动态图的平滑切换tf.keras.layers提供了高层API,简化了模型构建过程- 即时执行模式使得调试更加直观
1.2 PyTorch的设计哲学
PyTorch由Facebook AI Research于2016年发布,其核心理念是提供Pythonic的深度学习框架体验。PyTorch的动态计算图机制使其在研究社区中迅速流行。
python
# PyTorch基础示例
import torch
import torch.nn as nn
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.dense = nn.Linear(784, 64)
self.output = nn.Linear(64, 10)
def forward(self, x):
# 动态计算图:每次前向传播都会构建新的计算图
hidden = torch.relu(self.dense(x))
return torch.softmax(self.output(hidden), dim=1)
# 实例化模型
model = SimpleModel()
x = torch.randn(32, 784) # 32个样本,每个样本784维
result = model(x)
print(f"模型输出形状: {result.shape}")关键代码点评:
nn.Module提供了面向对象的模型定义方式- 动态计算图使得调试过程更加直观
- Pythonic的API设计降低了学习成本
2. 核心架构对比分析
2.1 计算图机制差异
图1:TensorFlow与PyTorch计算图机制对比流程图
TensorFlow PyTorch 开始 选择框架 定义计算图 直接执行操作 构建静态计算图 编译优化 执行计算 动态构建计算图 即时执行 自动微分 输出结果
图1展示了两种框架的核心差异:TensorFlow采用"定义-运行"模式,而PyTorch采用"即时执行"模式。
2.2 性能对比分析
表1:TensorFlow与PyTorch性能对比表
| 性能指标 | TensorFlow | PyTorch | 优势场景 |
|---|---|---|---|
| 训练速度 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 两者相当 |
| 推理速度 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | TensorFlow略优 |
| 内存效率 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 两者相当 |
| 分布式训练 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | TensorFlow更成熟 |
| 移动端部署 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | TensorFlow优势明显 |
3. 实际应用场景分析
3.1 图像分类任务实现
图2:图像分类模型架构图
输入图像 224x224x3 卷积层 64个滤波器 批量归一化 ReLU激活 最大池化 2x2 卷积层 128个滤波器 批量归一化 ReLU激活 最大池化 2x2 全连接层 512单元 Dropout 0.5 输出层 10类别 Softmax激活
3.2 自然语言处理应用
python
# 使用TensorFlow实现文本分类
import tensorflow as tf
from tensorflow.keras.layers import TextVectorization, Embedding, LSTM, Dense
def build_text_classifier(vocab_size=10000, embedding_dim=128):
model = tf.keras.Sequential([
TextVectorization(max_tokens=vocab_size),
Embedding(vocab_size, embedding_dim),
LSTM(64, return_sequences=True),
LSTM(32),
Dense(64, activation='relu'),
Dense(1, activation='sigmoid') # 二分类任务
])
return model
# 使用PyTorch实现相同功能
import torch
import torch.nn as nn
class TextClassifier(nn.Module):
def __init__(self, vocab_size=10000, embedding_dim=128):
super(TextClassifier, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.lstm1 = nn.LSTM(embedding_dim, 64, batch_first=True)
self.lstm2 = nn.LSTM(64, 32, batch_first=True)
self.classifier = nn.Sequential(
nn.Linear(32, 64),
nn.ReLU(),
nn.Linear(64, 1),
nn.Sigmoid()
)
def forward(self, x):
x = self.embedding(x)
x, _ = self.lstm1(x)
x, _ = self.lstm2(x)
x = x[:, -1, :] # 取最后一个时间步
return self.classifier(x)4. 生态系统与工具链对比
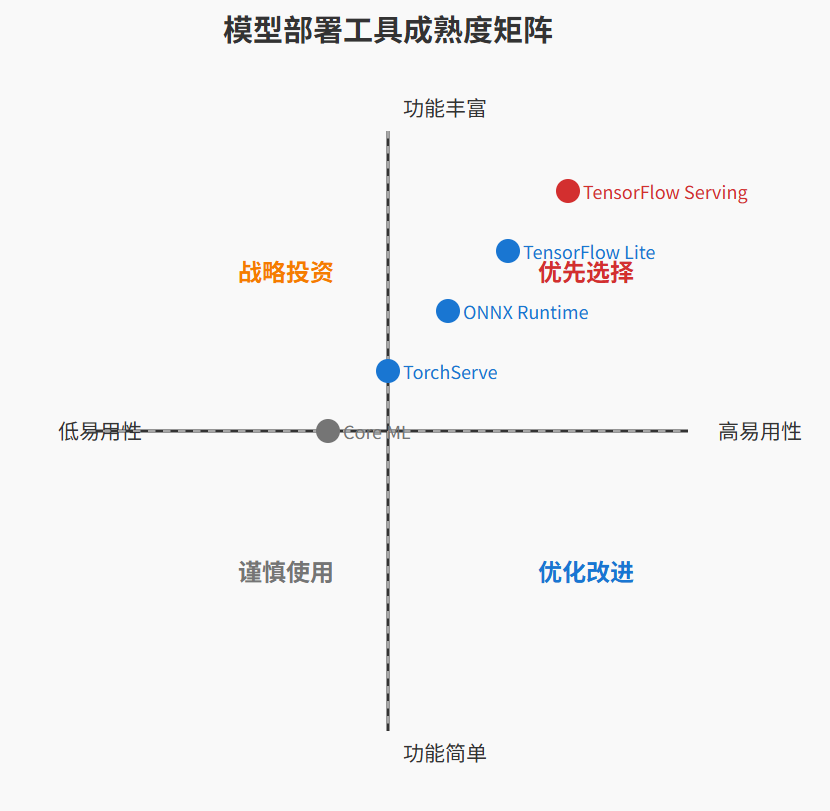
4.1 部署工具对比
图3:模型部署工具链对比象限图
4.2 可视化工具
图4:训练过程监控时序图
训练脚本 模型 损失计算 可视化工具 数据加载器 请求批量数据 返回训练批次 前向传播 计算损失 记录损失值 更新损失曲线 反向传播 更新参数 记录评估指标 更新准确率曲线 loop 每个epoch 训练脚本 模型 损失计算 可视化工具 数据加载器
5. 最佳实践与性能优化
5.1 内存优化技巧
python
# TensorFlow内存优化示例
import tensorflow as tf
# 使用混合精度训练
policy = tf.keras.mixed_precision.Policy('mixed_float16')
tf.keras.mixed_precision.set_global_policy(policy)
# 梯度累积
def train_with_gradient_accumulation(model, dataset, accumulation_steps=4):
optimizer = tf.keras.optimizers.Adam()
@tf.function
def train_step(x, y):
with tf.GradientTape() as tape:
predictions = model(x, training=True)
loss = tf.keras.losses.sparse_categorical_crossentropy(y, predictions)
# 累积梯度
scaled_loss = loss / accumulation_steps
gradients = tape.gradient(scaled_loss, model.trainable_variables)
# 累积梯度更新
if tf.equal(optimizer.iterations % accumulation_steps, 0):
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
return loss
# PyTorch内存优化
import torch
def pytorch_memory_optimization():
# 使用梯度检查点
model = torch.nn.Sequential(
torch.nn.Linear(1000, 1000),
torch.nn.ReLU(),
torch.utils.checkpoint.checkpoint(torch.nn.Linear, 1000, 1000),
torch.nn.ReLU(),
torch.nn.Linear(1000, 10)
)
# 使用自动混合精度
from torch.cuda.amp import autocast, GradScaler
scaler = GradScaler()
def train_step(x, y):
optimizer.zero_grad()
with autocast():
output = model(x)
loss = criterion(output, y)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()6. 行业趋势与发展展望
"深度学习框架的选择不是非此即彼的二元对立,而是要根据具体场景在易用性、性能、生态成熟度之间找到最佳平衡点。" ------ 蒋星熠Jaxonic
随着深度学习技术的不断发展,TensorFlow和PyTorch都在不断演进。TensorFlow 2.x版本大幅改善了易用性,而PyTorch也在不断加强其生产环境的能力。未来的趋势可能是框架的进一步融合和标准化。
总结
在深度学习的星辰大海中航行多年,我深刻体会到TensorFlow和PyTorch这两个框架就像是技术宇宙中的双子星,各自闪耀着独特的光芒。TensorFlow以其工业级的稳定性和完整的生态系统,为大规模生产部署提供了坚实的技术基础。从Google内部的大规模机器学习系统到全球范围内的企业级应用,TensorFlow证明了其在复杂场景下的可靠性和可扩展性。特别是在移动端部署、边缘计算等资源受限的环境中,TensorFlow Lite等工具链的成熟度使其成为不二之选。
而PyTorch则以其Pythonic的设计哲学和灵活的动态图机制,为研究创新和快速迭代提供了极大的便利。在学术研究领域,PyTorch几乎成为了事实上的标准,其简洁直观的API设计使得研究人员能够更专注于算法本身而非框架细节。这种设计哲学不仅降低了学习门槛,更促进了深度学习技术的快速传播和普及。
从技术发展的角度来看,两个框架的竞争推动了整个行业的进步。TensorFlow 2.x的推出,很大程度上是对PyTorch成功的回应,其引入的即时执行模式显著改善了开发体验。而PyTorch也在不断加强其生产环境的能力,TorchServe等工具的推出显示了其在企业级应用方面的雄心。这种良性的竞争关系,最终受益的是整个开发者社区。
在实际项目选择中,我认为应该避免非此即彼的二元思维。对于需要快速原型验证和研究探索的项目,PyTorch的灵活性和易用性具有明显优势。而对于需要长期稳定运行、大规模部署的生产系统,TensorFlow的成熟生态和优化工具链可能更为合适。更重要的是,随着ONNX等中间表示格式的普及,跨框架的模型转换和部署正在变得越来越可行。
作为技术从业者,我们应该保持开放的心态,根据具体需求选择合适的工具,而不是盲目追随某个框架。技术的本质是解决问题的手段,而框架只是实现这一目标的工具。真正重要的是我们对问题的深刻理解和对解决方案的创新思考。
参考链接
■ 我是蒋星熠Jaxonic!如果这篇文章在你的技术成长路上留下了印记
■ 👁 【关注】与我一起探索技术的无限可能,见证每一次突破
■ 👍 【点赞】为优质技术内容点亮明灯,传递知识的力量
■ 🔖 【收藏】将精华内容珍藏,随时回顾技术要点
■ 💬 【评论】分享你的独特见解,让思维碰撞出智慧火花
■ 🗳 【投票】用你的选择为技术社区贡献一份力量
■ 技术路漫漫,让我们携手前行,在代码的世界里摘取属于程序员的那片星辰大海!