前言:
最近国庆假期,有点放松了,好久没写博客,今天学习了利用Redis构造分布式全局唯一ID,正好整理一下所学内容。

问题分析:
在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识。数据日渐增长,对数据分库分表后需要有一个唯一ID来标识一条数据或消息,数据库的自增ID显然不能满足需求;特别一点的如订单、骑手、优惠券也都需要有唯一ID做标识。此时一个能够生成全局唯一ID的系统是非常必要的。概括下来,那业务系统对ID号的要求有哪些呢?
- 全局唯一性: 生成的ID必须在整个系统范围内绝对唯一,不允许出现任何重复。
- 写入性能优化(趋势递增): 为了在如MySQL InnoDB(使用B-tree索引)等数据库中-tree索引)等数据库中实现高效的写入性能,ID应具备整体趋势递增的特性(新ID通常比旧ID大),避免插入时索引结构的频繁分裂调整。
- 严格顺序性(单调递增): 在需要严格时间或逻辑顺序的场景(如事务版本号、增量消息、排序等),ID必须具备单调递增的特性,确保新生成的ID一定大于之前生成的所有ID。
- 信息安全(非连续/无规律): 为了防止恶意用户通过连续ID推测业务量、爬取数据或获取敏感信息(如订单量),ID应设计成非连续、无明显规律、不可预测的形式。
上述123对应三类不同的场景,3和4需求还是互斥的,无法使用同一个方案满足。
方案一:UUID生成
UUID(Universally Unique Identifier)的标准型式包含32个16进制数字,以连字号分为五段,形式为8-4-4-4-12的36个字符,示例:550e8400-e29b-41d4-a716-446655440000
优点:
- 性能非常高:本地生成,没有网络消耗。
缺点:
-
不易于存储:UUID太长,16字节128位,通常以36长度的字符串表示,很多场景不适用。
-
信息不安全:基于MAC地址生成UUID的算法可能会造成MAC地址泄露
-
ID作为主键时在特定的环境会存在一些问题,比如做DB主键的场景下,UUID就非常不适用(Mysql中的主键id要求尽量要短)
方案二:利用Redis构造全局唯一ID

由图可看得,我们设计的ID一共分为三部分:
1.符号位:永远为0,标识我们的ID是一个整数。
2.时间戳:从自定义时间开始,按秒计算。那么32位我们大约可以使用60多年。
3.序列号:同一时间内下单进行自增。在时间戳相等的形况下的区分不同的订单。
java
public long nextId(String keyPrefix) {
//1.生成时间戳
LocalDateTime now = LocalDateTime.now();
long nowhSecond = now.toEpochSecond(ZoneOffset.UTC);
long timestamp = nowhSecond - BEGIN_TIMESTAMP;
//2.生成序列号
//1.获取日期,精确到天
String date = now.format(DateTimeFormatter.ofPattern("yyyy:MM:dd"));
Long count = stringRedisTemplate.opsForValue().increment("icr:" + keyPrefix + ":" + date);
return (timestamp << COUNT_BITS) | count;
}最后的return为了提高效率,使用了位运算。
优点:
高位为时间,低位为序列,保证整体在递增
以服务的形式生成id,减小对数据库的压力
缺点:
如果机器的时间回拨,可能会导致id出现重复
解决方案:
通过Redis保存最后一次生成ID的逻辑时间戳 (而非依赖物理时间),确保逻辑时间只增不减。即使物理时间回拨,逻辑时间仍延续上次的值,从而保证ID的唯一性和有序性。
1. 优化ID结构(必选)
为解决分布式环境下的唯一性(不同机器可能生成相同时间戳+序列号),需在ID中增加机器ID (或数据中心ID)。推荐结构(64位Long类型,兼容Java的long):
java
符号位(1位) + 时间戳(41位) + 机器ID(10位) + 序列号(12位)- 符号位:固定为0(保证ID为正数);
- 时间戳:相对于某个epoch(如2020-01-01)的毫秒数,可使用约69年;
- 机器ID:每个实例唯一(通过配置文件/环境变量/ZooKeeper获取);
- 序列号:每毫秒内的自增值(0-4095,支持每秒409.6万次ID生成)。
2. 关键组件:Redis存储逻辑时间
用Redis的String类型存储两个关键值:
last_timestamp:最后一次生成ID的逻辑时间戳(毫秒);sequence:当前毫秒内的序列号(0-4095)。
通过Lua脚本保证这两个值的原子更新(避免并发 race condition)。
3. 具体实现步骤(Java+Redis)
(1)Lua脚本:原子生成逻辑时间戳和序列号:
Lua脚本是Redis原子操作的核心,用于处理时间回拨、序列号溢出等场景。
(2)Java客户端实现
通过Redisson或Jedis调用Lua脚本,处理返回结果,构造最终ID。
- 逻辑时间戳 :Redis中保存的
last_timestamp是逻辑时间,仅增不减。即使物理时间回拨,逻辑时间仍延续上次的值,保证ID的有序性。 - 时间回拨处理 :
- 回拨未超过阈值(如1秒):使用逻辑时间继续生成ID,序列号递增。若序列号溢出,则递增逻辑时间(如
last_timestamp+1),重置序列号。 - 回拨超过阈值:拒绝生成ID,抛出异常(需报警通知管理员处理,如系统时间被恶意修改)。
- 回拨未超过阈值(如1秒):使用逻辑时间继续生成ID,序列号递增。若序列号溢出,则递增逻辑时间(如
由于该项方案技术实现较为复杂,我这里没有实现
方案三:Leaf-segment方案
批量获取ID进行处理 。在上文我们简单的对数据库进行优化的时候,优化问题基本都来源于高并发下数据库高频的读写操作。而LEAF数据库方案也是针对这个方面进行优化的。
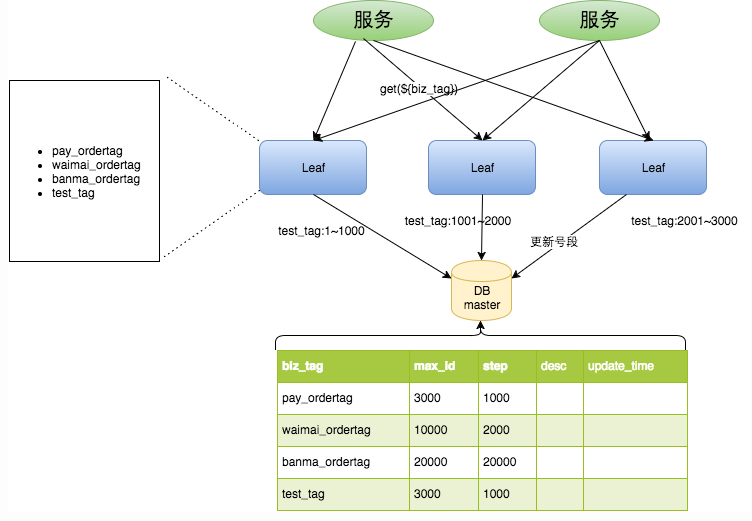
我们可以把图中的leaf简单的理解为是一个生成全局唯一ID的服务。那么整个LEAF数据库的思想就是:leaf服务提前就拿好一批号端,例如从0-1000。那么我在生成唯一ID的时候,压力就从数据库转到了Leaf这个服务里面。
优点:
将生成id的功能作为服务,方便后续扩展和维护
容灾性强,即使数据库挂掉,服务中因为保存了一部分号段,短时间内仍可进行服务
满足递增要求
缺点:
在号段用完后,突然出现大量请求,服务器压力增大
解决方案:双buffer优化
Leaf------美团点评分布式ID生成系统 - 美团技术团队
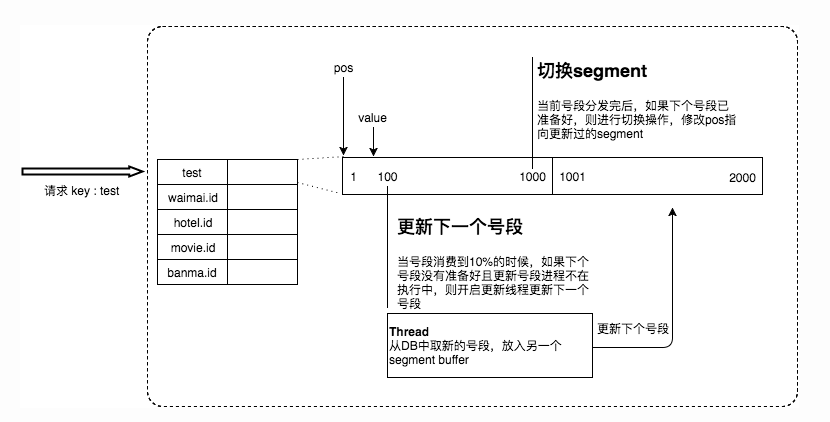
我们并不会等到号段全部用完之后再去请求新的号段。美团给出的技术方案是当号段消费到某个点时就异步的把下一个号段加载到内存中。而不需要等到号段用尽的时候才去更新号段。
一开始先用A号段,等 A号段消耗10%的时候,就向数据库请求新号段。之后当前号段消耗完之后就可以进行快速的切换。如此循环往复。
总结:
三个方案各有千秋,大家可以根据结合自身项目的情况选择合适的方案为项目赋能