KAN论文地址:https://arxiv.org/abs/2404.19756

一、KAN 的原理:像 "定制化导线" 拼出复杂功能
可以把 KAN(Kolmogorov-Arnold Networks)理解成一套 "灵活的信号传输系统",核心思路来自一个数学定理 ------Kolmogorov-Arnold 表示定理,即KART(Kolmogorov--Arnold Representation Theorem),这个定理的通俗意思是:"再复杂的多变量函数(比如用多个因素预测结果的情况),都能拆成一个个单变量函数的组合"。
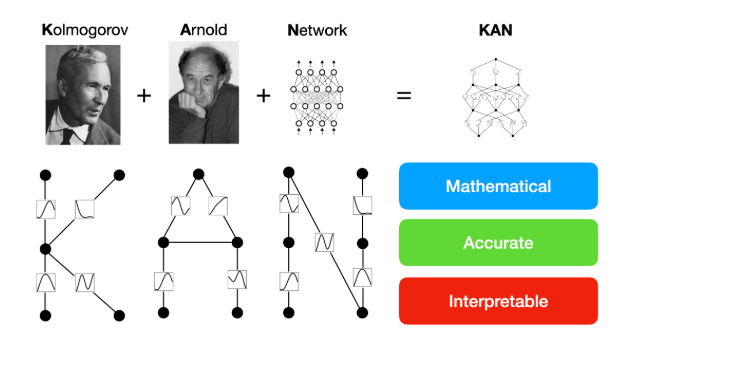
具体到 KAN 的结构,我们可以想象它有几层 "节点",节点之间用 "导线" 连接:
- 这些 "导线" 不是普通的电线(像 MLP 里固定的权重),而是能自己学习 "传输规则" 的定制化导线------ 每根导线里都装了一个 "可学习的激活函数"(通常用 "B 样条函数",可以理解成能灵活弯曲的曲线)。
- 节点的作用很简单,只负责 "汇总信号":比如某个节点会收集所有连到它的 "导线" 传来的信号,直接加起来传给下一层,自己不做任何复杂处理。
举个例子:如果用 KAN 处理 "根据 EEG 信号预测看到的图像"(对应论文里的任务),EEG 的每个通道信号是 "输入节点",最终的图像特征是 "输出节点"。连接它们的 "导线" 会自己学习:"通道 1 的信号该怎么变换,才能和通道 3 的信号配合,最终对应到'苹果'的图像特征"------ 每根导线的变换规则(激活函数)都是独立学习的,能精准适配数据里的复杂关联。
二、KAN 与 MLP 的关系:替代者,而非完全不同的 "新物种"
MLP(多层感知器)是我们熟悉的 "基础款神经网络",KAN 是为了解决 MLP 的缺点而生的 "升级替代方案",两者的核心区别和联系可以用 "工厂生产" 来类比:
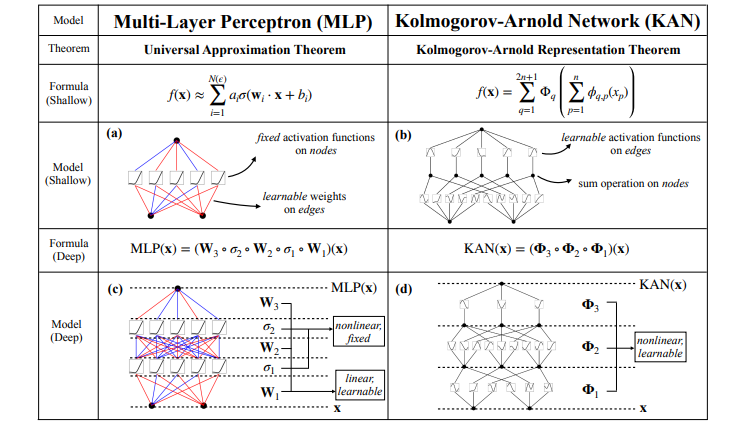 Figure 0.1:MLPs VS KAN(ref.KAN: Kolmogorov-Arnold Networks)
Figure 0.1:MLPs VS KAN(ref.KAN: Kolmogorov-Arnold Networks)
1. 核心区别:"固定工序" vs "定制工序"
-
MLP 像 "标准化工厂":它的每一层都有固定流程 ------ 先把输入信号用 "固定权重" 做线性组合(比如 "信号 1×0.3 + 信号 2×0.5"),再用一个固定的激活函数(比如 ReLU,像个 "开关",只保留正数信号)处理。不管数据是什么规律,这个 "线性组合 + 固定激活" 的工序是不变的,只能通过调整 "权重" 来适配数据。缺点很明显:如果数据里有复杂的非线性关系,MLP 需要堆很多层、很多节点才能勉强拟合,不仅参数多、训练慢,还像个 "黑箱"------ 不知道哪个权重起了关键作用。
-
KAN 像 "定制化工厂":它把 MLP 里 "固定的权重 + 固定的激活" 拆成了 "每根导线的定制激活函数"------ 不再用统一的 "线性组合 + ReLU",而是让每根连接节点的 "导线" 自己学习适合的变换规则。比如处理 EEG 信号时,对 "枕叶通道"(负责视觉信息的脑区)的导线,会学到和 "额叶通道" 完全不同的变换规则,更精准地捕捉数据规律。优点是:用更少的参数就能达到甚至超过 MLP 的效果(比如论文里提到,2 层宽 10 的 KAN,比 4 层宽 100 的 MLP 精准 100 倍),而且 "导线" 的激活函数能可视化 ------ 你能看到哪根导线对结果影响最大,解释性更强。
2. 共同点:都是 "全连接结构",目标一致
两者都是 "全连接" 的 ------ 前一层的每个节点都会连接到后一层的每个节点,没有像 CNN 那样的 "局部连接";而且核心目标相同:都是通过多层变换,把输入数据映射到想要的输出(比如 数据→分类结果)。
简单说:KAN 不是推翻了 MLP 的结构,而是把 MLP 里 "僵硬的工序" 改成了 "灵活的定制工序",既保留了 MLP 处理复杂数据的能力,又解决了它 "参数多、解释性差" 的缺点。
总的来说,KAN 是 MLP 的 "升级版替代方案":MLP 用 "固定激活函数 + 可调整权重" 处理数据,像标准化生产;KAN 用 "可学习的激活函数(装在导线上)+ 简单节点汇总",像定制化生产,能更高效、更精准地拟合复杂数据,还能让人看懂它的 "决策过程"。
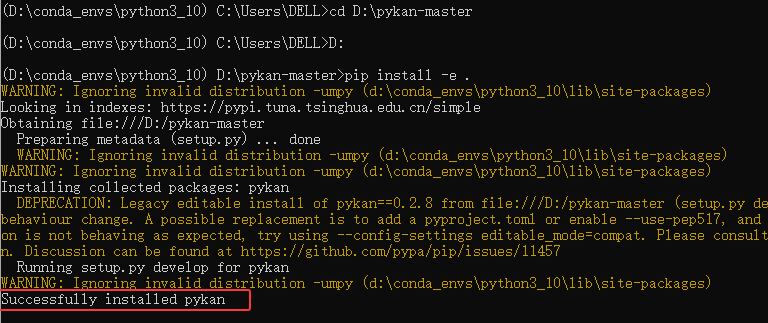
三、安装KAN
优先方案:无需安装 git,直接下载 pykan 源码手动安装。
1. 下载 pykan 源码压缩包
- 打开 GitHub 仓库链接:https://github.com/KindXiaoming/pykan
- 点击页面右上角的 Code 按钮,选择 Download ZIP ,将源码压缩包保存到本地(如
D:\pykan-master.zip)。
2. 解压并本地安装
-
右键解压
pykan-master.zip,得到文件夹pykan-master(确保路径无中文,如D:\pykan-master); -
打开 Anaconda Prompt,激活你的 conda 环境(
conda activate环境名称); -
切换到解压后的
pykan-master文件夹路径:cd D:\pykan-main -
执行本地安装命令:
pip install -e .
安装成功后,会提示 "Successfully installed pykan"。