博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
- 技术栈:Python语言、Django框架(后端)、Vue框架(前端)、MySQL数据库、Scrapy爬虫、Echarts可视化、懂车帝网数据源、HTML
- 研究背景:当前懂车帝网作为主流汽车信息平台,聚集海量车型数据(参数、销量、评价、降价信息),但用户面临三大痛点------信息分散(车型参数、销量走势、用户差评需跨页面查找)、筛选低效(传统关键词搜索难精准匹配"品牌+价格+车型"组合需求)、数据缺乏直观分析(如销量对比、降价趋势无可视化呈现);同时人工采集懂车帝数据耗时久,难以满足实时分析需求,亟需"爬虫采集-多维度分析-可视化展示-精准筛选"的一体化系统解决。
- 研究意义:技术层面,通过Scrapy实现懂车帝数据自动化采集,Django+Vue构建前后端分离架构,Echarts实现数据可视化,构建"采集-存储-分析-展示"完整技术闭环;用户层面,为购车者提供高效筛选、直观数据分析,为管理员提供数据管控工具;行业层面,推动汽车信息服务从"信息罗列"转向"数据驱动决策",提升用户选车效率与平台运营精细化程度,具备实际应用价值。
2、项目界面
-
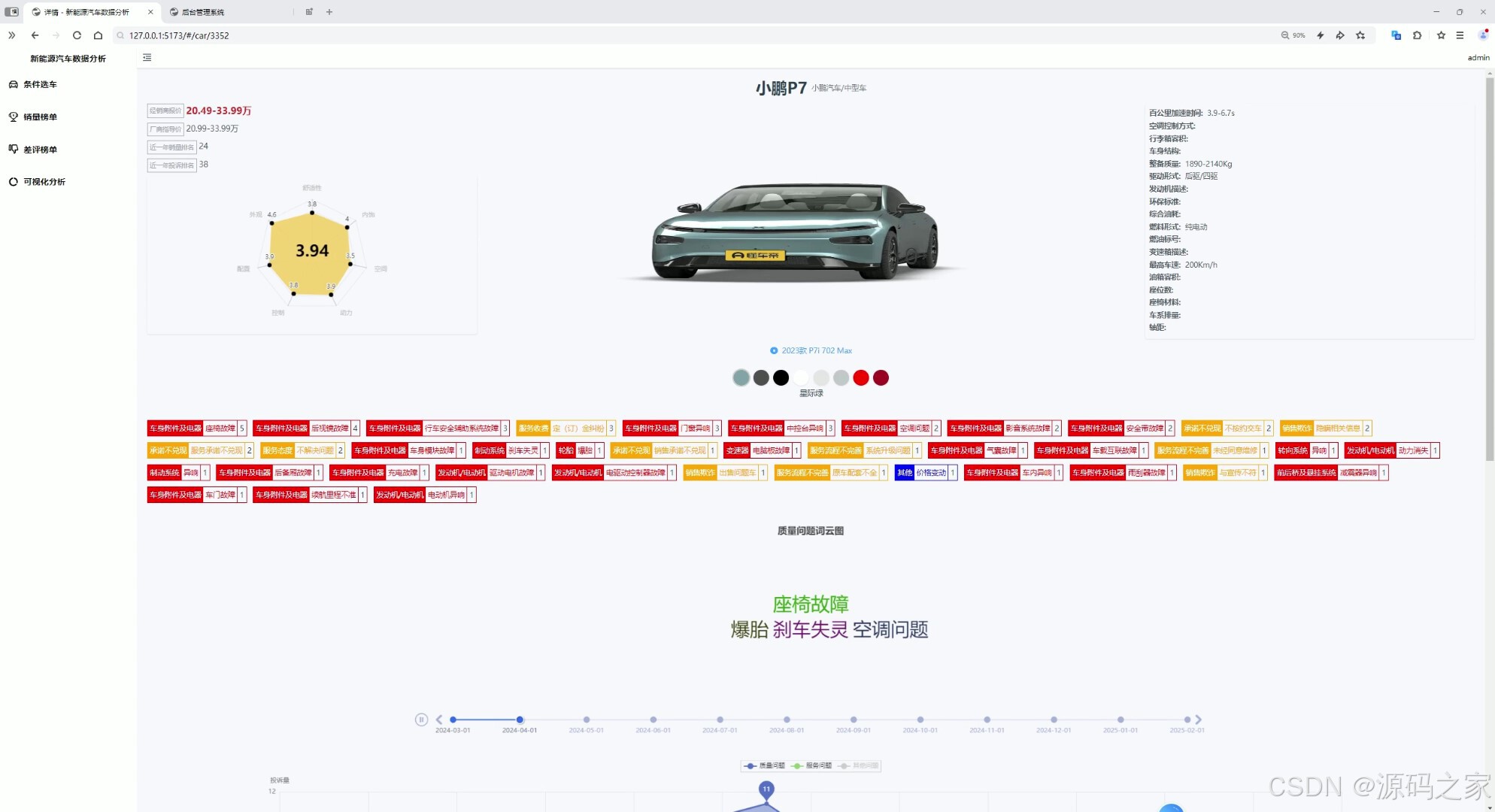
汽车详情信息页面
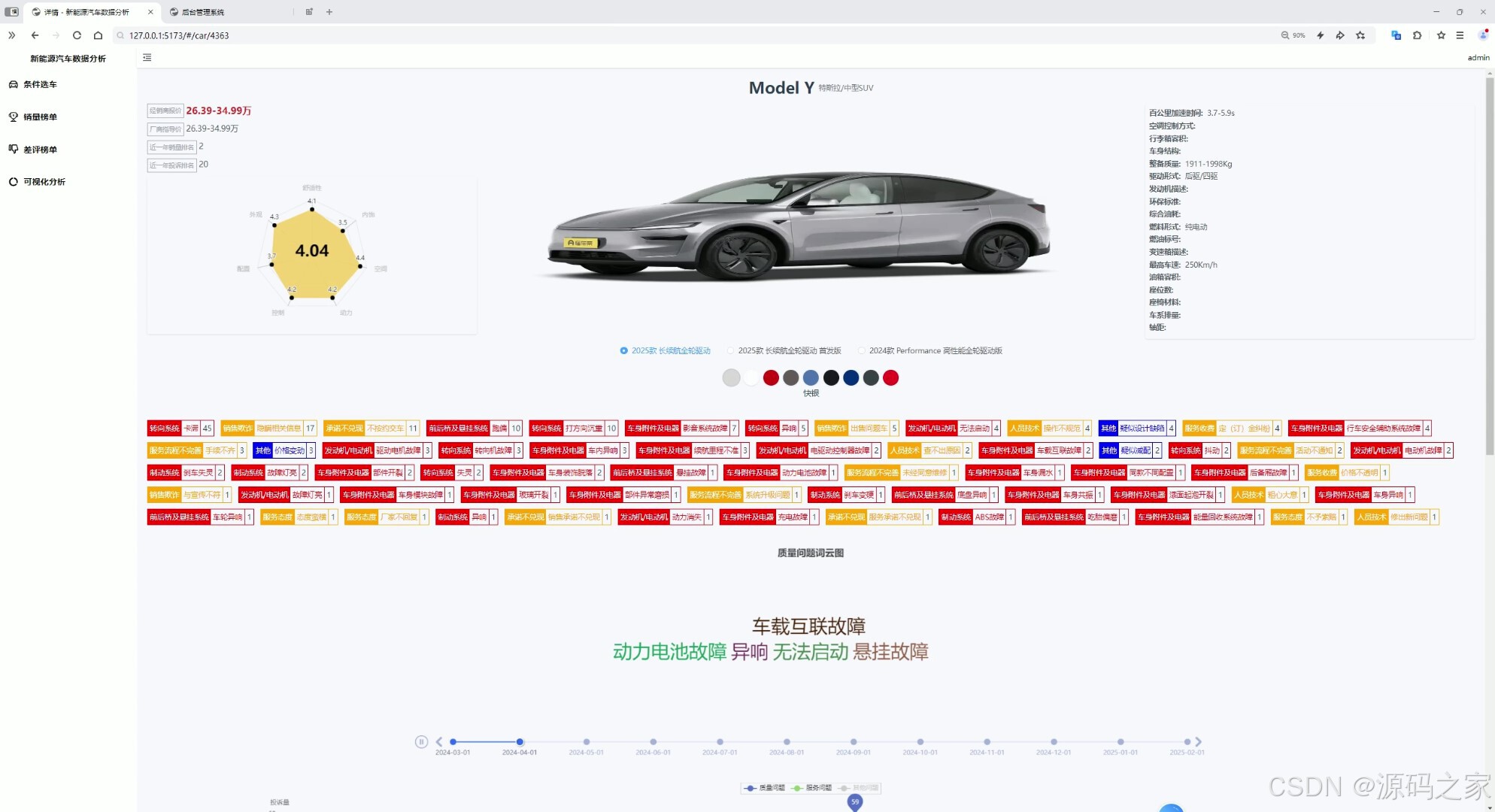
-
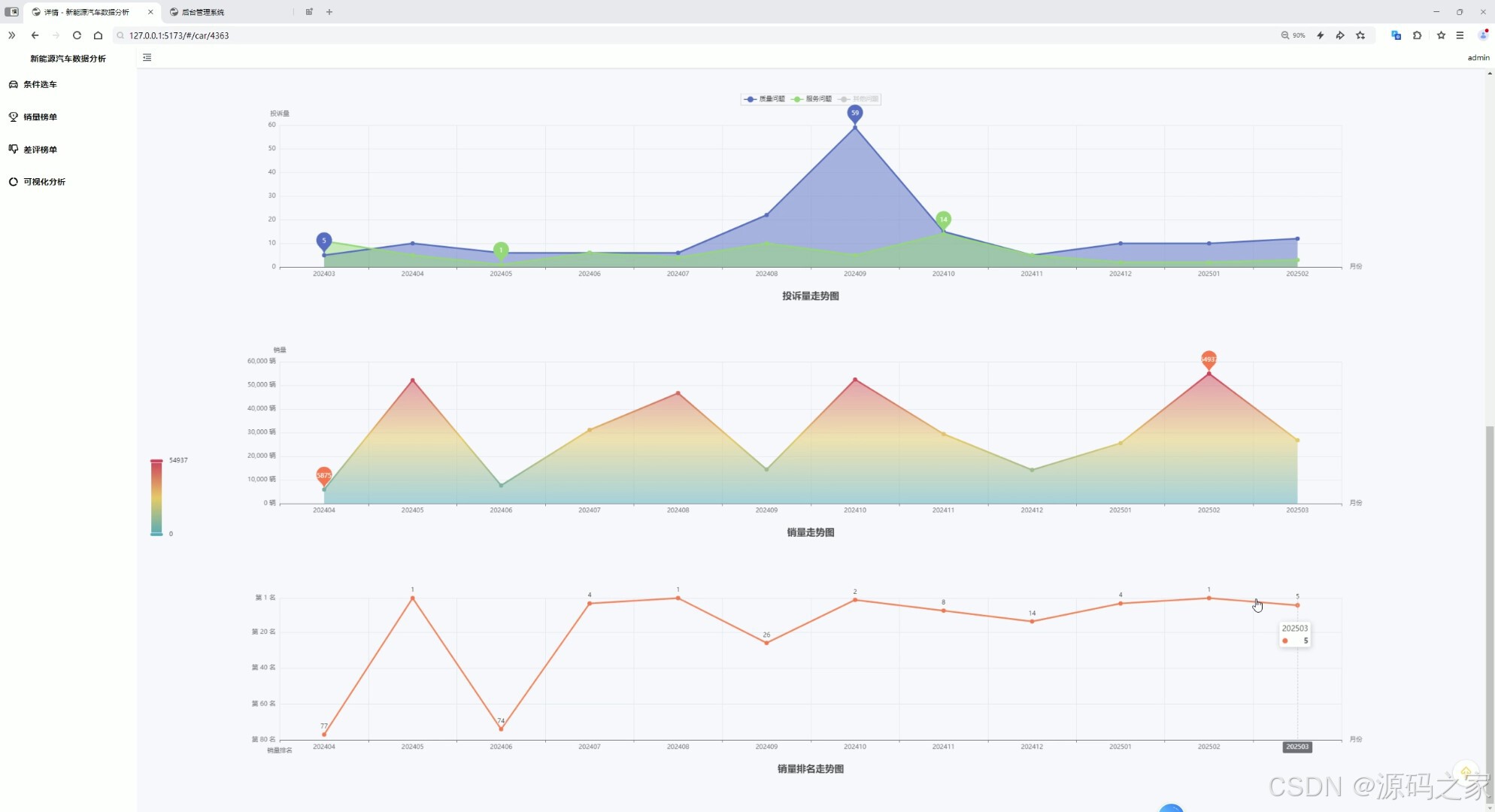
汽车数据分析---销量走势、销量排名曲线、投诉走势等等
-
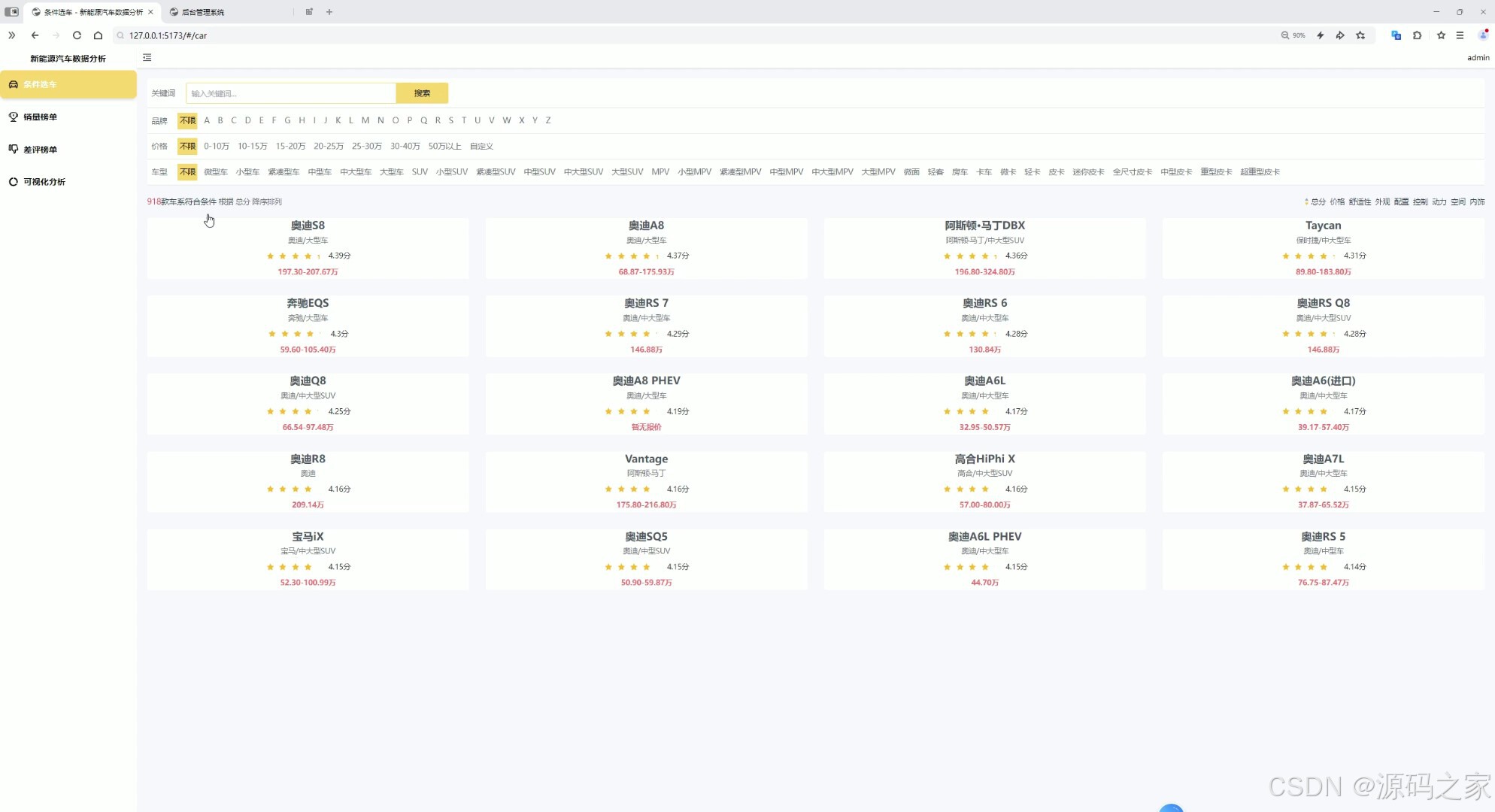
首页----按条件选车
-
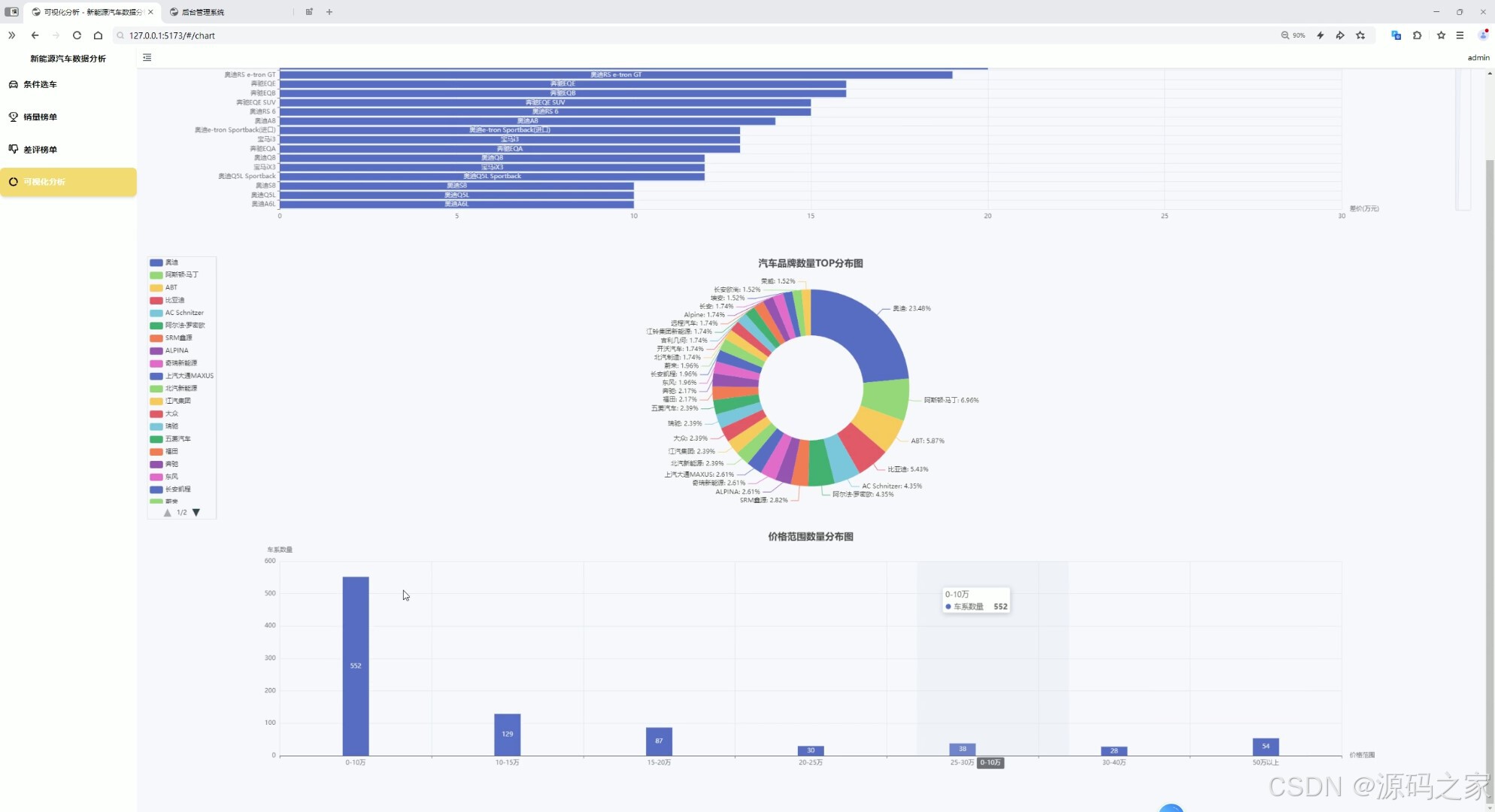
数据可视化分析----降价排行榜、汽车品牌分布、价格分布分析
-
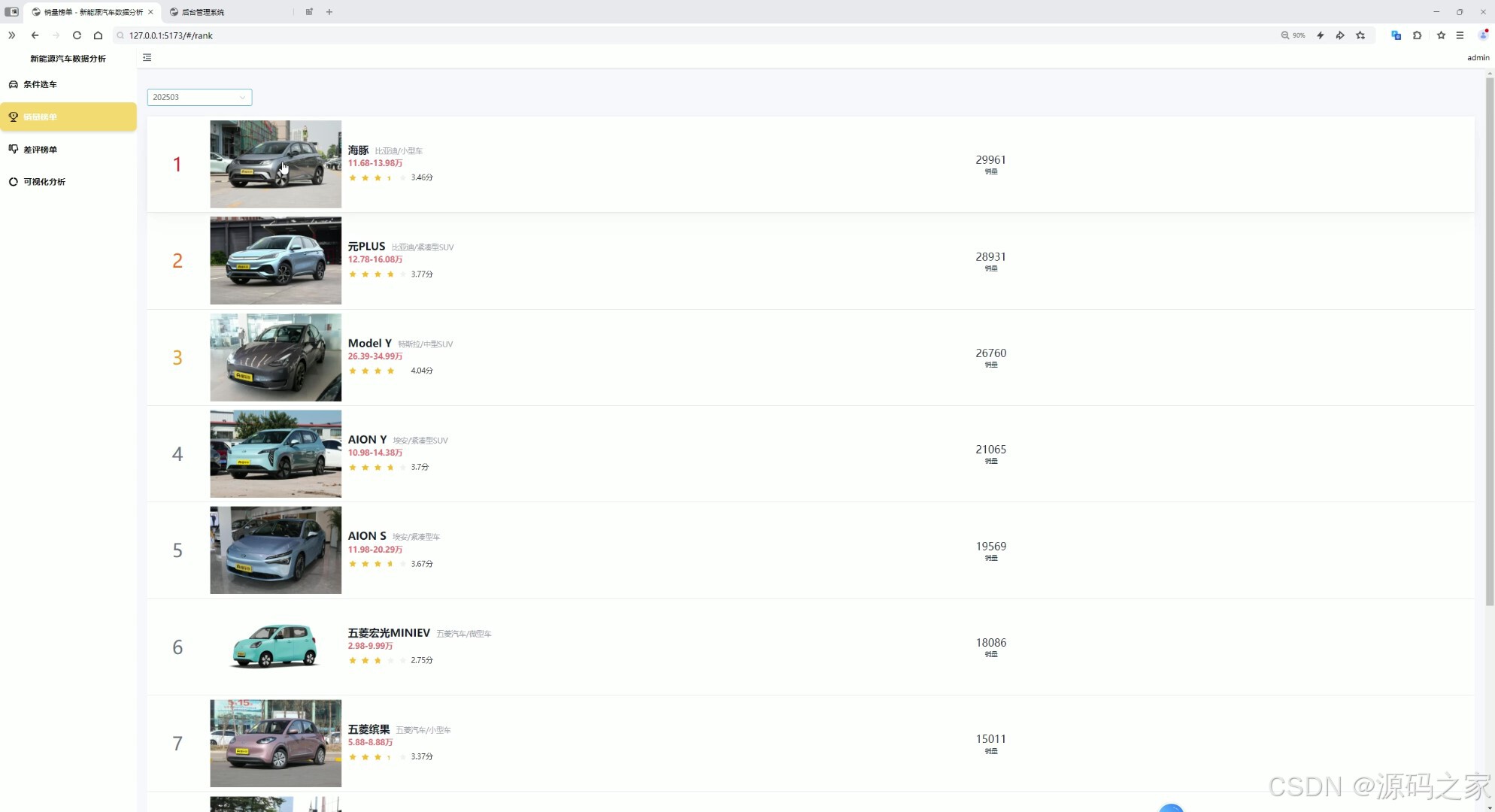
销量榜单分析
-
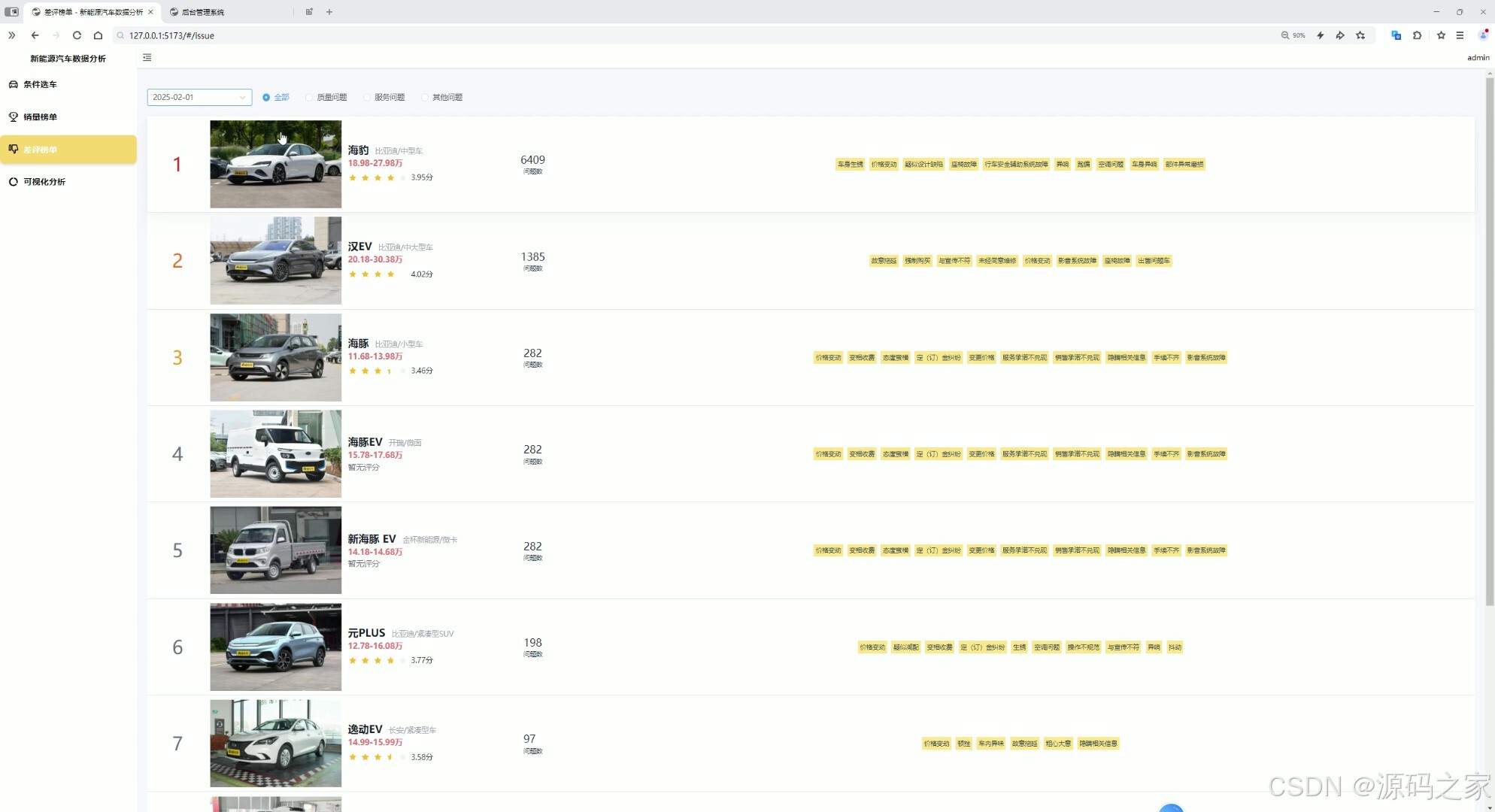
差评榜单---质量、服务、其他
-
汽车详情页面
-
注册登录
-
后台数据管理
3、项目说明
本项目是基于Python开发的懂车帝网汽车数据智能分析系统,采用Django+Vue前后端分离架构,整合Scrapy爬虫、MySQL数据库与Echarts可视化,核心实现"懂车帝数据采集-多维度筛选-可视化分析-后台管理"的完整流程,旨在解决汽车信息筛选难、数据洞察浅、采集效率低的问题。
(1)系统架构与技术逻辑
- 架构设计 :
- 后端(Django):负责业务逻辑核心------调度Scrapy爬虫采集数据、处理MySQL数据库CRUD操作、开发API接口(供前端调用数据)、实现用户认证与权限控制;
- 前端(Vue):负责用户交互与界面展示------构建响应式页面(如首页选车、详情页)、嵌入Echarts组件实现可视化、通过AJAX调用后端API同步数据,确保界面流畅性;
- 数据层:Scrapy爬虫定向采集懂车帝网数据,经清洗后存入MySQL,为后端接口与前端可视化提供高质量数据源;
- 核心流程:Scrapy爬取懂车帝数据(车型、销量、评价、降价)→ 数据清洗存MySQL → Django开发接口 → Vue前端调用接口加载数据 → Echarts生成可视化图表 → 用户操作(选车、看分析)/管理员后台管理。
(2)核心功能模块详解
① 数据采集模块(Scrapy爬虫核心)
- 功能:自动化采集懂车帝网关键数据,解决"人工采集耗时"问题;
- 技术实现 :
- 定向爬取:Scrapy爬虫模拟浏览器请求,分析懂车帝网页HTML结构,编写Item Pipeline提取目标数据,涵盖:
- 车型基础信息(品牌、型号、官方指导价、配置参数);
- 市场动态数据(销量走势、月度降价金额、降价排行榜);
- 用户评价数据(好评/差评内容、投诉类型(质量/服务)、评分);
- 数据预处理:爬虫内置清洗逻辑,过滤重复数据(如同一车型不同页面的重复参数)、补全缺失值(如无降价信息标注"暂无降价")、统一数据格式(如销量按"辆/月"规整);
- 采集控制:支持两种模式------后端手动触发(管理员在"后台管理"界面启动爬虫)、定时自动采集(通过Django定时任务,如每周一更新上周销量数据)。
- 定向爬取:Scrapy爬虫模拟浏览器请求,分析懂车帝网页HTML结构,编写Item Pipeline提取目标数据,涵盖:
② 前端交互模块(用户核心操作)
(1)首页------按条件选车
- 功能:支持多维度组合筛选,快速定位目标车型,解决"海量车型找不准"问题;
- 筛选维度:品牌(如"丰田""比亚迪")、价格区间(如"10-15万""20-30万")、车型(如"轿车""SUV""新能源")、核心配置(如"全景天窗""自动驾驶辅助");
- 技术实现:Vue前端通过表单组件接收用户筛选条件,AJAX提交至后端API,后端查询MySQL匹配数据后返回结果,前端实时渲染车型列表,支持点击列表进入"汽车详情页面"。
(2)汽车详情页面(2个界面,功能互补)
- 功能:展示单车型完整信息,满足用户"深度了解车型"需求;
- 展示内容 :
- 基础信息:车型参数(轴距、动力类型)、官方图片、经销商报价;
- 用户评价:差评榜单(质量/服务类差评摘要)、投诉趋势(近3个月投诉量变化);
- 市场数据:该车型近6个月销量走势、同级别车型销量对比;
- 技术实现:Vue前端通过URL参数(如车型ID)调用后端详情API,后端从MySQL关联查询该车型的所有数据,返回后前端分模块渲染(参数区、评价区、销量区),确保信息结构化呈现。
③ 数据可视化分析模块(Echarts核心应用)
通过Echarts将MySQL数据转化为直观图表,覆盖"销量、降价、评价、品牌"四大分析维度:
- 汽车数据分析界面 :
- 图表类型:折线图(销量走势、投诉走势)、柱状图(同品牌不同车型销量排名);
- 价值:帮助用户直观判断车型市场热度(如"某车型近3个月销量持续增长")、质量风险(如"某车型投诉量环比上升50%");
- 数据可视化分析界面 :
- 图表类型:排行榜(降价金额TOP10柱状图)、饼图(汽车品牌市场占比)、直方图(价格区间车型数量分布);
- 价值:用户快速把握市场趋势(如"10-15万区间车型最多,占比35%")、找到高性价比车型(如"某车型降价2.5万,位列降价榜第一");
- 销量榜单分析界面 :
- 图表类型:多系列柱状图(不同品牌月度销量对比)、排行榜(年度销量TOP20车型);
- 价值:为购车者提供"热门车型参考",为行业研究者提供市场份额数据;
- 差评榜单界面 :
- 图表类型:饼图(差评类型占比:质量60%、服务30%、其他10%)、条形图(各品牌差评数量排名);
- 价值:帮助用户规避"高差评风险车型",为车企提供改进方向。
④ 后台管理与注册登录模块(系统运维)
- 注册登录 :
- 功能:用户通过账号密码完成认证,区分"普通用户"与"管理员"角色;
- 技术实现:Django内置用户认证系统,密码加密存储,登录后生成Token,前端携带Token调用对应权限的API(如普通用户无法调用后台管理接口);
- 后台管理(管理员专属) :
- 功能:保障系统数据可控与稳定运行,包括:
- 数据管理:增删改查MySQL中的车型数据、评价数据,支持批量导入/导出(如Excel格式);
- 爬虫管理:查看爬虫运行日志(采集成功条数、失败原因)、手动启动/停止爬虫任务;
- 用户管理:维护用户账号(启用/禁用)、分配角色权限(如升级普通用户为管理员);
- 技术实现:Django Admin框架快速搭建后台界面,结合自定义View扩展功能(如爬虫任务调度按钮)。
- 功能:保障系统数据可控与稳定运行,包括:
(3)系统优势与应用场景
- 核心优势 :
- 前后端分离:Vue前端响应速度快,Django后端扩展性强,便于后期功能迭代(如新增"新能源车型专题分析");
- 数据实时性:Scrapy定时采集+MySQL实时存储,确保销量、降价等动态数据最新;
- 可视化直观:Echarts支持图表交互(如缩放、hover看详情),降低非技术用户的理解门槛;
- 应用场景 :
- 普通用户:通过"按条件选车"快速找车型,通过"可视化分析"判断性价比与风险;
- 汽车经销商:参考"销量榜单""降价趋势"调整库存与促销策略;
- 管理员:通过后台管控数据质量,确保系统稳定运行。
4、核心代码
python
from django.shortcuts import render
from datetime import datetime, timedelta
from .models import *
from django.http.response import JsonResponse
from itertools import groupby
from .models import *
import json
from django.http.response import HttpResponse
from django.shortcuts import render
from django.http import JsonResponse
from pyecharts import options as opts
from pyecharts.charts import Map, Grid, Bar, Line, Pie, WordCloud, Radar, Timeline
from pyecharts.faker import Faker
from pyecharts.commons.utils import JsCode
from pyecharts.options.charts_options import MapItem
from datetime import datetime, time
from django.core.paginator import Paginator
from django.db.models import Q, F
from pyecharts.globals import SymbolType
from django.db.models import Sum, Count, Max, Min, Avg
from collections import Counter
from requests_html import requests
from itertools import chain
from functools import lru_cache
def to_dict(l, exclude=tuple(), single=False):
# 将数据库模型 变为 字典数据 的工具类函数
def transform(v):
if isinstance(v, datetime):
return v.strftime("%Y-%m-%d %H:%M:%S")
return v
def _todict(obj):
j = {
k: transform(v)
for k, v in obj.__dict__.items()
if not k.startswith("_") and k not in exclude
}
return j
if single:
return _todict(l)
return [_todict(i) for i in l]
def car_rank(request):
body = request.json
id = body.get("id")
return _car_rank(id)
@lru_cache()
def _car_rank(id):
# 获取当前日期及1年前的日期
today = datetime.now().date()
one_year_ago = today - timedelta(days=365)
# 设置查询条件
q = Q(month__gte=one_year_ago.strftime("%Y%m"), month__lte=today.strftime("%Y%m"))
result = (
CarSale.objects.filter(q)
.values("series_id", "series_name")
.annotate(total_sales=Sum("rank_value"))
.filter(total_sales__gt=0)
.order_by("-total_sales")
)
sales_rank = next(
(
i
for i, e in enumerate(
result,
start=1,
)
if e["series_id"] == int(id)
),
-1,
)
# ---------
# 获取当前日期及1年前的日期
q = Q(
stime__gte=one_year_ago.strftime("%Y-%m-%d"),
stime__lte=today.strftime("%Y-%m-%d"),
)
result = (
CarIssue.objects.filter(q)
.values("series_id", "series_name")
.annotate(total_issues=Sum("count"))
.filter(total_issues__gt=0)
.order_by("-total_issues")
)
issue_rank = next(
(
i
for i, e in enumerate(
result,
start=1,
)
if e["series_id"] == int(id)
),
-1,
)
return JsonResponse(dict(sales_rank=sales_rank, issue_rank=issue_rank))
def car_sales_rank(request):
# 获取请求体中的数据
body = request.json
# 获取请求体中的月份
month = body.get("month")
# 定义查询条件
q = Q()
# 根据月份设置查询条件
if month == "1y":
# 获取当前日期及1年前的日期
today = datetime.now().date()
one_year_ago = today - timedelta(days=365)
# 设置查询条件
q &= Q(
month__gte=one_year_ago.strftime("%Y%m"), month__lte=today.strftime("%Y%m")
)
elif month == "6m":
# 近半年,即6个月
today = datetime.now().date()
half_year_ago = today - timedelta(days=365 // 2)
# 设置查询条件
q &= Q(
month__gte=half_year_ago.strftime("%Y%m"), month__lte=today.strftime("%Y%m")
)
else:
q &= Q(month=month)
# 统计各个车系一年内的总销量,并按照销量进行排序和排名
result = (
CarSale.objects.filter(q)
.values("series_id", "series_name")
.annotate(total_sales=Sum("rank_value"))
.order_by("-total_sales")
)
# 对结果进行排名
result_list = list(result)
for i, item in enumerate(result_list):
item["sales_rank"] = i + 1
# 分页处理数据
pagesize = body.get("pagesize", 20)
page_num = body.get("page", 1)
paginator = Paginator(result_list, pagesize) # 创建Paginator对象
page = paginator.get_page(page_num) # 获取指定页码的数据
result = list(page.object_list)
# 获取每个车系的详细信息,并将其添加到结果中
for i in result:
car_series = to_dict([CarSeries.objects.get(series_id=i["series_id"])])[0]
i.update(**car_series)
# 返回分页后的结果
return JsonResponse({"total": paginator.count, "records": result})
def car_issue_rank(request):
body = request.json
stime = body.get("stime")
type = body.get("type")
q = Q()
if stime == "1y":
# 获取当前日期及1年前的日期
today = datetime.now().date()
one_year_ago = today - timedelta(days=365)
q &= Q(
stime__gte=one_year_ago.strftime("%Y-%m-%d"),
stime__lte=today.strftime("%Y-%m-%d"),
)
elif stime == "6m":
# 近半年,即6个月
today = datetime.now().date()
half_year_ago = today - timedelta(days=365 // 2)
q &= Q(
stime__gte=half_year_ago.strftime("%Y-%m-%d"),
stime__lte=today.strftime("%Y-%m-%d"),
)
else:
q &= Q(stime=stime)
if type:
q &= Q(type=type)
# 统计各个车系一年内的总问题数,并按照问题数进行排序和排名
result = (
CarIssue.objects.filter(q)
.values("series_id", "series_name")
.annotate(total_issues=Sum("count"))
.order_by("-total_issues")
)
# 对结果进行排名
result_list = list(result)
for i, item in enumerate(result_list):
item["issues_rank"] = i + 1
# 分页处理数据
pagesize = body.get("pagesize", 20)
page_num = body.get("page", 1)
paginator = Paginator(result_list, pagesize) # 创建Paginator对象
page = paginator.get_page(page_num) # 获取指定页码的数据
result = list(page.object_list)
for i in result:
car_series = to_dict([CarSeries.objects.get(series_id=i["series_id"])])[0]
counter = Counter()
for x in CarIssue.objects.filter(q, series_id=i["series_id"]).values_list(
"dxwt", flat=True
):
counter.update(dict([(j["ctiTitle"], j["count"]) for j in x]))
i["issues"] = counter.most_common(10)
i.update(**car_series)
return JsonResponse({"total": paginator.count, "records": result})
def get_detail(request):
body = request.json
id = body.get("id")
o = CarSeries.objects.get(pk=id)
o = to_dict(o, single=True)
o["brand"] = to_dict(Brand.objects.get(brand_id=o["brand_id"]), single=True)
return JsonResponse(o)
def car_360_color_pic(request):
body = request.json
id = body.get("id")
try:
color_pic_list = requests.get(
f"https://www.dongchedi.com/motor/pc/car/series/car_360_color_pic?aid=1839&app_name=auto_web_pc&series_id={id}"
).json()["data"]["color_pic_list"]
except:
color_pic_list = []
return JsonResponse(color_pic_list, safe=False)🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看 👇🏻获取联系方式👇🏻