博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
- 技术栈:Python语言、Flask框架、Echarts可视化、Prophet时间序列预测算法、逻辑回归算法、requests爬虫、汽车之家二手车数据源(核心应用:二手车数据采集、口碑分析、销量预测、个性化推荐)
- 研究背景:当前汽车之家二手车平台数据海量,但存在三大核心痛点------数据分散在车型、口碑、销量等板块,人工整合分析效率低;传统口碑分析仅靠主观判断,无法量化"评分与售价""评价人数与车型热度"的关联;销量预测依赖经验,缺乏科学的时间序列模型支撑;同时个性化推荐缺失,用户需在海量车源中手动筛选,时间成本高,亟需"采集-分析-预测-推荐"一体化系统解决。
- 研究意义:技术层面,通过requests爬虫实现数据自动化采集,逻辑回归算法量化口碑与价格关联,Prophet算法提升销量预测精度,Echarts可视化降低数据理解门槛,Flask搭建稳定Web架构;用户层面,为买家提供精准推荐、为卖家提供销量预判、为管理员提供数据管控工具;行业层面,推动二手车市场从"经验驱动"转向"数据驱动",提升交易透明度与运营效率,具备实际应用价值。
2、项目界面
-
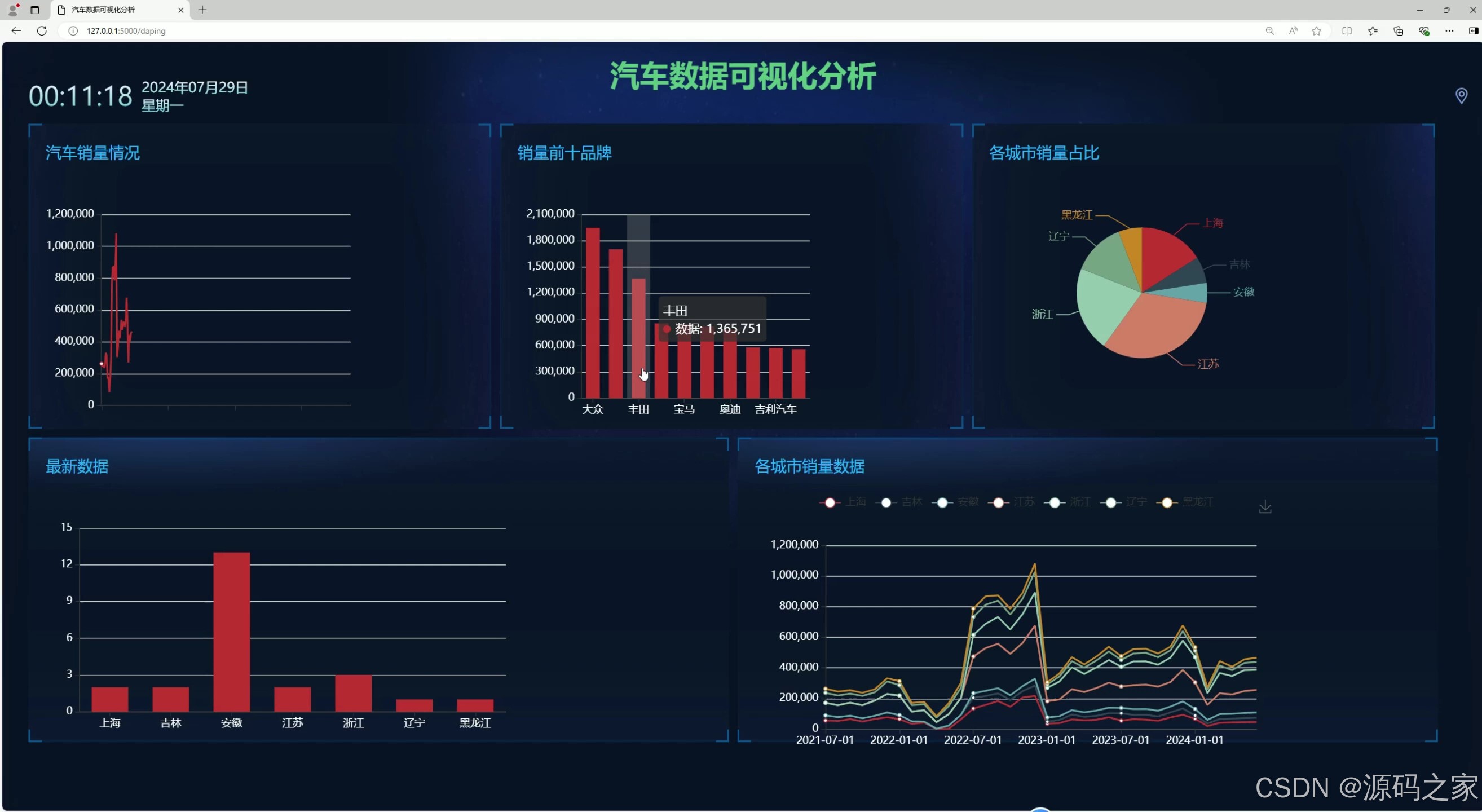
数据可视化分析大屏
-
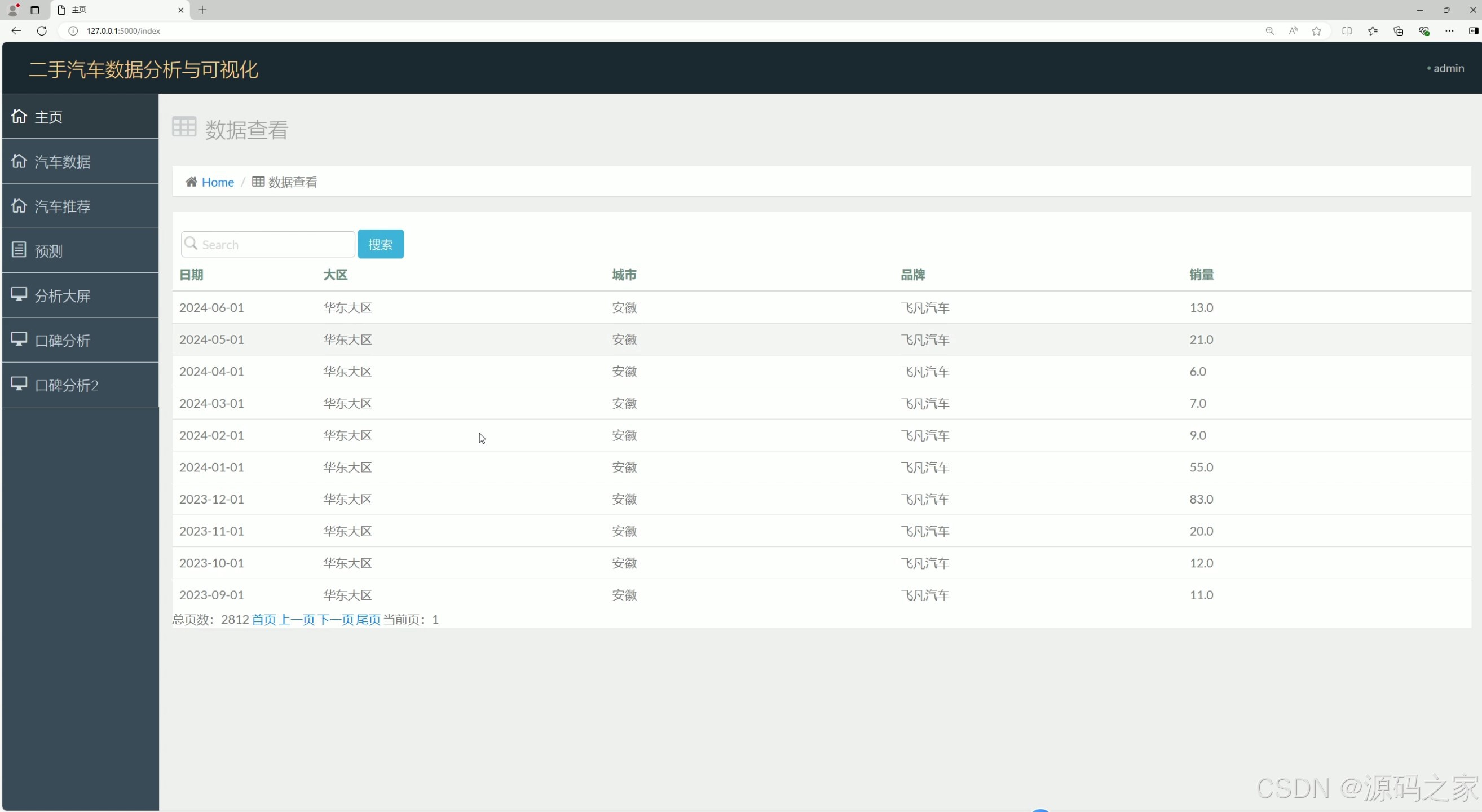
数据中心
-
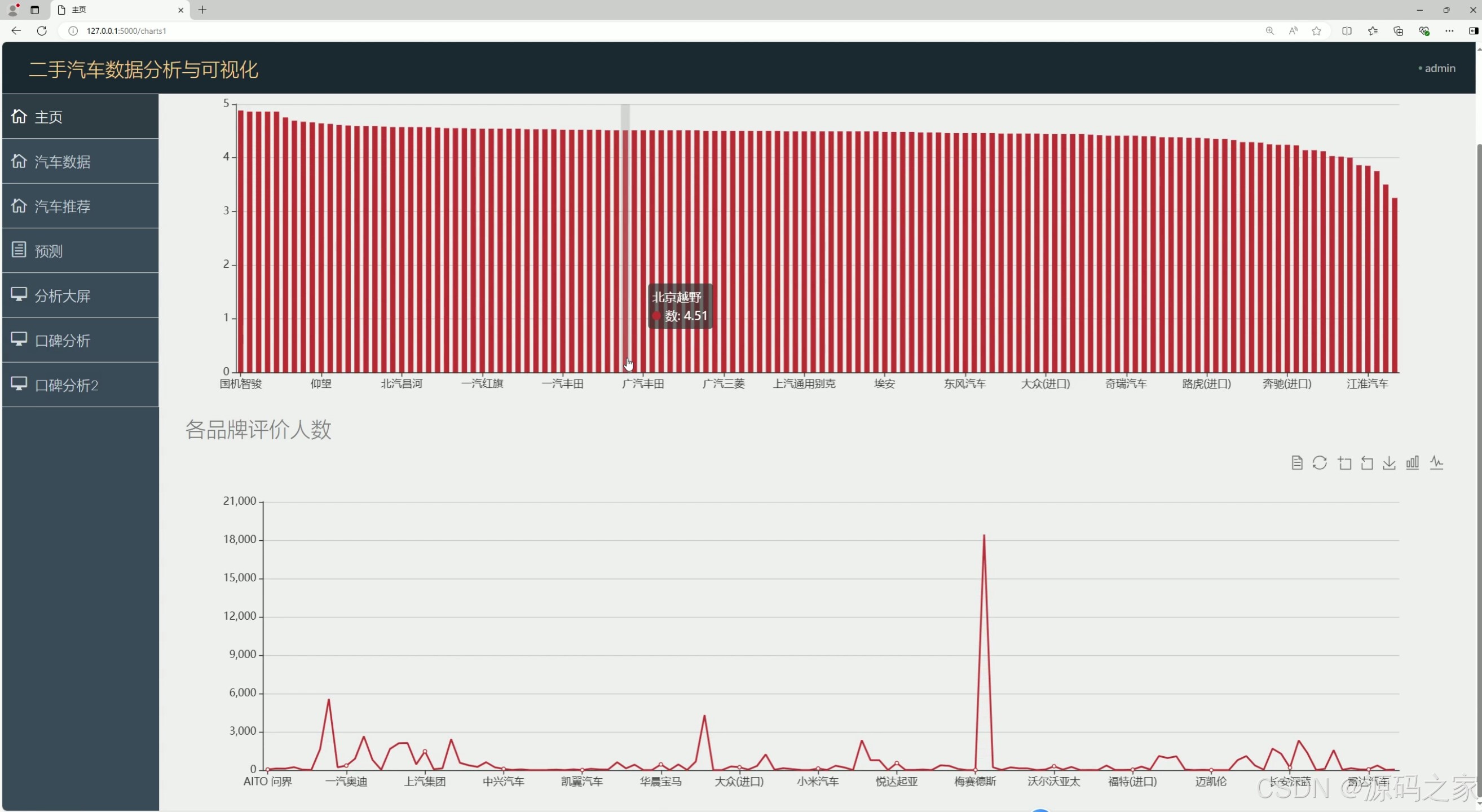
汽车口碑分析1----评分、评价人数
-
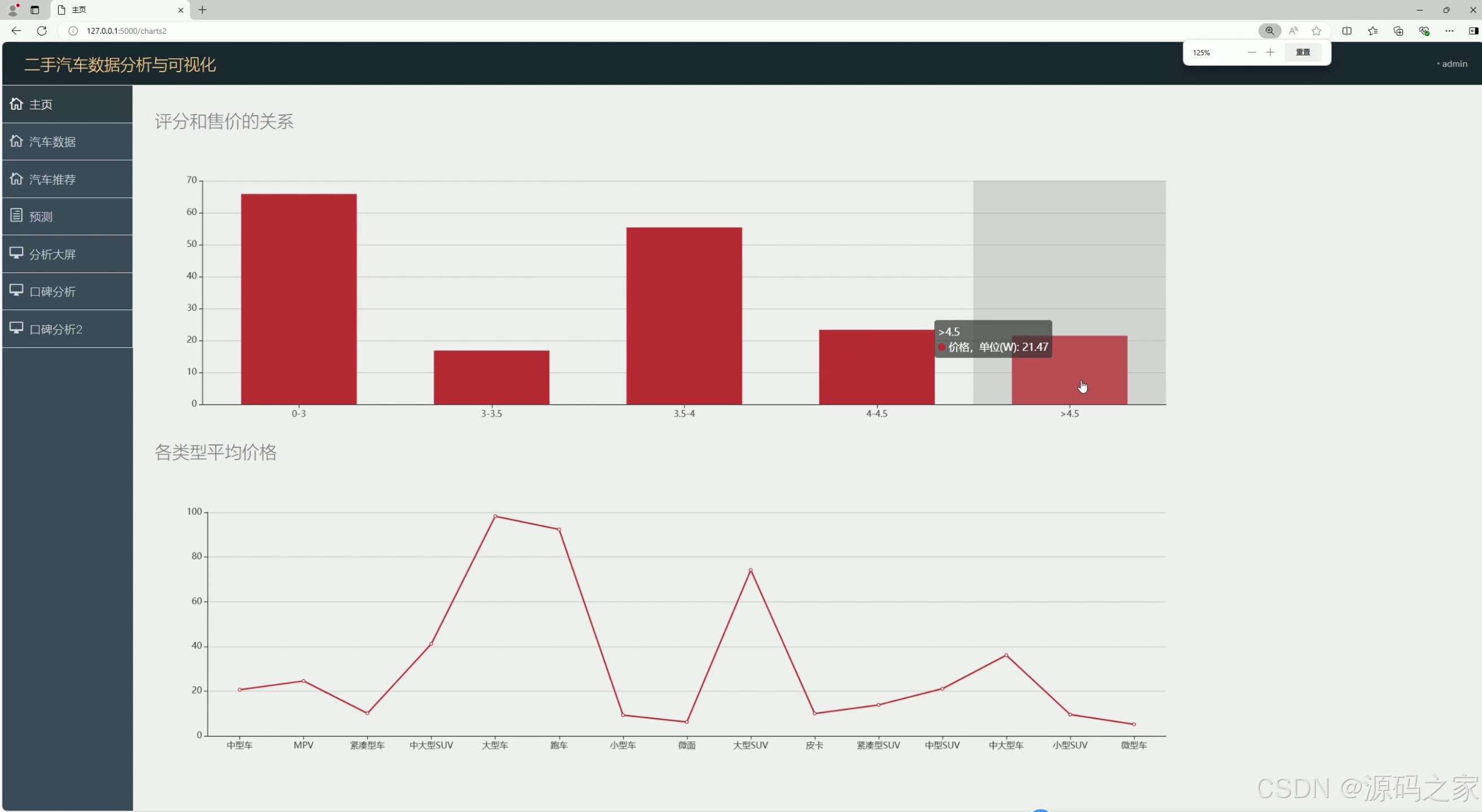
汽车口碑分析2----评分与售价关系、各类型均价分析
-
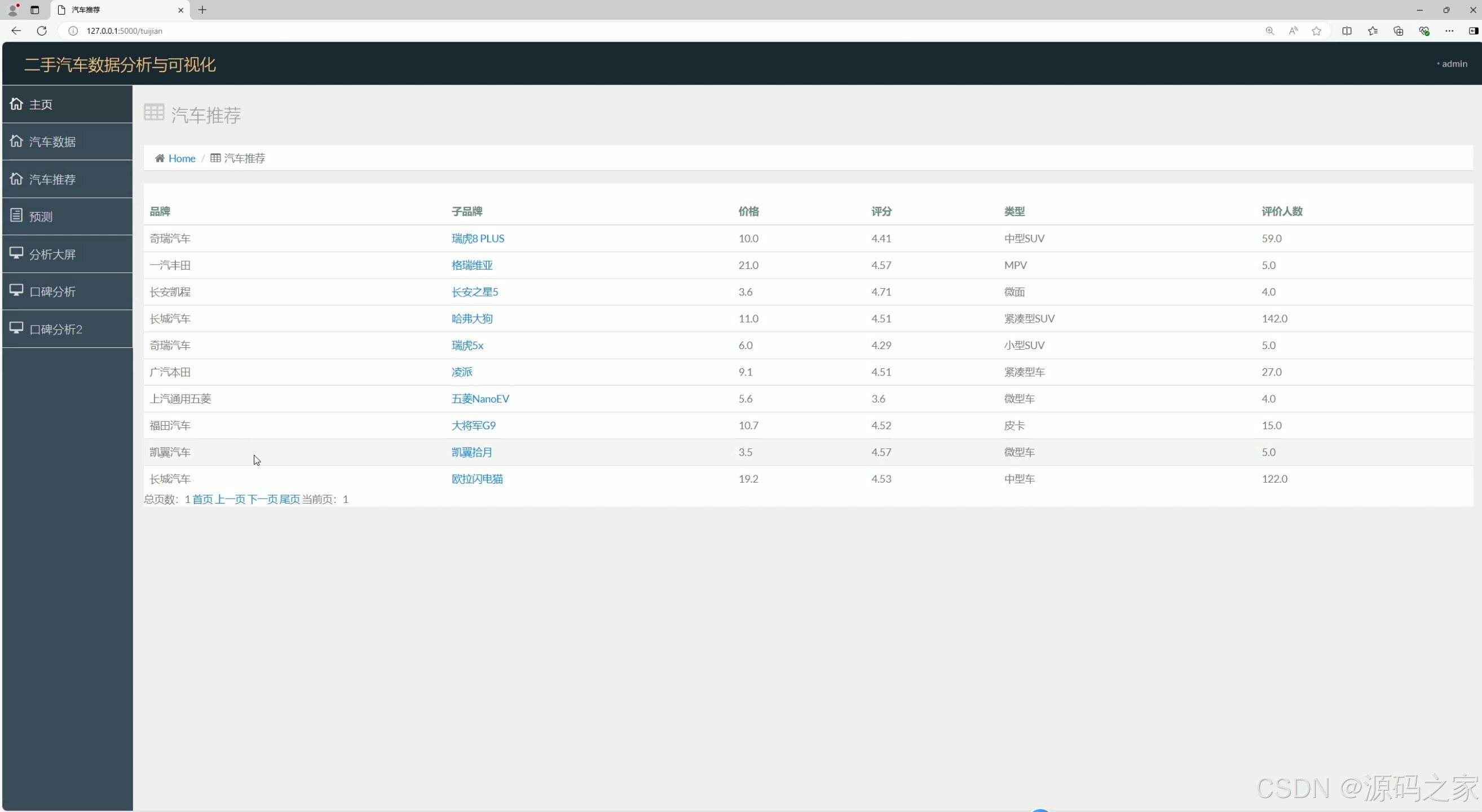
汽车推荐
-
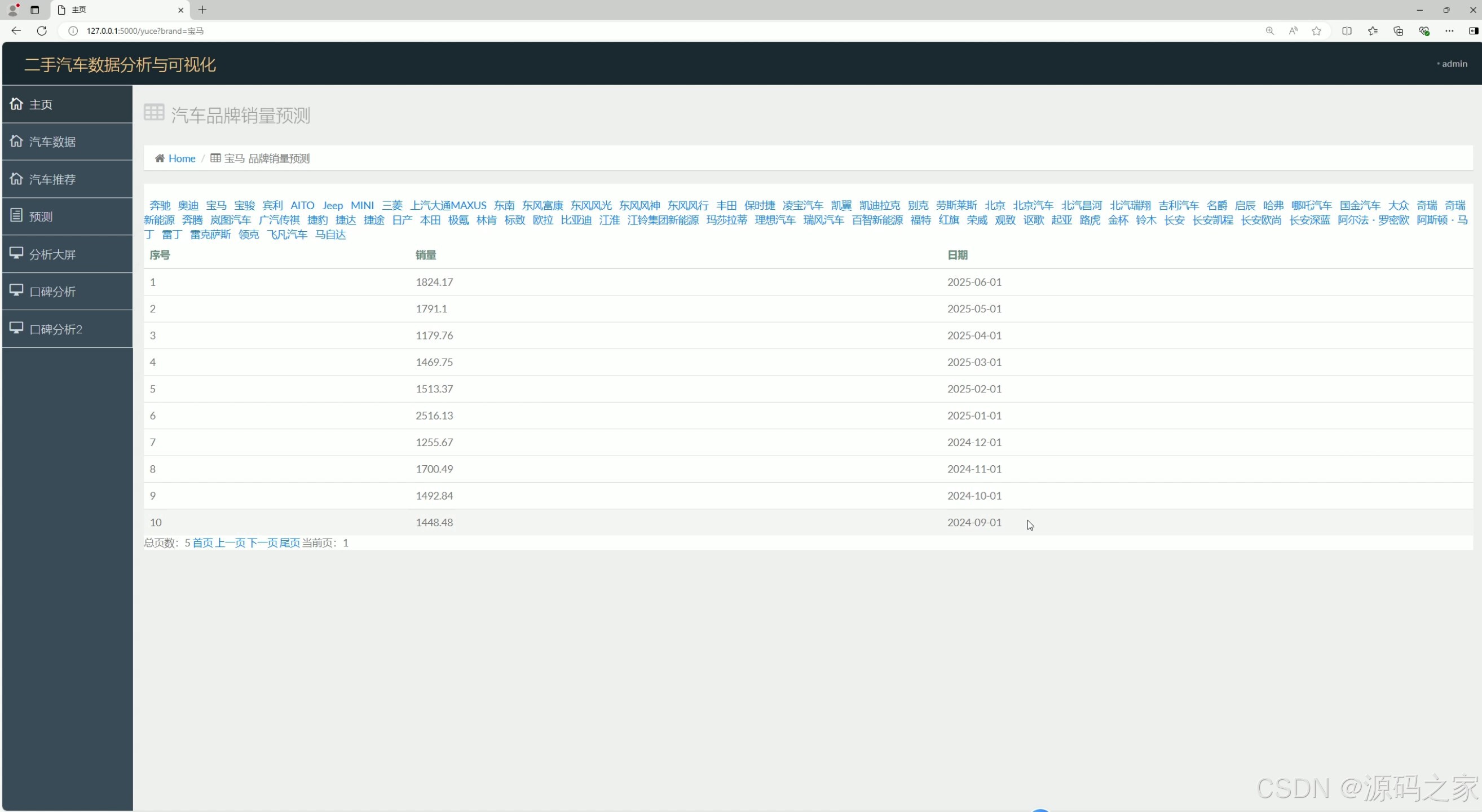
各品牌销量预测
-
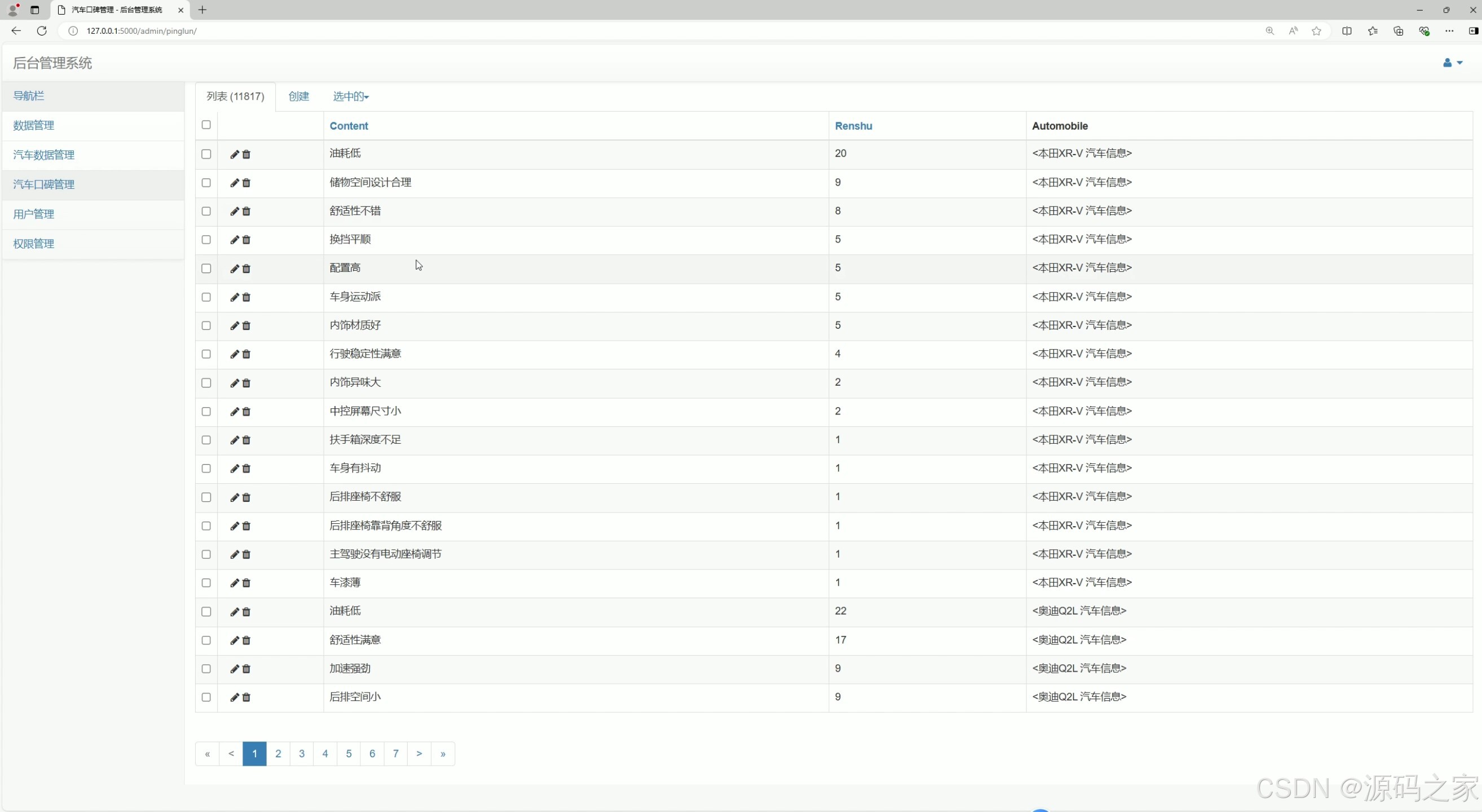
后台管理
-
注册登录
-
数据采集
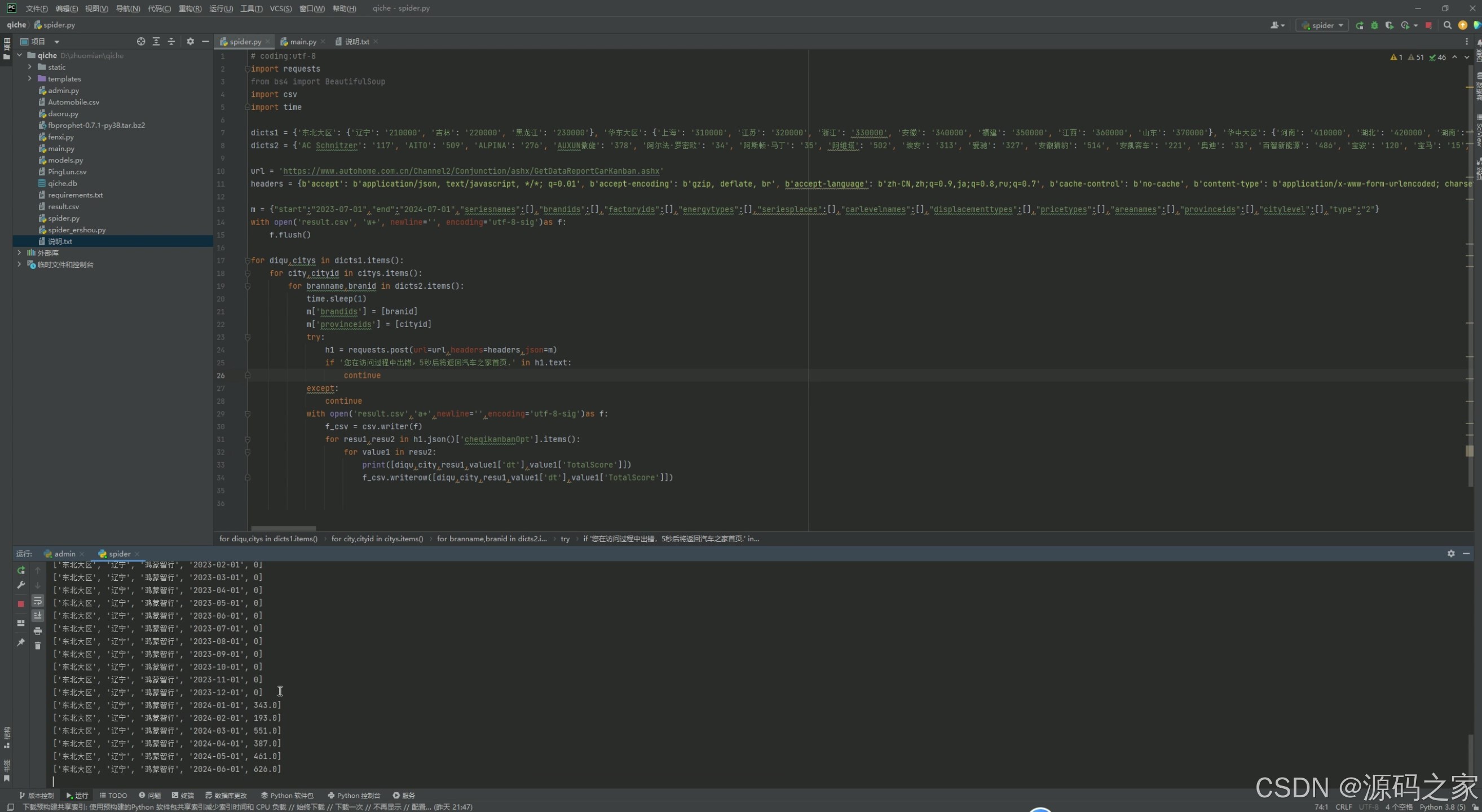
3、项目说明
本项目是基于Python+Flask框架开发的汽车之家二手车数据智能分析系统,整合requests爬虫、逻辑回归、Prophet时间序列算法与Echarts可视化,构建"数据采集-口碑分析-销量预测-个性化推荐-后台管理"的完整流程,旨在解决二手车市场数据利用低效、决策缺乏科学支撑的问题。
(1)系统架构与技术逻辑
- 架构设计:采用"前后端轻量协同"模式------后端基于Flask框架,负责三大核心任务:① requests爬虫采集汽车之家数据(车型、口碑、销量);② 算法调度(逻辑回归分析口碑、Prophet预测销量);③ 接口开发(为前端提供数据与功能支撑);前端通过HTML+CSS构建交互界面,核心嵌入Echarts组件,将后端数据转化为可视化图表,支持用户操作与结果展示。
- 数据支撑:系统数据源聚焦汽车之家二手车板块,涵盖车辆基础信息(品牌、型号、售价、年份)、口碑数据(用户评分、评价内容、评价人数)、销量数据(各品牌月度/季度销量),经爬虫采集后清洗(去重、补缺失值),存储至数据库(如MySQL/SQLite),为后续模块提供高质量输入。
(2)核心功能模块详解
① 数据采集模块(基础支撑)
- 功能:实现汽车之家二手车数据的自动化采集与更新,解决"数据手动获取耗时"问题;
- 技术实现 :
- 爬虫逻辑:用requests库模拟浏览器请求,解析汽车之家网页HTML结构,编写定向抽取规则,获取车型列表、用户口碑、历史销量等数据;
- 采集控制:支持两种模式------"数据采集"界面手动触发(用户点击"开始采集")、定时自动运行(通过Flask调度任务,如每日凌晨更新前一天销量);
- 数据预处理:采集后自动过滤无效数据(如重复车型、无评分的口碑),统一数据格式(如售价保留两位小数、销量按月份规整),确保数据可用性。
② 数据可视化模块(直观展示)
- 数据可视化分析大屏 :
- 功能:作为系统宏观入口,整合口碑、销量、价格的核心指标,如"各品牌销量TOP10柱状图""二手车均价区间饼图""口碑评分分布折线图";
- 价值:用户一眼把握二手车市场整体动态,为战略决策提供宏观参考;
- 数据中心 :
- 功能:提供数据明细查询与管理,支持按"品牌、价格区间、评分"筛选车辆数据,展示原始数据表格(如"2023款丰田凯美瑞,售价18.5万,评分4.7");
- 价值:满足用户"精细化查数"需求,为后续口碑分析、推荐提供数据筛选基础。
③ 汽车口碑分析模块(逻辑回归应用)
- 功能:量化分析二手车口碑与关键指标的关联,避免"主观判断偏差";
- 技术实现(逻辑回归算法) :
- 分析维度1:以"评价人数"为因变量,"品牌、车型、评分"为自变量,构建逻辑回归模型,判断哪些因素对评价热度影响显著(如"豪华品牌评价人数通常更高");
- 分析维度2:以"评分"为因变量,"售价、车龄、配置"为自变量,模型输出"评分与售价的关联系数"(如"售价15-25万区间车型评分普遍高于10万以下车型");
- 可视化呈现:通过Echarts生成"评分与售价散点图""各类型车型均价柱状图"(如SUV、轿车均价对比),直观展示分析结果,辅助用户判断车型性价比。
④ 汽车推荐模块(逻辑回归驱动)
- 功能:基于用户需求实现个性化二手车推荐,解决"海量车源筛选难"问题;
- 技术实现 :
- 需求采集:用户在推荐界面输入偏好(如"预算15-20万""SUV车型""评分≥4.5");
- 模型匹配:逻辑回归模型将用户需求转化为特征变量,与数据库中车辆特征进行匹配,按"匹配度+销量热度"排序;
- 结果展示:推荐列表展示车辆图文信息、评分、口碑摘要,支持点击查看详情,提升用户找车效率。
⑤ 各品牌销量预测模块(Prophet算法核心)
- 功能:预测未来一段时间(如3个月、6个月)各二手车品牌的销量趋势,为卖家库存规划提供依据;
- 技术实现(Prophet时间序列算法) :
- 数据输入:将数据库中各品牌历史销量数据(如近2年每月销量)按品牌分组,作为Prophet模型输入;
- 模型训练:Prophet自动捕捉销量的"趋势性"(如逐年增长/下降)、"季节性"(如春节后销量高峰),无需复杂参数调优;
- 预测输出:生成各品牌销量预测曲线(含预测值与置信区间),通过Echarts在"销量预测"界面展示,支持对比不同品牌趋势;
- 价值:帮助卖家提前调整库存(如预测销量增长则增加备货),减少库存积压或缺货风险。
⑥ 后台管理与注册登录模块(系统运维)
- 后台管理(管理员专属) :
- 数据管理:增删改查数据库车辆数据、口碑记录,导出分析结果为Excel;
- 用户管理:维护注册用户账号,划分权限(普通用户/管理员);
- 爬虫监控:查看爬虫运行日志(如采集成功条数、失败原因),确保数据更新正常;
- 注册登录 :
- 功能:用户通过账号密码认证,登录后获取对应权限(普通用户可使用推荐、查看分析;管理员可进入后台);
- 安全保障:Flask实现密码加密存储,防止用户信息泄露。
4、核心代码
python
import re
import time
import traceback
import requests
from bs4 import BeautifulSoup
import models
from sqlalchemy import and_
session = requests.session()
url = 'https://k.autohome.com.cn/'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36",
"Referer": "https://k.autohome.com.cn/"
}
session.get(url=url,headers=headers,verify=False)
dicts_item = {
'小型SUV': 'https://k.autohome.com.cn/suva01/',
'紧凑型SUV': 'https://k.autohome.com.cn/suva1/',
'中型SUV': 'https://k.autohome.com.cn/suvb1/',
'中大型SUV': 'https://k.autohome.com.cn/suvc1/',
'大型SUV': 'https://k.autohome.com.cn/suvd1/',
'微型车': 'https://k.autohome.com.cn/a001/',
'小型车': 'https://k.autohome.com.cn/a01/',
'紧凑型车': 'https://k.autohome.com.cn/a1/',
'中型车': 'https://k.autohome.com.cn/b1/',
'中大型车': 'https://k.autohome.com.cn/c1/',
'大型车': 'https://k.autohome.com.cn/d1/',
'MPV': 'https://k.autohome.com.cn/mpv1/',
'跑车': 'https://k.autohome.com.cn/s1/',
'皮卡': 'https://k.autohome.com.cn/p1/',
'微面': 'https://k.autohome.com.cn/mb1/'}
for _key,_url in dicts_item.items():
time.sleep(3)
headers = {
}
print(_url)
h1 = session.get(url=_url + '#pvareaid=2099126',headers=headers,verify=False)
print(h1.request.url)
if h1.request.url == 'https://k.autohome.com.cn':
print(1111)
h1 = session.get(url=_url, headers=headers, verify=False)
soup = BeautifulSoup(h1.text,'html.parser')
lis = soup.select('ul.list-cont > li')
# print(lis)
for li in lis:
time.sleep(1)
try:
img_url = li.select('img')[0].attrs.get('src')
title = li.select('a.font-14-b')[0].text.strip()
fenshu = li.select('span.red')[0].text.strip()
renshu = li.select('a')[-1].text.strip()
lianjie = li.select('a.font-14-b')[0].attrs.get('href')
if not str(lianjie).startswith('http'):
lianjie = 'https://k.autohome.com.cn' + lianjie + '#pvareaid=102519'
print(img_url,title,fenshu,renshu,lianjie)
print(lianjie)
h2 = session.get(url=lianjie, headers=headers, verify=False)
soup2 = BeautifulSoup(h2.text, 'html.parser')
# print(soup2)
subnav_name = soup2.select('div.header_toolbar__car__name__5SxJb a')[0].text
brand = subnav_name.split('-')[0]
Sub_brand = subnav_name.split('-')[1:]
if len(Sub_brand) == 1:
Sub_brand = Sub_brand[0]
else:
Sub_brand = '-'.join(Sub_brand)
price = re.findall('seriesMinPrice":{"title":"(.*?)万',h2.text)[0]
pingjias = soup2.select('ul.score_tag__Wq2Z4 > li')
if not models.Automobile.query.filter(models.Automobile.url==lianjie).all():
models.db.session.add(
models.Automobile(
title=title,
brand=brand,
Sub_brand=Sub_brand,
price=price,
pingfen=fenshu,
renshu=renshu,
img_url=img_url,
url=lianjie,
type=_key
)
)
models.db.session.commit()
for pingjia in pingjias:
print(pingjia)
try:
text1 = pingjia.select("div")[0].text.strip()
renshu2 = re.findall('(\d+)',text1)
if renshu2:
renshu2 = renshu2[0]
else:
renshu2 = '0'
content = text1.replace(renshu2,'')
datas1 = models.Automobile.query.filter(models.Automobile.url==lianjie).all()[0]
print(content,renshu2)
if not models.PingLun.query.filter(
and_(models.PingLun.automobile_id == datas1.id, models.PingLun.content == content)).all():
print('插入数据',content,renshu2)
models.db.session.add(
models.PingLun(
content=content,
renshu = renshu2,
automobile_id = datas1.id
)
)
models.db.session.commit()
except:
print(traceback.format_exc())
continue
except:
print(traceback.format_exc())
continue🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看 👇🏻获取联系方式👇🏻