文章目录
- 0.CNN的核心思想
- 1.卷积层-提取局部特征
-
- [1.1 卷积动画理解](#1.1 卷积动画理解)
- [1.2 卷积运算](#1.2 卷积运算)
- 2.池化层-压缩数据,提取关键信息
-
- [2.1 池化动画理解](#2.1 池化动画理解)
- [2.2 池化层理论运算](#2.2 池化层理论运算)
- 3.全连接层-做最终决策
-
- [3.1 全连接层相关理论](#3.1 全连接层相关理论)
- 4.代码实现CNN
- 5.CNN代码重要参数讲解
最近结合一些文章及视频学习CNN,学习过程中遇到便于理解的例子记录一下,方便有同样需要的人参考。
0.CNN的核心思想
传统神经网络处理图像时,需将二维图像展平为一维向量输入全连接层,导致参数数量爆炸(如 28×28 的 MNIST 图像展平后为 784 维,若全连接层有 1000 个神经元,仅该层参数就达 78.4 万),且无法保留图像的空间结构信息(如像素的邻域关系)。
CNN 借鉴生物视觉系统的 "感受野" 机制:视觉皮层的神经元仅对视野中的局部区域敏感,且相邻神经元的感受野有重叠,从而高效捕捉局部特征。同时,通过权重共享减少参数冗余,通过下采样降低特征维度,兼顾模型性能与计算效率。

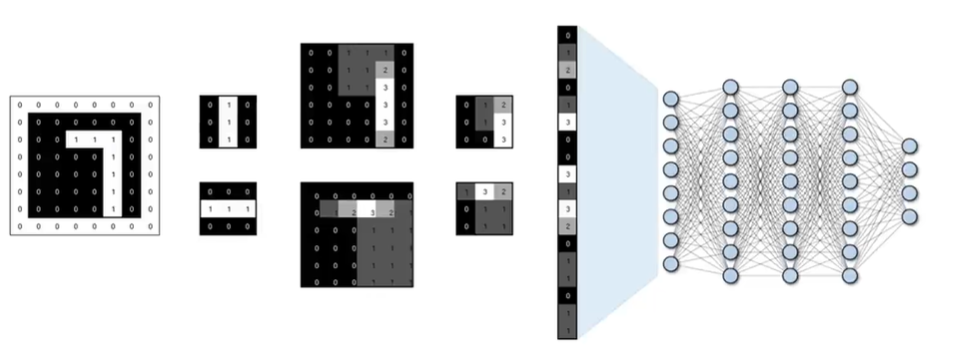
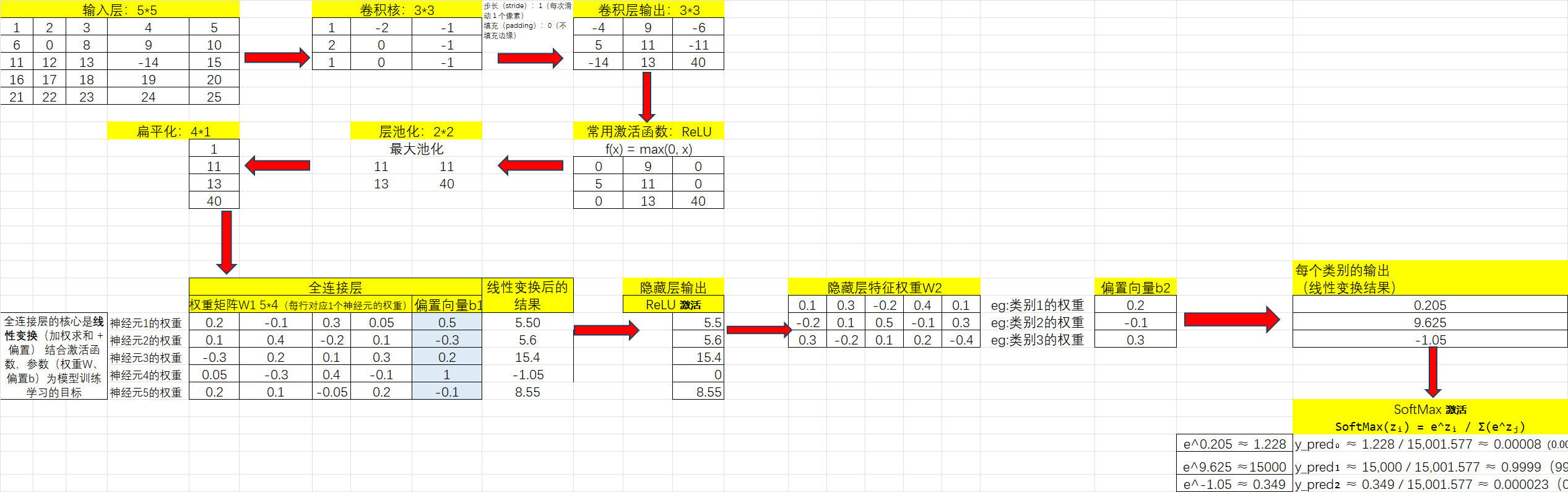
自己在理解过程中,利用Excel画的图,把抽象难以理解的东西尽量以简单的方式去理解,重要的图提前放。
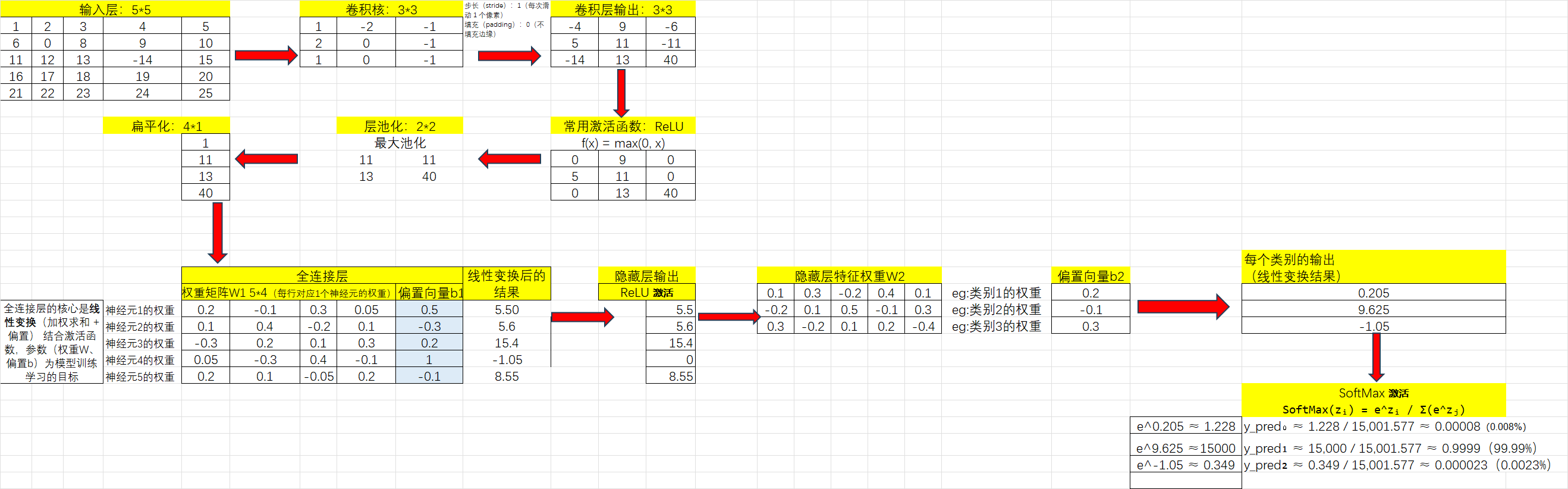
1.卷积层-提取局部特征
1.1 卷积动画理解
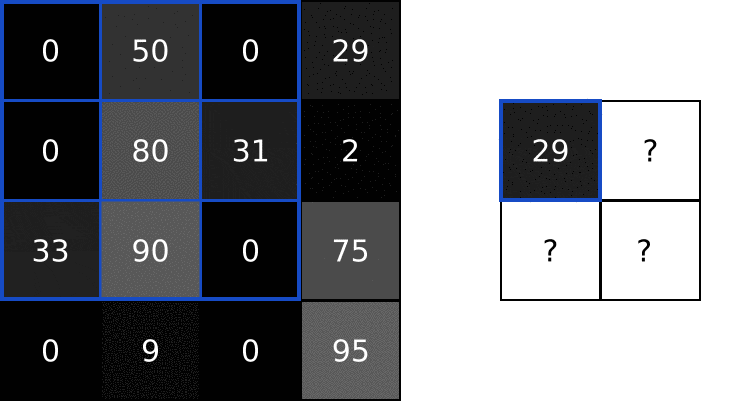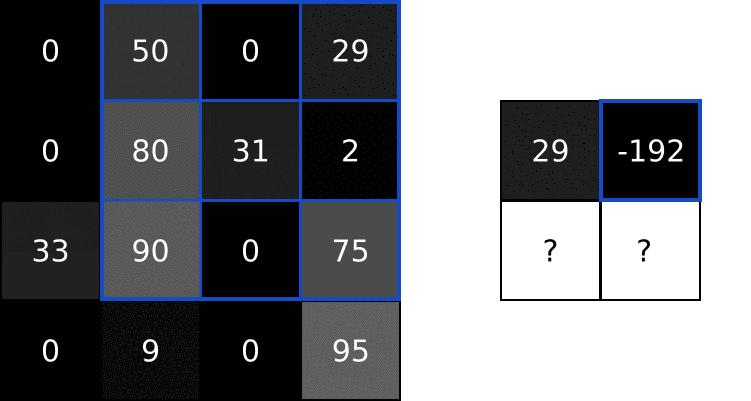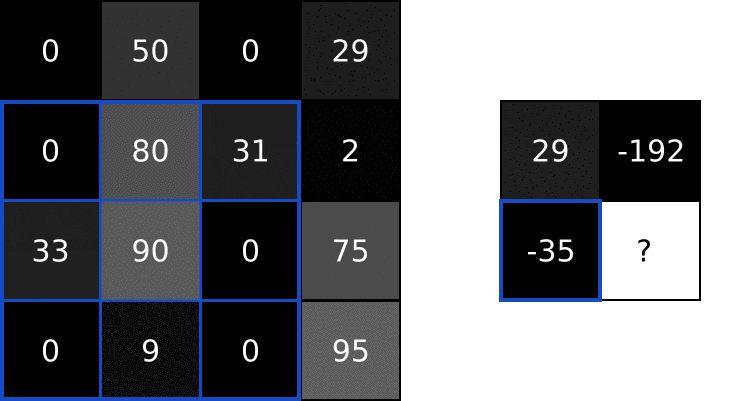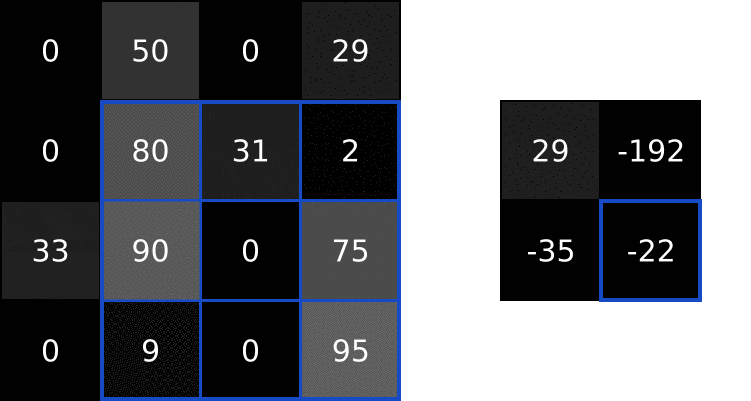
参考深度学习】Python实现CNN操作 里的动图
- 提取图片特征:用卷积核(大小通常为33,55),也成为特征过滤器;
- 逐步扫描整张图像 提取特征的计算规则;
- 每次滑过时,计算当前区域的加权求和; 这样提取出不同层次的特征(比如第一层提取边缘,第二层识别形状,第三层检测复杂对象)
具体运算过程见-卷积运算。
1.2 卷积运算
理论理解参考超全面讲透一个强大算法模型,CNN!!




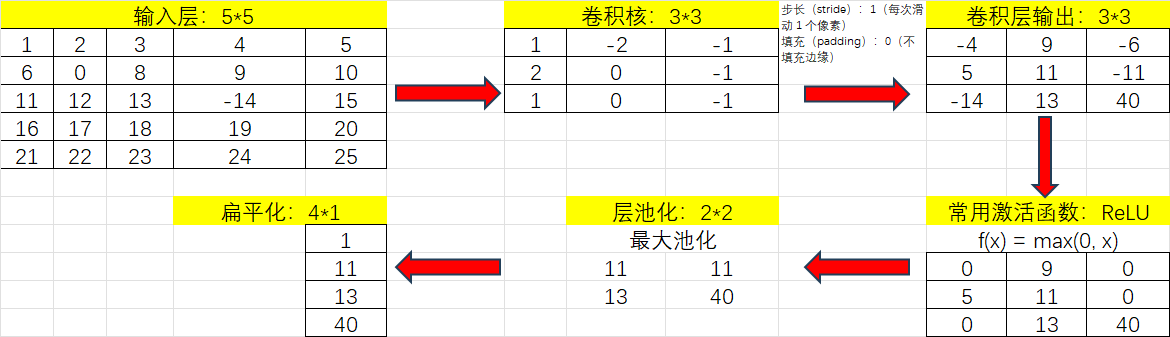
卷积层输出的特征图是线性的,激活函数通过引入非线性变换,使模型能拟合复杂的非线性关系。

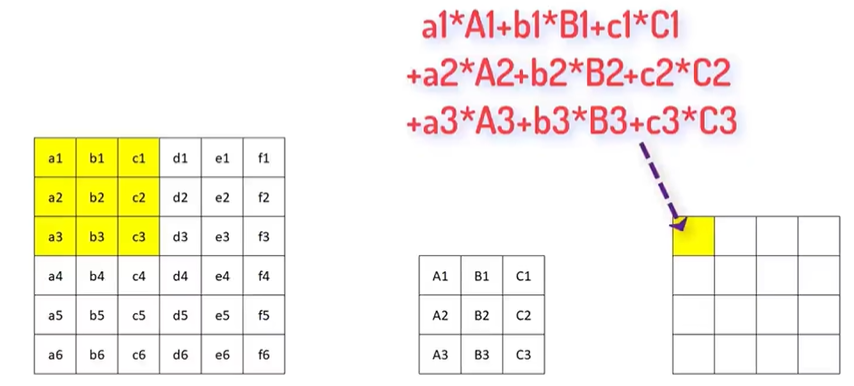
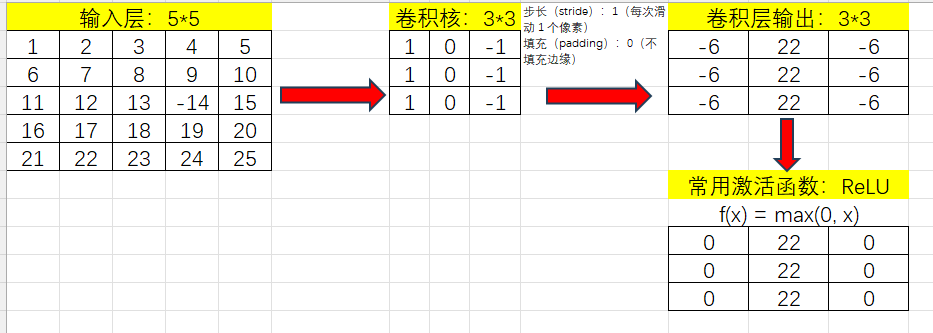
以这个图为例,输出尺寸为(6-3)/1+1=4
根据以上理论流程,使用简单数据用Excel做了示例便于理解。
2.池化层-压缩数据,提取关键信息
2.1 池化动画理解
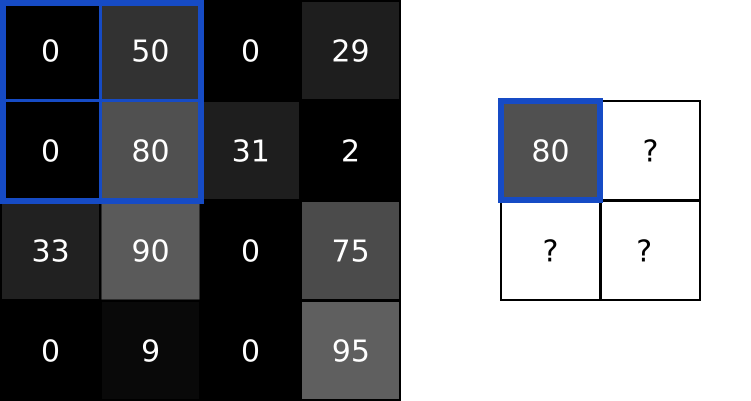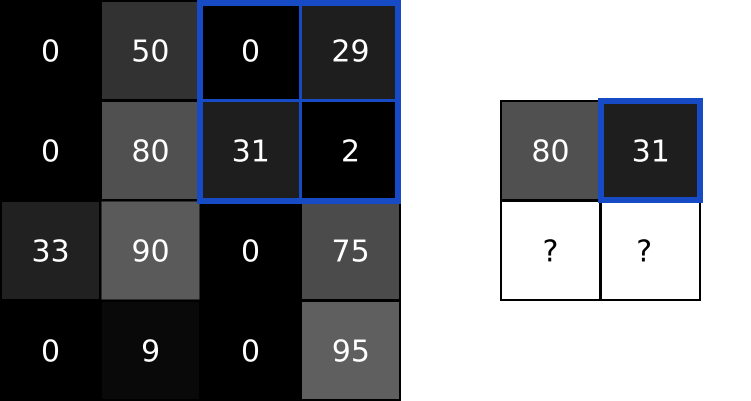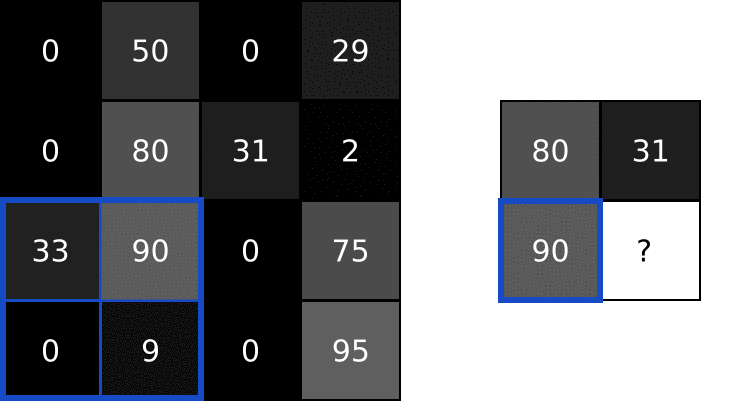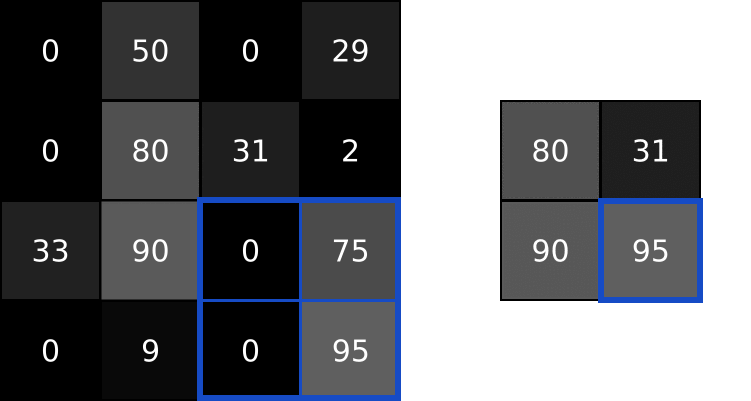
- 池化层通过「最大池化(Max Pooling)」或者「平均池化(Average Pooling)」缩小数据,类似于「压缩图片,但保留主要内容」。

2.2 池化层理论运算

这里放一个在视频里动画讲如何池化的例子,更有助于理解。
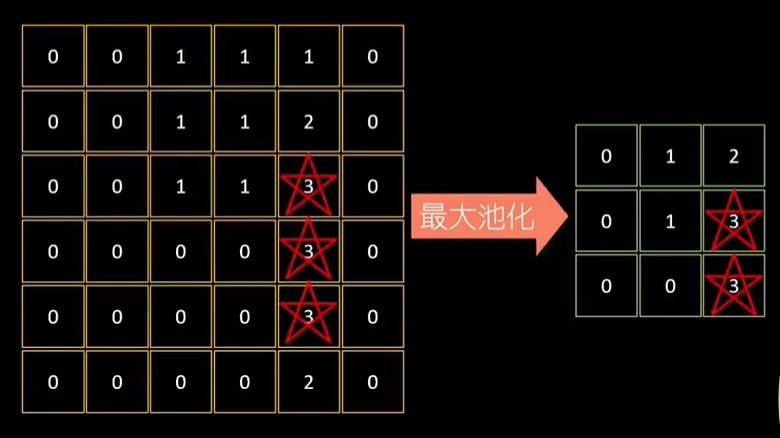

把池化后的数据进行扁平化处理,转化为1维的数据条,数据条录入到后面的"全连接隐藏层"
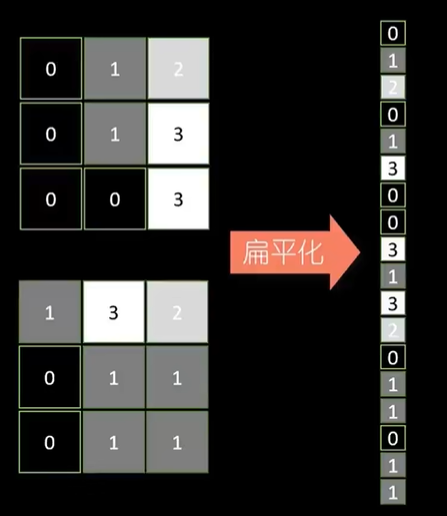
3.全连接层-做最终决策

3.1 全连接层相关理论
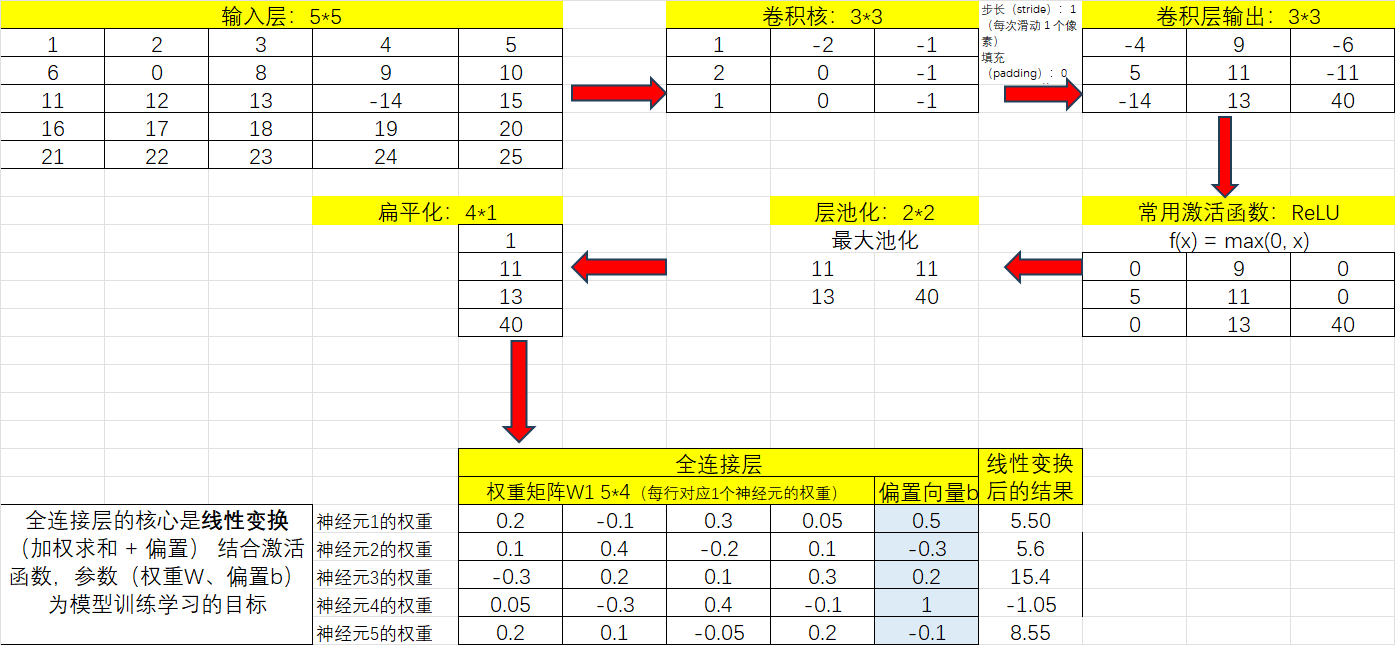
全连接隐藏层意味着扁平化后的数据,任意一个神经元都与前后层的所有神经元相连接,这样就可以保证最终的输出值是基于图片整体信息的结果。




4.代码实现CNN
代码示例1
因为还在学习过程,这里的例子我使用的是前面文章里,能够成功复现感觉已经很开心了。
python
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import DataLoader, TensorDataset
import matplotlib.pyplot as plt
import numpy as np
# 生成虚拟数据集(例如,使用随机生成的图像数据)
def generate_synthetic_data(num_samples=1000, img_size=(28, 28), num_classes=10):
images = torch.randn(num_samples, 1, img_size[0], img_size[1]) # 随机生成图像数据
labels = torch.randint(0, num_classes, (num_samples,)) # 随机生成标签
return images, labels
# 定义一个简单的CNN模型
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)
self.fc1 = nn.Linear(64 * 7 * 7, 128)
self.fc2 = nn.Linear(128, 10) # 10个类的输出
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2) # 池化层
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2)
x = x.view(x.size(0), -1) # Flatten
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
# 生成数据
train_images, train_labels = generate_synthetic_data(num_samples=800)
val_images, val_labels = generate_synthetic_data(num_samples=100)
test_images, test_labels = generate_synthetic_data(num_samples=100)
# 创建数据加载器
train_dataset = TensorDataset(train_images, train_labels)
val_dataset = TensorDataset(val_images, val_labels)
test_dataset = TensorDataset(test_images, test_labels)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=32)
test_loader = DataLoader(test_dataset, batch_size=32)
# 初始化模型、损失函数和优化器
model = SimpleCNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 学习率调度器
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.7)
# 训练和评估函数
def train_and_evaluate(model, train_loader, val_loader, optimizer, criterion, scheduler, num_epochs=20):
train_losses = []
val_losses = []
train_acc = []
val_acc = []
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
correct = 0
total = 0
# Training loop
for inputs, labels in train_loader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
train_loss = running_loss / len(train_loader)
train_accuracy = 100 * correct / total
train_losses.append(train_loss)
train_acc.append(train_accuracy)
# Validation loop
model.eval()
val_loss = 0.0
val_correct = 0
val_total = 0
with torch.no_grad():
for inputs, labels in val_loader:
outputs = model(inputs)
loss = criterion(outputs, labels)
val_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
val_total += labels.size(0)
val_correct += (predicted == labels).sum().item()
val_loss = val_loss / len(val_loader)
val_accuracy = 100 * val_correct / val_total
val_losses.append(val_loss)
val_acc.append(val_accuracy)
# 调度器调整学习率
scheduler.step()
return train_losses, train_acc, val_losses, val_acc
# 训练并获取数据
train_losses, train_acc, val_losses, val_acc = train_and_evaluate(model, train_loader, val_loader, optimizer, criterion, scheduler)
# 绘制图形
fig, axs = plt.subplots(2, 2, figsize=(14, 10))
# 图1: 损失函数曲线
axs[0, 0].plot(train_losses, label='Train Loss', color='blue', linewidth=2)
axs[0, 0].plot(val_losses, label='Validation Loss', color='red', linewidth=2)
axs[0, 0].set_title('Loss Curve')
axs[0, 0].set_xlabel('Epoch')
axs[0, 0].set_ylabel('Loss')
axs[0, 0].legend()
# 图2: 训练精度曲线
axs[0, 1].plot(train_acc, label='Train Accuracy', color='green', linewidth=2)
axs[0, 1].plot(val_acc, label='Validation Accuracy', color='orange', linewidth=2)
axs[0, 1].set_title('Accuracy Curve')
axs[0, 1].set_xlabel('Epoch')
axs[0, 1].set_ylabel('Accuracy (%)')
axs[0, 1].legend()
# 图3: 测试精度(模拟的结果)
test_acc = 80 + np.random.randn(100) * 5 # 模拟测试精度
axs[1, 0].plot(test_acc, label='Test Accuracy', color='purple', linewidth=2)
axs[1, 0].set_title('Test Accuracy')
axs[1, 0].set_xlabel('Samples')
axs[1, 0].set_ylabel('Accuracy (%)')
axs[1, 0].legend()
# 图4: 训练损失的平均曲线
axs[1, 1].plot(np.cumsum(train_losses) / (np.arange(len(train_losses)) + 1), label='Cumulative Train Loss', color='pink', linewidth=2)
axs[1, 1].set_title('Cumulative Training Loss')
axs[1, 1].set_xlabel('Epoch')
axs[1, 1].set_ylabel('Cumulative Loss')
axs[1, 1].legend()
plt.tight_layout()
plt.show()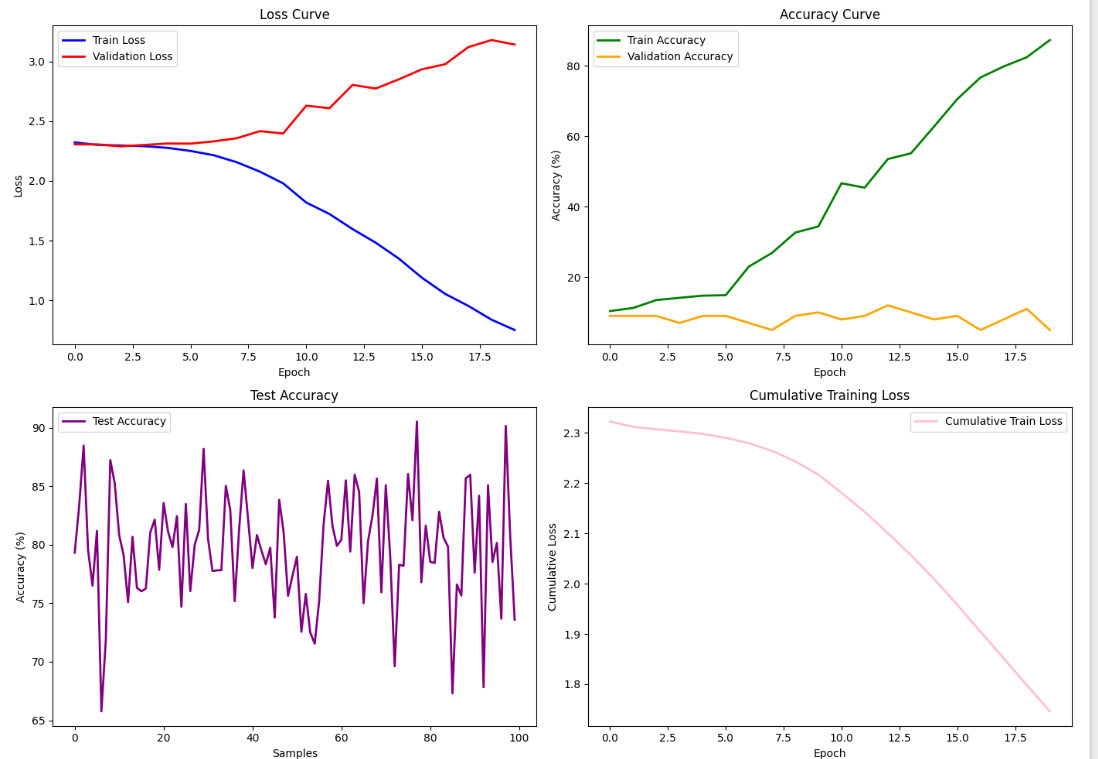
代码示例2
python
# 1. 导入必要的库
import torch # PyTorch 核心库,用于张量操作和神经网络
import torch.nn as nn # 神经网络模块,包含各种层和损失函数
import torch.optim as optim # 优化器模块,用于模型参数优化
from torch.utils.data import DataLoader # 数据加载工具,用于批量加载数据
from torchvision import datasets, transforms # 计算机视觉工具,包含数据集和数据预处理
import matplotlib.pyplot as plt # 可视化工具,用于展示训练过程和结果
# 2. 设置超参数(根据任务调整)
batch_size = 64 # 每次训练的样本批次大小,影响训练效率和模型收敛
learning_rate = 0.001 # 学习率,控制参数更新幅度,过大会不收敛,过小会训练慢
num_epochs = 10 # 训练轮次,完整遍历数据集的次数
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 自动选择GPU或CPU训练
# 3. 数据预处理与加载
# 定义数据转换:将图像转为张量,并标准化(均值=0.1307,标准差=0.3081是MNIST数据集的统计值)
transform = transforms.Compose([
transforms.ToTensor(), # 将PIL图像转为Tensor(维度:[C, H, W],值范围0-1)
transforms.Normalize((0.1307,), (0.3081,)) # 标准化:output = (input - mean) / std
])
# 加载MNIST训练集和测试集(自动下载到本地)
train_dataset = datasets.MNIST(
root='./data', # 数据保存路径
train=True, # 训练集
transform=transform, # 应用预处理
download=True # 若本地无数据则下载
)
test_dataset = datasets.MNIST(
root='./data',
train=False, # 测试集
transform=transform,
download=True
)
# 用DataLoader封装数据集,支持批量加载、打乱顺序、多线程加载
train_loader = DataLoader(
dataset=train_dataset,
batch_size=batch_size,
shuffle=True # 训练时打乱数据,增强泛化能力
)
test_loader = DataLoader(
dataset=test_dataset,
batch_size=batch_size,
shuffle=False # 测试时无需打乱
)
# 4. 定义CNN模型(核心部分)
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__() # 继承父类nn.Module的初始化方法
# 卷积层1:输入通道1(灰度图),输出通道16,卷积核3x3,步长1,边缘填充1(保持尺寸)
self.conv1 = nn.Conv2d(in_channels=1, out_channels=16, kernel_size=3, stride=1, padding=1)
# 激活函数:ReLU,引入非线性,增强模型表达能力
self.relu = nn.ReLU()
# 池化层1:2x2最大池化,步长2(尺寸减半)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
# 卷积层2:输入通道16,输出通道32,卷积核3x3,步长1,填充1
self.conv2 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, stride=1, padding=1)
# 全连接层1:输入特征数=32*7*7(池化后尺寸:28/2/2=7),输出128
self.fc1 = nn.Linear(32 * 7 * 7, 128)
# 全连接层2:输入128,输出10(MNIST有10个类别)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
# 前向传播过程(定义数据在模型中的流动路径)
# 输入x形状:[batch_size, 1, 28, 28]
x = self.conv1(x) # 卷积1:[batch_size, 16, 28, 28]
x = self.relu(x) # 激活:保持形状不变
x = self.pool(x) # 池化1:[batch_size, 16, 14, 14](28/2=14)
x = self.conv2(x) # 卷积2:[batch_size, 32, 14, 14]
x = self.relu(x) # 激活:保持形状不变
x = self.pool(x) # 池化2:[batch_size, 32, 7, 7](14/2=7)
x = x.view(-1, 32 * 7 * 7) # 展平:[batch_size, 32*7*7=1568](-1表示自动计算batch_size)
x = self.fc1(x) # 全连接1:[batch_size, 128]
x = self.relu(x) # 激活:保持形状不变
x = self.fc2(x) # 全连接2:[batch_size, 10](输出10个类别的得分)
return x
# 5. 初始化模型、损失函数和优化器
model = CNN().to(device) # 创建模型实例,并移动到GPU/CPU
criterion = nn.CrossEntropyLoss() # 交叉熵损失,适用于分类任务(内置SoftMax)
optimizer = optim.Adam(model.parameters(), lr=learning_rate) # Adam优化器,常用且收敛稳定
# 6. 训练模型
train_losses = [] # 记录每轮训练的平均损失
for epoch in range(num_epochs):
model.train() # 切换到训练模式(启用 dropout、批归一化更新等)
running_loss = 0.0 # 累计当前轮次的损失
for i, (images, labels) in enumerate(train_loader):
# 将数据移动到设备(GPU/CPU)
images = images.to(device)
labels = labels.to(device)
# 前向传播:计算模型输出
outputs = model(images)
# 计算损失:输出与真实标签的差异
loss = criterion(outputs, labels)
# 反向传播与参数更新
optimizer.zero_grad() # 清空上一轮的梯度(否则会累积)
loss.backward() # 反向传播计算梯度
optimizer.step() # 根据梯度更新参数
running_loss += loss.item() # 累加损失(.item()将张量转为数值)
# 每100个批次打印一次中间结果
if (i + 1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{len(train_loader)}], Loss: {loss.item():.4f}')
# 计算当前轮次的平均损失并记录
avg_loss = running_loss / len(train_loader)
train_losses.append(avg_loss)
print(f'Epoch [{epoch+1}/{num_epochs}], Average Loss: {avg_loss:.4f}\n')
# 7. 测试模型(评估泛化能力)
model.eval() # 切换到评估模式(关闭 dropout、固定批归一化参数等)
with torch.no_grad(): # 禁用梯度计算,节省内存和计算资源
correct = 0 # 正确预测的样本数
total = 0 # 总样本数
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1) # 取得分最高的类别作为预测结果(维度1是类别)
total += labels.size(0) # 累加总样本数
correct += (predicted == labels).sum().item() # 累加正确样本数
print(f'Test Accuracy: {100 * correct / total:.2f}%') # 计算并打印测试准确率
# 8. 可视化训练损失曲线
plt.plot(range(1, num_epochs+1), train_losses)
plt.xlabel('Epoch')
plt.ylabel('Average Training Loss')
plt.title('Training Loss Curve')
plt.show()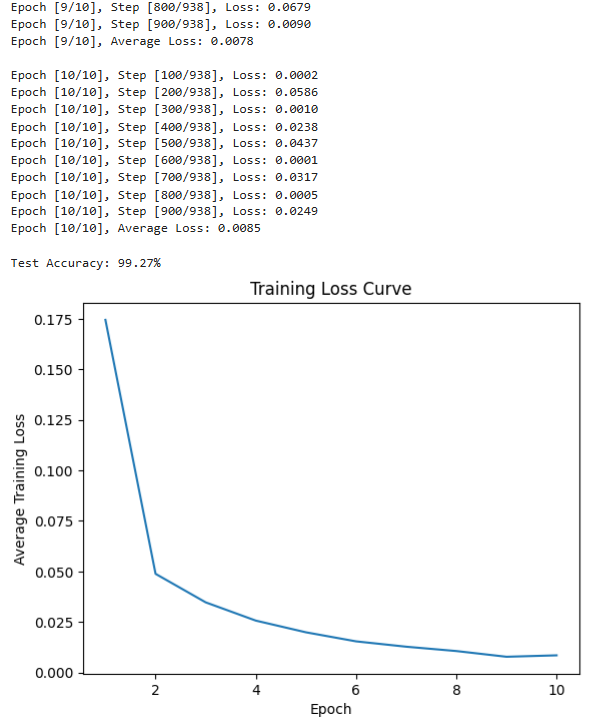
5.CNN代码重要参数讲解
代码中涉及一些东西,还需要细扣,敬请期待