"一致性" alignment ,更多的时候被译为"对齐"。每次它的含义都略有不同,取决于我们当时所处的层面,让我们慢慢梳理一下。
- 广义上的一致性(对齐)
从本质上讲,一致性意味着确保人工智能系统的行为与人类的意图(训练目标)和价值观相符。它旨在确保当模型做出回应时,模型输出与人类的实际需求保持一致。
因此,意图的一致性代表模型会按照你的要求去做。价值观的一致性指模型以一种良好、公平且无害的方式去做。结果一致性,保证结果真正有效,而不仅仅是表面看起来有效。你可以把它理解为"让理解、关怀和能力朝着同一个方向前进的艺术"。
- 训练中的一致性
从技术角度讲,一致性主要发生在预训练之后。在监督式微调阶段,人类会编写优秀答案的示例;模型会从中学习。然后,在强化学习高通量训练,通常是RLHF,也就是我们一直在讨论的阶段,一致性会进一步加深,因为奖励模型本身就编码了人类的偏好。
从数学角度来说,这就是我们要最小化的"一致性损失":
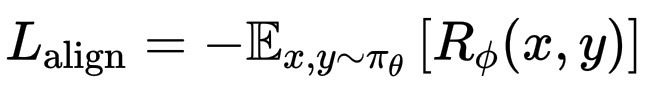
L_\text{align} = -\mathbb{E}{x,y\sim\pi\theta}\,R_\\phi(x,y)
此外,模型还受到一些约束(例如KL项)的限制,以确保模型与基础模型保持一致。这就是"训练"阶段的一致性,优化模型以使其行为更符合人类的喜好。
对齐问题并非语言模型独有,而是人工智能领域的普遍问题。任何从数据中学习或优化目标的系统,理论上都可能偏离其设计者的初衷。对于任何人工智能而言,对齐意味着确保系统的目标函数真正反映人类的期望,而不仅仅是人类写下的内容。预期目标与优化目标之间的差距正是错位的根源。例如:
• 机器人:一个训练为"快速移动"的机器人可能会撞倒东西,因为其奖励函数忽略了安全性和效率。对齐意味着调整奖励机制,以平衡速度和安全性。
• 推荐系统:一个优化"互动"的算法可能会传播两极分化的内容,因为这可以最大化点击量。对齐是指调整损失函数,使其包含长期福祉、公平性或真实性等因素。
• 自动驾驶车辆:它们必须协调感知、规划和伦理约束。例如,最大限度地减少伤害,而不仅仅是以最快的速度到达目的地。
• 大型语言模型:目标更为微妙,通过诸如 RLHF、宪法人工智能或直接偏好优化等方法,使输出与人类的意图和价值观(有益、无害、诚实)保持一致。
从数学角度来看,对齐是指真实人类目标 U_{human} 与模型优化目标 U_{model} 之间的不匹配:
不匹配度 = |U_{human} - U_{model}|
即使是很小的差异,在系统规模扩大或自主运行时也会增大。这就是为什么人们常说"确保强大的系统保持可纠正性和合作性"是一种一致性的研究。