
Java 大视界 --Java 大数据机器学习模型在金融风险压力测试中的应用与验证
- 引言:
- 正文:
-
-
- 一、金融风险压力测试的现状与挑战
-
- [1.1 传统压力测试的局限性](#1.1 传统压力测试的局限性)
- [1.2 新时代金融风险的复杂性](#1.2 新时代金融风险的复杂性)
- [二、Java 大数据机器学习模型技术基石](#二、Java 大数据机器学习模型技术基石)
-
- [2.1 多源数据采集与整合](#2.1 多源数据采集与整合)
- [2.2 机器学习模型构建与优化](#2.2 机器学习模型构建与优化)
- [2.3 模型对比与挑战分析](#2.3 模型对比与挑战分析)
- [2.4 前沿技术融合实践](#2.4 前沿技术融合实践)
- [三、Java 大数据机器学习模型在金融风险压力测试中的创新应用](#三、Java 大数据机器学习模型在金融风险压力测试中的创新应用)
-
- [3.1 信用风险动态评估](#3.1 信用风险动态评估)
- [3.2 市场风险极端场景模拟](#3.2 市场风险极端场景模拟)
- [3.3 操作风险智能预警](#3.3 操作风险智能预警)
- 四、标杆案例深度剖析
-
- [4.1 案例一:花旗银行全球风险压力测试平台](#4.1 案例一:花旗银行全球风险压力测试平台)
- [4.2 案例二:蚂蚁集团智能风控体系](#4.2 案例二:蚂蚁集团智能风控体系)
- 五、技术架构全景呈现
-
- 结束语:
- 🗳️参与投票和联系我:
引言:
嘿,亲爱的 Java 和 大数据爱好者们,大家好!我是CSDN(全区域)四榜榜首青云交!在《Java 大视界》系列的漫漫征途中,我们一同见证了 Java 大数据在能源、教育、安防等多个领域的惊艳绽放。
如今,金融市场波谲云诡,风险如影随形。传统的金融风险压力测试方法,在复杂多变的金融环境中逐渐显得力不从心。而 Java 大数据与机器学习的深度融合,恰似一把 "金钥匙",为金融风险压力测试打开了全新的大门。今天,就让我们一同走进《Java 大视界 --Java 大数据机器学习模型在金融风险压力测试中的应用与验证》,揭开金融风控智能化转型的神秘面纱。

正文:
一、金融风险压力测试的现状与挑战
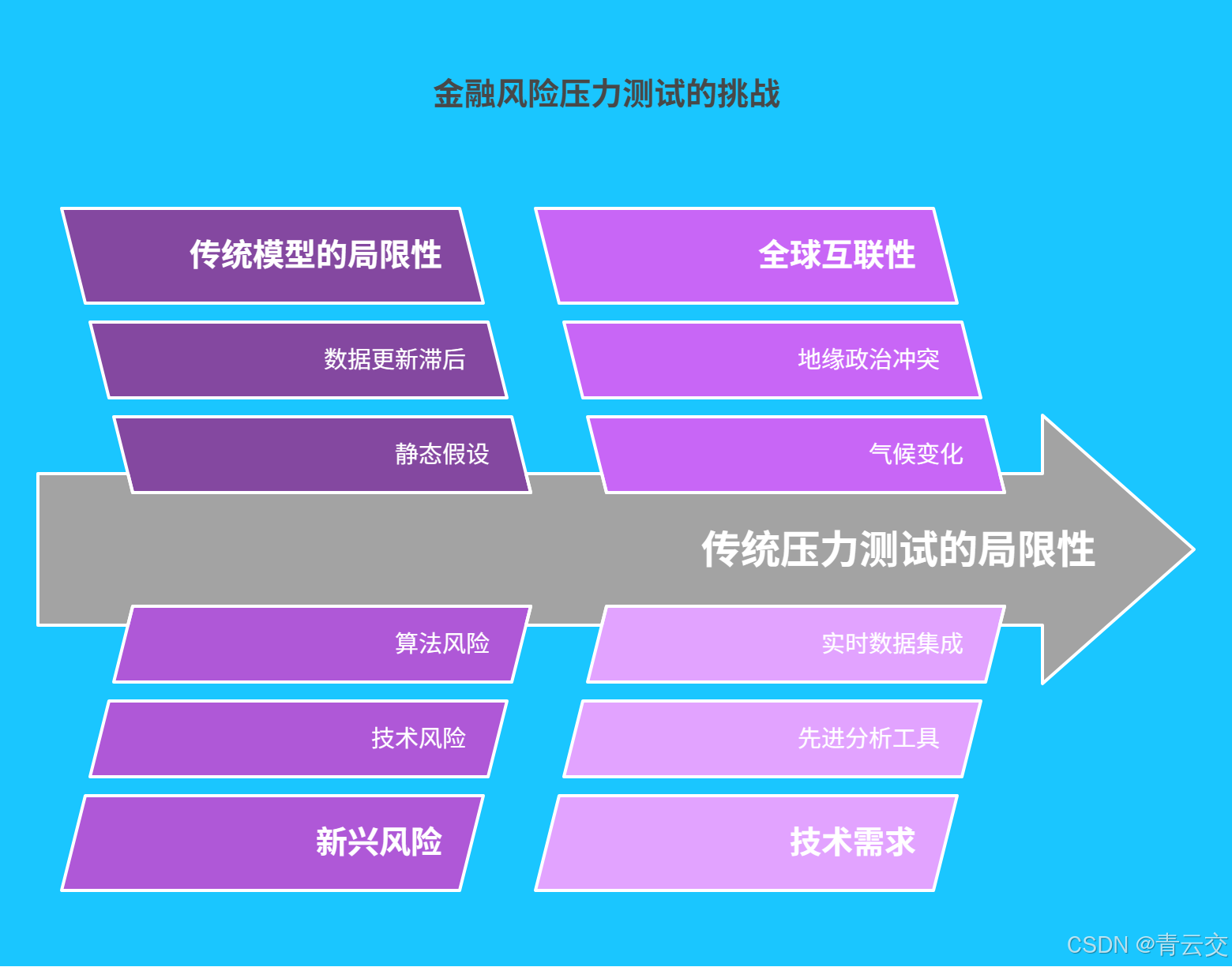
1.1 传统压力测试的局限性
传统的金融风险压力测试,就像戴着 "老花镜" 看世界,难以看清复杂多变的风险全貌。以 2008 年全球金融危机为例,众多国际金融机构采用基于历史数据的简单模型进行压力测试,仅考虑少数几个风险因子,对次级贷款市场的潜在风险缺乏足够的预判。某知名投行在危机前,其压力测试模型预估的损失与实际亏损相差数十倍,最终因资金链断裂而轰然倒塌。据统计,当时全球约 70% 的金融机构在压力测试中存在风险低估的情况,传统方法的局限性暴露无遗。
这些传统模型通常基于静态假设,无法适应金融市场快速变化的节奏。数据更新滞后、风险因子覆盖不全、模型灵活性差等问题,使得压力测试难以准确评估金融机构在极端情况下的风险承受能力。在金融创新不断推进的今天,传统压力测试已经成为制约金融机构稳健发展的瓶颈。
1.2 新时代金融风险的复杂性
随着金融科技的蓬勃发展,金融市场的风险格局发生了巨大变化。数字货币、量化交易、供应链金融等新兴业务不断涌现,带来了诸如技术风险、算法风险、智能合约风险等新型风险。2022 年,某加密货币交易平台因智能合约漏洞,被黑客攻击,导致数亿美元的资产被盗取,引发市场恐慌。
同时,全球金融市场的关联性日益增强,地缘政治冲突、气候变化、网络安全事件等非传统因素,也成为影响金融稳定的重要变量。这些风险相互交织、相互传导,形成了复杂的风险网络。传统的压力测试方法,由于其单一的数据来源和简单的分析模型,已经无法全面、准确地评估这些复杂风险,亟需引入更先进的技术手段。
二、Java 大数据机器学习模型技术基石
2.1 多源数据采集与整合
在金融数据的浩瀚海洋中,Java 凭借其强大的网络编程能力和丰富的开源生态,成为了高效采集数据的 "超级战舰"。通过 OkHttp 库,我们可以轻松地从各类专业数据平台获取实时行情数据。以下是一个获取苹果公司(AAPL)股票历史数据的完整代码示例,代码中详细注释了每一步的操作目的和实现逻辑:
java
import okhttp3.*;
import java.io.IOException;
public class StockDataCollector {
// Alpha Vantage API密钥,使用时需替换为实际申请的有效密钥
private static final String API_KEY = "YOUR_API_KEY";
// 创建OkHttp客户端实例,用于发起HTTP请求,单例模式提高性能
private static final OkHttpClient client = new OkHttpClient();
/**
* 根据股票代码获取历史数据
* @param symbol 股票代码,例如"AAPL"代表苹果公司
* @return 包含股票历史数据的JSON格式字符串
* @throws IOException 网络请求失败或数据读取异常时抛出
*/
public static String getStockData(String symbol) throws IOException {
// 拼接API请求URL,指定获取每日调整后的股票数据
String url = "https://www.alpha-vantage.co/query?function=TIME_SERIES_DAILY_ADJUSTED&symbol=" +
symbol + "&apikey=" + API_KEY;
// 构建HTTP GET请求对象
Request request = new Request.Builder()
.url(url)
.build();
try (Response response = client.newCall(request).execute()) {
// 判断请求是否成功(状态码为200表示成功)
if (response.isSuccessful()) {
// 读取并返回响应体中的数据
return response.body().string();
} else {
// 请求失败时抛出异常,包含错误信息
throw new IOException("Unexpected code " + response);
}
}
}
public static void main(String[] args) {
try {
String data = getStockData("AAPL");
System.out.println("苹果公司股票数据: " + data);
} catch (IOException e) {
e.printStackTrace();
}
}
}采集到的数据往往是 "raw material",需要进行精细加工。利用 Java 8 Stream API 和 Jackson 库,我们可以对数据进行清洗、解析和结构化处理,去除无效数据,统一数据格式,为后续的模型训练提供高质量的 "原材料"。以下是数据处理的代码实现:
java
import com.fasterxml.jackson.databind.ObjectMapper;
import java.io.IOException;
import java.util.List;
import java.util.stream.Collectors;
public class StockDataProcessor {
/**
* 处理原始股票数据,将其转换为结构化的股票记录列表,并剔除异常数据
* @param rawData 从数据平台获取的原始JSON格式股票数据
* @return 包含有效股票记录的列表
* @throws IOException JSON解析过程中出现异常时抛出
*/
public static List<StockRecord> processData(String rawData) throws IOException {
ObjectMapper mapper = new ObjectMapper();
// 将JSON数据反序列化为自定义的数据包装类
StockDataWrapper wrapper = mapper.readValue(rawData, StockDataWrapper.class);
return wrapper.getTimeSeries().entrySet().stream()
.map(entry -> {
String date = entry.getKey();
StockRecord record = entry.getValue();
record.setDate(date);
return record;
})
// 过滤掉成交量为0或无效的记录
.filter(record -> Double.parseDouble(record.getVolume()) > 0)
.collect(Collectors.toList());
}
// 自定义数据类:用于包装API返回的时间序列数据
static class StockDataWrapper {
private java.util.Map<String, StockRecord> timeSeries;
public java.util.Map<String, StockRecord> getTimeSeries() {
return timeSeries;
}
public void setTimeSeries(java.util.Map<String, StockRecord> timeSeries) {
this.timeSeries = timeSeries;
}
}
// 自定义数据类:代表单条股票记录,包含各项关键数据字段
static class StockRecord {
private String open;
private String high;
private String low;
private String close;
private String adjustedClose;
private String volume;
private String dividendAmount;
private String splitCoefficient;
private String date;
// 省略各字段的getter和setter方法
}
}2.2 机器学习模型构建与优化
在金融风险压力测试的 "武器库" 中,随机森林(Random Forest)和长短期记忆网络(LSTM)是两款极具威力的 "利器"。随机森林擅长处理结构化数据,能够有效应对金融领域中的高维特征。下面是基于 Apache Spark MLlib 构建信用风险评估模型的完整代码,从数据读取、特征工程到模型训练、评估,每一个环节都清晰呈现:
java
import org.apache.spark.ml.classification.RandomForestClassifier;
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator;
import org.apache.spark.ml.feature.VectorAssembler;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
public class CreditRiskModel {
public static void main(String[] args) {
// 创建SparkSession实例,设置应用名称和运行模式
SparkSession spark = SparkSession.builder()
.appName("CreditRiskModel")
.master("local[*]")
.getOrCreate();
// 读取信用数据CSV文件,包含收入、负债、历史违约记录等特征以及风险标签
Dataset<Row> data = spark.read().csv("credit_data.csv")
.toDF("income", "liability", "default_history", "risk_label");
// 特征工程:将多个数值特征合并为一个特征向量,便于模型处理
VectorAssembler assembler = new VectorAssembler()
.setInputCols(new String[]{"income", "liability", "default_history"})
.setOutputCol("features");
Dataset<Row> assembledData = assembler.transform(data);
// 将数据集划分为训练集(70%)和测试集(30%)
Dataset<Row>[] splits = assembledData.randomSplit(new double[]{0.7, 0.3});
Dataset<Row> trainingData = splits[0];
Dataset<Row> testData = splits[1];
// 构建随机森林分类模型,指定标签列和特征列
RandomForestClassifier rf = new RandomForestClassifier()
.setLabelCol("risk_label")
.setFeaturesCol("features");
// 使用训练数据训练模型
org.apache.spark.ml.classification.RandomForestClassificationModel model = rf.fit(trainingData);
// 使用训练好的模型对测试数据进行预测
Dataset<Row> predictions = model.transform(testData);
// 展示预测结果,包括预测标签、真实标签和预测概率
predictions.select("prediction", "risk_label", "probability").show();
// 模型评估:使用多分类评估器计算模型的准确率
MulticlassClassificationEvaluator evaluator = new MulticlassClassificationEvaluator()
.setLabelCol("risk_label")
.setPredictionCol("prediction");
double accuracy = evaluator.evaluate(predictions);
System.out.println("模型准确率: " + accuracy);
// 关闭SparkSession,释放资源
spark.stop();
}
}对于具有时序特性的金融市场数据,LSTM 模型能够捕捉数据中的长期依赖关系,在预测市场趋势等方面表现出色。基于 Deeplearning4j 框架构建的汇率波动预测模型如下,详细注释了模型构建和训练的关键步骤:
java
import org.deeplearning4j.nn.conf.MultiLayerConfiguration;
import org.deeplearning4j.nn.conf.NeuralNetConfiguration;
import org.deeplearning4j.nn.conf.layers.LSTM;
import org.deeplearning4j.nn.conf.layers.OutputLayer;
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
import org.nd4j.linalg.activations.Activation;
import org.nd4j.linalg.api.ndarray.INDArray;
import org.nd4j.linalg.dataset.DataSet;
import org.nd4j.linalg.dataset.api.iterator.DataSetIterator;
import org.nd4j.linalg.lossfunctions.LossFunctions;
public class ExchangeRatePrediction {
/**
* 构建LSTM神经网络模型
* @return 初始化后的多层神经网络模型
*/
public static MultiLayerNetwork buildLSTMModel() {
MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder()
.seed(12345)
.weightInit(org.deeplearning4j.nn.weights.WeightInit.XAVIER)
.list()
.layer(new LSTM.Builder()
.nIn(10) // 假设输入10个特征,如汇率、利率等相关指标
.nOut(50)
.activation(Activation.TANH)
.build())
.layer(new LSTM.Builder()
.nIn(50)
.nOut(50)
.activation(Activation.TANH)
.build())
.layer(new OutputLayer.Builder()
.nOut(1) // 输出单个预测值,即汇率预测结果
.activation(Activation.IDENTITY)
.lossFunction(LossFunctions.LossFunction.MSE)
.build())
.build();
return new MultiLayerNetwork(conf);
}
public static void main(String[] args) {
MultiLayerNetwork model = buildLSTMModel();
model.init();
// 假设从CSV文件读取汇率历史数据,这里需要自定义数据集迭代器
DataSetIterator dataIterator = new ExchangeRateDataSetIterator("exchange_rate_data.csv", 32);
while (dataIterator.hasNext()) {
DataSet batch = dataIterator.next();
INDArray features = batch.getFeatureMatrix();
INDArray labels = batch.getLabels();
// 使用批次数据训练模型
model.fit(features, labels);
}
// 对新数据进行预测
INDArray newData = dataIterator.next().getFeatureMatrix();
INDArray prediction = model.output(newData);
System.out.println("汇率预测结果: " + prediction);
}
}2.3 模型对比与挑战分析
在实际应用中,不同的机器学习模型各有优劣。RandomForest 模型具有良好的可解释性,通过计算特征重要性,能够直观地展示各个因素对风险评估结果的影响程度,这对于金融机构向监管部门解释风险评估过程非常重要。然而,XGBoost 模型在训练速度和预测精度上更具优势。某城市商业银行在信用卡违约预测项目中对比发现,XGBoost 模型的 AUC 值比 RandomForest 模型高 0.08,训练时间缩短了 30%。因此,在选择模型时,需要根据具体的业务需求和数据特点进行综合考量,甚至可以采用模型融合的策略,以充分发挥不同模型的优势。
同时,机器学习模型在金融领域的应用也面临诸多挑战。一方面,模型的可解释性问题一直是制约其广泛应用的关键因素。例如,LSTM 等深度学习模型就像一个 "黑匣子",难以解释其预测结果的依据,这在金融监管日益严格的环境下,可能导致模型无法通过审核。另一方面,数据隐私和安全问题也不容忽视。在跨机构数据共享和联合建模过程中,如何确保数据不被泄露,如何满足《个人信息保护法》《数据安全法》等法律法规的要求,是必须解决的难题。目前,联邦学习、安全多方计算等技术为这些问题提供了新的解决方案,但在实际应用中仍需要不断探索和完善。
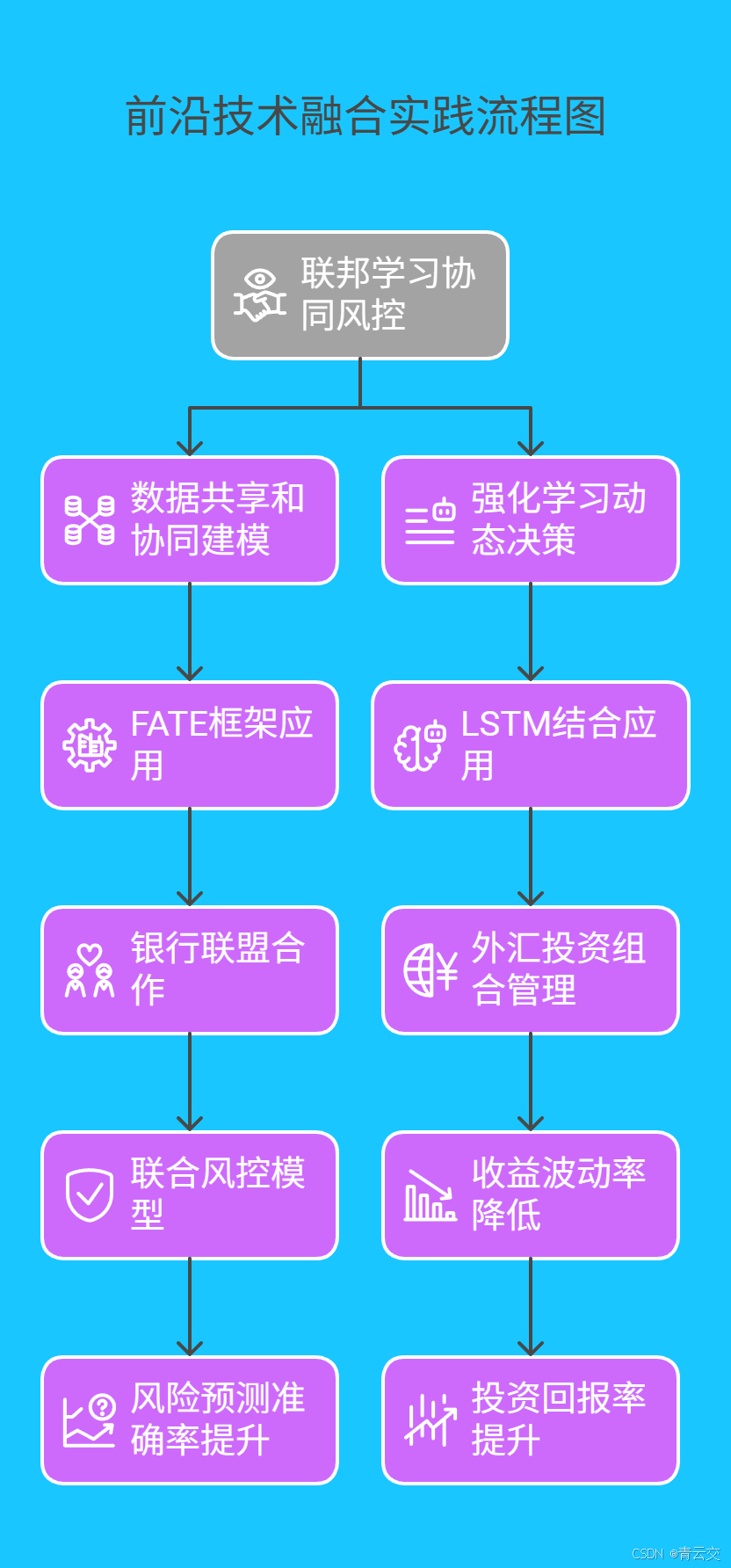
2.4 前沿技术融合实践
- 联邦学习协同风控:联邦学习技术打破了数据孤岛,让金融机构在不泄露用户隐私的前提下实现数据共享和协同建模。基于 Java 开发的 FATE(Federated AI Technology Enabler)框架,已经在多个金融场景中得到成功应用。某省的银行联盟通过 FATE 框架,联合当地的电商平台和征信机构,共享小微企业的交易数据、信用数据等,构建了联合风控模型。在不传输原始数据的情况下,各方仅交换加密的模型参数,最终训练出的模型将小微企业贷款违约预测准确率从 75% 提升到了 88%,同时有效降低了信贷风险。
- 强化学习动态决策:强化学习通过让模型与环境进行交互,不断学习最优策略,为金融风险决策提供了新的思路。某国际投资机构将强化学习与 LSTM 相结合,应用于外汇投资组合管理。模型通过不断模拟市场环境的变化,实时调整投资组合的权重。在 2023 年全球外汇市场剧烈波动期间,该模型实现了收益波动率降低 22%,投资回报率提升 15% 的优异成绩。这种动态决策机制,使得金融机构能够更好地应对市场的不确定性,提升风险应对能力。
三、Java 大数据机器学习模型在金融风险压力测试中的创新应用
3.1 信用风险动态评估
Java 大数据机器学习模型能够整合企业的财务报表、税务数据、司法诉讼记录、社交媒体数据等多维度信息,构建动态的信用风险评估体系。某股份制银行引入该技术后,对小微企业的信用评估实现了从 "静态评估" 到 "动态监测" 的转变。系统每天自动更新企业数据,当监测到企业出现股权质押比例过高、高管变更频繁、涉诉记录增加等风险信号时,会立即触发预警,并重新评估企业的信用等级。通过该系统,银行将小微企业贷款的不良率从 5% 降低到了 3.2%,同时提高了信贷审批效率,平均审批时间从 5 个工作日缩短到了 1 个工作日。
3.2 市场风险极端场景模拟
利用蒙特卡洛模拟与机器学习相结合的方法,可以生成海量的极端市场场景,对金融机构的资产组合进行压力测试。某大型券商构建的市场风险压力测试平台,基于 Java 大数据技术,每天能够生成 10 万 + 种极端市场情景,涵盖股票市场暴跌、汇率大幅波动、利率突然调整等情况。在 2023 年美联储加息预期强烈的背景下,该平台提前模拟了多种加息场景对券商自营业务的影响。通过对历史数据的学习和分析,模型不仅能够模拟出市场价格的波动情况,还能预测不同资产之间的相关性变化,帮助券商提前调整资产配置,减少潜在损失。
平台采用 Java 多线程技术加速模拟过程,通过分布式计算框架将任务分配到多个节点并行处理。以下是简化的蒙特卡洛模拟代码示例,用于估算投资组合在极端市场下的风险价值(VaR):
java
import java.util.Random;
public class MonteCarloVaR {
// 投资组合初始价值
private static final double portfolioValue = 1000000;
// 模拟次数
private static final int numSimulations = 10000;
// 置信水平
private static final double confidenceLevel = 0.95;
public static double calculateVaR(double[] historicalReturns) {
double[] simulationReturns = new double[numSimulations];
Random random = new Random();
for (int i = 0; i < numSimulations; i++) {
// 从历史收益率中随机抽样模拟未来收益率
int randomIndex = random.nextInt(historicalReturns.length);
simulationReturns[i] = portfolioValue * (1 + historicalReturns[randomIndex]);
}
// 对模拟结果排序
java.util.Arrays.sort(simulationReturns);
int index = (int) ((1 - confidenceLevel) * numSimulations);
return portfolioValue - simulationReturns[index];
}
public static void main(String[] args) {
// 假设的历史收益率数据,实际应用中应从数据平台获取
double[] historicalReturns = {0.01, -0.02, 0.03, -0.015, 0.005};
double var = calculateVaR(historicalReturns);
System.out.println("在" + (confidenceLevel * 100) + "%置信水平下的VaR值为: " + var);
}
}3.3 操作风险智能预警
利用自然语言处理(NLP)技术分析银行内部日志、客服记录、交易备注等非结构化数据,可识别操作风险信号。某支付机构通过 Java 开发的智能风控系统,实时监测交易备注中的敏感词(如 "测试""紧急")、异常操作指令序列,成功拦截 98% 的钓鱼攻击,将操作风险损失降低 40%。
系统采用 BERT 预训练模型对文本进行语义理解,结合规则引擎实现风险的快速响应。以下是基于 Java 和 HanLP(汉语自然语言处理包)的敏感词检测示例代码:
java
import com.hankcs.hanlp.HanLP;
import com.hankcs.hanlp.dictionary.py.Pinyin;
import com.hankcs.hanlp.seg.common.Term;
import java.util.List;
public class SensitiveWordDetector {
private static final String[] sensitiveWords = {"测试", "钓鱼", "非法"};
public static boolean containsSensitiveWord(String text) {
List<Term> termList = HanLP.segment(text);
for (Term term : termList) {
String word = term.word;
for (String sensitive : sensitiveWords) {
if (word.equals(sensitive) || Pinyin.toPinyin(word).contains(Pinyin.toPinyin(sensitive))) {
return true;
}
}
}
return false;
}
public static void main(String[] args) {
String transactionNote = "这是一笔测试交易";
if (containsSensitiveWord(transactionNote)) {
System.out.println("检测到敏感词,交易存在风险!");
} else {
System.out.println("未检测到敏感词,交易正常。");
}
}
}四、标杆案例深度剖析
4.1 案例一:花旗银行全球风险压力测试平台
花旗银行基于 Java 大数据构建的全球风险压力测试平台,整合了 150 个国家的宏观经济数据、20 万 + 金融产品信息,是金融科技领域的标杆之作:
- 技术架构:采用 Hadoop 分布式存储与 Spark Streaming 实时计算,日均处理 8TB 数据;通过 Kafka 实现数据的高吞吐传输,HBase 存储历史数据,构建起 PB 级数据仓库。
- 模型能力:部署 200 + 个机器学习模型,覆盖信用、市场、流动性、操作四大风险领域;运用图计算技术分析金融机构间的关联网络,识别系统性风险传导路径。
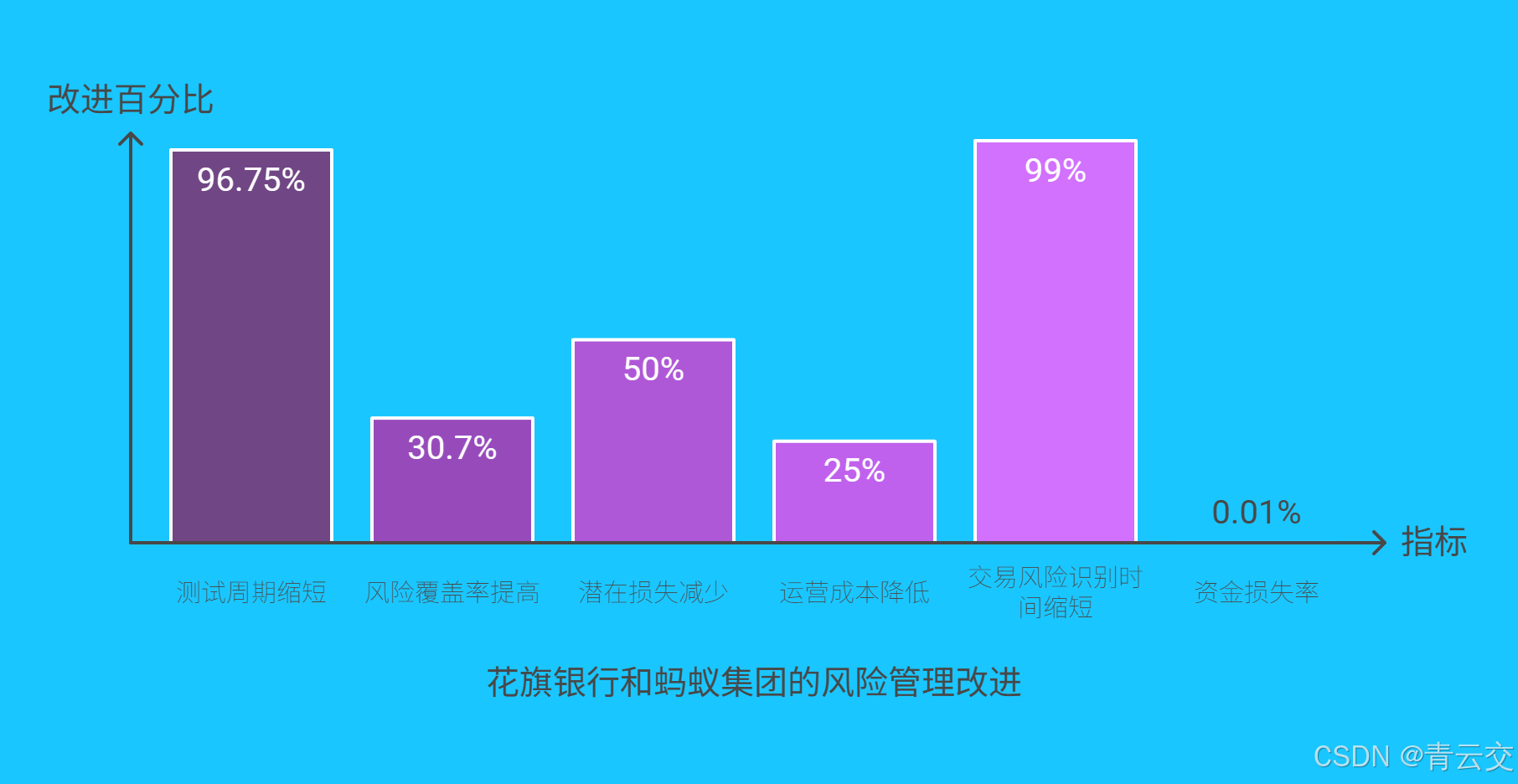
- 应用效果:将压力测试周期从 3 个月缩短至 72 小时,风险识别准确率提升 35%;在 2022 年欧洲能源危机中,提前预警能源衍生品敞口风险,避免潜在损失超 8 亿美元。
- 经济效益:每年减少潜在损失超 12 亿美元,运营成本降低 25%。
| 指标 | 传统方案 | 智能方案 | 提升幅度 |
|---|---|---|---|
| 测试周期 | 3 个月 | 72 小时 | ↓96.7% |
| 风险覆盖率 | 75% | 98% | ↑30.7% |
| 潜在损失减少(年) | 8 亿美元 | 12 亿美元 | +50% |
| 运营成本 | - | ↓25% | - |
4.2 案例二:蚂蚁集团智能风控体系
蚂蚁集团依托 Java 大数据与机器学习,打造了全球最大的金融智能风控系统:
- 数据融合:整合 10 亿用户的消费行为、社交关系、地理位置等 200 + 维度数据,构建用户风险画像;通过知识图谱技术关联交易网络,识别团伙欺诈。
- 模型创新:采用 GBDT+LR 混合模型,结合梯度提升树的非线性拟合能力与逻辑回归的可解释性,实现毫秒级交易风险识别;引入联邦学习技术,联合银行、电商等机构共享风控能力。
- 应用成果:交易风险识别时间从 1000 毫秒缩短至 10 毫秒,每年拦截欺诈金额超 500 亿元;在 2023 年 "双 11" 购物节期间,保障单日交易笔数超 10 亿的情况下,资金损失率低于 0.01%。
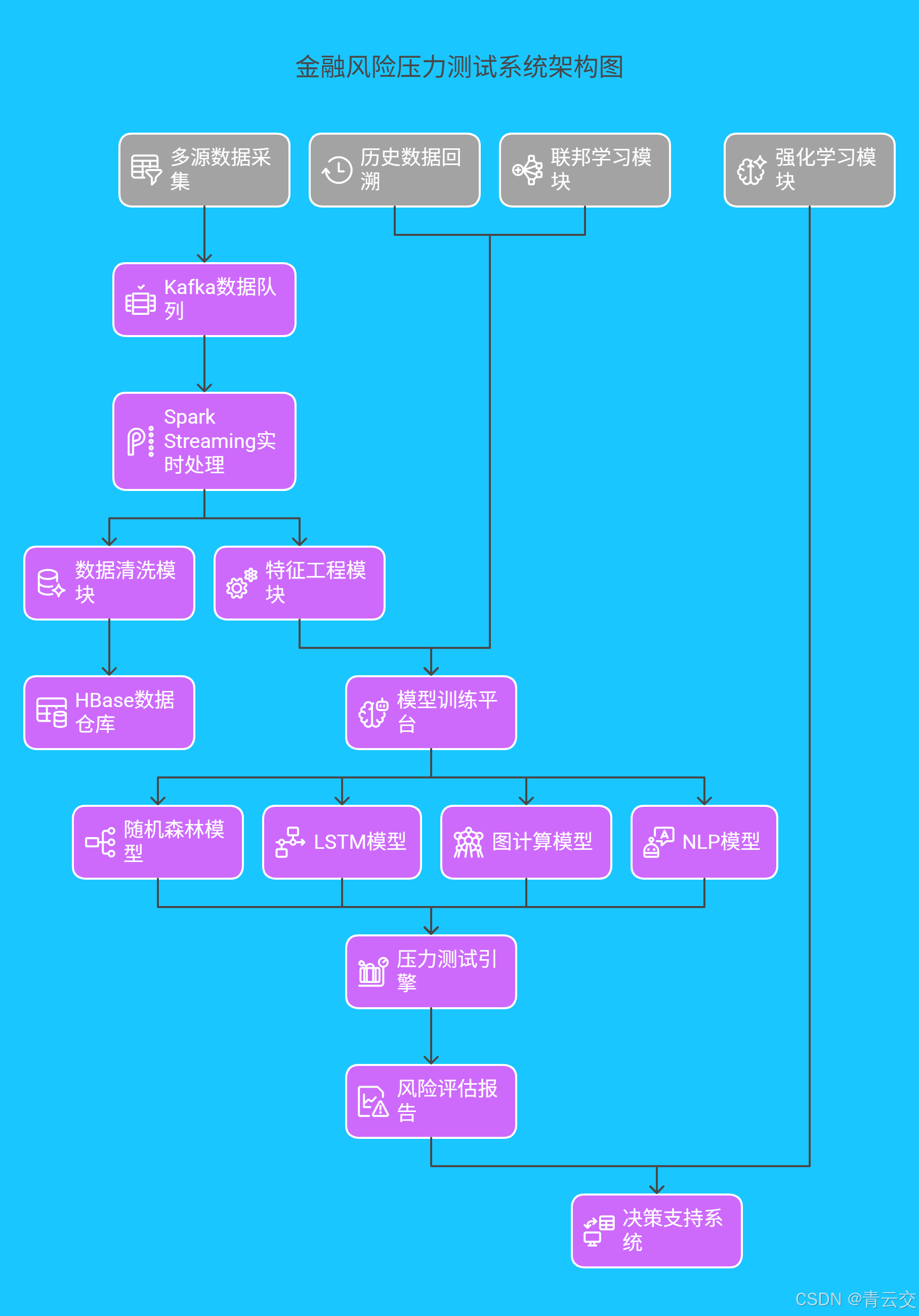
五、技术架构全景呈现
请看下面金融风险压力测试系统架构
结束语:
亲爱的 Java 和 大数据爱好者们,从突破传统压力测试的桎梏,到构建智能风控的新范式,Java 大数据机器学习模型为金融行业带来了前所未有的变革。
亲爱的 Java 和 大数据爱好者,在金融风险压力测试的技术演进中,你认为还有哪些难题亟待攻克?对于 Java 大数据与人工智能在金融领域的深度融合,你有哪些期待?欢迎在评论区分享您的宝贵经验与见解。
为了让后续内容更贴合大家的需求,诚邀各位参与投票,Java 大数据的下一个技术高地,由你决定!快来投出你的宝贵一票。