9.逻辑回归
(1)应用场景
广告点击率 是否会被点击
是否为垃圾邮件
是否患病
是否为金融诈骗
是否为虚假账号
(2)逻辑回归的原理
1.输入
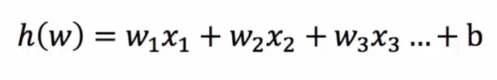
逻辑回归的输入就是一个线性回归的结果
2.激活函数
sigmold函数 0,1
1/(1+e^(-x))
假设函数/线性模型
1/(1+e^(-(w1x1+w2x2+w3x3+...+wnxn+b)))
损失函数
(y_predict - y_true)平方和/总数
逻辑回归的真实值/预测值 是否属于某个类别
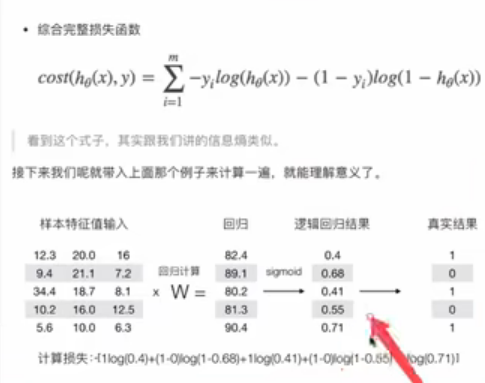
对数似然损失

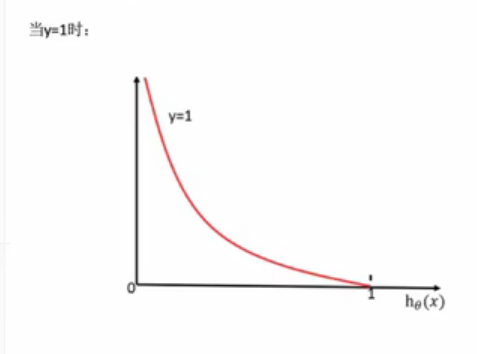
y=1 真实值属于这个类别 y=0 真实值不属于这个类别
计算损失:其中x为逻辑回归结果,y为真实结果
log(P),P值越大,结果越小
优化损失
梯度下降
(3)逻辑回归API

案例:癌症分类预测-良/恶性乳腺癌预测
流程分析:
python
import pandas as pd
import numpy as np1)获取数据
读取的时候加上names
python
#1.读取数据
path = "网址"
column_name = [数据列名称]
data = pd.read_csv(patn,names=column_name)2)数据处理
处理缺失值
python
#2.缺失值处理
# 1)替换-)np.nan
data = data.replace(to_replace="7",value=np.nan)
# 2)删除缺失样本
data.dropna(inplace=True)3)数据集划分
python
# 3.划分数据集
from sklearn.model_selection import train_test_split
# 筛选特征值和目标值
x = data.iloc[:,1:-1]
y = data["Class"]
python
x_train,x_test,y_train,y_test = train_test_aplit(x,y)4)特征工程:
无量纲化处理-标准化
python
#4.标准化
from sklearn.preprocessing import StandardScaler5)逻辑回归预估器
python
from sklearn.linear_model import LogisticRegression
python
eatimator = LogisticRegression()
estimator.fit(x_train,y_train)
python
#逻辑回归的模型参数:回归系数和偏执
estimator.coef_
estimator.intercept_6)模型评估
python
# 模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n",y_predict)
print("直接比对真实值和预测值:\n",y_test = y_predict)
#方法2:计算准确率
score = estimator.score(x_test,y_test)
print("准确率为:\n",score)10.分类的评估方法
(1)精确率与召回率
1 混淆矩阵
TP = True Possitive
FN = False Negative
2 精确率(Precision)与召回率(Recall)
精确率:预测结果为正例样本中真实为正例的比例
召回率:真实为正例的样本中预测结果为正例的比例 查的全不全
F1-score 模型的稳健性
python
# 查看精确率,召回率,F1-score
from sklearn.metrics import classification_report
python
report = classification_report(y_test,y_predict,label=[2,4],target_names=["良性","恶性")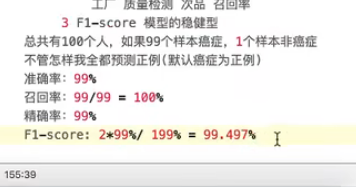

(2)ROC曲线与AUC指标
AUC=1,完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。
0.5<AUC<1,优于随机猜测。这个分类(模型)妥善设定阈值的话,能有预测价值。
1.TPR与FPR
TPR = TP/(TP+FN)
所有真实类别为1的样本中,预测类别为1的比例
FPR = FP/(FP+TN)
所有真实类别为0的样本中,预类别为1的比例

将y_true中的样本都为0,1
python
#y_true:每个样本的真实类别,必须为0(反例),1(正例)标记
#将y_test 转换为 0 1
y_true = np.where(y_test > 3,1,0)
python
from sklearn.metrics import roc_auc_acore
python
roc_auc_score(y_true,y_predict)总共有100人,如果99个样本癌症,1个样本非癌症
AUC:0.5
TPR = 100%
FPR = 1/1 = 100%
(3)模型保存和加载
python
import joblib
#保存模型
joblib.dump(estimator,"my_ridge.pkl")
#加载模型
estimator = joblib.load("my_ridge.pkl")(4)无监督学习KMeans
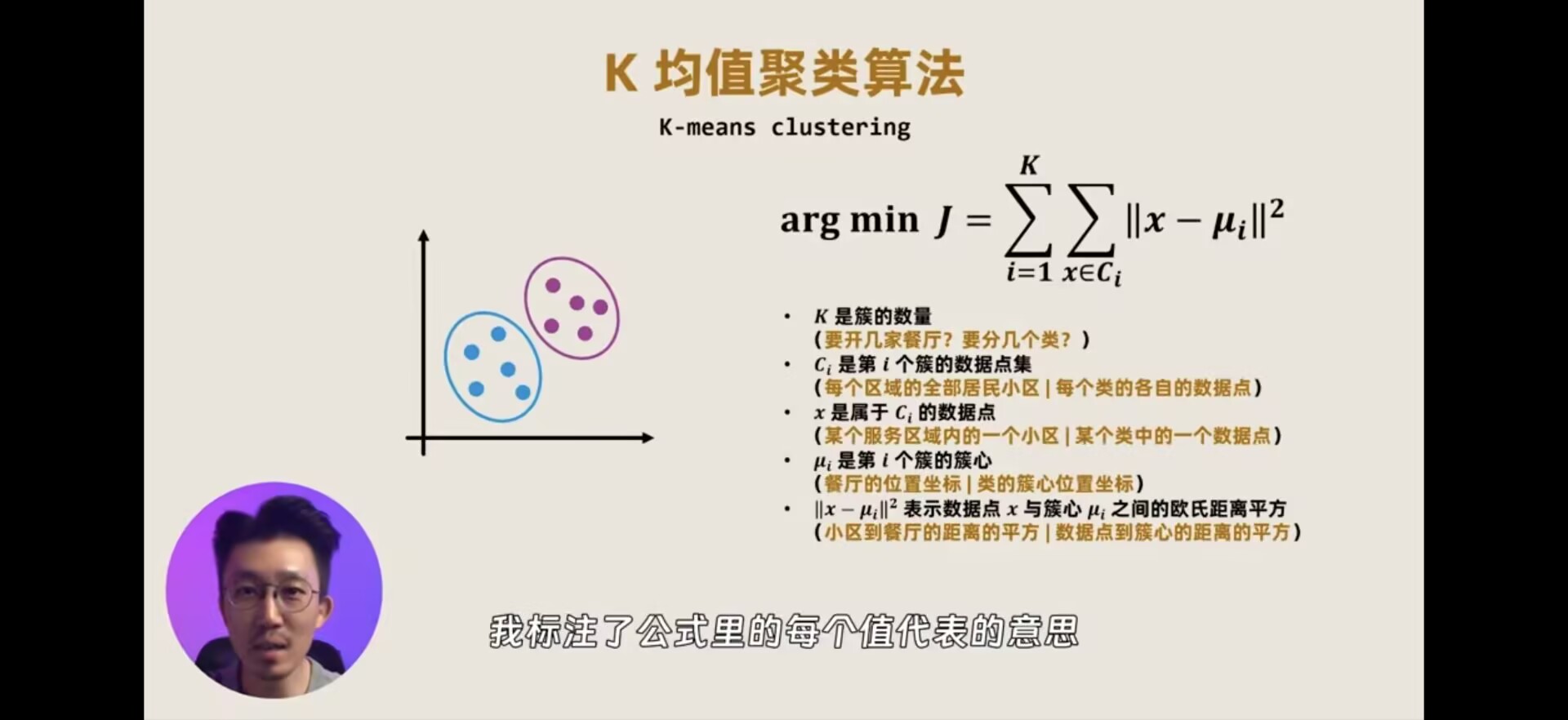
K 均值聚类算法
例:找到最佳的餐厅位置
方法:分别以两家餐厅为中心,让两家的餐厅的服务范围去覆盖周围最近的小区居民
每家餐厅服务的小区范围叫做簇;你的两家餐厅的位置叫做簇心
然后把所有小区的坐标点,放在坐标系中,利用K 均值聚类算法,解决此问题
step1:任意选K个点作为簇心
step2:计算所有点,到两个簇心的距离,比如使用欧氏距离进行计算
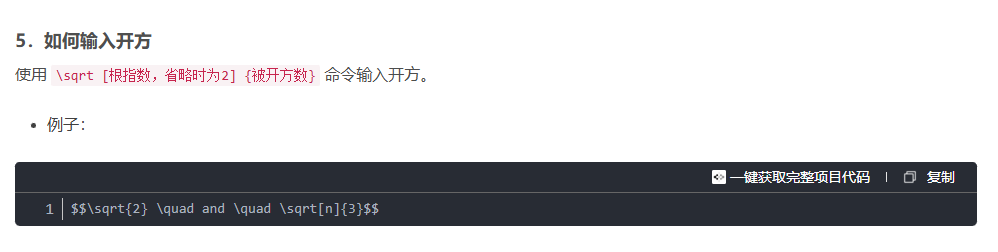
d = ^(1/2)|x1-x2|^2+|y1-y2|^2
step3:根据计算的距离选择最近的簇心,进行划分分类的归属
step4:计算分类内,所有点的平均坐标点 ,作为新的簇心
重复2,3,4步骤 直到:1.簇心点的坐标不再更新或2.设定的迭代次数全部跑完即可终止