
目录
[1. 前言](#1. 前言)
[2. 正文](#2. 正文)
[2.1 开发场景](#2.1 开发场景)
[2.2 解决方案](#2.2 解决方案)
[2.2.1 先从Redis中获取全量城市列表 (基础数据获取)](#2.2.1 先从Redis中获取全量城市列表 (基础数据获取))
[2.2.2 过滤器的基础实现 (问题暴露)](#2.2.2 过滤器的基础实现 (问题暴露))
[2.2.3 引入设计模式的过滤优化](#2.2.3 引入设计模式的过滤优化)
[2.2.3.1 引入策略模式 (Strategy Pattern)](#2.2.3.1 引入策略模式 (Strategy Pattern))
[2.2.3.2 引入工厂模式 (Factory Pattern) - 简化策略获取](#2.2.3.2 引入工厂模式 (Factory Pattern) - 简化策略获取)
[2.2.3.3 引入单例模式 (Singleton Pattern) - 策略复用](#2.2.3.3 引入单例模式 (Singleton Pattern) - 策略复用)
[2.3 最终实现](#2.3 最终实现)
[3. 小结](#3. 小结)
摘要: 在房源搜索这类需要处理大量数据并根据多种条件进行动态过滤和排序的场景中,直接使用Stream API配合if-else虽然能快速实现功能,但会带来代码臃肿、难以维护、扩展困难等问题。本文将结合一个真实的房源搜索系统案例,详细讲解如何利用 策略模式 (Strategy Pattern) 和 工厂模式 (Factory Pattern) 对过滤和排序逻辑进行优雅重构,显著提升代码的可读性、可维护性和扩展性。我们还会探讨如何利用Spring容器简化工厂实现,并分析基础实现与优化后方案的优劣对比。
1. 前言
各位Java开发者朋友,大家好!相信大家在开发后台系统时,经常会遇到类似"列表筛选"的需求,尤其是在电商、租房、招聘等涉及大量条目展示和复杂搜索条件的场景。今天,我们就以一个典型的"房源搜索系统 "为例,聚焦其核心功能之一:从缓存中获取全量房源列表,再根据用户选择的条件(区域、租金范围、居室、类型等)进行动态过滤和排序,最后分页返回结果。
在项目初期,为了快速上线,我们可能会采用最直接的方式------使用Java 8的Stream API配合一连串的if-else语句来实现过滤和排序逻辑(如代码片段 filterHouseV1 所示)。这种方式虽然"能用",但随着业务发展,条件增加,代码会迅速变得臃肿不堪,宛如一锅"意大利面条",维护起来苦不堪言,添加新条件或修改排序规则更是小心翼翼,生怕牵一发而动全身。
本文将带大家亲历一次代码重构之旅,看看如何运用 策略模式 和 工厂模式 这两把利器,将混乱的过滤排序逻辑梳理得井井有条,让代码焕发新生。
插播一条消息~
🔍十年经验淬炼 · 系统化AI学习平台推荐
系统化学习AI平台![]() https://www.captainbed.cn/scy/
https://www.captainbed.cn/scy/
- 📚 **完整知识体系:**从数学基础 → 工业级项目(人脸识别/自动驾驶/GANs),内容由浅入深
- 💻 **实战为王:**每小节配套可运行代码案例(提供完整源码)
- 🎯**零基础友好:**用生活案例讲解算法,无需担心数学/编程基础
🚀 特别适合
- 想系统补强AI知识的开发者
- 转型人工智能领域的从业者
- 需要项目经验的学生
2. 正文
2.1 开发场景
假设我们开发的是一个租房平台。用户在搜索房源时,可以选择:
- 城市 (City): 必选。
- 区域 (Region): 城市下的行政区域。
- 租金范围 (Rental Ranges) : 如
0-1000,1000-1500等预定义的区间。 - 居室数 (Rooms): 一居、二居、三居等。
- 租赁类型 (Rent Types): 整租、合租。
- 排序方式 (Sort): 距离最近、价格升序、价格降序等。
- 分页参数: 页码、每页数量。
为了性能考虑,我们将全量城市下的房源ID列表 存储在 Redis 中(使用List或Set结构,键如 city:house:1 代表城市ID为1的房源ID列表)。当用户选择某个城市进行搜索时:
- Step 1 : 根据城市ID从Redis获取该城市下的所有房源ID列表 (
getCacheCityHouses)。 - Step 2 : 根据这些房源ID,从数据库或缓存中批量查询出具体的房源详细信息 (
HouseDTO) (getCacheHouseListByCity中的detail方法,实际可能走缓存或DB)。 - Step 3 : 对获取到的全量
HouseDTO列表,根据用户传入的SearchHouseListReqDTO对象中的各种条件进行 过滤。 - Step 4 : 对过滤后的列表,根据用户选择的排序规则进行 排序。
- Step 5 : 对排序后的列表进行 分页 处理,返回当前页的数据及分页信息 (
BasePageDTO<HouseDTO>)。
我们的优化重点在于 Step 3 (过滤) 和 Step 4 (排序) 的逻辑实现。
2.2 解决方案
2.2.1 先从Redis中获取全量城市列表 (基础数据获取)
这部分是数据准备阶段,逻辑相对清晰。核心方法如下:
java
/**
* 根据城市ID从Redis获取该城市下的房源ID列表
* @param cityId 城市ID
* @return 房源ID列表 (可能为空)
*/
private List<Long> getCacheCityHouses(Long cityId) {
if (null == cityId) {
return Collections.emptyList(); // 更推荐空集合
}
List<Long> houseIds = Collections.emptyList(); // 初始化空
String cacheKey = CITY_HOUSE_PREFIX + cityId;
try {
houseIds = redisService.getCacheList(cacheKey, Long.class); // 假设redisService已封装好
} catch (Exception e) {
log.error("从缓存中获取城市下的房源列表异常,key: {}", cacheKey, e);
// 实际项目中,可能需要考虑降级(如查DB),这里仅记录日志
}
return houseIds;
}
/**
* 根据城市ID获取该城市下的房源详细信息列表 (依赖上一步的ID列表)
* @param cityId 城市ID
* @return 房源详细信息DTO列表
*/
private List<HouseDTO> getCacheHouseListByCity(Long cityId) {
if (null == cityId) {
return Collections.emptyList();
}
// 1. 从缓存获取房源ID列表
List<Long> houseIds = getCacheCityHouses(cityId);
if (houseIds.isEmpty()) {
return Collections.emptyList();
}
// 2. 去重 (如果Redis List允许重复,或为了安全)
Set<Long> uniqueHouseIds = new HashSet<>(houseIds);
// 3. 批量获取房源详情 (假设detail(Long id)方法负责获取单个房源详情,可能来自缓存或DB)
List<HouseDTO> resultList = new ArrayList<>(uniqueHouseIds.size());
for (Long houseId : uniqueHouseIds) {
HouseDTO detail = detail(houseId); // 关键:获取详情
if (detail != null) {
resultList.add(detail);
}
}
return resultList;
}- 说明 :
getCacheCityHouses负责从Redis读取基础ID列表。getCacheHouseListByCity利用ID列表获取详细的房源对象。这里使用了Set去重,避免潜在的数据问题。 - 注意 :
detail(houseId)方法的实现是关键,它决定了房源详细信息的来源(可能是二级缓存、数据库查询等),需要保证效率。
2.2.2 过滤器的基础实现 (问题暴露)
拿到全量 HouseDTO 列表后,我们需要根据请求参数 SearchHouseListReqDTO 进行过滤和排序。最直观的实现方式就是 filterHouseV1:
java
private BasePageDTO<HouseDTO> filterHouseV1(List<HouseDTO> houseDTOList, SearchHouseListReqDTO reqDTO) {
// ===== 1. 条件过滤 (多个if + Stream.filter) =====
// 区域筛选
if (null != reqDTO.getRegionId()) {
houseDTOList = houseDTOList.stream()
.filter(house -> house.getRegionId().equals(reqDTO.getRegionId()))
.collect(Collectors.toList());
}
// 租赁类型筛选
if (!CollectionUtils.isEmpty(reqDTO.getRentTypes())) {
houseDTOList = houseDTOList.stream()
.filter(house -> reqDTO.getRentTypes().contains(house.getRentType()))
.collect(Collectors.toList());
}
// 居室数筛选
if (!CollectionUtils.isEmpty(reqDTO.getRooms())) {
houseDTOList = houseDTOList.stream()
.filter(house -> reqDTO.getRooms().contains(house.getRooms()))
.collect(Collectors.toList());
}
// 租金范围筛选 (内部有复杂逻辑)
if (!CollectionUtils.isEmpty(reqDTO.getRentalRanges())) {
houseDTOList = houseDTOList.stream()
.filter(house -> filterHouseByRentalRanges(house.getPrice(), reqDTO.getRentalRanges()))
.collect(Collectors.toList());
}
// 状态筛选 (只展示上架的)
houseDTOList = houseDTOList.stream()
.filter(house -> HouseStatusEnum.UP.name().equalsIgnoreCase(house.getStatus()))
.collect(Collectors.toList());
// ===== 2. 排序 (大的if-else + Stream.sorted) =====
if (StringUtils.isNotEmpty(reqDTO.getSort())) {
if (reqDTO.getSort().equalsIgnoreCase(HouseSortEnum.DISTANCE.name())) {
houseDTOList = houseDTOList.stream()
.sorted(Comparator.comparingDouble(
house -> house.calculateDistance(reqDTO.getLongitude(), reqDTO.getLatitude())
)).collect(Collectors.toList());
} else if (reqDTO.getSort().equalsIgnoreCase(HouseSortEnum.PRICE_ASC.name())) {
houseDTOList = houseDTOList.stream()
.sorted(Comparator.comparingDouble(HouseDTO::getPrice))
.collect(Collectors.toList());
} else if (reqDTO.getSort().equalsIgnoreCase(HouseSortEnum.PRICE_DESC.name())) {
houseDTOList = houseDTOList.stream()
.sorted(Comparator.comparingDouble(HouseDTO::getPrice).reversed())
.collect(Collectors.toList());
} else { // 默认按距离排序
log.warn("不支持的排序规则: {}, 将按默认(距离)排序", reqDTO.getSort());
houseDTOList = houseDTOList.stream()
.sorted(Comparator.comparingDouble(
house -> house.calculateDistance(reqDTO.getLongitude(), reqDTO.getLatitude())
)).collect(Collectors.toList());
}
} // 如果sort为空,则不排序?这里可能需要定义默认行为
// ===== 3. 分页处理 =====
int totalCount = houseDTOList.size();
int totalPages = BasePageDTO.calculateTotalPages(totalCount, reqDTO.getPageSize());
List<HouseDTO> pageList = houseDTOList.stream()
.skip(reqDTO.getOffset()) // 通常 offset = (page - 1) * pageSize
.limit(reqDTO.getPageSize())
.collect(Collectors.toList());
// ===== 4. 组装结果 =====
BasePageDTO<HouseDTO> pageDTO = new BasePageDTO<>();
pageDTO.setTotals(totalCount);
pageDTO.setTotalPages(totalPages);
pageDTO.setList(pageList);
return pageDTO;
}
// 辅助方法:根据租金范围字符串判断价格是否在范围内
private boolean filterHouseByRentalRanges(Double price, List<String> rentalRanges) {
// ... 实现逻辑与后面 RentalRangesFilter 中的方法相同 ...
}filterHouseV1的问题分析:
|-----------|---------------------------------|
| 问题维度 | 描述 |
| 🚫 可读性差 | 一屏代码塞满业务逻辑,新成员难以理解 |
| 🧱 扩展困难 | 新加一个"是否带电梯"筛选?改原方法+加if判断,违反开闭原则 |
| ⚖️ 违反单一职责 | 同一函数干了:筛选、排序、分页三件事 |
| 🔥 性能隐患 | 每次过滤都生成新 List,频繁 GC;多次遍历集合 |
总结: filterHouseV1 是典型的 过程式编程 在复杂业务逻辑下的表现,它在灵活性、可维护性和扩展性上都存在明显缺陷。我们需要引入设计模式来重构。
2.2.3 引入设计模式的过滤优化
为了解决上述问题,我们将分别对 过滤 (Filter) 和 排序 (Sort) 逻辑应用 策略模式 (Strategy Pattern) ,并利用 工厂模式 (Factory Pattern) 来管理和获取这些策略的具体实现。
2.2.3.1 引入策略模式 (Strategy Pattern)
策略模式定义: 定义一系列算法,将每个算法封装起来,并使它们可以相互替换。策略模式让算法的变化独立于使用它的客户。
(1) 过滤策略 (Filter Strategy)
首先定义一个过滤策略的通用接口 IHouseFilter:
java
public interface IHouseFilter {
/**
* 判断单个房源DTO是否满足该过滤器的条件 (基于请求参数)
* @param houseDTO 房源DTO
* @param reqDTO 搜索请求DTO
* @return true 表示通过过滤, false 表示被过滤掉
*/
boolean filter(HouseDTO houseDTO, SearchHouseListReqDTO reqDTO);
}然后,为 每一个 过滤条件创建一个具体的策略实现类,并注册为Spring管理的Bean (@Component):
- 区域过滤器 (RegionFilter)
java
@Component // 由Spring管理
public class RegionFilter implements IHouseFilter {
@Override
public boolean filter(HouseDTO houseDTO, SearchHouseListReqDTO reqDTO) {
// 如果请求中没有选择区域 (reqDTO.getRegionId() == null), 则该过滤器不限制,返回true
// 如果选择了区域,则只保留区域ID匹配的房源
return reqDTO.getRegionId() == null || houseDTO.getRegionId().equals(reqDTO.getRegionId());
}
}- 租赁类型过滤器 (RentTypesFilter)
java
@Component
public class RentTypesFilter implements IHouseFilter {
@Override
public boolean filter(HouseDTO houseDTO, SearchHouseListReqDTO reqDTO) {
// 如果请求中没有选择任何租赁类型,则该过滤器不限制
// 如果选择了类型,则只保留类型在所选列表中的房源
return CollectionUtils.isEmpty(reqDTO.getRentTypes())
|| reqDTO.getRentTypes().contains(houseDTO.getRentType()); // 注意:这里原代码是 rentalRanges,应是笔误,应改为 rentTypes
}
}- 居室数过滤器 (RoomsFilter)
java
@Component
public class RoomsFilter implements IHouseFilter {
@Override
public boolean filter(HouseDTO houseDTO, SearchHouseListReqDTO reqDTO) {
// 如果请求中没有选择任何居室数,则该过滤器不限制
// 如果选择了居室数,则只保留居室数在所选列表中的房源
return CollectionUtils.isEmpty(reqDTO.getRooms())
|| reqDTO.getRooms().contains(houseDTO.getRooms());
}
}- 状态过滤器 (StatusFilter) - 通常固定过滤上架房源
java
@Component // 原代码是@Configuration,用@Component更合适
public class StatusFilter implements IHouseFilter {
@Override
public boolean filter(HouseDTO houseDTO, SearchHouseListReqDTO reqDTO) {
// 固定过滤规则:只保留状态为 "UP" (上架) 的房源
// 注意:原代码 equalsIgnoreCase,这里假设 HouseStatusEnum.UP.name() 返回 "UP"
return HouseStatusEnum.UP.name().equalsIgnoreCase(houseDTO.getStatus());
}
}- 租金范围过滤器 (RentalRangesFilter) - 包含复杂逻辑
java
@Slf4j
@Component
public class RentalRangesFilter implements IHouseFilter {
@Override
public boolean filter(HouseDTO houseDTO, SearchHouseListReqDTO reqDTO) {
// 如果请求中没有选择任何租金范围,则该过滤器不限制
// 如果选择了租金范围,则判断房源价格是否在任意一个所选范围内
return CollectionUtils.isEmpty(reqDTO.getRentalRanges())
|| isPriceInAnyRange(houseDTO.getPrice(), reqDTO.getRentalRanges());
}
private boolean isPriceInAnyRange(Double price, List<String> rentalRanges) {
if (price == null) {
return false; // 价格为空,不符合任何范围
}
for (String range : rentalRanges) {
if (isPriceInRange(price, range)) {
return true; // 只要在一个范围内,就算通过
}
}
return false; // 不在任何所选范围内
}
private boolean isPriceInRange(Double price, String rangeKey) {
// 根据 rangeKey 判断价格区间
switch (rangeKey) {
case "range_1": return price < 1000;
case "range_2": return price >= 1000 && price < 1500;
case "range_3": return price >= 1500 && price < 2000;
case "range_4": return price >= 2000 && price < 3000;
case "range_5": return price >= 3000 && price < 5000;
case "range_6": return price >= 5000;
default:
log.warn("未知的租金范围标识: {}", rangeKey);
return false;
}
}
}过滤策略的优势:
- 每个过滤条件独立成类,职责单一。
- 新增过滤条件只需实现
IHouseFilter接口并添加一个新的@Component类,无需修改 核心的过滤流程代码 (filterHouse方法)。 - 过滤逻辑集中在其
filter方法中,清晰易懂。 - 易于单元测试:每个过滤器可以单独测试。
(2) 排序策略 (Sort Strategy)
同样,定义一个排序策略的通用接口 ISortStrategy:
java
public interface ISortStrategy {
/**
* 对房源列表进行排序
* @param houseDTOList 待排序的房源列表
* @param reqDTO 搜索请求DTO (包含排序可能需要的参数,如经纬度)
* @return 排序后的列表
*/
List<HouseDTO> sort(List<HouseDTO> houseDTOList, SearchHouseListReqDTO reqDTO);
}然后,为 每一种 排序方式创建具体的策略实现类:
- 距离排序策略 (DistanceSortStrategy)
java
public class DistanceSortStrategy implements ISortStrategy {
// 单例模式:静态实例
private static final DistanceSortStrategy INSTANCE = new DistanceSortStrategy();
// 私有构造器
private DistanceSortStrategy() {}
// 获取单例实例
public static DistanceSortStrategy getInstance() {
return INSTANCE;
}
@Override
public List<HouseDTO> sort(List<HouseDTO> houseDTOList, SearchHouseListReqDTO reqDTO) {
// 按距离排序 (升序,离得近的在前)
return houseDTOList.stream()
.sorted(Comparator.comparingDouble(
house -> house.calculateDistance(reqDTO.getLongitude(), reqDTO.getLatitude())
)).collect(Collectors.toList());
}
}- 价格排序策略 (PriceSortStrategy) - 支持升序/降序
java
public class PriceSortStrategy implements ISortStrategy {
private final boolean ascending; // 排序方向
// 单例模式:升序实例
private static final PriceSortStrategy ASC_INSTANCE = new PriceSortStrategy(true);
// 单例模式:降序实例
private static final PriceSortStrategy DESC_INSTANCE = new PriceSortStrategy(false);
// 私有构造器
private PriceSortStrategy(boolean ascending) {
this.ascending = ascending;
}
// 获取升序策略实例
public static PriceSortStrategy getAscInstance() {
return ASC_INSTANCE;
}
// 获取降序策略实例
public static PriceSortStrategy getDescInstance() {
return DESC_INSTANCE;
}
@Override
public List<HouseDTO> sort(List<HouseDTO> houseDTOList, SearchHouseListReqDTO reqDTO) {
Comparator<HouseDTO> priceComparator = Comparator.comparingDouble(HouseDTO::getPrice);
if (!ascending) {
priceComparator = priceComparator.reversed();
}
return houseDTOList.stream()
.sorted(priceComparator)
.collect(Collectors.toList());
}
}排序策略的优势:
- 每种排序规则独立成类。
- 新增排序规则只需实现
ISortStrategy接口。 - 逻辑清晰,易于测试。
PriceSortStrategy通过构造参数和静态工厂方法 (getAscInstance,getDescInstance) 支持了升序和降序两种策略,避免了为方向创建两个几乎相同的类。
2.2.3.2 引入工厂模式 (Factory Pattern) - 简化策略获取
策略模式定义了策略,但需要一个地方来创建或选择合适的策略实例。这就是工厂模式的用武之地。
(1) 过滤策略的"工厂" - Spring IoC 容器
对于过滤策略 IHouseFilter,我们采用了 @Component 注解将其实现类交由 Spring IoC 容器 管理。Spring 容器本身就是一个强大的 对象工厂。
在核心的过滤方法 (houseFilter) 中,我们可以直接注入一个 Map,其 key 是 Bean 的名字(或类型),value 是 IHouseFilter 的实现实例:
java
@Service
public class HouseSearchService {
// Spring 会自动将所有 IHouseFilter 的实现注入到这个Map中
// key: Bean的名称 (如 "regionFilter"), value: 对应的 IHouseFilter 实例
@Autowired
private Map<String, IHouseFilter> houseFilterMap; // 关键注入
// ... 其他方法 ...
private List<HouseDTO> houseFilter(List<HouseDTO> houseDTOList, SearchHouseListReqDTO reqDTO) {
return houseDTOList.stream()
.filter(houseDTO -> {
// 遍历 Map 中的所有过滤器 (策略)
for (IHouseFilter filter : houseFilterMap.values()) {
// 如果任何一个过滤器返回 false,则此房源被过滤掉
if (!filter.filter(houseDTO, reqDTO)) {
return false;
}
}
return true; // 所有过滤器都通过
})
.collect(Collectors.toList());
}
}- 优势 : Spring 容器充当了工厂的角色,我们无需手动创建和管理这些过滤器实例。通过注入
Map<String, IHouseFilter>,我们轻松获取到了所有可用的过滤策略。新增过滤器只需添加一个@Component类,它会自动出现在这个Map中,核心过滤流程 (houseFilter方法) 完全不需要修改! - 执行顺序 : 注意,
Map中值的遍历顺序可能依赖于 Bean 的注册顺序(通常是非确定的)。如果过滤条件有严格的依赖关系(例如必须先过滤状态再过滤区域),需要在过滤器实现中处理好逻辑(比如StatusFilter总是返回false如果状态不对,其他条件就不依赖它),或者考虑使用@Order注解或List<IHouseFilter>注入来明确顺序。
(2) 排序策略的工厂 (SortStrategyFactory)
对于排序策略 ISortStrategy,由于我们使用了显式的单例模式(getInstance() 方法),并且不是由Spring管理(或者也可以交给Spring管理为单例Bean),我们可以创建一个专门的工厂类 SortStrategyFactory 来根据请求中的排序标识 (sort) 返回对应的策略实例:
java
public class SortStrategyFactory {
// 根据排序标识获取对应的排序策略
public static ISortStrategy getSortStrategy(String sortType) {
if (sortType == null || sortType.isEmpty()) {
// 默认策略?例如按距离
return DistanceSortStrategy.getInstance();
}
switch (sortType.toUpperCase()) {
case HouseSortEnum.DISTANCE.name():
return DistanceSortStrategy.getInstance();
case HouseSortEnum.PRICE_ASC.name():
return PriceSortStrategy.getAscInstance();
case HouseSortEnum.PRICE_DESC.name():
return PriceSortStrategy.getDescInstance();
// 可以轻松扩展新的排序策略
// case "NEW_SORT": return NewSortStrategy.getInstance();
default:
log.warn("未知的排序类型: {}, 使用默认排序(距离)", sortType);
return DistanceSortStrategy.getInstance();
}
}
}优势:
- 将策略的创建逻辑集中在一个地方 (
SortStrategyFactory)。 - 客户端代码 (
houseSorting方法) 只需要传入sortType,即可获得正确的策略对象,无需关心具体实现类的创建细节。 - 易于扩展:新增排序策略只需在
SortStrategyFactory中添加一个新的case分支。
与Spring的结合 : 如果希望排序策略也由Spring管理,可以将 DistanceSortStrategy 和 PriceSortStrategy 也标注为 @Component (注意单例问题,Spring Bean默认单例),然后在 SortStrategyFactory 中通过 @Autowired 注入这些Bean,或者使用 ApplicationContext 来获取Bean。这样工厂本身也可以成为Spring Bean。
2.2.3.3 引入单例模式 (Singleton Pattern) - 策略复用
在上面的排序策略实现 (DistanceSortStrategy, PriceSortStrategy) 中,我们使用了 单例模式:
java
public class DistanceSortStrategy implements ISortStrategy {
private static final DistanceSortStrategy INSTANCE = new DistanceSortStrategy();
private DistanceSortStrategy() {} // 私有构造
public static DistanceSortStrategy getInstance() { return INSTANCE; }
// ... sort 方法 ...
}为什么需要单例?
- 无状态性 : 排序策略对象本身通常不持有与特定请求相关的状态(它们的行为完全由传入的
List<HouseDTO>和reqDTO参数决定)。它们只包含算法逻辑。 - 避免重复创建 : 在高并发场景下,如果每次排序都
new一个策略实例,会产生大量短暂存在的对象,增加GC压力。使用单例可以复用同一个策略对象。 - 线程安全: 因为策略对象是无状态的,所以它们的单例实例在多线程环境下使用也是安全的。
单例模式的实现: 这里使用了 饿汉式 (Eager Initialization) 单例。在类加载时就直接创建实例 (private static final ... = new ...()),通过私有构造器防止外部实例化,并提供静态的 getInstance() 方法获取该唯一实例。
Spring管理的单例: 如果将策略类交给Spring管理(使用 @Component),Spring容器默认创建的Bean就是单例的(Scope: Singleton),同样可以达到复用对象、避免重复创建的目的。此时就不需要手动实现单例模式了,Spring会帮我们管理。
2.3 最终实现
将策略模式和工厂模式结合后,我们的核心过滤排序分页方法 filterHouse 变得非常简洁:
java
private BasePageDTO<HouseDTO> filterHouse(List<HouseDTO> houseDTOList, SearchHouseListReqDTO reqDTO) {
// 1. 过滤:应用所有注册的 IHouseFilter 策略 (通过 houseFilterMap)
List<HouseDTO> filteredList = houseFilter(houseDTOList, reqDTO);
// 2. 排序:根据请求的 sort 类型,通过工厂获取对应的 ISortStrategy 并应用
List<HouseDTO> sortedList = houseSorting(filteredList, reqDTO);
// 3. 分页:对排序后的列表进行分页
return housePage(sortedList, reqDTO);
}
// 具体子方法实现:
private List<HouseDTO> houseFilter(List<HouseDTO> houseDTOList, SearchHouseListReqDTO reqDTO) {
return houseDTOList.stream()
.filter(houseDTO -> {
try {
// 使用 Stream.allMatch 表示必须通过所有过滤器
return houseFilterMap.values().stream()
.allMatch(filter -> filter.filter(houseDTO, reqDTO));
} catch (Exception e) { // 异常处理,记录日志,通常认为过滤失败
log.error("房源过滤异常 houseId={}, filter={}", houseDTO.getId(), e.getClass().getSimpleName(), e);
return false;
}
})
.collect(Collectors.toList());
}
private List<HouseDTO> houseSorting(List<HouseDTO> houseDTOList, SearchHouseListReqDTO reqDTO) {
// 通过工厂获取策略
ISortStrategy sortStrategy = SortStrategyFactory.getSortStrategy(reqDTO.getSort());
// 应用策略进行排序
return sortStrategy.sort(houseDTOList, reqDTO);
}
private BasePageDTO<HouseDTO> housePage(List<HouseDTO> houseDTOList, SearchHouseListReqDTO reqDTO) {
int total = houseDTOList.size();
int totalPages = BasePageDTO.calculateTotalPages(total, reqDTO.getPageSize());
List<HouseDTO> pageList = houseDTOList.stream()
.skip(reqDTO.getOffset())
.limit(reqDTO.getPageSize())
.collect(Collectors.toList());
BasePageDTO<HouseDTO> result = new BasePageDTO<>();
result.setTotals(total);
result.setTotalPages(totalPages);
result.setList(pageList);
return result;
}重构后的优势总结 (对比 filterHouseV1):
|----------|--------------------------|--------------------------------------|---------------------------------------|
| 特性 | 基础实现 (filterHouseV1) | 策略+工厂模式实现 (filterHouse) | 优势 |
| 扩展性 | 差。新增条件/排序需修改核心方法,违反开闭原则。 | 极好。新增过滤器/排序器只需添加新策略类,核心流程不变。 | 符合开闭原则,易于适应业务变化。 |
| 可读性 | 差。长方法,嵌套逻辑,混杂。 | 好。核心流程清晰(过滤->排序->分页),各策略逻辑独立。 | 代码结构清晰,职责分明。 |
| 可维护性 | 差。修改一处可能影响其他,调试困难。 | 好。各策略独立,修改或调试单个策略不影响其他。 | 降低耦合度,提高代码健壮性。 |
| 单一职责 | 违反。一个方法做多件事。 | 遵守 。filterHouse 协调流程,策略负责具体逻辑。 | 符合面向对象设计原则。 |
| 复用性 | 低。逻辑绑定在特定方法中。 | 高。策略类可独立复用。 | 提高代码利用率。 |
| 代码量 | 核心方法冗长。 | 核心方法简洁,但策略类增加。 | 值得的权衡。核心复杂度降低,新增逻辑的成本转移到易于管理的策略类。 |
UML 图示 (核心关系):
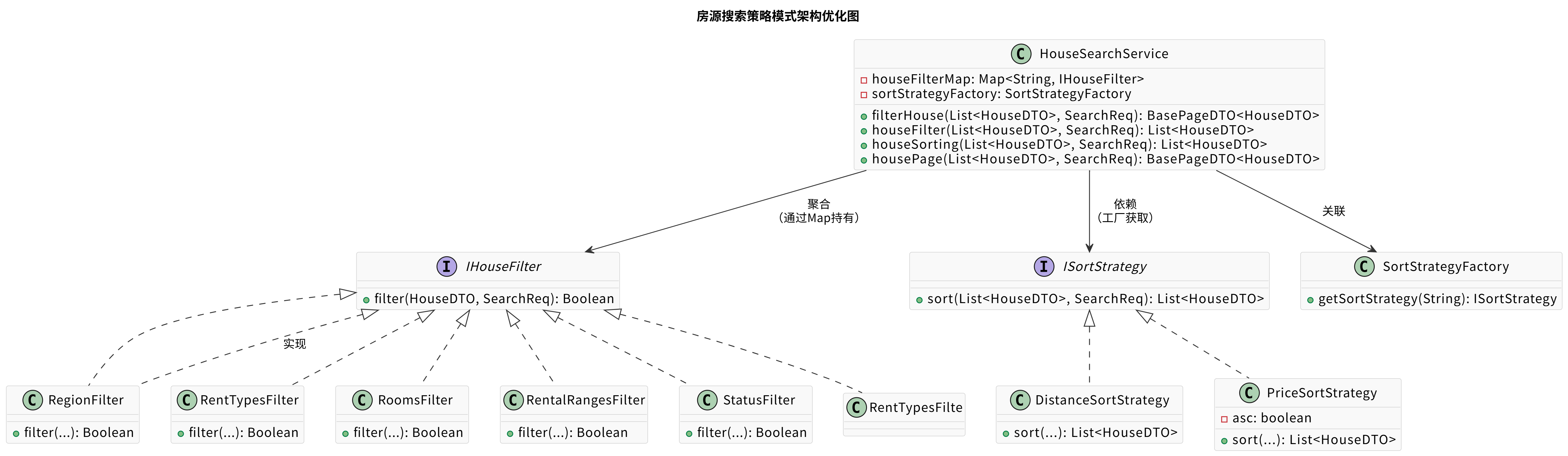
- HouseSearchService : 服务类,持有
IHouseFilter的Map (houseFilterMap),包含filterHouse等核心方法。 - IHouseFilter : 过滤策略接口。
RegionFilter等是具体实现。 - ISortStrategy : 排序策略接口。
DistanceSortStrategy等是具体实现。 - SortStrategyFactory : 负责根据请求参数创建具体的
ISortStrategy实例。 - 箭头: 表示依赖、实现或关联关系。
3. 小结
通过将 策略模式 和 工厂模式 应用于房源搜索系统的过滤和排序逻辑,我们成功地将一个臃肿、难以维护的 filterHouseV1 方法,重构为清晰、灵活、易于扩展的 filterHouse 流程。总结一下关键点:
- 策略模式解耦逻辑 : 将变化的过滤条件和排序规则封装成独立的策略类 (
IHouseFilter,ISortStrategy),使它们与使用它们的核心流程 (filterHouse) 解耦。 - 工厂模式简化获取:
-
- 利用 Spring IoC 容器 作为天然的工厂,自动管理和注入所有过滤策略 (
@Autowired Map<String, IHouseFilter>),极大地简化了过滤策略的获取和管理。 - 创建专门的
SortStrategyFactory工厂类,根据请求参数返回合适的排序策略实例。
- 利用 Spring IoC 容器 作为天然的工厂,自动管理和注入所有过滤策略 (
- 单例模式提升效率: 对于无状态的策略对象(尤其是排序策略),采用单例模式(或依靠Spring的单例管理)避免不必要的对象创建,提升性能。
- 符合设计原则 : 重构后的代码更好地遵循了 开闭原则 (OCP) 、单一职责原则 (SRP),降低了模块间的耦合度。
- 显著提升可维护性: 新增业务规则(如新的过滤条件、排序方式)变得非常容易,只需添加新的策略类并在工厂(如果是排序)或Spring容器(如果是过滤)中注册即可,核心流程代码保持稳定。
实战建议:
- 策略粒度: 策略的划分要适度。像"租金范围"这种内部逻辑复杂的,适合单独一个策略。如果两个条件逻辑非常简单且总是同时出现,可以考虑合并到一个策略中,但要评估未来变化的可能性。
- Spring 管理 : 尽可能利用Spring容器管理策略对象(使用
@Component),享受依赖注入和单例管理的便利。对于需要参数化构造的策略(如PriceSortStrategy的方向),可以考虑结合工厂模式或使用Spring的@Qualifier。 - 策略顺序 : 如果过滤条件之间有依赖关系或需要特定顺序,注入
List<IHouseFilter>并配合@Order注解,或者让策略实现Ordered接口。 - 性能考量 : 虽然策略模式增加了类的数量,但其带来的可维护性提升是巨大的。对于性能敏感的 最内层循环 ,确保策略的
filter方法实现高效。Stream API在数据量特别大时,parallelStream可能是一个选项(但要考虑线程安全和上下文切换开销)。 - 测试: 策略模式极大地方便了单元测试。每个过滤器/排序器都可以单独测试其核心逻辑。
这次重构实践清晰地展示了设计模式如何在实际项目中解决代码坏味道,提升软件质量。希望这个案例能帮助你在今后的开发中,更自信地运用这些模式来构建更优雅、更健壮的代码!大家如果在实践中遇到问题或有更好的想法,欢迎在评论区留言讨论。