突破智能体训练瓶颈:DreamGym如何通过经验合成实现可扩展的强化学习?
本文将介绍DreamGym,一个革命性的强化学习框架,它通过合成多样化经验来解决智能体训练中的核心挑战。DreamGym首次提出基于推理的经验模型,能够在不依赖昂贵真实环境交互的情况下,生成一致的状态转换和反馈信号,为自主智能体的在线强化学习训练提供了可扩展的解决方案。在WebArena等非RL就绪任务中,DreamGym的性能超越所有基线30%以上;在RL就绪但成本高昂的环境中,它仅使用合成交互就匹配了GRPO和PPO的性能。
论文标题 :Scaling Agent Learning via Experience Synthesis
来源 :arXiv:2511.03773 cs.AI,链接:https://arxiv.org/abs/2511.03773
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 AI极客熊 」 即刻免费解锁
文章核心
研究背景
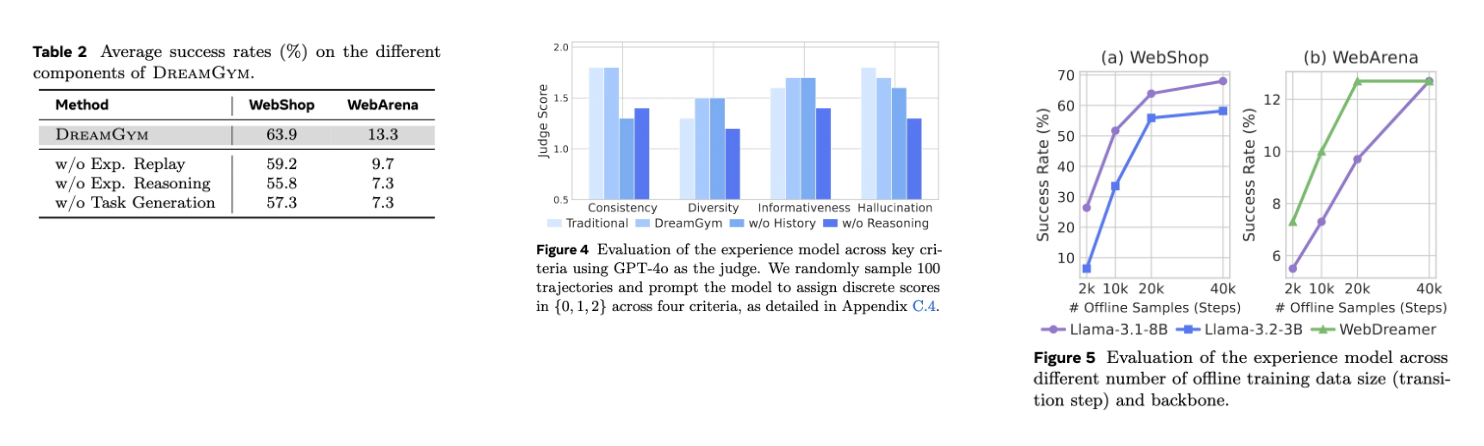
强化学习(RL)能够通过交互使自主智能体实现自我提升,但其实际应用仍面临巨大挑战。高昂的rollout成本、有限的任务多样性、不可靠的奖励信号以及基础设施复杂性共同阻碍了可扩展经验数据的收集。这些限制使得构建通用且可扩展的智能体RL训练系统成为一个紧迫且未解决的挑战,特别是在需要长程交互、稀疏奖励和复杂环境动态的场景中。
研究问题
- 传统RL训练依赖昂贵真实环境交互,单次交互成本高且样本效率低,难以收集大规模多样化数据
- 现有环境提供有限静态指令集,缺乏多样化可扩展任务,无法满足RL训练对广泛任务探索的需求
- 动态环境(如网页和GUI)产生噪声、稀疏甚至错误反馈,导致学习不稳定,且某些动作不可逆
- 异构环境和重型后端(如Docker或虚拟机)使大批量rollout采样工程密集且成本高昂
主要贡献
- 首创统一框架DreamGym,通过基于推理的经验模型合成多样化经验,实现可扩展的在线RL训练
- 提出经验回放缓冲区机制,结合离线真实世界数据与在线合成转换,与智能体协同进化确保稳定训练
- 设计自适应任务生成器,基于奖励熵启发式生成具有挑战性的任务变体,实现有效的在线课程学习
- 在多个环境和智能体骨干网络上验证,DreamGym在完全合成设置和仿真到真实迁移场景中显著改善RL训练
方法论精要
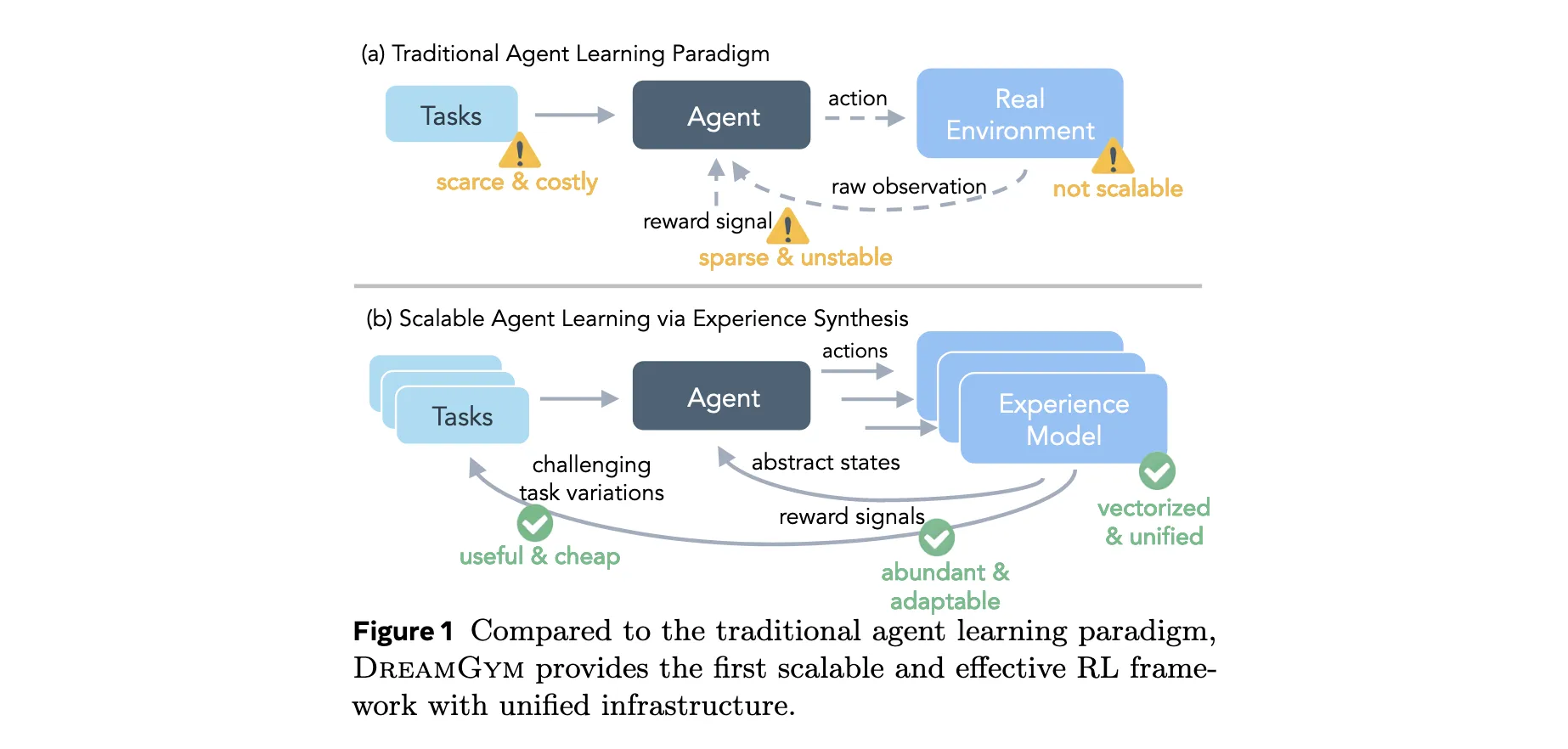
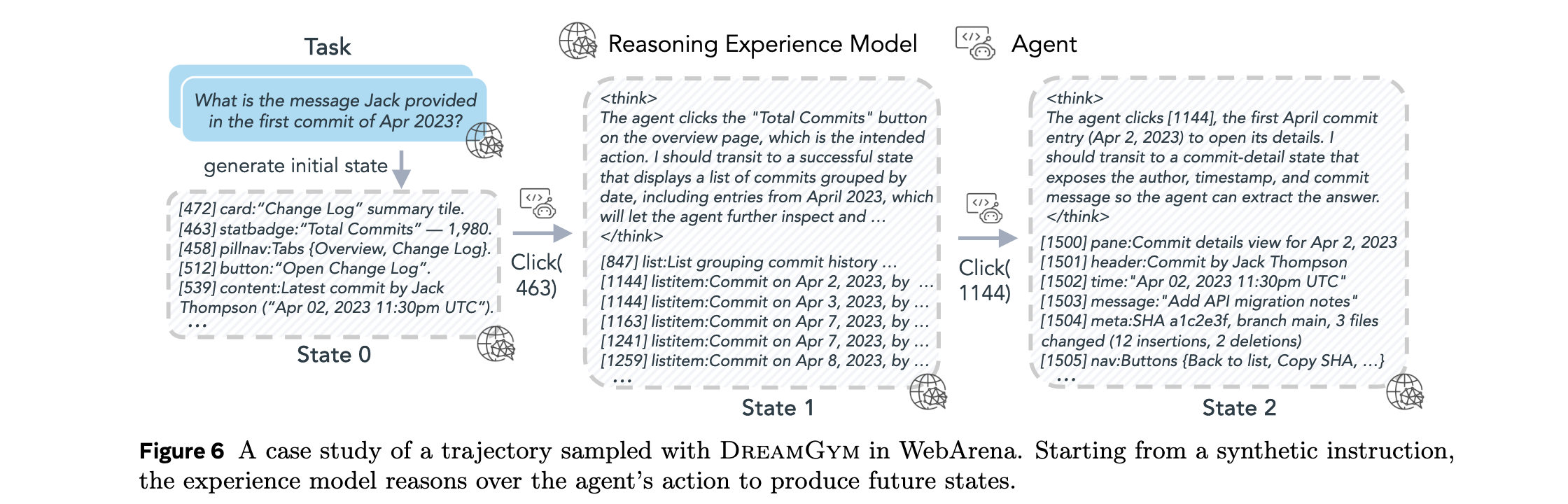
推理经验模型构建
DreamGym的核心是基于LLM的推理经验模型 M e x p M_{exp} Mexp,它在抽象的元表示文本空间 S \mathcal{S} S中运行,而非原始像素空间。这种设计通过减少无关维度,生成比原始观测更具信息性和token效率的轨迹。模型通过链式思维(CoT)推理预测下一状态和奖励:
( s t + 1 , r t + 1 ) = M e x p ( R t ∣ { ( s i , a i ) } i = 0 t , { d j } j = 1 k , τ ) (s_{t+1}, r_{t+1}) = M_{exp}(R_t | \{(s_i, a_i)\}{i=0}^{t}, \{d_j\}{j=1}^{k}, \tau) (st+1,rt+1)=Mexp(Rt∣{(si,ai)}i=0t,{dj}j=1k,τ)
其中 R t R_t Rt是显式推理轨迹, { ( s i , a i ) } i = 0 t \{(s_i, a_i)\}{i=0}^{t} {(si,ai)}i=0t是交互历史, { d j } j = 1 k \{d_j\}{j=1}^{k} {dj}j=1k是从回放缓冲区检索的top-k相似演示, τ \tau τ是任务指令。
经验模型训练
通过SFT训练目标联合优化推理生成和下一状态预测:
L S F T = E ( s t , a t , s t + 1 , R t ∗ ) ∼ D − log P θ ( R t ∗ ∣ s t , a t , H t , D k ) − log P θ ( s t + 1 ∣ s t , a t , R t ∗ , H t , D k ) L_{SFT} = \mathbb{E}{(s_t, a_t, s{t+1}, R_t^*) \sim \mathcal{D}} -\\log P_\\theta(R_t\^\* \| s_t, a_t, H_t, D_k) - \\log P_\\theta(s_{t+1} \| s_t, a_t, R_t\^\*, H_t, D_k) LSFT=E(st,at,st+1,Rt∗)∼D−logPθ(Rt∗∣st,at,Ht,Dk)−logPθ(st+1∣st,at,Rt∗,Ht,Dk)
这确保模型学会生成忠实推理轨迹并利用这些轨迹预测一致且信息丰富的下一状态。
基于课程的任务生成
多样化、课程对齐的任务指令对RL智能体获取知识至关重要。DreamGym通过自适应任务生成解决任务扩展成本高昂的问题:
τ t = M t a s k ( { τ i t − 1 } i = 1 m ) \tau_t = M_{task}(\{\tau_i^{t-1}\}_{i=1}^{m}) τt=Mtask({τit−1}i=1m)
其中 M t a s k M_{task} Mtask与 M e x p M_{exp} Mexp共享参数。种子任务基于两个标准选择:(1)对当前智能体策略足够有挑战性,最大化信息增益;(2)定义良好,避免不切实际或格式错误的任务。
引入基于组的奖励熵作为选择高质量挑战性任务的标准:
V τ = 1 n ∑ i = 1 n ( r i − r ˉ ) 2 V_\tau = \frac{1}{n}\sum_{i=1}^{n}(r_i - \bar{r})^2 Vτ=n1∑i=1n(ri−rˉ)2,其中 r ˉ = 1 n ∑ i = 1 n r i \bar{r} = \frac{1}{n}\sum_{i=1}^{n} r_i rˉ=n1∑i=1nri
非零方差表明智能体在任务中既观察到成功也观察到失败,表明任务可行但有挑战性。当成功和失败在 G \mathcal{G} G中平衡时,任务达到最大熵,为信用分配提供最大信息增益。
从合成经验中学习
DreamGym从种子任务集开始,通过智能体策略和经验模型交替生成每个任务的多轮rollout。收集的rollout使用标准RL算法更新策略。每次迭代后,经验模型通过生成高奖励熵的挑战性任务变体来扩展任务集。这种交互、训练和课程扩展的循环持续直到收敛或预定义训练预算达到。
仿真到真实的策略迁移
DreamGym-S2R设置中,智能体策略首先使用合成经验训练,然后迁移到真实环境中的RL。合成环境中的预训练扩展了跨多样化任务的探索覆盖范围,使智能体能够以低成本获取广泛知识,为后续真实环境学习提供强大的初始化。
实验洞察
实验设置
在三个具有挑战性的智能体基准上评估DreamGym,涵盖不同领域、复杂性和RL准备程度:(1) WebShop:需要推理改进搜索查询并准确识别产品以完成电子商务任务;(2) ALFWorld:涉及多轮工具化具身控制以导航3D环境;(3) WebArena-Lite:提供真实网页交互界面但非RL就绪,缺乏可扩展数据收集和环境重置机制。
智能体骨干网络包括Llama-3.2-3B-Instruct、Llama-3.1-8B-Instruct和Qwen-2.5-7B-Instruct。基线包括:(1) 离线模仿学习:SFT、DPO;(2) 真实环境在线RL:GRPO、PPO。
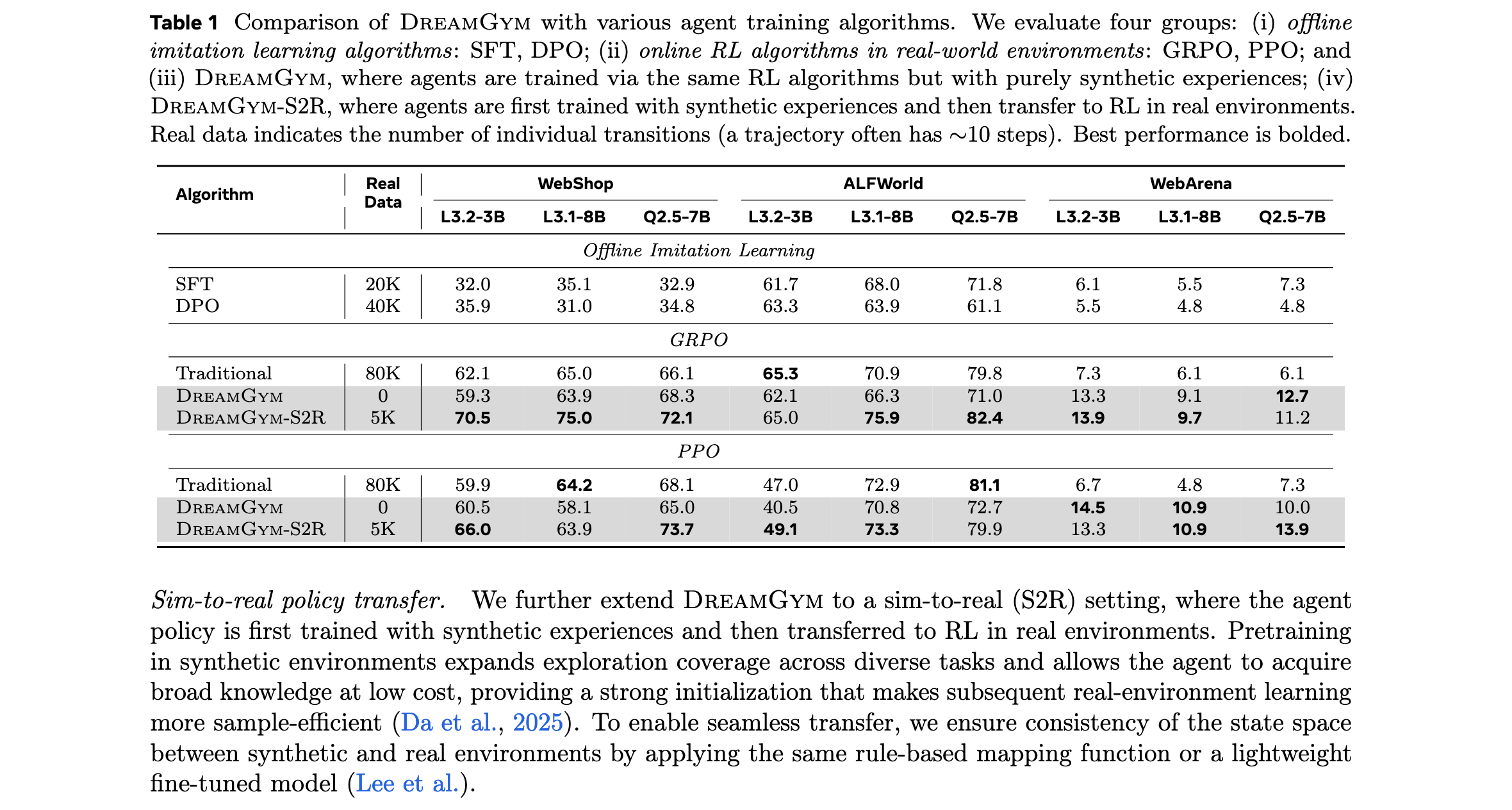
主要结果
非RL就绪环境。在WebArena中,DreamGym展示最显著优势。纯DreamGym训练的智能体在所有骨干网络上实现超过30%的成功率,而零样本RL基线因原始环境中探索多样性有限和稀疏奖励信号而表现不佳。
RL就绪环境。在WebShop和ALFWorld上,DreamGym训练的智能体仅使用合成rollout就与在80K真实交互上训练的GRPO和PPO智能体表现相当。当对合成环境中中期训练的策略应用小规模RL阶段(5k真实rollout)时,DreamGym-S2R始终优于从零开始在真实环境中训练的GRPO和PPO基线。
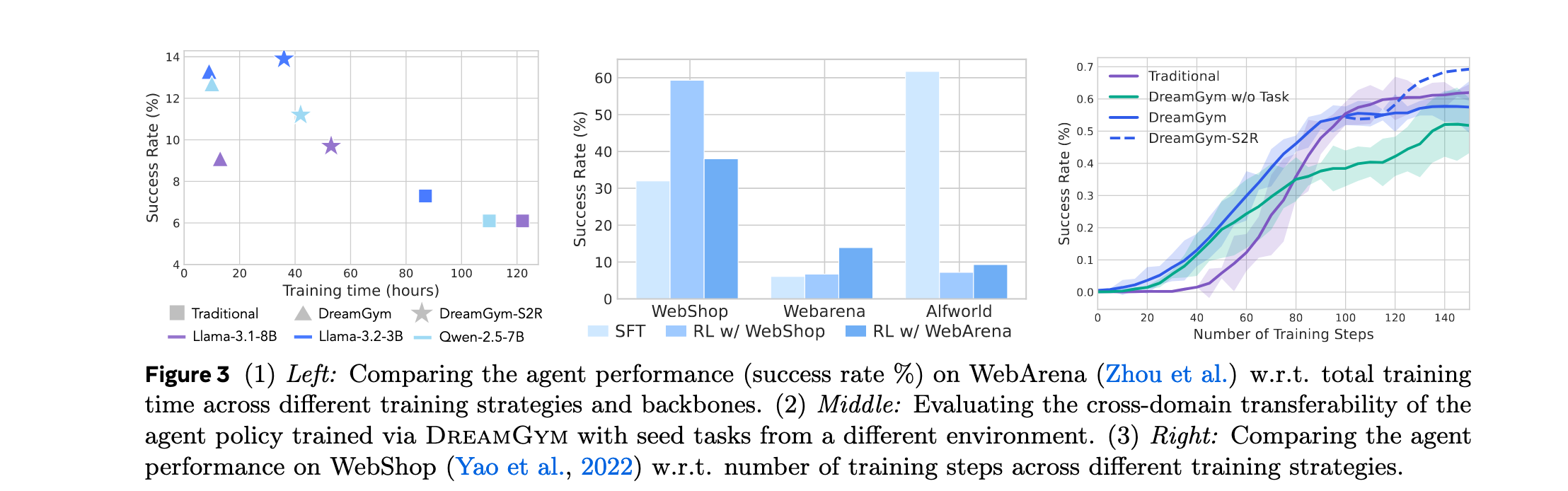
样本效率和训练成本。DreamGym在WebArena上实现显著性能增益,同时将训练努力(包括rollout采样时间和GPU小时)减少到真实环境中RL基线的大约三分之一甚至五分之一。效率提升源于课程驱动的rollout合成提供的密集反馈和可扩展LLM服务托管的轻量级抽象状态转换。
泛化和学习可迁移性。在WebShop上训练的策略能够泛化到WebArena并超越直接在那里训练的SFT模型;在WebArena上训练的策略同样能迁移回WebShop并表现优于SFT。但当领域差距过大时(如从基于网页环境迁移到ALFWorld),性能显著下降。
消融研究
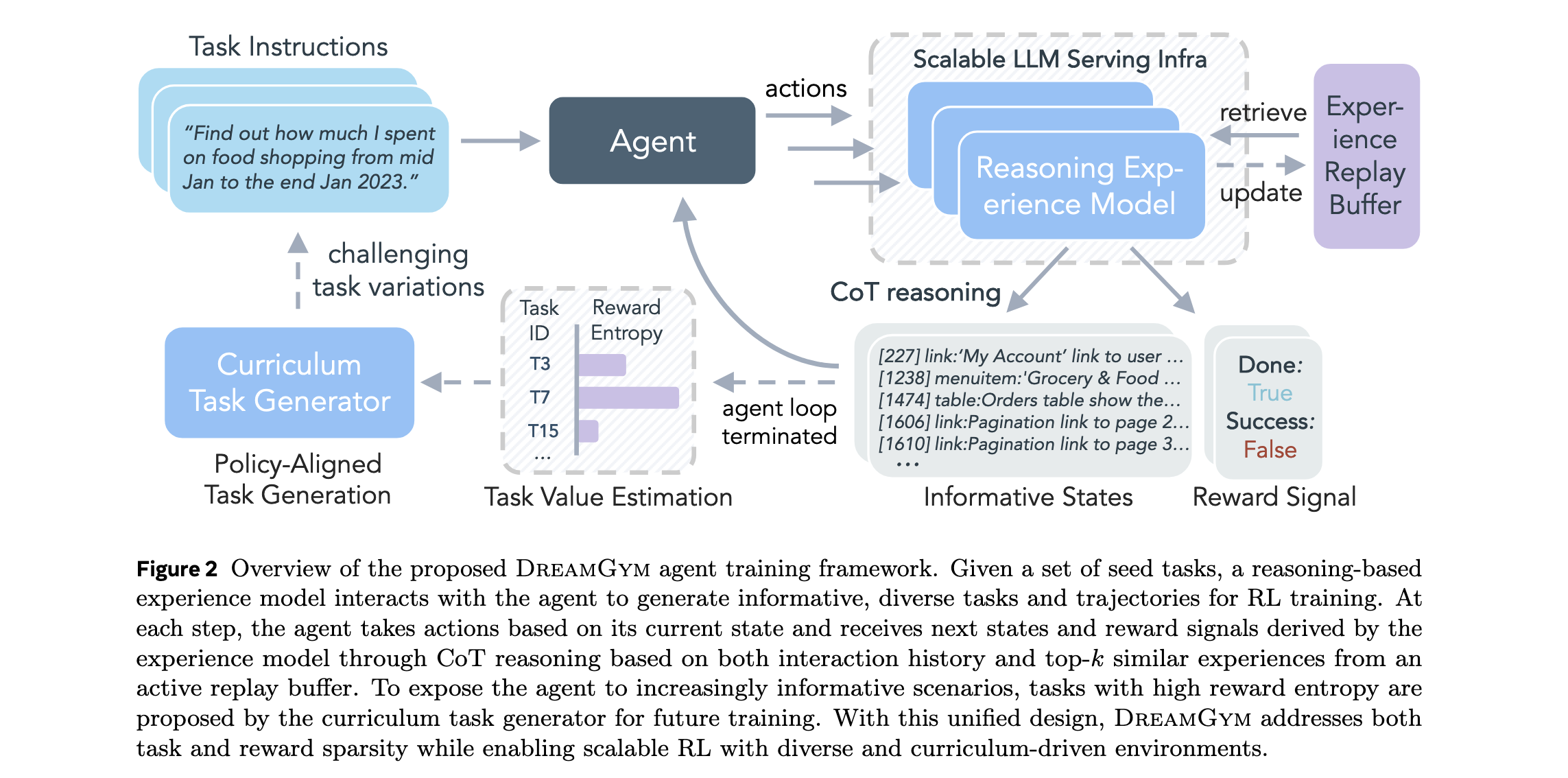
任务生成器消融。移除此组件导致智能体在WebShop场景中初始进展后更快达到平台期。在WebShop和WebArena中,移除任务生成器导致成功率分别下降6.6%和6.0%。没有自适应任务生成,回放缓冲区可能饱和低熵、重复轨迹,限制经验多样性并阻碍探索。
经验模型消融。评估四个变体:传统真实环境模型、DreamGym、无历史访问的DreamGym(w/o History)和无推理的DreamGym(w/o Reasoning)。移除轨迹历史显著降低一致性;移除推理主要损害状态信息量并增加幻觉。完整的DreamGym在所有指标上实现最佳或接近最佳性能,确认历史和推理提供互补优势。
经验模型骨干网络和离线训练数据消融。经验模型高度数据高效,即使使用非常有限的离线样本(2k-10k),已达到竞争性能。在WebShop上,Llama-3.1-8B仅用10k样本就超过50%成功率。较小骨干网络仍然可行,Llama-3.2-3B在20k样本时达到约55%成功率。