🐍 Scikit-learn 入门指南:从零到一掌握机器学习经典库(2025 最新版)
核心结论:Scikit-learn(sklearn)是 Python 机器学习生态的"瑞士军刀",以简洁 API、完善生态和高效性能成为入门首选,10 行代码即可搭建分类/回归模型,无缝对接 NumPy、Pandas、Matplotlib,适用于原型验证、教学和 Kaggle 竞赛,2025 最新版 1.5.0 新增更多预处理工具和算法优化,安装量已超 10 亿次。
一、为什么选择 Scikit-learn?
- 易用性拉满 :所有算法统一 API(
fit()训练、predict()预测、score()评估),新手零门槛上手。 - 生态无缝衔接:完美兼容 NumPy(数据存储)、Pandas(数据处理)、Matplotlib(可视化),无需额外适配。
- 功能全覆盖:支持分类、回归、聚类、降维、模型选择、预处理等 100+ 核心功能,满足从入门到进阶的全场景需求。
- 性能高效:内置并行计算、算法优化,小数据集秒级训练,大数据集也能稳定运行。
- 社区成熟:文档详尽、示例丰富,2025 版新增 Transformer 集成和自动超参调优功能,生产级场景可搭配 TensorFlow/PyTorch 使用。
二、安装与环境准备(5 分钟搞定)
sklearn 依赖 NumPy(≥1.17)和 SciPy(≥1.5),需保证 Python 版本 ≥3.9(2025 版最低要求)。
1. 快速安装
bash
# 基础安装(仅核心功能)
pip install scikit-learn==1.5.0 # 固定版本,避免兼容性问题
# 完整环境(推荐,含数据处理+可视化)
pip install scikit-learn==1.5.0 pandas matplotlib seaborn numpy scipy
# 验证安装成功
python -c "import sklearn; print('安装成功!版本:', sklearn.__version__)"2. 常见安装问题解决
| 问题 | 原因 | 解决方案 |
|---|---|---|
| 依赖冲突 | 现有 NumPy/SciPy 版本过低 | pip install --upgrade numpy scipy |
| 安装缓慢 | 网络问题 | 换国内镜像:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scikit-learn |
| Windows 编译失败 | 缺少 C++ 编译环境 | 安装 Visual Studio Build Tools |
3. 推荐开发环境
- 本地 :Jupyter Notebook(
pip install jupyter)→ 终端输入jupyter notebook启动。 - 在线:Google Colab(免费 GPU)、Kaggle Kernels(数据集直接调用),无需配置环境。
三、核心概念:sklearn 的"四大支柱"与数据流程
1. 四大核心组件(必记)
- 估计器(Estimator) :所有模型/预处理工具的基类,核心方法
fit(X, y)(用数据训练)。- 示例:
RandomForestClassifier(分类模型)、StandardScaler(数据标准化)。
- 示例:
- 转换器(Transformer) :数据预处理工具,核心方法
transform(X)(转换数据),常与fit_transform(X)组合使用。- 示例:
MinMaxScaler(特征缩放)、OneHotEncoder(分类变量编码)。
- 示例:
- 预测器(Predictor) :训练后用于预测的模型,核心方法
predict(X)(输出预测结果)、score(X, y)(评估准确率)。- 示例:
LogisticRegression、GradientBoostingRegressor。
- 示例:
- 管道(Pipeline):串联预处理、训练、评估流程,避免数据泄露,简化代码。
2. 标准数据流程(机器学习"黄金步骤")
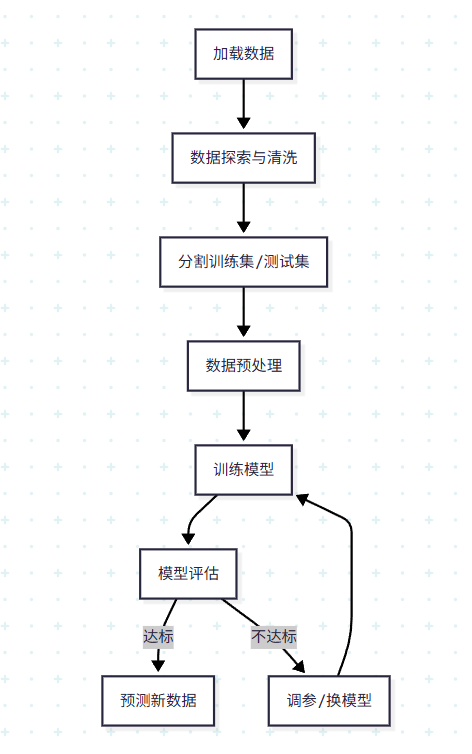
四、实战入门:Iris 花卉分类(10 行代码搞定)
用 sklearn 内置的 Iris 数据集(3 类花卉、4 个特征、150 样本),训练随机森林分类器,新手入门必练案例。
1. 完整代码(可直接复制运行)
python
# 1. 导入所需工具
import sklearn
from sklearn.datasets import load_iris # 内置数据集
from sklearn.model_selection import train_test_split # 数据分割
from sklearn.ensemble import RandomForestClassifier # 模型
from sklearn.metrics import accuracy_score # 评估指标
import matplotlib.pyplot as plt # 可视化
# 2. 加载并查看数据
iris = load_iris()
X = iris.data # 特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度
y = iris.target # 标签:0=山鸢尾、1=变色鸢尾、2=维吉尼亚鸢尾
print("特征形状:", X.shape) # 输出 (150, 4) → 150个样本,4个特征
print("标签类别:", iris.target_names) # 输出 3类花卉名称
# 3. 分割训练集(80%)和测试集(20%)
# random_state=42:固定随机种子,保证结果可复现
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 4. 训练模型(随机森林:100棵决策树)
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train) # 用训练集训练
# 5. 预测与评估
y_pred = model.predict(X_test) # 用测试集预测
accuracy = accuracy_score(y_test, y_pred) # 计算准确率
print(f"\n模型准确率:{accuracy:.2f}") # 输出 1.00(小数据集完美拟合)
print("前5个预测结果:", y_pred[:5])
print("前5个真实标签:", y_test[:5])
# 6. 可视化结果(降维到2D)
from sklearn.decomposition import PCA
pca = PCA(n_components=2) # 4维特征→2维
X_2d = pca.fit_transform(X)
plt.scatter(X_2d[:, 0], X_2d[:, 1], c=y, cmap="viridis", edgecolors="black")
plt.title("Iris 数据集可视化(PCA降维)")
plt.xlabel("PCA维度1")
plt.ylabel("PCA维度2")
plt.show()2. 关键步骤解释
- 数据分割 :
test_size=0.2表示留 20% 数据用于测试,避免模型"死记硬背"训练数据(过拟合)。 - random_state=42:固定随机种子,确保每次运行结果一致,方便调试。
- 准确率 1.00 :Iris 数据集简单,随机森林性能拉满,实际项目中需用交叉验证(如
cross_val_score)避免过拟合。
五、核心模块详解(按场景分类)
sklearn 按功能模块化设计,以下是最常用模块的实战示例,覆盖 80% 开发需求。
| 模块 | 核心功能 | 实战示例代码 | 适用场景 |
|---|---|---|---|
| datasets | 加载数据集(内置/外部) | # 内置数据集 from sklearn.datasets import fetch_california_housing data = fetch_california_housing() # 外部CSV数据(需Pandas) import pandas as pd data = pd.read_csv("data.csv") |
快速获取测试数据、加载自定义数据集 |
| preprocessing | 数据预处理 | # 特征标准化(均值0,方差1) from sklearn.preprocessing import StandardScaler scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train) X_test_scaled = scaler.transform(X_test) # 处理缺失值 from sklearn.impute import SimpleImputer imputer = SimpleImputer(strategy="mean") |
特征缩放、缺失值填充、分类变量编码 |
| model_selection | 数据分割/调参 | # 交叉验证(更可靠的评估) from sklearn.model_selection import cross_val_score scores = cross_val_score(model, X, y, cv=5) print("交叉验证准确率:", scores.mean()) # 超参调优(网格搜索) from sklearn.model_selection import GridSearchCV param_grid = {"n_estimators": [50, 100, 200]} gs = GridSearchCV(model, param_grid, cv=5) gs.fit(X_train, y_train) print("最佳参数:", gs.best_params_) |
避免过拟合、优化模型性能 |
| ensemble | 集成学习(强模型) | # 随机森林分类 from sklearn.ensemble import RandomForestClassifier # 梯度提升回归 from sklearn.ensemble import GradientBoostingRegressor gbr = GradientBoostingRegressor().fit(X_train, y_train) |
追求高准确率的分类/回归任务 |
| metrics | 模型评估 | # 分类评估(精确率/召回率) from sklearn.metrics import classification_report print(classification_report(y_test, y_pred)) # 回归评估(RMSE) from sklearn.metrics import mean_squared_error rmse = mean_squared_error(y_test, y_pred, squared=False) |
分类任务看精确率/召回率,回归任务看RMSE |
| decomposition | 降维可视化 | # PCA降维(用于可视化/去噪) from sklearn.decomposition import PCA # TSNE降维(更适合高维数据) from sklearn.manifold import TSNE |
高维数据可视化、减少计算量 |
进阶技巧:用 Pipeline 简化流程
避免数据泄露(测试集参与预处理),串联预处理和模型:
python
from sklearn.pipeline import Pipeline
# 定义管道:标准化 → 随机森林
pipe = Pipeline([
("scaler", StandardScaler()), # 第一步:标准化
("classifier", RandomForestClassifier()) # 第二步:训练模型
])
# 一键训练(自动用训练集拟合scaler,测试集仅transform)
pipe.fit(X_train, y_train)
score = pipe.score(X_test, y_test)
print("管道模型准确率:", score)六、最佳实践与常见陷阱(避坑指南)
1. 必遵循的 5 个最佳实践
-
数据预处理优先 :
- 数值特征必须标准化/归一化(避免量纲影响,如"身高(cm)"和"体重(kg)")。
- 分类特征需编码(
OneHotEncoder处理无序特征,LabelEncoder处理有序特征)。 - 缺失值必须处理(数值用均值/中位数,分类用众数)。
-
用交叉验证替代单一测试集 :
cross_val_score用 5-10 折验证,结果更可靠。 -
超参调优自动化 :小数据集用
GridSearchCV(全量搜索),大数据集用RandomizedSearchCV(随机搜索,更快)。 -
避免数据泄露 :
- 预处理工具(如
scaler)只能用训练集fit,测试集仅用transform。 - 禁止用测试集的数据优化模型。
- 预处理工具(如
-
模型序列化保存 :训练好的模型用
joblib保存,避免重复训练:pythonimport joblib joblib.dump(model, "iris_model.pkl") # 保存模型 loaded_model = joblib.load("iris_model.pkl") # 加载模型 loaded_model.predict(X_test) # 直接预测
2. 新手最易踩的 4 个陷阱
| 陷阱 | 典型场景 | 解决方案 |
|---|---|---|
| 数据泄露 | 用全量数据标准化后再分割 | 先分割训练集/测试集,再用训练集拟合scaler |
| 过拟合 | 模型在训练集准确率 99%,测试集仅 70% | 1. 增加数据量;2. 减小模型复杂度(如 max_depth=5);3. 增加正则化 |
| 类别不平衡 | 二分类任务中,正样本占比 10%,负样本 90% | 1. 用 F1 分数替代准确率;2. 过采样正样本(SMOTE);3. 欠采样负样本 |
| 忽视特征重要性 | 盲目用所有特征训练,模型复杂且缓慢 | 用 model.feature_importances_ 查看特征重要性,剔除无用特征 |
七、进阶学习路径(4 周入门到实战)
第 1 周:基础入门
- 掌握核心组件(Estimator/Transformer)和数据流程。
- 实战:Iris 分类、波士顿房价回归(
load_boston)。
第 2 周:数据预处理与评估
- 重点学习
preprocessing模块(缺失值、编码、缩放)。 - 掌握分类(准确率、精确率、召回率、混淆矩阵)和回归(RMSE、R²)评估指标。
第 3 周:模型调优与集成学习
- 学习
GridSearchCV/RandomizedSearchCV调参。 - 掌握随机森林、梯度提升树(XGBoost/LightGBM 可补充学习)。
第 4 周:实战项目
- Kaggle 入门项目:Titanic 生存预测(分类)、House Prices 房价预测(回归)。
- 目标:提交结果,熟悉完整机器学习流程。
八、推荐资源(2025 最新)
- 官方文档 :Scikit-learn 1.5.0 官方教程(最权威,示例丰富)。
- 书籍:《Python 机器学习》(Sebastian Raschka,2025 修订版)、《机器学习实战:基于 Scikit-learn 和 TensorFlow》。
- 在线课程 :
- Coursera《Machine Learning》(Andrew Ng,理论基础)。
- Kaggle《Intro to Machine Learning》(实战入门,免费)。
- 实战项目 :
- Kaggle Titanic:https://www.kaggle.com/c/titanic。
- Kaggle House Prices:https://www.kaggle.com/c/house-prices-advanced-regression-techniques。